







文章链接(92条消息) 实验一、双向链表_crystal.star的博客-CSDN博客(网上观看更舒适^^)
实验目的及内容:

解题思路:
基本需求分析:建立带头结点的双向链表,下面说明几点基本概念:
头结点 是在链表的首元结点之前附设的一个结点;数据域内只放空表标志和表长等信息
头指针 是指向链表中第一个结点(即头结点)的指针
首元结点 是指链表中存储第一个数据元素a1的结点

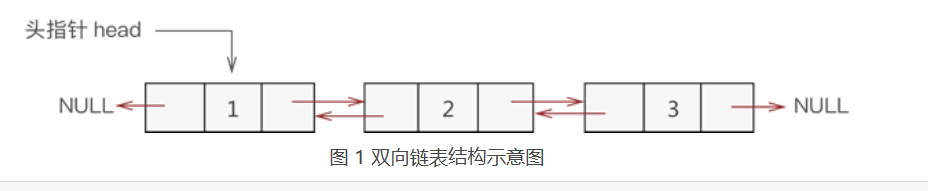

2.对建立好的链表进行“删减”,根据题目要求,对于绝对值相等的节点,仅保留第一次出现的结点,而删除其余绝对值相等的结点
比如这样(直接放上最终实现结果):

删减算法
思路一:对撞指针法 时间复杂度为O(n^2)
算法示意

实现代码:略
思路二👍:额外借助一个布尔数组 时间复杂度为O(n)
由于只需比对数据data的绝对值,而我突然发现数组的Index不正好就是一个个整数的绝对值吗?
所以突发奇想,不妨开一个足够大的bool数组,用每一个数组元素的索引值去对应每一个节点的绝对值,比如:
若扫描指针读到了abs(data)==i,若a[i]==0,说明是第一次读到这个绝对值,那我们就相应的让a[i]=1(初始默认值为0);若a[i]==1,说明之前读到过这个绝对值,那我们就要删除这个节点
算法图解↓↓↓↓
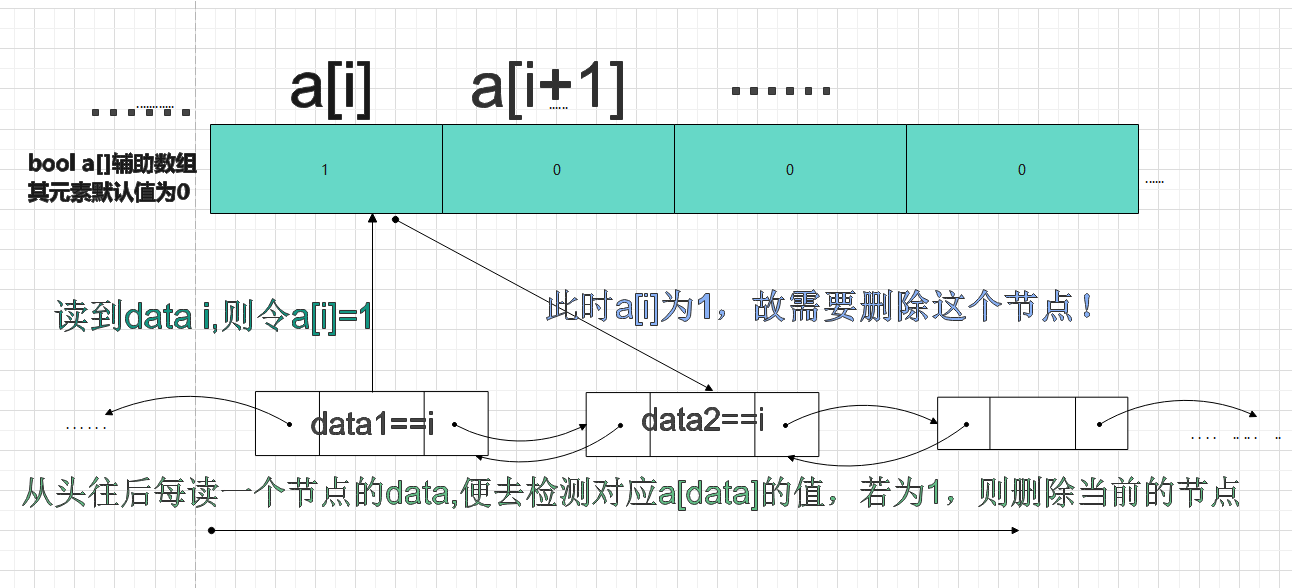
这样,只需从头到尾扫描整个链表一遍,就能够实现题目要求,故时间复杂度为O(n);
额外说明:由于题目仅要求存储“整形”的数据,那么按照一般的int 来算的话,绝对值最大也就65536,而我的电脑可以申请到的bool数组最大可以有999999个元素,可以说是浪费了很多空间来换时间上的高效了。。。。。。
实验代码及注释
#include<stdio.h>
#include<iostream>
#include<stdlib.h>
using namespace std;
typedef struct node
{
struct node * prior;
int data;
struct node * next;
} node;
//双链表的创建函数
node* initLine(node * head);
//删除结点的函数
void deLine(node * trash);
//输出双链表的函数
void display(node * head);
///*******正片开始
int main()
{
//一会儿用来扫描的指针
node* tmp=NULL;
//获取链表容量m和数据域大小n,题目要求嘛
int m,n;
cout<<"请输入链表表长:"<<endl;
cin>>m;
cout<<"请输入数据域大小:"<<endl;
cin>>n;
bool a[999999];//用bool型的数组可以开这么多,C++默认初始值都是FALSE(即0),可以省去自己手动初始化的烦恼
//创建一个链表
node* head=NULL;
head=initLine(head);
node * list=head;//方便初始化赋值用
//读入链表数据值,并赋给对应结点
cout<<"请输入链表数据;"<<endl;
for(int i=0; i<m; ++i)
{
int num;
scanf("%d",&num);
//创建并初始化一个新结点
node * body=(node*)malloc(sizeof(node));
