







在本教程中,我们将向您展示如何开发水平联合推荐模型。我们使用第三方库torch rechub调用一些经典的推荐模型,如FM、DeepFM等,并使用它在FATE中构建联邦任务。在数据集方面,我们使用了经过采样和预处理的Criteo数据集,共有50K个数据。为了方便起见,在本教程中,所有客户端都使用相同的数据集。
安装Torch-rechub(推荐)
我们将从以下位置使用Torch-rechub:https://github.com/datawhalechina/torch-rechub.要运行本教程,您需要安装最新版本:
cd torch-rechub
python setup.py install
也可以安装稳定版(存在报错)
#稳定版
pip install torch-rechub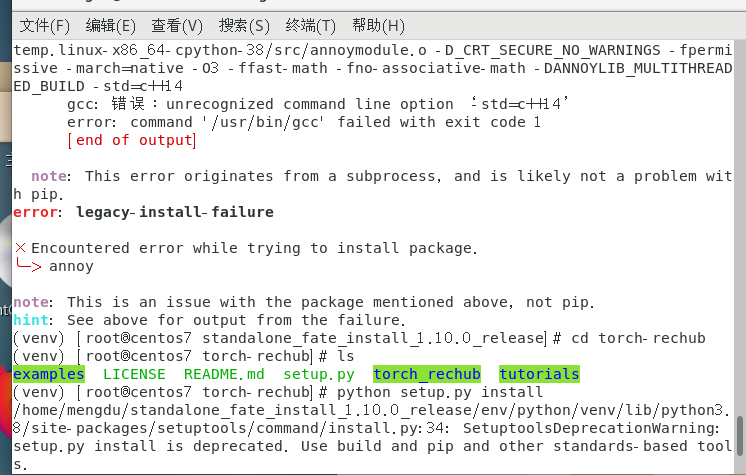
在进行稳定版安装时出现了报错,所以推荐最新版安装。
Criteo公司
Criteo数据集是Criteo实验室发布的在线广告数据集。它包含数百万条显示广告的点击反馈记录,可作为点击率(CTR)预测的基准。数据集有40个特征,第一列是标签,其中值1表示广告被点击,值0表示广告未被点击。其他特征包括13个密集特征和26个稀疏特征。
此处下载本教程中使用的采样数据:
然后将csv放在/examples/data下(或者自己存放文件的地址,代码中需要用到)。
criteo数据集的来源是:https://ailab.criteo.com/ressources/
构造数据集类
在这里,我们将构建一个Criteo数据集来读取csv。同时,它将处理数据集并返回有关密集和稀疏特征的信息。
from pipeline.component.nn import save_to_fate %%save_to_fate dataset criteo_dataset.py
from sklearn.preprocessing import MinMaxScaler, LabelEncoder
from tqdm import tqdm
import pandas as pd
import numpy as np
from federatedml.nn.dataset.base import Dataset
from torch_rechub.basic.features import DenseFeature, SparseFeature
class CriteoDataset(Dataset):
def __init__(self):
# super().__init__()
super(CriteoDataset, self).__init__()
self.x = None
self.y = None
self.sample_ids= None
# load dataset and process
def load(self, data_path):
# convert numeric features
def convert_numeric_feature(val):
v = int(val)
if v > 2:
return int(np.log(v)**2)
else:
return v - 2
# load data
if data_path.endswith(".gz"): #if the raw_data is gz file:
data = pd.read_csv(data_path, compression="gzip")
else:
data = pd.read_csv(data_path)
print("data load finished")
# print(data.info())
if 'sid' in data.columns:
self.sample_ids = list(data.sid)
# feature_process
dense_features = [f for f in data.columns.tolist() if f[0] == "I"]
sparse_features = [f for f in data.columns.tolist() if f[0] == "C"]
data[sparse_features] = data[sparse_features].fillna('0')
data[dense_features] = data[dense_features].fillna(0)
for feat in tqdm(dense_features): #discretize dense feature and as new sparse feature
sparse_features.append(feat + "_cat")
data[feat + "_cat"] = data[feat].apply(lambda x: convert_numeric_feature(x))
sca = MinMaxScaler() #scaler dense feature
data[dense_features] = sca.fit_transform(data[dense_features])
for feat in tqdm(sparse_features): #encode sparse feature
lbe = LabelEncoder()
data[feat] = lbe.fit_transform(data[feat])
def get_dense_feat(name):
return DenseFeature(name), {'name': name}
dense_feas = []
dense_feas_dict = []
for feature_name in dense_features:
a,b = get_dense_feat(feature_name)
dense_feas.append(a)
dense_feas_dict.append(b)
def get_sparse_feat(name, vocab_size,embed_dim):
return SparseFeature(name, vocab_size,embed_dim), {'name': name, 'vocab_size': vocab_size,'embed_dim':embed_dim}
sparse_feas=[]
sparse_feas_dict=[]
for feature_name in sparse_features:
a,b = get_sparse_feat(name=feature_name, vocab_size=data[feature_name].nunique(), embed_dim=16)
sparse_feas.append(a)
sparse_feas_dict.append(b)
ffm_linear_feas = []
ffm_linear_feas_dict = []
def get_ffm_linear_feat(name, vocab_size,embed_dim):
