








前言
以后所有资源模型,都在这个网址公布:https://tianfeng.space/1240.html
要不然东一个西一个难找麻烦
安装:stable diffusion 小白最全详细使用教程
模型最终版:https://blog.csdn.net/weixin_62403633/article/details/131089616?spm=1001.2014.3001.5501
如果安装或者使用有问题,欢迎评论区留言,CSDN博客,知乎都行。本人只分享资源,有问题看到都会解答,而且不会建什么群,拿资源,只要我有的统统公开。只希望看到我的文章对你有点用的话,可以点个赞,评论几句,就十分感谢!!!
文章目录
一、插件推荐
1.sd-webui-prompt-all-in-one
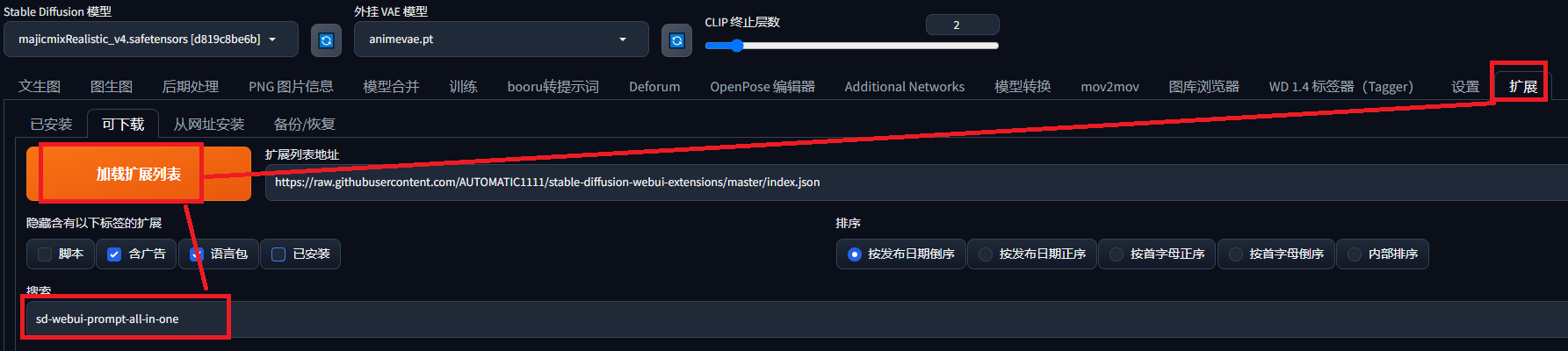
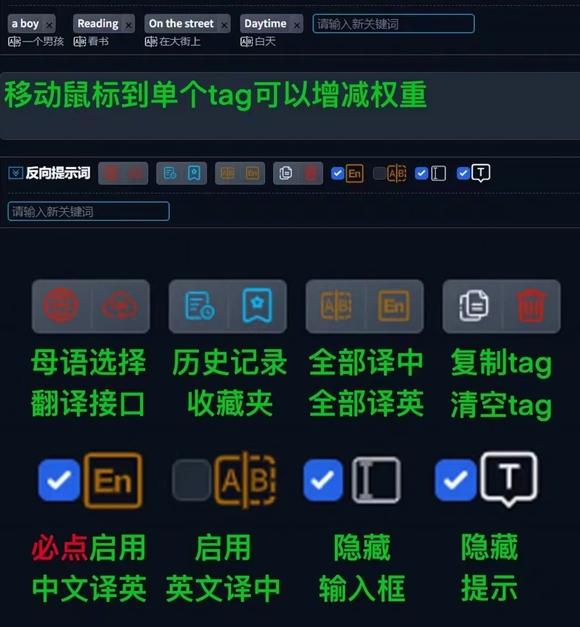
- 中文输入自动转英文
- 自动保存使用描述词
- 一键收藏想要描述词
- 翻译接口超多种选择
- -键粘贴删除描述词
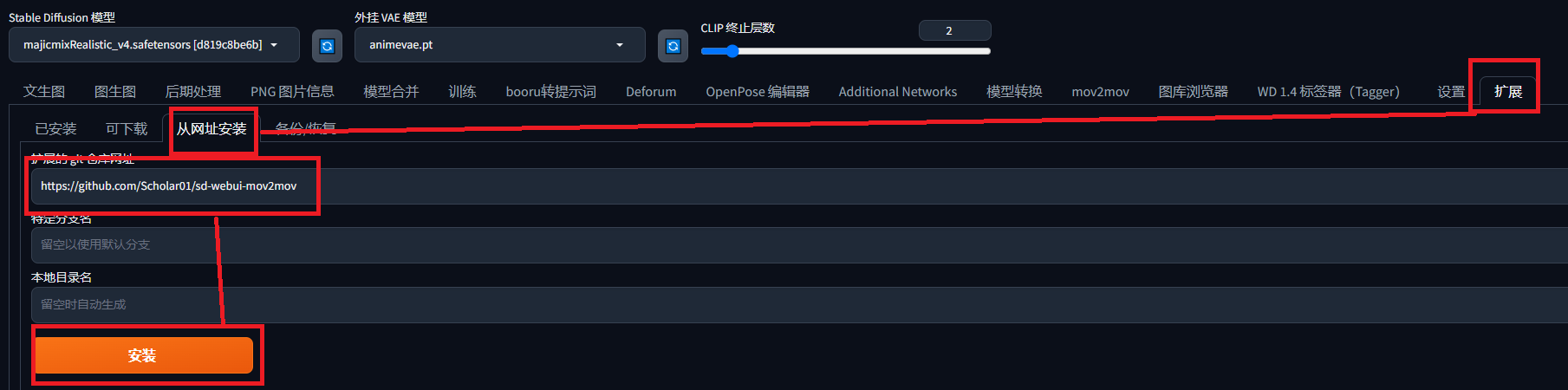
2.sd-webui-mov2mov(AI视频转换)
