






1.Hashmap的底层数据结构
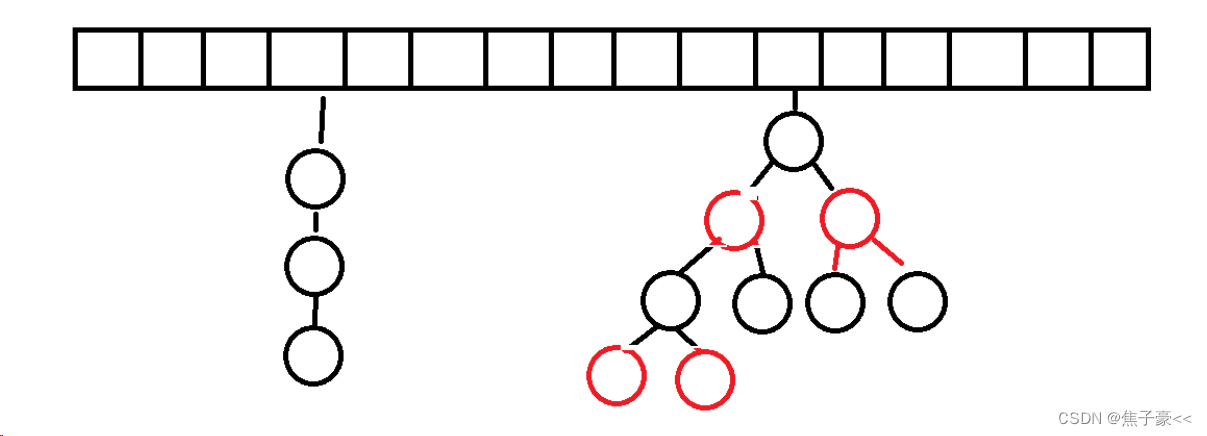
Hashmap的底层使用的是数组+链表或数组+红黑树实现
如图:

数组+链表:
-
因为多个元素Hash之后的值可能是相同的,也叫做哈希冲突,为了避免哈希冲突,所以想到了可以将Hash值相同的元素存到链表中
-
插入元素时的时间复杂度是O(1)
-
由于存入的元素Hash值集中,可能导致链表变的很长,导致查找效率变慢,所以引入了下面的数组+红黑树的数据结构
数组+红黑树:
-
这种数据结构可以保证查询某个数据时,将时间复杂度保证在O(logN),避免查找时间复杂度太大
-
还可以防止DDos攻击带来的效率问题
2. HashMap的实现原理
-
HashMap的数据结构:底层使用的是Hash表的数据结果,即数组+链表/红黑树
-
当往HashMap中put元素时,利用key的hashCode重新计算Hash值,计算当前元素在数组中的下标
-
存储中,如果出现hash的值相同key
-
如果key相同,则覆盖原始值
-
如果key不同,将当前值放到链表或红黑树中
-
-
获取时,直接找到hash值对应的下标,在进一步判断key是否相同,从而找到对应的值
2.1 HashMap的jdk1.7和jdk1.8有什么区别
-
在jdk1.7之前,底层使用的是数组+链表
-
jdk1.8之后,底层使用的是数组+链表+红黑树,当链表长度大于8,且数组长度大于64时,链表转换成红黑树
3. HashMap的put过程
-
判断数组是否为null,如果为null,就执行扩容操作
-
根据key计算hash值,得到数组索引
-
判断table[i] == null 如果条件成立,直接新建节点添加
-
如果table[i] != null
-
判断当前添加的key是否已经存在,如果存在,直接覆盖
-
如果不存在,直接插到当前位置下对应的链表尾部,或插入到红黑树的对应节点
-
如果插入到链表中,插入后链表长度如果大于8,则链表转换为红黑树
-
-
插入成功后,判断实际存在的键值对数量是否超过了当前数组长度的0.75倍,如果超过,触发HashMap的扩容机制
4.HashMap的扩容机制
-
在添加元素或初始化的时候需要调用resize方法进行扩容,第一次添加数据时,初始化数组长度为16,以后每次达到数组的阈值(数组长度*0.75)会触发再次扩容
-
每次扩容后都是原来容量的2倍
-
扩容实际上是创建一个新的数组,把老数组的数据挪动到新数组中
5.HashMap的寻址算法
-
将key进行哈希算法,得到hash值
-
将得到的hash值右移16位再进行运算,目的是让hash值分布的更均匀
-
最后(数组长度-1)&hash值,得到数组索引。(数组长度-1)&hash值相当于hash值%数组长度,提高了运算效率,但这种情况下数组长度必须是2的n次幂才能成立;这也就解释了hash表的数组长度为什么是2的n次幂了















 704
704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