return SparseFeature(name, vocab_size,embed_dim), {'name': name, 'vocab_size': vocab_size,'embed_dim':embed_dim}
for feature in sparse_feas:
a,b = get_ffm_linear_feat(name = feature.name, vocab_size=feature.vocab_size, embed_dim=1)
ffm_linear_feas.append(a)
ffm_linear_feas_dict.append(b)
ffm_cross_feas = []
ffm_cross_feas_dict = []
def get_ffm_cross_feat(name, vocab_size,embed_dim):
return SparseFeature(name, vocab_size,embed_dim), {'name': name, 'vocab_size': vocab_size,'embed_dim':embed_dim}
for feature in sparse_feas:
a,b = get_ffm_cross_feat(name = feature.name, vocab_size=feature.vocab_size*len(sparse_feas), embed_dim=10)
ffm_cross_feas.append(a)
ffm_cross_feas_dict.append(b)
y = data["label"]
del data["label"]
x = data
# ncq:
self.x = x
self.y = y
return dense_feas, dense_feas_dict,sparse_feas,sparse_feas_dict, ffm_linear_feas,ffm_linear_feas_dict, ffm_cross_feas, ffm_cross_feas_dict
def __getitem__(self, index):
return {k: v[index] for k, v in self.x.items()}, self.y[index].astype(np.float32)
def __len__(self):
return len(self.y)
def get_sample_ids(self,):
return self.sample_idsCTR模型
在Torch rechub的基础上,我们开发了四种CTR模型:FM、FFM、DeepFM和DeepFFM
%%save_to_fate model fm_model.py
import torch
from torch_rechub.basic.layers import FM,LR,EmbeddingLayer
from torch_rechub.basic.features import DenseFeature, SparseFeature
class FMModel(torch.nn.Module):
'''
A standard FM models
'''
def __init__(self, dense_feas_dict, sparse_feas_dict):
super(FMModel, self).__init__()
dense_features = []
def recover_dense_feat(dict_):
return DenseFeature(name=dict_['name'])
for i in dense_feas_dict:
dense_features.append(recover_dense_feat(i))
self.dense_features = dense_features
sparse_features = []
def recover_sparse_feat(dict_):
return SparseFeature(dict_['name'], dict_['vocab_size'],dict_['embed_dim'])
for i in sparse_feas_dict:
sparse_features.append(recover_sparse_feat(i))
self.sparse_features = sparse_features
self.fm_features = self.sparse_features
self.fm_dims = sum([fea.embed_dim for fea in self.fm_features])
self.linear = LR(self.fm_dims) # 1-odrder interaction
self.fm = FM(reduce_sum=True) # 2-odrder interaction
self.embedding = EmbeddingLayer(self.fm_features)
def forward(self, x):
input_fm = self.embedding(x, self.fm_features, squeeze_dim=False) #[batch_size, num_fields, embed_dim]input_fm: torch.Size([100, 39, 16])
# print('input_fm:',input_fm.shape) # input_fm: torch.Size([100, 39, 16]) (batch_size, num_features, embed_dim)
y_linear = self.linear(input_fm.flatten(start_dim=1))
y_fm = self.fm(input_fm)
# print('y_fm.shape:',y_fm.shape) # y_fm.shape: torch.Size([100, 1])
y = y_linear + y_fm
return torch.sigmoid(y.squeeze(1))%%save_to_fate model deepfm_model.py
import torch
from torch_rechub.basic.layers import FM,LR,EmbeddingLayer,MLP
from torch_rechub.basic.features import DenseFeature, SparseFeature
class DeepFMModel(torch.nn.Module):
"""Deep Factorization Machine Model
Args:
deep_features (list): the list of `Feature Class`, training by the deep part module.
fm_features (list): the list of `Feature Class`, training by the fm part module.