if(!body)exit(0);//分配不成功的处理
body->prior=NULL;
body->next=NULL;
body->data=num;
list->next=body;//直接前趋结点的next指针指向新结点
body->prior=list;//新结点指向直接前趋结点
list=list->next;
}
cout<<"初始链表:"<<endl;//输出删减前的链表
display(head);
//借助布尔数组和扫描节点tmp删除绝对值相等的节点
tmp=head->next;
while(tmp)
{
int dat = tmp->data;
int count = abs(dat);
//cout<<a[count]<<endl;//这一句可以用于调试
if(a[count]==0)
{
a[count]=1;
tmp=tmp->next;
}
else if(a[count]==1)
{
node*rubbish=tmp;
tmp=tmp->next;
deLine(rubbish);
}
}
cout<<"删减后的链表:"<<endl;
display(head);//再次输出trim后的双链表
return 0;
}
//链表初始化函数
node* initLine(node * head)
{
head=(node*)malloc(sizeof(node));//创建链表的头结点head
if(!head)exit(0);//分配不成功的处理
head->prior=NULL;
head->next=NULL;
head->data=0;
return head;
}
//链表输出函数
void display(node * head)
{
node * temp=head->next;
while (temp)
{
//↓↓如果该节点无后继节点,说明此节点是链表的最后一个节点
if (temp->next==NULL)
{
printf("%d\n",temp->data);
}
else
{
printf("%d <-> ",temp->data);
}
temp=temp->next;
}
}
//删除单个结点的函数,
void deLine(node * trash)
{
node * pointer=trash;
if(pointer->next==NULL)//删除尾结点时,特别注意其后继为空!
{
pointer->prior->next=pointer->next;
free(pointer);
pointer=NULL;
}
else
{
pointer->prior->next=pointer->next;
pointer->next->prior=pointer->prior;
free(pointer);
pointer=NULL;
}
}实验结果
输入输出说明
输入:
链表长度m,和数据域大小n,以及链表每个节点的数据值
输出:
第一行:初始的链表;第二行:删减后的链表
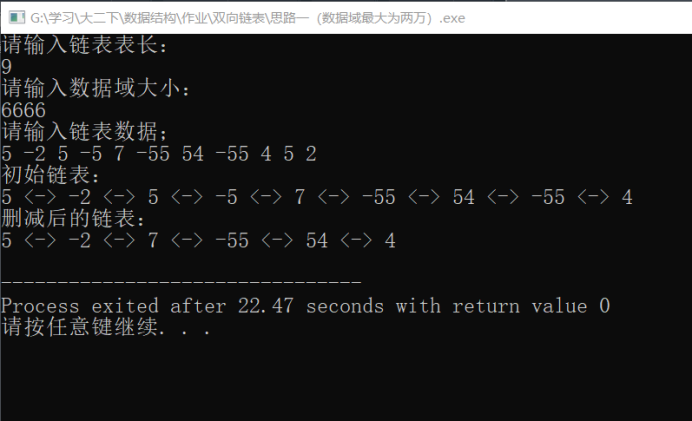
结果截图
一般情况如下:
边界情况(空表)验证:

心得体会
通过两种思路的对比,我们可以非常直观与明显地发现,有时候浪费一些内存空间的确可以大大优化时间复杂度!!














 812
812











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