https://github.com/Scholar01/sd-webui-mov2mov
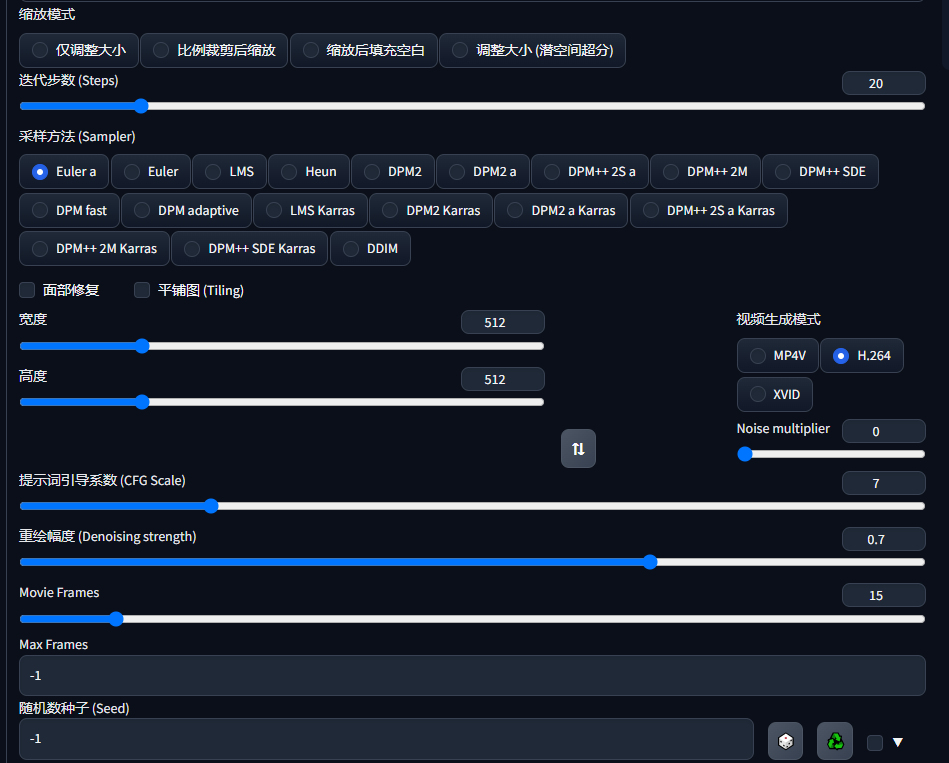
参数如下:感觉没有40显卡玩不了,如果显卡比较好,可以试试(movie frame为每秒视频帧数)
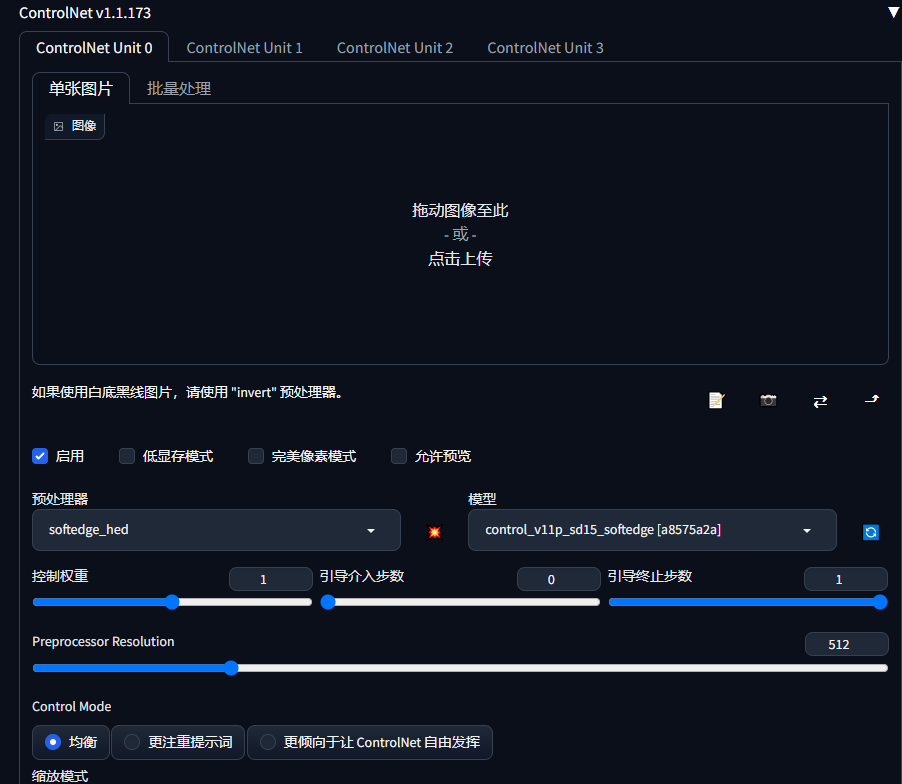
3.Deforum
直接在扩展搜索安装
使用参数如下,我只给出改了的部分,其他默认,最大帧数就是你要制作多少帧的视频,模型可以选择在第几帧开始使用哪个大模型,必须自已已经安装的,图片大小自己看着办,显卡好可以往上调
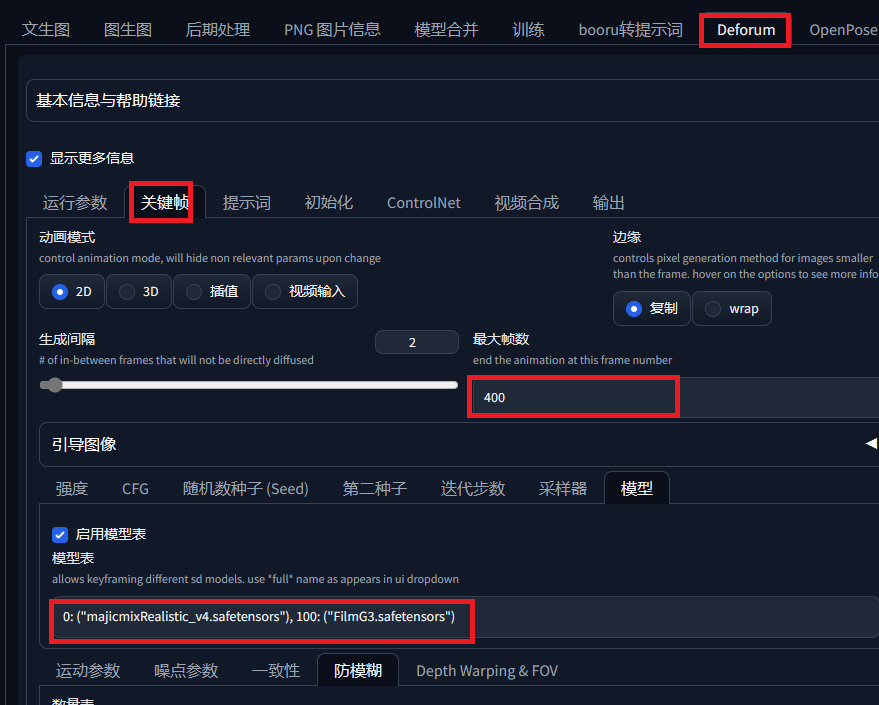
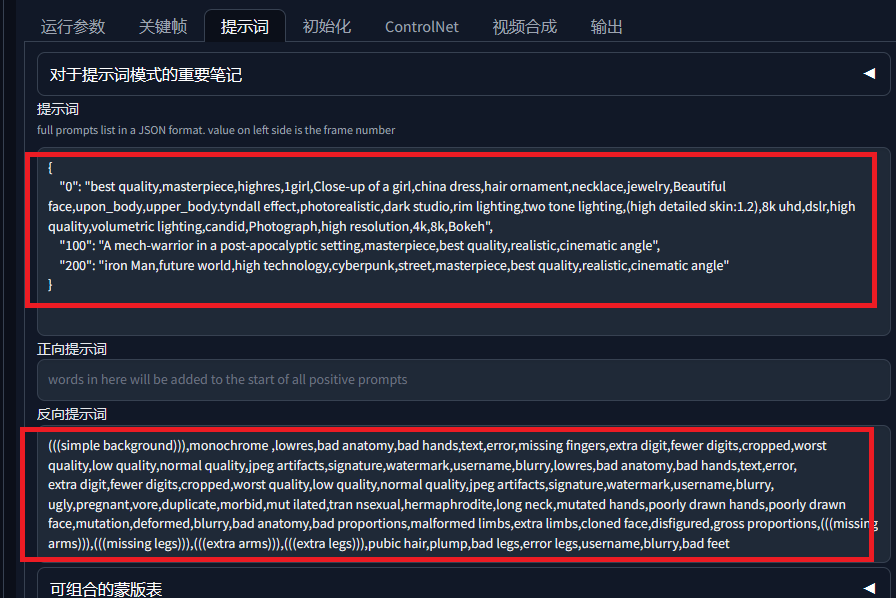
提示词我在,第0,100,200帧分别写了提示词,如果要改,按照格式改
运行参数就是控制镜头移动,xy控制上下左右,噪声越小,图片细腻度越高
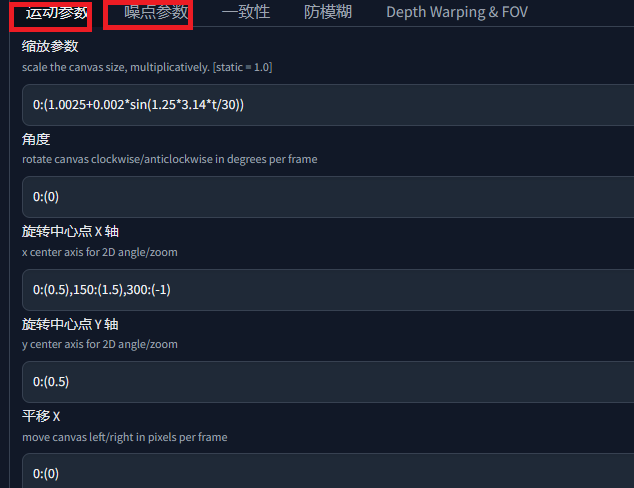
30为每秒的帧数,不保留中间生成图片,
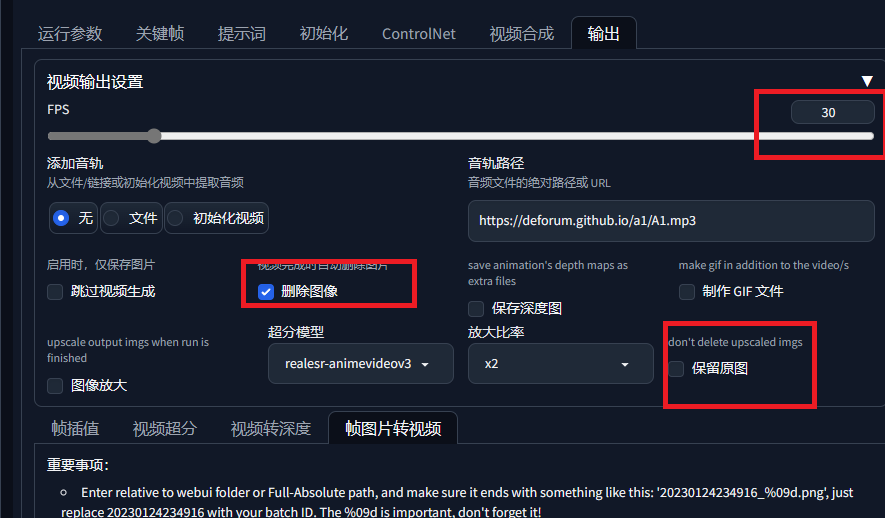