mlp_params (dict): the params of the last MLP module, keys include:`{"dims":list, "activation":str, "dropout":float, "output_layer":bool`}
"""
def __init__(self, dense_feas_dict, sparse_feas_dict, mlp_params):
super(DeepFMModel, self).__init__()
dense_features = []
def recover_dense_feat(dict_):
return DenseFeature(name=dict_['name'])
for i in dense_feas_dict:
dense_features.append(recover_dense_feat(i))
self.dense_features = dense_features
sparse_features = []
def recover_sparse_feat(dict_):
return SparseFeature(dict_['name'], dict_['vocab_size'],dict_['embed_dim'])
for i in sparse_feas_dict:
sparse_features.append(recover_sparse_feat(i))
self.deep_features = dense_features
self.fm_features = sparse_features
self.deep_dims = sum([fea.embed_dim for fea in dense_features])
self.fm_dims = sum([fea.embed_dim for fea in sparse_features])
self.linear = LR(self.fm_dims) # 1-odrder interaction
self.fm = FM(reduce_sum=True) # 2-odrder interaction
self.embedding = EmbeddingLayer(dense_features + sparse_features)
self.mlp = MLP(self.deep_dims, **mlp_params)
def forward(self, x):
input_deep = self.embedding(x, self.deep_features, squeeze_dim=True) #[batch_size, deep_dims]
input_fm = self.embedding(x, self.fm_features, squeeze_dim=False) #[batch_size, num_fields, embed_dim]
y_linear = self.linear(input_fm.flatten(start_dim=1))
y_fm = self.fm(input_fm)
y_deep = self.mlp(input_deep) #[batch_size, 1]
y = y_linear + y_fm + y_deep
return torch.sigmoid(y.squeeze(1))%%save_to_fate model ffm_model.py
import torch
from torch_rechub.basic.layers import LR,EmbeddingLayer,FFM,FM
import torch
from torch_rechub.basic.features import DenseFeature, SparseFeature
class FFMModel(torch.nn.Module):
def __init__(self, liner_feas_dict, cross_feas_dict):
super(FFMModel, self).__init__()
linear_features = []
def recover_ffm_linear_feat(dict_):
return SparseFeature(dict_['name'], dict_['vocab_size'],dict_['embed_dim'])
for i in liner_feas_dict:
linear_features.append(recover_ffm_linear_feat(i))
cross_features = []
def recover_ffm_cross_feat(dict_):
return SparseFeature(dict_['name'], dict_['vocab_size'],dict_['embed_dim'])
for i in cross_feas_dict:
cross_features.append(recover_ffm_cross_feat(i))
self.linear_features = linear_features
self.cross_features = cross_features
self.num_fields = len(cross_features)
self.num_field_cross = self.num_fields * (self.num_fields - 1) // 2
# print('num_fields:',self.num_fields) #39
self.ffm = FFM(num_fields=self.num_fields, reduce_sum=False)
self.linear_embedding = EmbeddingLayer(linear_features)
self.ffm_embedding = EmbeddingLayer(cross_features)
self.b =torch.nn.Parameter(torch.zeros(1))
