






 文章详细介绍了使用Python的Pandas库进行数据分析的一般步骤,包括读取数据、检查和处理缺失值、数据转换、分组分析以及数据可视化,如柱状图、饼图和词云图的绘制。此外,还提及了香农公式和基尼系数在信息理论和分类过程中的应用。
文章详细介绍了使用Python的Pandas库进行数据分析的一般步骤,包括读取数据、检查和处理缺失值、数据转换、分组分析以及数据可视化,如柱状图、饼图和词云图的绘制。此外,还提及了香农公式和基尼系数在信息理论和分类过程中的应用。
目录
转为dataframe格式设置列,用head()查看前几行数据
pandas
- pd.read_csv详解:(14条消息) pd.read_csv参数详解_愚末语的博客-CSDN博客
- pd.merge:数据融合,合并有交叉字段的数据
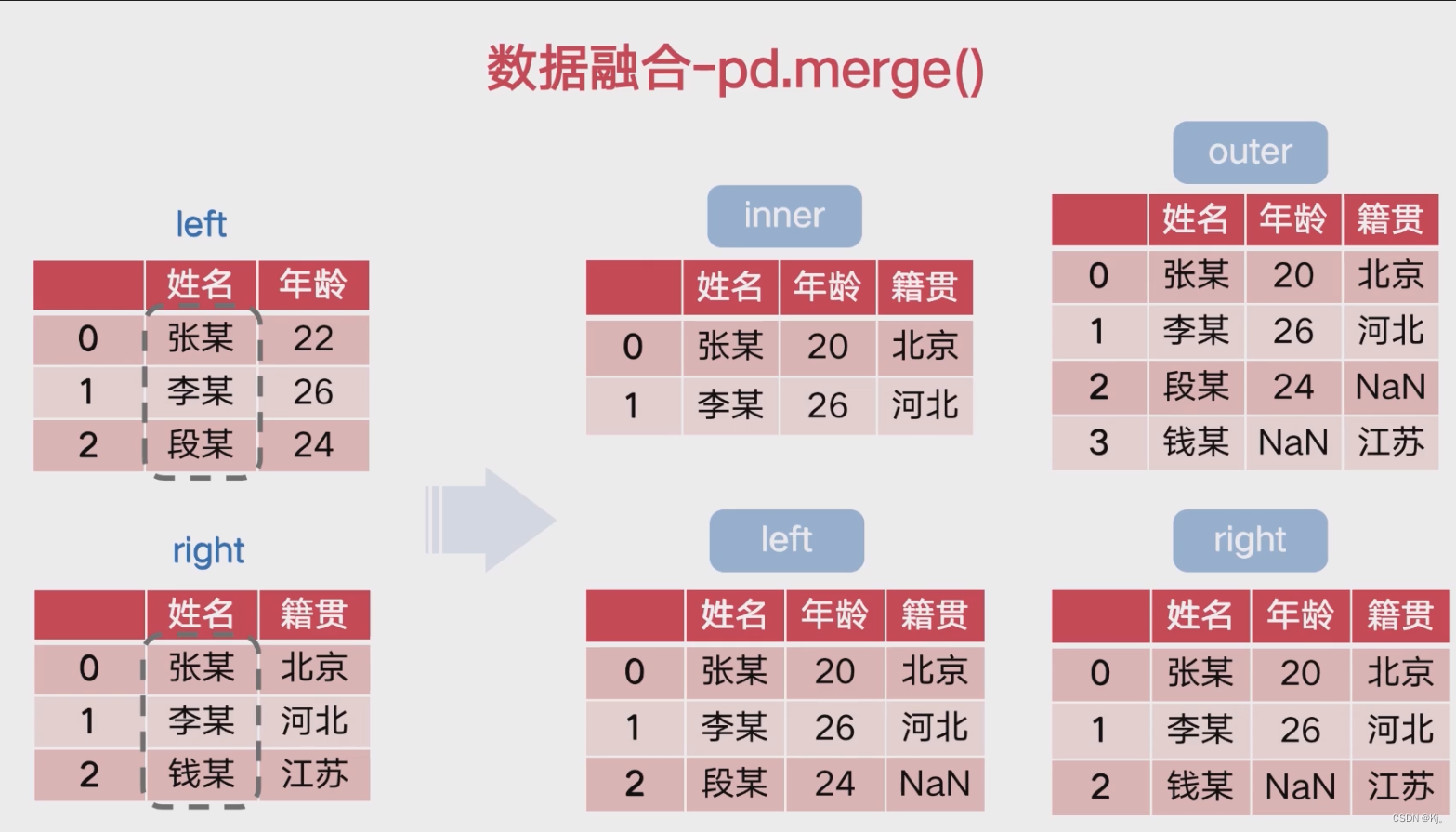
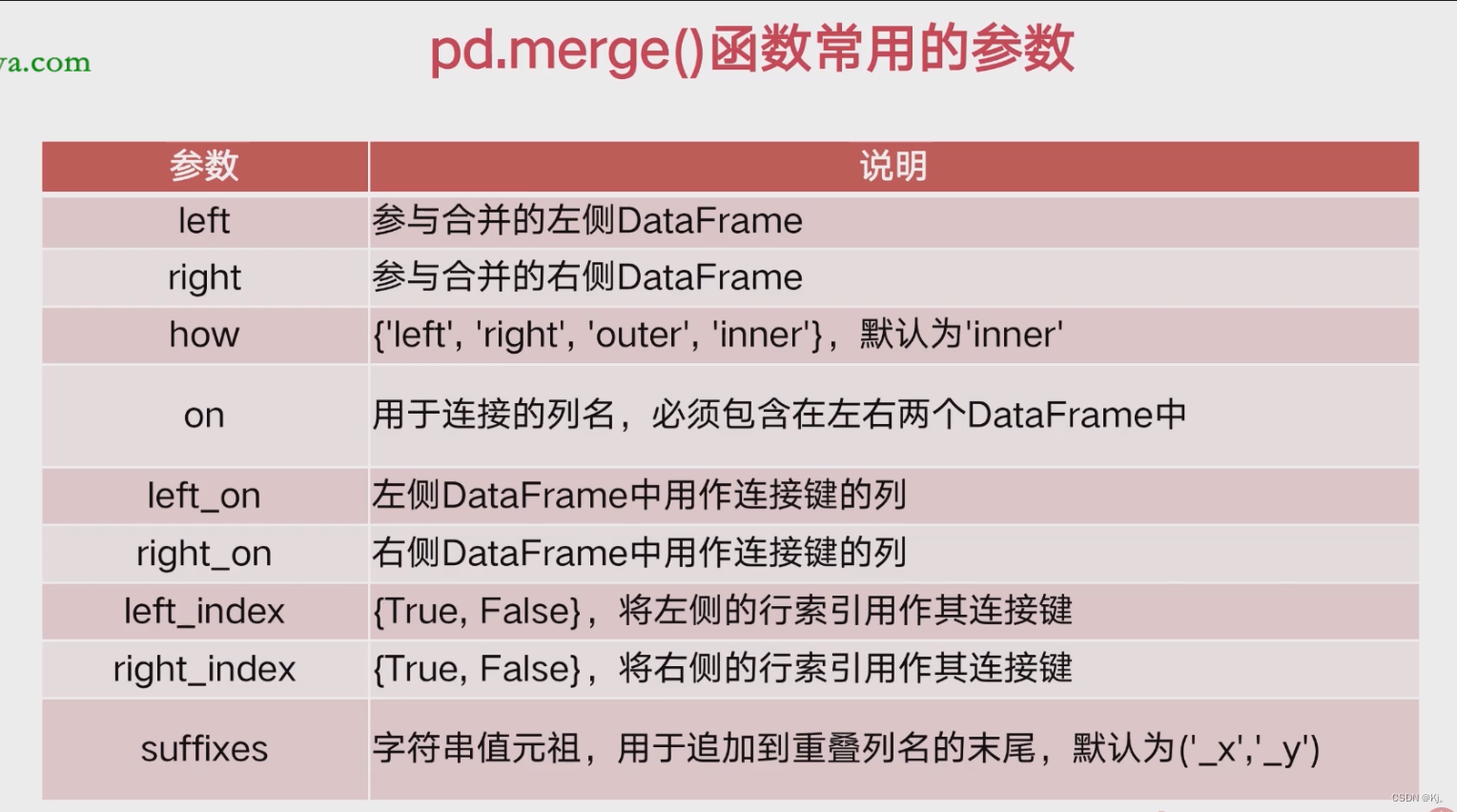
数据分析一般步骤
-
pd.read读取数据
-
分析各数据中是否存在相同字段,是否需要整合

-
可用merge,concat等

-
-
转为dataframe格式设置列,用head()查看前几行数据
ccl=pd.DataFrame(ccl,columns=['CMTE_ID','CAND_ID','CAND_NAME','CAND_PTY_AFFILIATION']) ccl.head(10)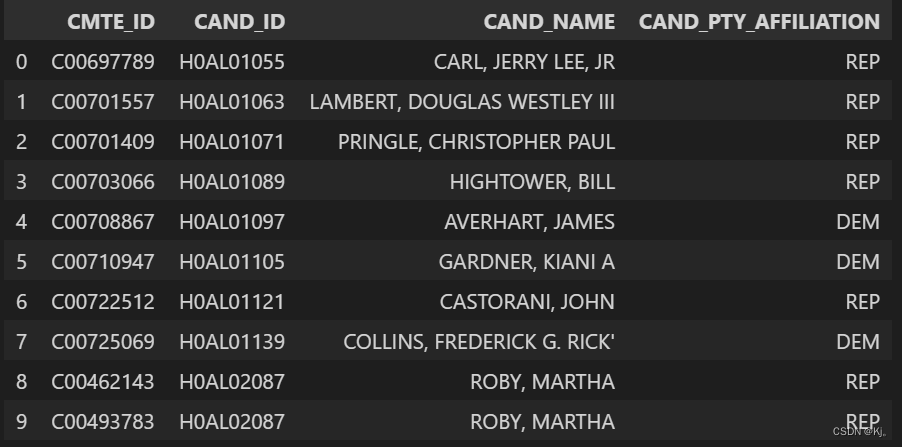
-
用info()查看数据描述,观察有无缺失值,格式问题等
例子
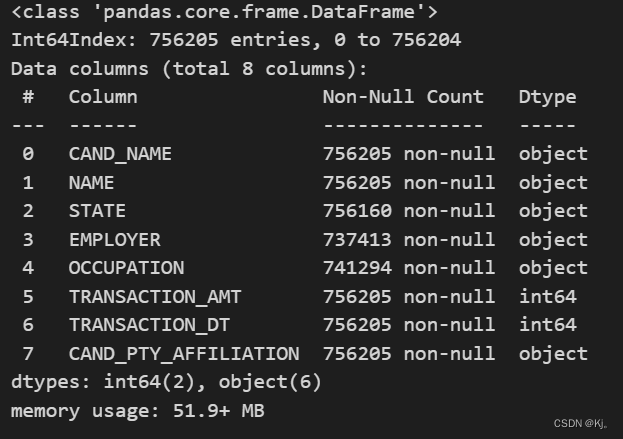
可以看到state、employer、occupation有缺失值(数据量与其他数据的数据量不同),且索引为6的日期格式为int64
-
用describe()观察数据描述
数据处理
缺失值处理,fillna函数。
函数形式:fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)
参数:
value:用于填充的空值的值。
method: {'backfill', 'bfill', 'pad', 'ffill', None}, default None。定义了填充空值的方法, pad / ffill表示用前面行/列的值,填充当前行/列的空值, backfill / bfill表示用后面行/列的值,填充当前行/列的空值。
axis:轴。0或'index',表示按行删除;1或'columns',表示按列删除。
inplace:是否原地替换。布尔值,默认为False。如果为True,则在原DataFrame上进行操作,返回值为None。