效果:https://www.bilibili.com/video/BV1TM4y1q7pp/?vd_source=69a72fa3fe0bf11ff1588ccaeb91737a
4.sd-dynamic-thresholding
支持使用更高的 CFG 比例而不会出现颜色问题
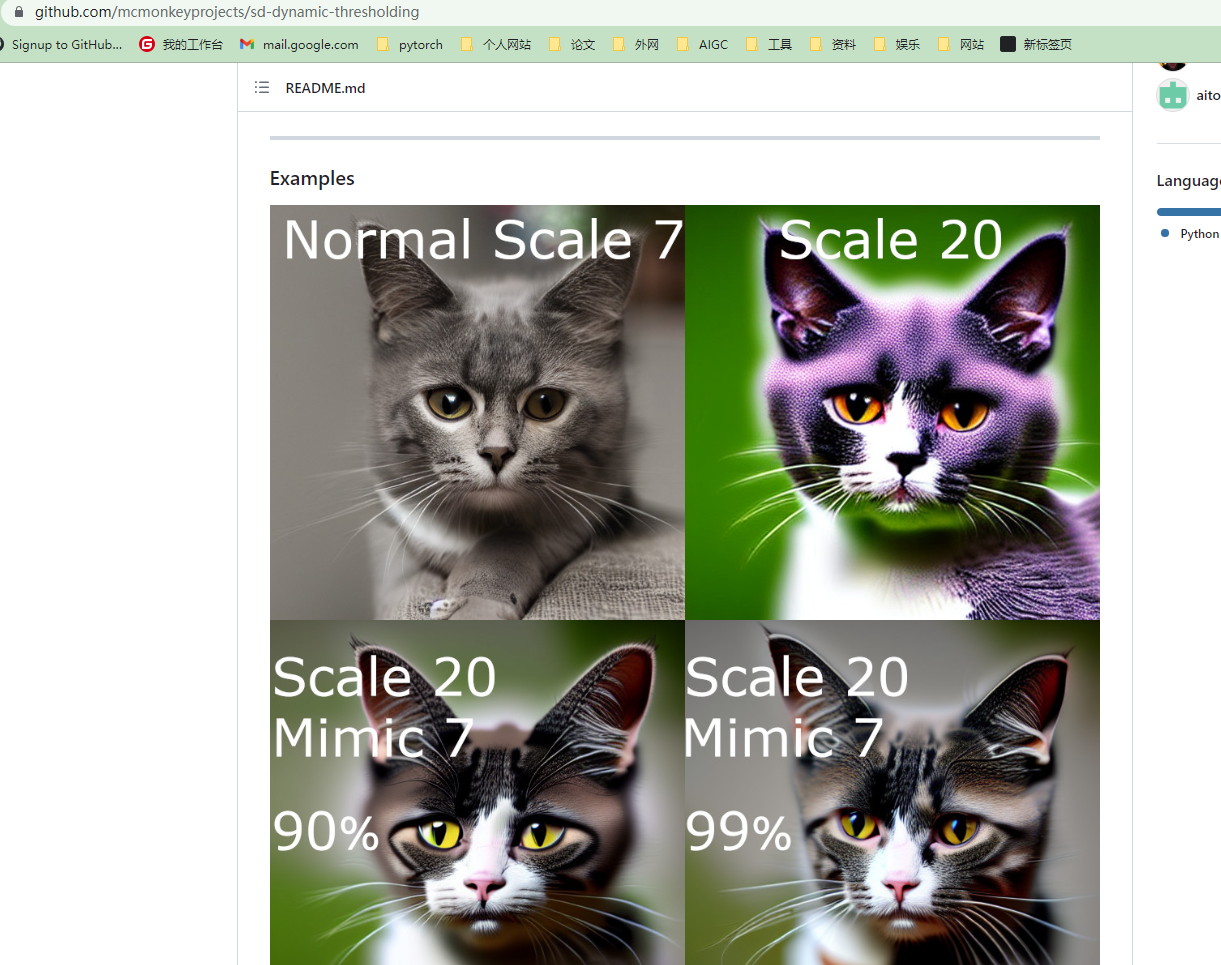
网址:https://github.com/mcmonkeyprojects/sd-dynamic-thresholding
在扩展页面网址安装,重启
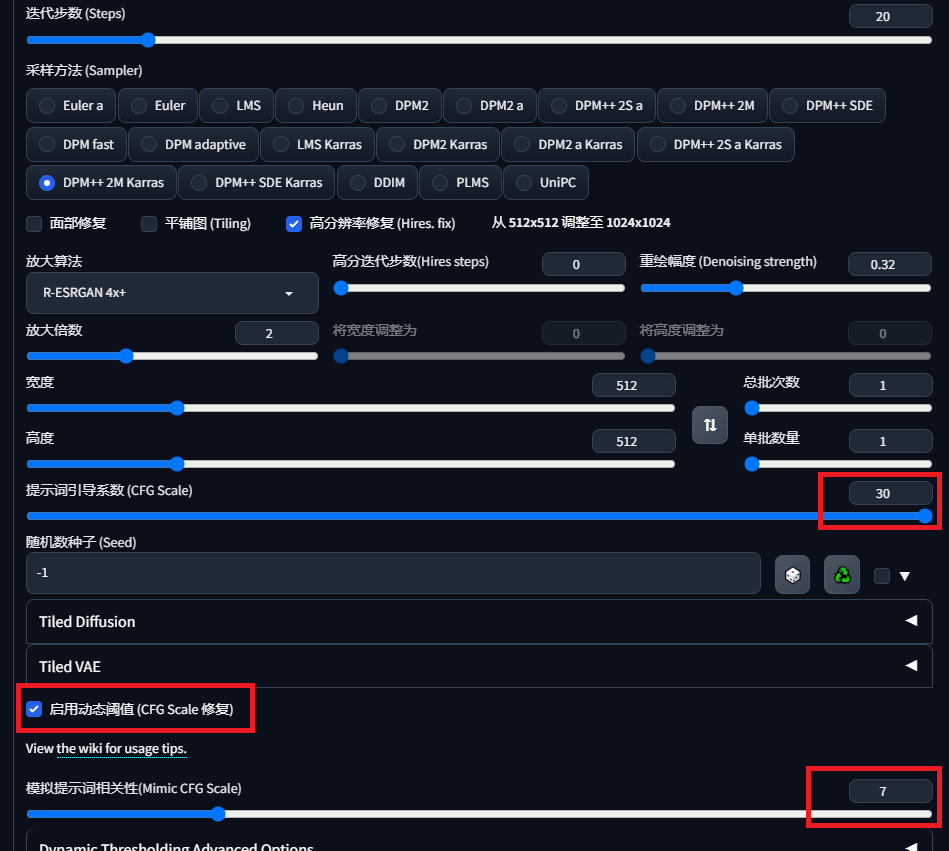
效果:可以在加大CFG同时增加更多细节而不崩坏 :
:
5.推荐一种生成AI视频的方法
准备好你的视频,下载pr,一款Adobe公司旗下的产品,处理视频的,ps处理照片的,把视频按照你想要的大小和格式导出,一般是720p,png格式导出,就是把视频一帧一帧取出,以图片方式放在文件夹
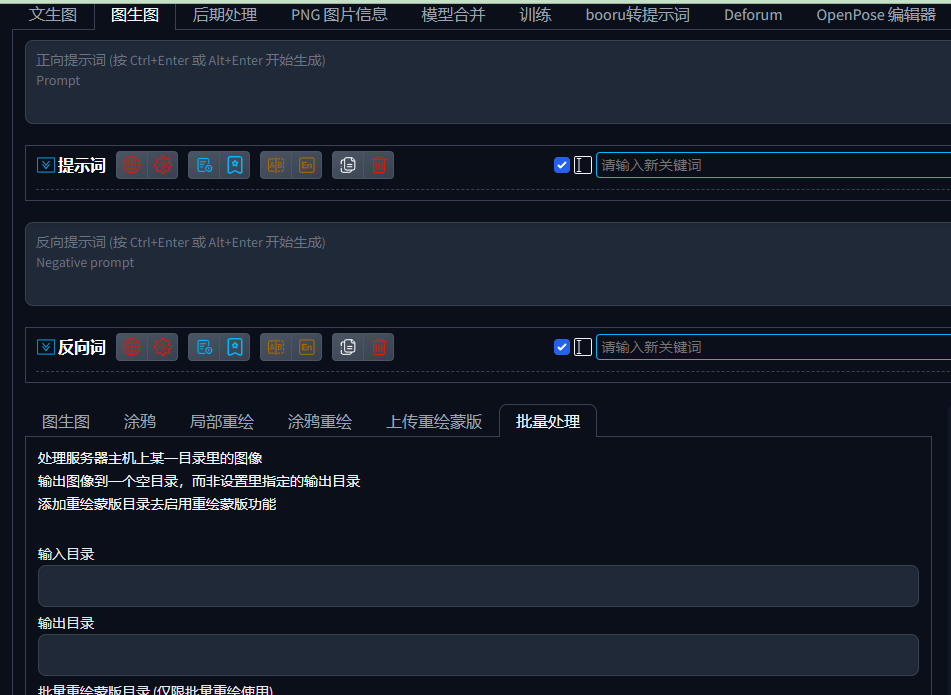
填写提示词,把输入目录(png目录),输出自己制定,就会把图片一帧一帧渲染,然后把渲染完的文件重新在pr组成视频。这种方法可能比上面对显卡要求低点。
6.Stable-Diffusion-Webui-Civitai-Helper