fields_offset = torch.arange(0, self.num_fields, dtype=torch.long)
self.register_buffer('fields_offset', fields_offset)
self.fm = FM(reduce_sum=True)
def forward(self, x):
y_linear = self.linear_embedding(x, self.linear_features, squeeze_dim=True).sum(1, keepdim=True) #[batch_size, 1]
# output shape [batch_size, num_field, num_field, emb_dim]
x_ffm = {fea.name: x[fea.name].unsqueeze(1) * self.num_fields + self.fields_offset for fea in self.cross_features}
input_ffm = self.ffm_embedding(x_ffm, self.cross_features, squeeze_dim=False)
# print('input_ffm.shape:',input_ffm.shape) # torch.Size([100, 39, 39, 10])
em = self.ffm(input_ffm)
# print('output_ffm.shape:',em.shape)
# torch.Size([100, 741, 10])(batch_size, num_fields*(num_fields-1)/2,embed_dim)
y_ffm = self.fm(em)
# compute scores from the ffm part of the model, output shape [batch_size, 1]
# print('y_linear.shape:',y_linear.shape) # torch.Size([100,1])
y = y_linear + y_ffm
return torch.sigmoid(y.squeeze(1)+ self.b)%%save_to_fate model deepffm_model.py
import torch
from torch import nn
from torch_rechub.basic.features import SparseFeature
from torch_rechub.models.ranking import DeepFFM
class DeepFFMModel(nn.Module):
def __init__(self,ffm_linear_feas_dict, ffm_cross_feas_dict):
super().__init__()
linear_features = []
cross_features = []
def recover_sparse_feat(dict_):
return SparseFeature(dict_['name'], dict_['vocab_size'],dict_['embed_dim'])
for i in ffm_linear_feas_dict:
linear_features.append(recover_sparse_feat(i))
for i in ffm_cross_feas_dict:
cross_features.append(recover_sparse_feat(i))
self.model = DeepFFM(linear_features=linear_features, cross_features=cross_features, embed_dim=10, mlp_params={"dims": [1600, 1600], "dropout": 0.5, "activation": "relu"})
def forward(self, x):
return self.model(x)本地测试
在本地测试这个集合(数据集+模型),看看它是否可以运行,并在本地验证期间省略联邦聚合部分。
import torch
from federatedml.nn.homo.trainer.fedavg_trainer import FedAVGTrainer
ds = CriteoDataset()
path = '/mnt/hgfs/criteo.csv' # 根据自己的criteo.csv下载位置进行调整
dense_feas, dense_feas_dict, sparse_feas, sparse_feas_dict, ffm_linear_feas, \
ffm_linear_feas_dict, ffm_cross_feas, ffm_cross_feas_dict = ds.load(path)
fm_model = FMModel(dense_feas_dict=dense_feas_dict,sparse_feas_dict=sparse_feas_dict)
ffm_model = FFMModel(liner_feas_dict=ffm_linear_feas_dict, cross_feas_dict=ffm_cross_feas_dict)
dfm_model = DeepFMModel(dense_feas_dict=dense_feas_dict,sparse_feas_dict=sparse_feas_dict, mlp_params={"dims": [256, 128], "dropout": 0.2, "activation": "relu"})
dffm_model = DeepFFMModel(ffm_linear_feas_dict=ffm_linear_feas_dict,ffm_cross_feas_dict=ffm_cross_feas_dict)
model = fm_model