limit:int, default None。如果method被指定,对于连续的空值,这段连续区域,最多填充前 limit 个空值(如果存在多段连续区域,每段最多填充前 limit 个空值)。如果method未被指定, 在该axis下,最多填充前 limit 个空值(不论空值连续区间是否间断)
downcast:dict, default is None,字典中的项为,为类型向下转换规则。或者为字符串“infer”,此时会在合适的等价类型之间进行向下转换,比如float64 to int64 if possible。
c_itcont['STATE'].fillna('NOT PROVIDED', inplace=True)
c_itcont['EMPLOYER'].fillna('NOT PROVIDED', inplace=True)
c_itcont['OCCUPATION'].fillna('NOT PROVIDED', inplace=True)
类型转换
astype()转换类型
c_itcont['TRANSACTION_DT']=c_itcont['TRANSACTION_DT'].astype(str)
c_itcont['TRANSACTION_DT']=[i[3:7]+i[0]+i[1:3] for i in c_itcont['TRANSACTION_DT']]#将日期转换为年月日格式groupby分组运用
函数详解: Pandas中groupby的这些用法_pandas groupby_Ch3n的博客-CSDN博客
以本项目为例子
c_itcont.groupby('CAND_PTY_AFFILIATION')['TRANSACTION_AMT'].sum().sort_values(ascending=False).plot(kind='bar',figsize=(10,5),title='各党派总收入')
c_itcont.groupby('CAND_PTY_AFFILIATION')['TRANSACTION_AMT'].sum().sort_values(ascending=False).head(10)按照affiliation分组,按照amt进行倒序排序,使用head查看前几行,plot直接画出图形
或者这样写:
c_itcont.groupby("CAND_PTY_AFFILIATION").sum().sort_values("TRANSACTION_AMT",ascending=False).head(10)数据可视化
DataFrame.plot(x=None, y=None, kind='line', ax=None, subplots=False,