https://github.com/butaixianran/Stable-Diffusion-Webui-Civitai-Helper/blob/main/README.cn.md
老规矩,zip下载解压安装,扩展网址安装,还是git clone都行,
1.功能(官方文档)
- 扫描所有模型,从Civitai下载模型信息和预览图
- 通过civitai模型页面url,连接本地模型和civitai模型信息
- 通过Civitai模型页面url,下载模型(含信息和预览图)到SD目录或子目录。
- 下载支持断点续传
- 批量检查本地模型,在civitai上的新版本
- 直接下载新版本模型到SD模型目录内(含信息和预览图)
- 修改了内置的"Extra Network"模型卡片,每个卡片增加了如下功能按钮:
- 🖼: 修改文字"replace preview"为这个图标
- 🌐: 在新标签页打开这个模型的Civitai页面
- 💡: 一键添加这个模型的触发词到关键词输入框
- 🏷: 一键使用这个模型预览图所使用的关键词
- 以上额外功能按钮支持thumbnail模式
- 增加一直显示按钮的选项,以供触屏用户使用
2.使用
前往扩展页面"Civitai Helper",有个按钮叫:“Scan Model”

点击,就会扫描所有模型,生成SHA256码,用于从civitai获取模型信息和预览图。扫描需要很久,耐心等待。
每个模型,本扩展都会创建一个json文件,用来保存从civitai得到的模型信息。这个文件会保存在模型同目录下,名称为:“模型名字.civitai.info”。

如果模型信息文件已经存在,扫描时就会跳过这个模型。如果模型不是civitai的,就会创建个空信息文件,以避免以后重复扫描。
3.添加新模型
当你下载了新模型之后,只要再次点击扫描按钮即可。已经扫描过的文件不会重复扫描,会自动得到新模型的信息和预览图。无须重启SD webui。
模型卡片
(先完成扫描,再使用卡片功能)
打开SD webui’s 内置的 “Extra Network” 页面,显示模型卡片
扫描出错,civitai扩展最下面填入代理地址和端口
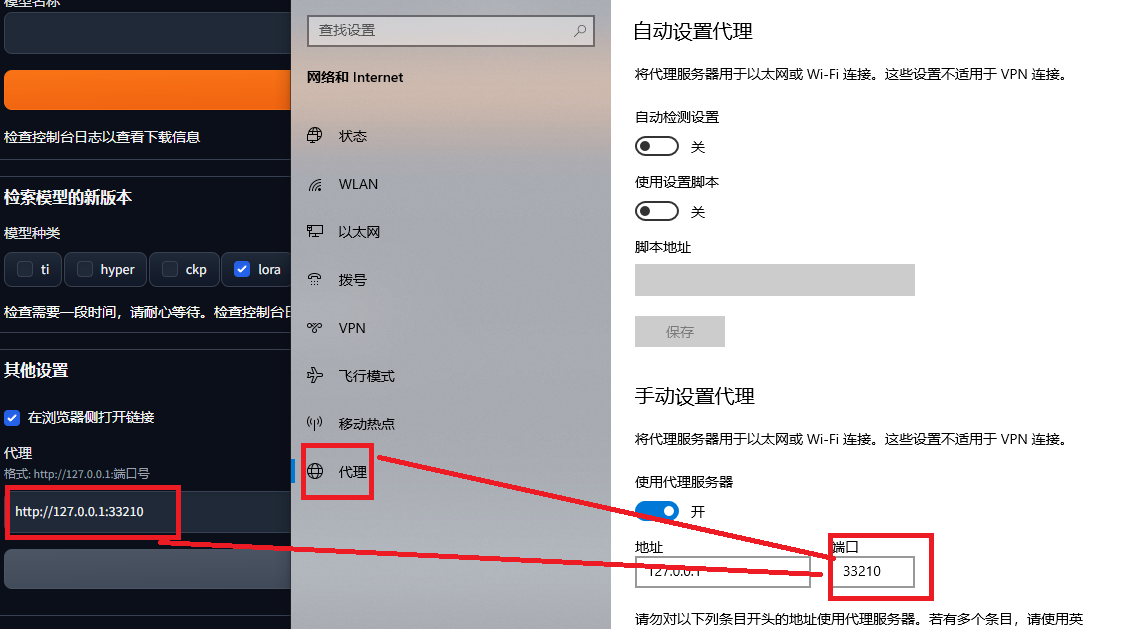
移动鼠标到模型卡片底部,就会显示4个按钮:
- 🖼: 修改文字"replace preview"为这个图标
- 🌐: 在新标签页打开这个模型的Civitai页面
- 💡: 一键添加这个模型的触发词到关键词输入框
- 🏷: 一键使用这个模型预览图所使用的关键词
如果你没有看到这些额外的按钮,只要点击Refresh Civitai Helper,他们就会被重新添加到卡片上。