# here we test one model: the FM Model
trainer = FedAVGTrainer(epochs=1, batch_size=256)
trainer.local_mode()
trainer.set_model(model)
trainer.train(ds, None, optimizer=torch.optim.Adam(model.parameters(), lr=0.01), loss=torch.nn.BCELoss())
提交Pipeline以运行联邦任务
from federatedml.nn.dataset.criteo_dataset import CriteoDataset
import numpy as np
import pandas as pd
from pipeline.interface import Data, Model
from pipeline.component import Reader, Evaluation, DataTransform
from pipeline.backend.pipeline import PipeLine
from pipeline.component import HomoNN
from pipeline import fate_torch_hook
from torch import nn
import torch as t
import os
from pipeline.component.homo_nn import DatasetParam, TrainerParam
fate_torch_hook(t)
# 同样根据自己的文件位置进行调整
# fate_project_path = os.path.abspath('../../../../')
# data_path = 'examples/data/criteo.csv'
host = 10000
guest = 9999
arbiter = 10000
pipeline = PipeLine().set_initiator(role='guest', party_id=guest).set_roles(guest=guest, host=host, arbiter=arbiter)
data = {"name": "criteo", "namespace": "experiment"}
pipeline.bind_table(name=data['name'],
namespace=data['namespace'], path='/mnt/hgfs/criteo.csv')
# reader
reader_0 = Reader(name="reader_0")
reader_0.get_party_instance(
role='guest', party_id=guest).component_param(table=data)
reader_0.get_party_instance(
role='host', party_id=host).component_param(table=data)
# compute model parameter for our CTR models
ds = CriteoDataset()
dense_feas, dense_feas_dict, sparse_feas, sparse_feas_dict, ffm_linear_feas, ffm_linear_feas_dict, \
ffm_cross_feas, ffm_cross_feas_dict = ds.load('/mnt/hgfs/criteo.csv')
model = t.nn.Sequential(
t.nn.CustModel(module_name='fm_model', class_name='FMModel', dense_feas_dict=dense_feas_dict, sparse_feas_dict=sparse_feas_dict)
)
nn_component = HomoNN(name='nn_0',
model=model,
loss=t.nn.BCELoss(),
optimizer=t.optim.Adam(
model.parameters(), lr=0.001, weight_decay=0.001),
dataset=DatasetParam(dataset_name='criteo_dataset'),
trainer=TrainerParam(trainer_name='fedavg_trainer', epochs=1, batch_size=256, validation_freqs=1,
data_loader_worker=6, shuffle=True),
torch_seed=100
)
pipeline.add_component(reader_0)
pipeline.add_component(nn_component, data=Data(train_data=reader_0.output.data))
pipeline.add_component(Evaluation(name='eval_0', eval_type='binary'), data=Data(data=nn_component.output.data))
pipeline.compile()
pipeline.fit()
写入并保存
import pandas as pd
df = pipeline.get_component('nn_0').get_output_data() # get result
df.to_csv('Criteo上的联邦经典CTR模型训练.csv')pipeline.get_component('nn_0').get_summary()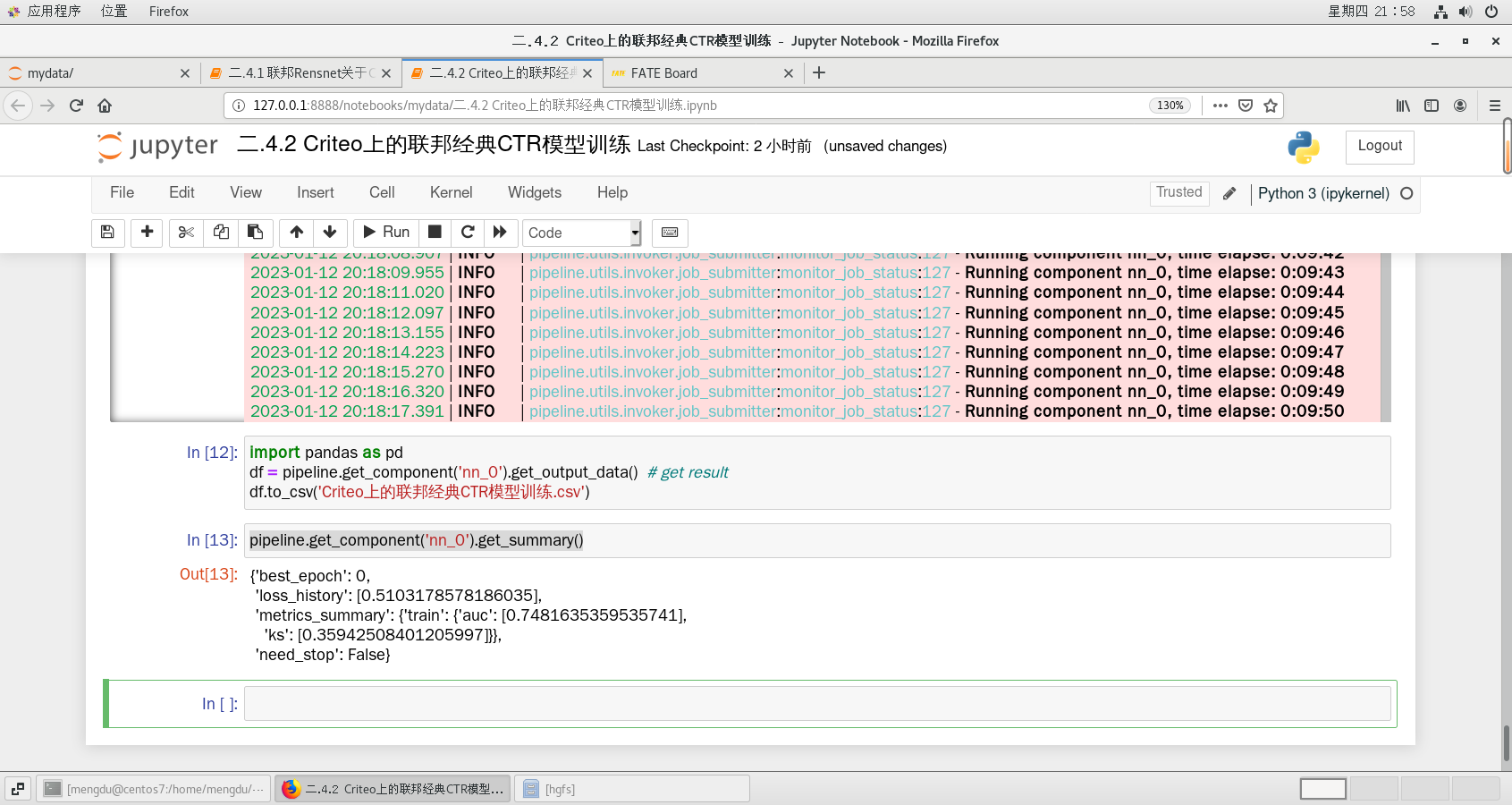
















 1515
1515











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