sharex=None, sharey=False, layout=None, figsize=None,
use_index=True, title=None, grid=None, legend=True,
style=None, logx=False, logy=False, loglog=False,
xticks=None, yticks=None, xlim=None, ylim=None, rot=None,
fontsize=None, colormap=None, position=0.5, table=False, yerr=None,
xerr=None, stacked=True/False, sort_columns=False,
secondary_y=False, mark_right=True, **kwds)
x和y:表示标签或者位置,用来指定显示的索引,默认为None
kind:表示绘图的类型,默认为line,折线图
line:折线图 bar/barh:柱状图(条形图),纵向/横向 pie:饼状图 hist:直方图(数值频率分布)
box:箱型图
kde:密度图,主要对柱状图添加Kernel 概率密度线
area:区域图(面积图)
scatter:散点图
hexbin:蜂巢图
ax:子图,可以理解成第二坐标轴,默认None
subplots:是否对列分别作子图,默认False
sharex:共享x轴刻度、标签。如果ax为None,则默认为True,如果传入ax,则默认为False
sharey:共享y轴刻度、标签
layout:子图的行列布局,(rows, columns)
figsize:图形尺寸大小,(width, height)
use_index:用索引做x轴,默认True
title:图形的标题
grid:图形是否有网格,默认None
legend:子图的图例
style:对每列折线图设置线的类型,list or dict
logx:设置x轴刻度是否取对数,默认False
logy
loglog:同时设置x,y轴刻度是否取对数,默认False
xticks:设置x轴刻度值,序列形式(比如列表)
yticks
xlim:设置坐标轴的范围。数值,列表或元组(区间范围)
ylim
rot:轴标签(轴刻度)的显示旋转度数,默认None
fontsize : int, default None#设置轴刻度的字体大小
colormap:设置图的区域颜色
colorbar:柱子颜色
position:柱形图的对齐方式,取值范围[0,1],默认0.5(中间对齐)
table:图下添加表,默认False。若为True,则使用DataFrame中的数据绘制表格