每次当Extra Network刷新,他都会删除掉额外的修改,我们的按钮就会消失。这时你就需要点击Refresh Civitai Helper把这些功能添加回去。

4.小图模式
以上功能按钮支持小图模式,但受制于SD Webui的CSS问题,目前,只能要么一直显示,要么一直不显示,不能鼠标滑过才显示。

5.下载
(单任务,下载完一个再下另一个)
通过Civitai模型页面Url下载模型,要3个步骤:
- 填入url,点击按钮获取模型信息
- 扩展会自动填入模型名称和类型,你需要选择下载的子目录和模型版本。
- 点击下载

下载过程会显示在命令行界面带个进度条。
支持断点续传,无畏大文件。
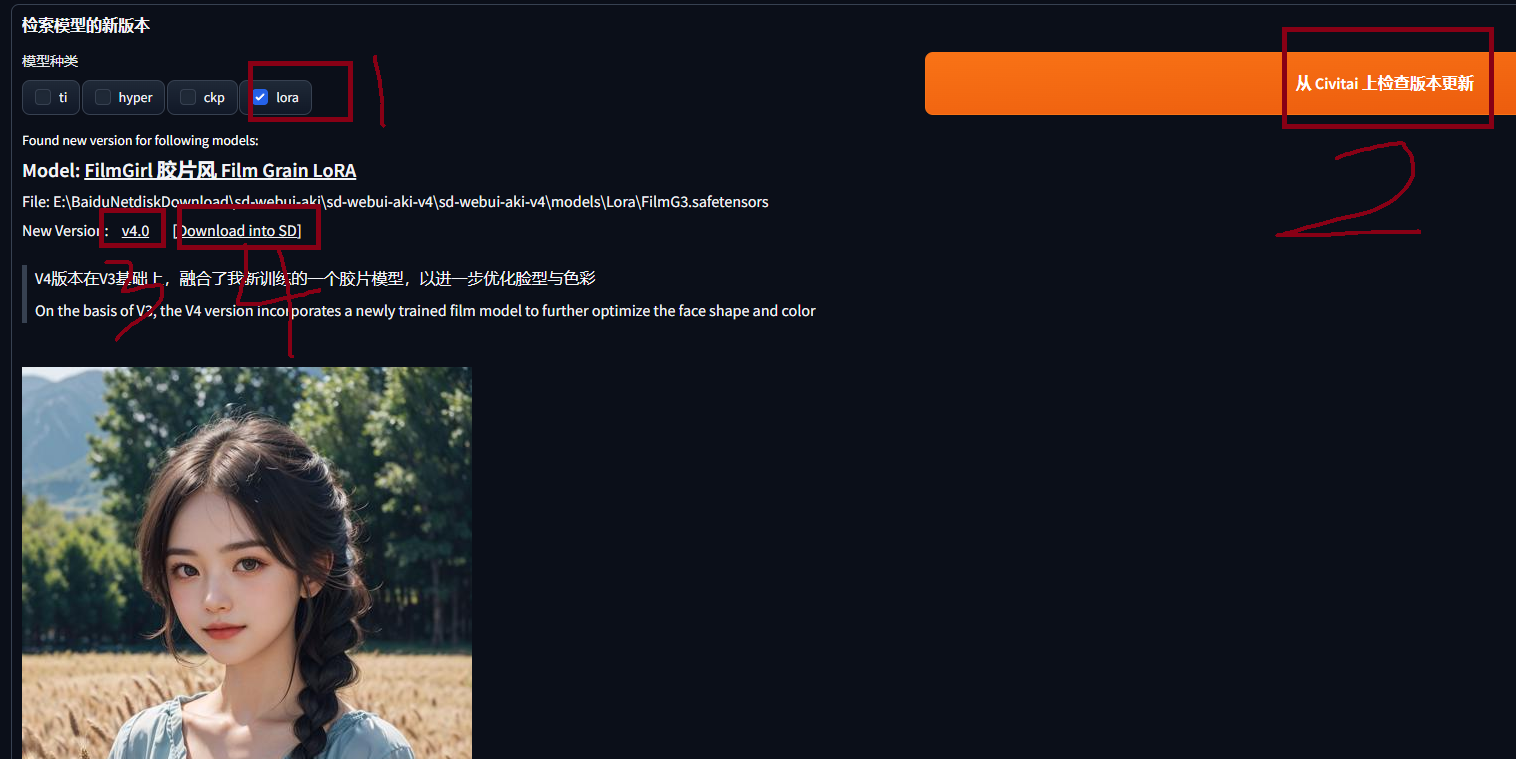
6.批量检查模型新版本
你可以按照模型类型,批量检查你的本地模型,在civitai上的新版本。你可以选择多个模型类型。
[
检查新版本的时候,每检查完一个模型,都会有一个1秒的延迟,所以速度有点慢。
这是为了保护Civitai避免因为本插件而短暂陷入类似DDos的局面。有些云服务商,有类似“免费用户每秒API请求不能超过1次”的保护机制。Civitai还没有这种设置。但我们还是得自觉保护它。因为如果它挂了,对大家都没有好处。