yerr:误差线
xerr
stacked:是否堆积,在折线图和柱状图中默认为False,在区域图中默认为True
sort_columns:对列名称进行排序,默认为False
secondary_y:设置第二个y轴(右辅助y轴),默认为False
mark_right : 当使用secondary_y轴时,在图例中自动用“(right)”标记列标签 ,默认True
x_compat:适配x轴刻度显示,默认为False。设置True可优化时间刻度的显示
1.2 其他常用说明
color:颜色
s:散点图大小,int类型
设置x,y轴名称
ax.set_ylabel(‘yyy’)
ax.set_xlabel(‘xxx’)
柱状图
# 各州总捐款数可视化
st_amt = c_itcont.groupby('STATE').sum().sort_values("TRANSACTION_AMT",ascending=False)[:10]
st_amt=pd.DataFrame(st_amt, columns=['TRANSACTION_AMT'])
st_amt.plot(kind='bar')饼图
c_itcont[c_itcont['CAND_NAME']=='BIDEN, JOSEPH R JR']
.groupby('STATE').sum().sort_values('TRANSACTION_AMT',ascending=False)
.head(10).plot(kind='pie',figsize=(10,5),title='拜登在各州获得的捐赠占比',subplots=True,autopct='%.2f%%')
subplots是否对各列分别作子图,autopct 显示所占总数的百分比
词云图
♦ 参数
♑ font path:字体路径,默认不支持中文,可通过该参数指定字体,支持OTF和TF格式;
♑ width、 height:画布的宽度和高度,单位为像素;
♑ margin:文字之间的边距;
♑ mask:指定图片的形状,忽略白色部分,通常为 ndarray
♑ max words:最多显示的词的数量,默认为200;
♑ min font size、 max font size:最小字体大小、最大字体大小;
♑ font_step:字体大小增加步长,默认为1
♑ background_ color:词云图的背景颜色,默认为黑色
♦ 方法
♑ generate(text):根据文本生成词云图,返回当前对象本身;
♑ to image0:将词云对象转化为图片;
♑ to_file(文件名):将词云对象转化为文件;
♑ to array():将词云对象转化为数组。
♦ 基本步骤