检查完毕之后,就会如下图,在UI上显示所有找到的新版本的信息。
每个模型新版本,都有3个链接。
- 第一个是这个模型的网页。
- 第二个是这个新版本的下载地址。
- 第三个是个按钮,在python端,直接下载新版本到模型目录内。
这种方式下载,下载详情显示在"Download Model"的区域和命令行窗口中。一次一个任务,不支持多任务。

7.根据URL获取模型信息
如果无法在civitai上找到你的模型的SHA256,但你还是希望能把你的模型连接到一个civitai模型,你可以在本扩展页面,从列表中选择你的模型,并提供一个civitai模型页面的url。
点击按钮之后,扩展就会下载那个civitai模型的信息,作为你这个本地模型的信息使用。

二、模型推荐
除了上一篇文章模型网站,现在国内也有了模型网站(模仿c站,但没c站全),方便下载不方便的伙伴
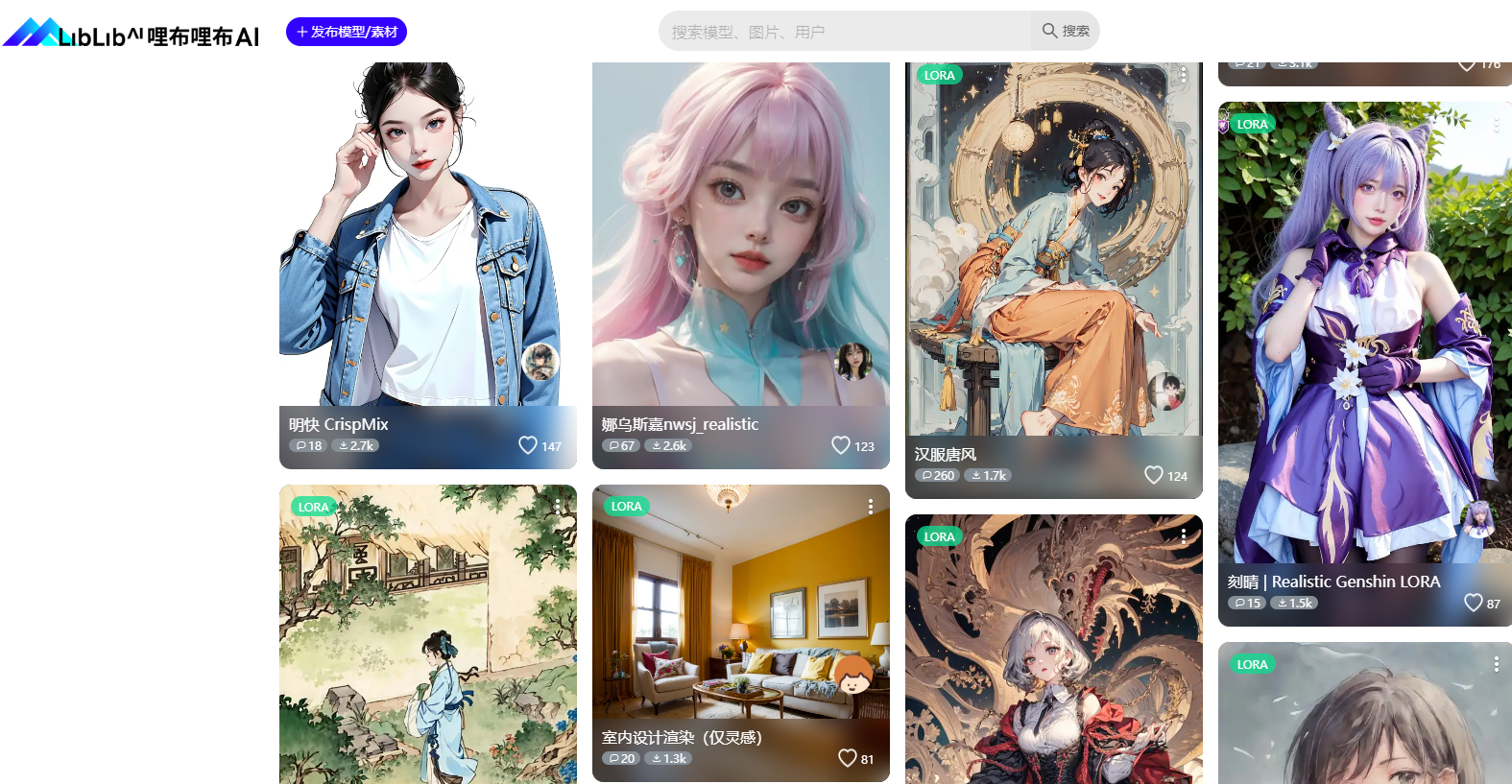
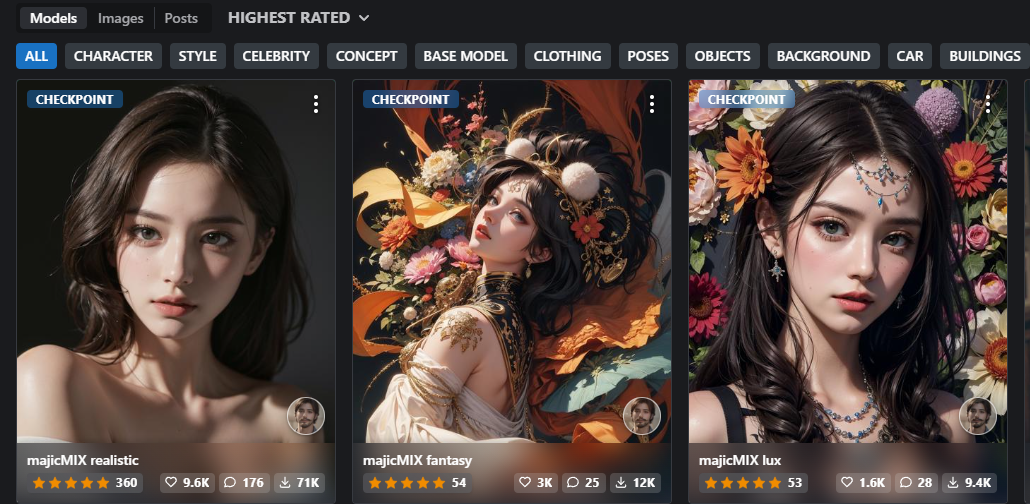
1.Majicmix_realistic 写实风格
2.Majicmix_fantastic绚丽异域

3.Majicmix_lux有点像两者结合
4.Dark Sushi Mix(人气比较高的模型)
三、controlnet使用技巧