♑ 创建wordcloud对象,设定基本信息
♑ 调用generate()方法生成词云
♑ 保存或显示词云
# 在4.2 热门候选人拜登在各州的获得的捐赠占比 中我们已经取出了所有支持拜登的人的数据,存在变量:biden中
# 将所有捐赠者姓名连接成一个字符串
data = ' '.join(biden["NAME"].tolist())
# 读取图片文件
bg = plt.imread("biden.jpg")
# 生成
wc = WordCloud(# FFFAE3
background_color="white", # 设置背景为白色,默认为黑色
width=890, # 设置图片的宽度
height=600, # 设置图片的高度
mask=bg, # 画布
margin=10, # 设置图片的边缘
max_font_size=100, # 显示的最大的字体大小
random_state=20, # 为每个单词返回一个PIL颜色
).generate_from_text(data)
# 图片背景
bg_color = ImageColorGenerator(bg)
# 开始画图
plt.imshow(wc.recolor(color_func=bg_color))
# 为云图去掉坐标轴
plt.axis("off")
# 画云图,显示
# 保存云图
wc.to_file("biden_wordcloud.png")数据分析方法
香农公式
在信息论中,随机离散事件出现的概率存在着不确定性。为了衡量这种信息的不确定性,信息学之父香农引入了信息熵的概念,并给出了计算信息熵的数学公式:

p(i|t) 代表了节点 t 为分类 i 的概率,其中 log2 为取以 2 为底的对数。这里我不是来介绍公式的,而是说存在一种度量,它能帮我们反映出来这个信息的不确定度。当不确定性越大时,它所包含的信息量也就越大,信息熵也就越高,当确定性越大时,则相反。
我举个简单的例子,假设有 2 个集合
1.集合 1:5 次参加天池比赛,1 次不参加天池比赛;
2.集合 2:3 次参加天池比赛,3 次不参加天池比赛;
在集合 1 中,有 6 次决策,其中参加天池比赛是 5 次,不参加天池比赛是 1 次。那么假设:类别 1 为“参加天池比赛”,即次数为 5;类别 2 为“不参加天池比赛”,即次数为 1。那么节点划分为类别 1 的概率是 5/6,为类别 2 的概率是 1/6,带入上述信息熵公式可以计算得出:
Entropy(t)=-(5/6)log2(5/6)-(1/6)log2(1/6)=0.65
同样,集合 2 中,也是一共 6 次决策,其中类别 1 中“参加天池比赛”的次数是 3,类别 2“不参加天池比赛”的次数也是 3,我们可以计算得出:
Enterop(t)=-(3/6)log2(3/6)-(3/6)log2(3/6)=1
从上面的计算结果中可以看出,信息熵越大,纯度越低。当集合中的所有样本均匀混合时,信息熵最大,纯度最低。
你可能在经济学中听过说基尼系数,它是用来衡量一个国家收入差距的常用指标。当基尼系数大于 0.4 的时候,说明财富差异悬殊。基尼系数在 0.2-0.4 之间说明分配合理,财富差距不大。基尼系数本身反应了样本的不确定度。当基尼系数越小的时候,说明样本之间的差异性小,不确定程度低。分类的过程本身是一个不确定度降低的过程,即纯度的提升过程。

基尼系数
假设 t 为节点,那么该节点的 GINI 系数的计算公式为: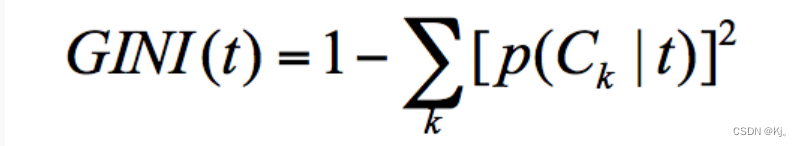
我举个简单的例子,假设有 2 个集合
1.集合 1:6次都参加天池比赛;
2.集合 2:3 次参加天池比赛,3 次不参加天池比赛;
集合 1,6次都参加天池比赛,所以 p(Ck|t)=1,因此 GINI(t)=1-1=0。
集合 2,3 次参加天池比赛,3 次不参加天池比赛,所以,p(C1|t)=0.5,p(C2|t)=0.5,GINI(t)=1-(0.5x0.5+0.5x0.5)=0.5。
通过两个基尼系数你可以看出,集合 1 的基尼系数最小,也证明样本最稳定,而集合 2 的样本不稳定性更大。
在 CART 算法中,基于基尼系数对特征属性进行二元分裂,假设节点 D 的基尼系数等于子节点 D1 和 D2 的归一化基尼系数之和,用公式表示为:
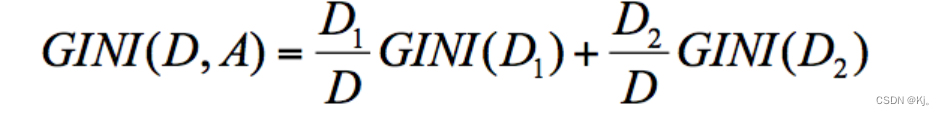

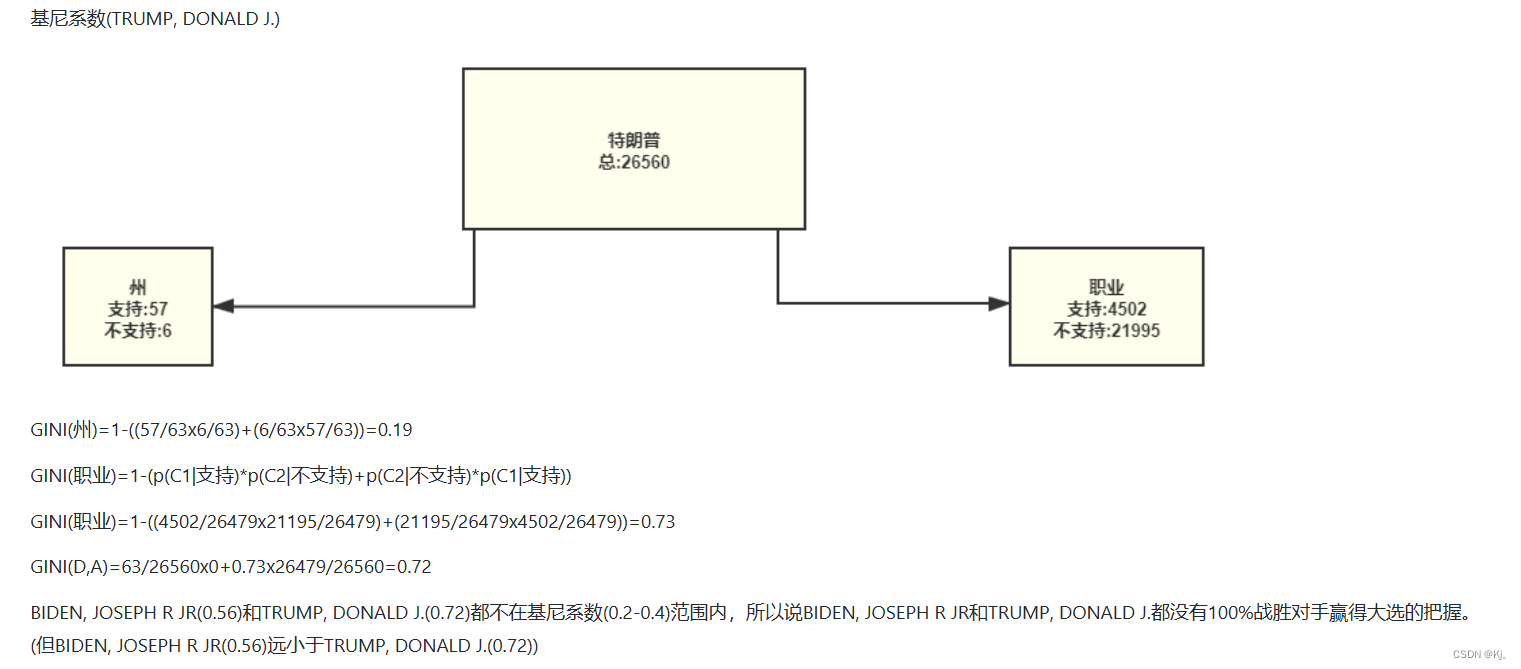
美国选总统为例
# 从所有数据中取出支持拜的数据
biden = c_itcont[c_itcont['CAND_NAME'] == 'BIDEN, JOSEPH R JR']
# 统计各州对拜的捐款总数
biden_state = biden.groupby('STATE').sum().sort_values("TRANSACTION_AMT", ascending=False)
q = np.array(biden_state) # 创建ndarray 对象
number_b = len(q) # 支持拜州的数量# 从所有数据中取出支持特朗的数据
trump = c_itcont[c_itcont['CAND_NAME'] == 'TRUMP, DONALD J.']
# 统计各州对特朗的捐款总数
trump_state = trump.groupby('STATE').sum().sort_values("TRANSACTION_AMT", ascending=False)
w = np.array(trump_state) # 创建ndarray 对象
number_t = len(w) # 支持特朗州的数量上方为支持的州的数量
下方为支持人数
# 从所有数据中取出支持拜的数据
biden = c_itcont[c_itcont['CAND_NAME'] == 'BIDEN, JOSEPH R JR']
# 统计各职业对拜的捐款总数
biden_state = biden.groupby('OCCUPATION').sum().sort_values("TRANSACTION_AMT", ascending=False)
e = np.array(biden_state) # 创建ndarray 对象# 从所有数据中取出支持特朗的数据
biden = c_itcont[c_itcont['CAND_NAME'] == 'TRUMP, DONALD J.']
# 统计各职业对特朗的捐款总数
biden_state = biden.groupby('OCCUPATION').sum().sort_values("TRANSACTION_AMT", ascending=False)
r = np.array(biden_state) # 创建ndarray 对象州的总数和职业的总数:
# pivot_table作用是按职业和捐赠数额聚合数据,index=['STATE']取出捐赠人所在的职业,values=['TRANSACTION_AMT']取出捐赠人捐赠的数额,aggfunc='sum'计算相同州的总额
by_occupation = pd.pivot_table(c_itcont, index=['STATE'], values=['TRANSACTION_AMT'], aggfunc='sum')
number = len(by_occupation) # 州的数量# pivot_table作用是按职业和捐赠数额聚合数据,index=['OCCUPATION']取出捐赠人所在的职业,values=['TRANSACTION_AMT']取出捐赠人捐赠的数额,aggfunc='sum'计算相同职业的总额
by_occupation = pd.pivot_table(c_itcont, index=['OCCUPATION'], values=['TRANSACTION_AMT'], aggfunc='sum')
number_j = len(by_occupation) # 职业的总数量

















 468
468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