1.tile+放大
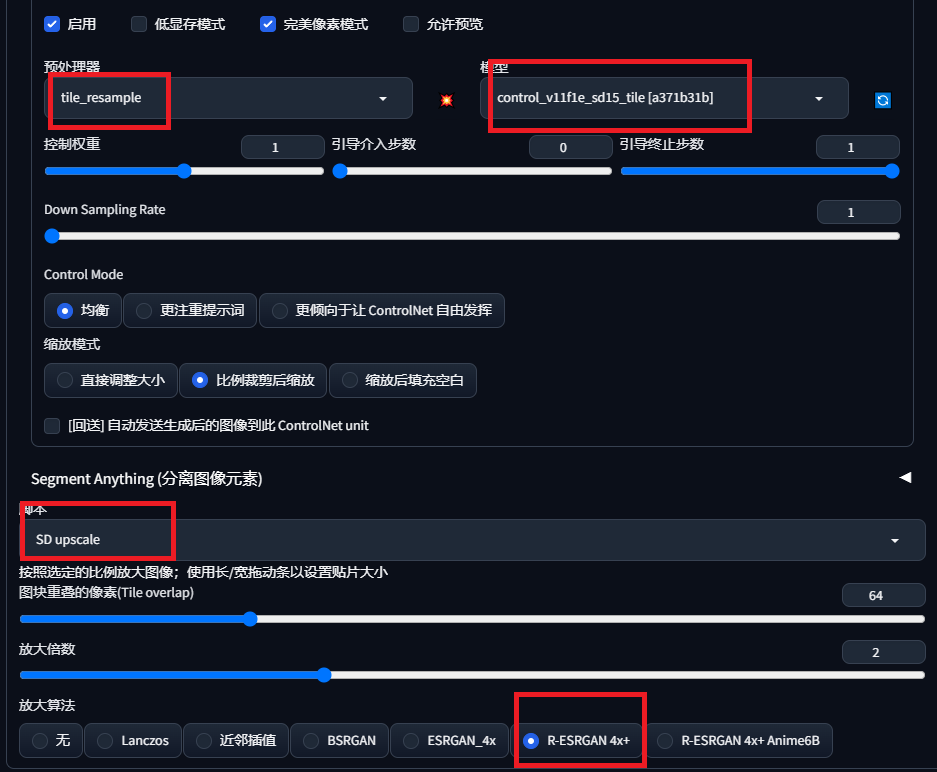
高清修复
2.tile风格转换

3.scribble_pidinet涂鸦手绘渲染(初试感觉效果很炸裂)
提示词:masterpiece,best quality,Digital Art Concept Car,High detail,4k,Industrial Design,beautiful background,Futurism,Seby Punk,Studio Lighting,Concept Art,Assembly,Fantasy Engine,Octane Rendering,Architectural Visualization,Architectural Rendering,surrealism,16k,Surreal,High detail,Clear car logo,
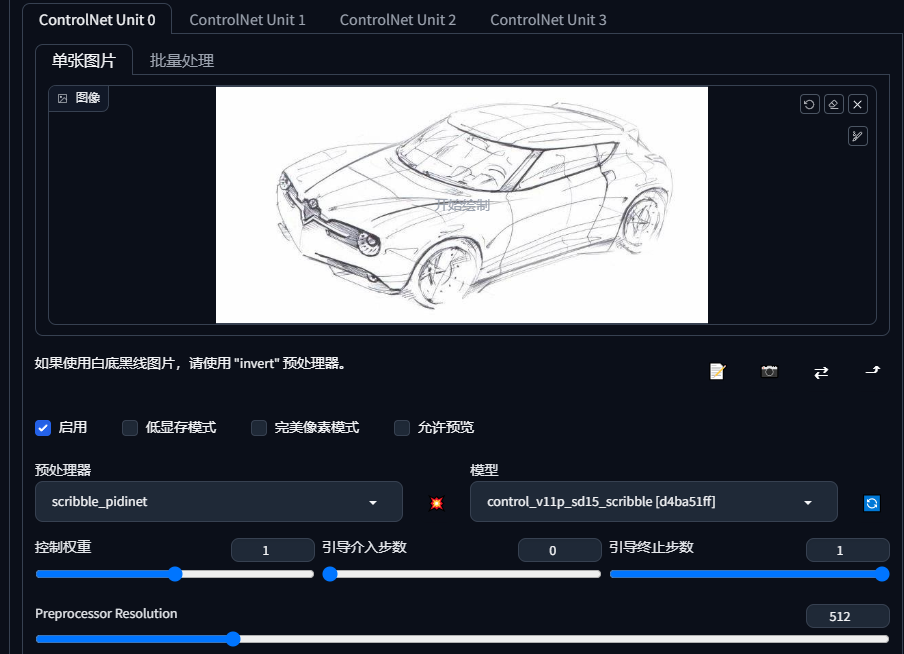

4.depth
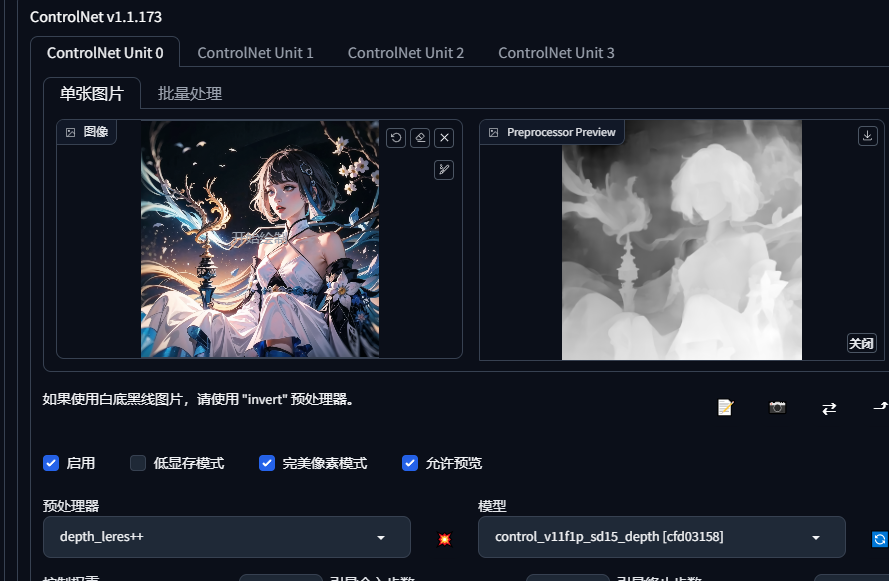
有的图片不方便展示,老是被提示,看我网站
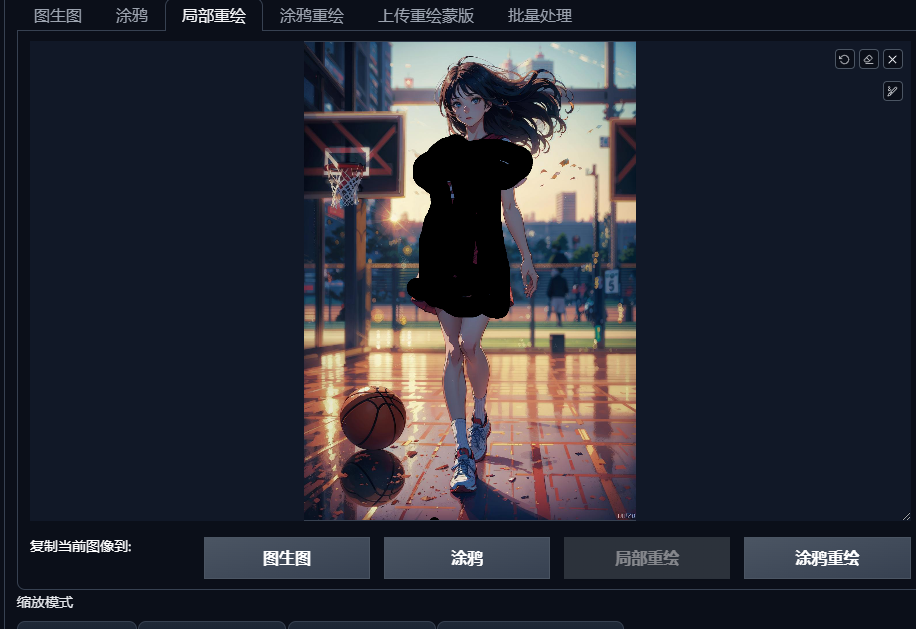
5.图生图局部重绘

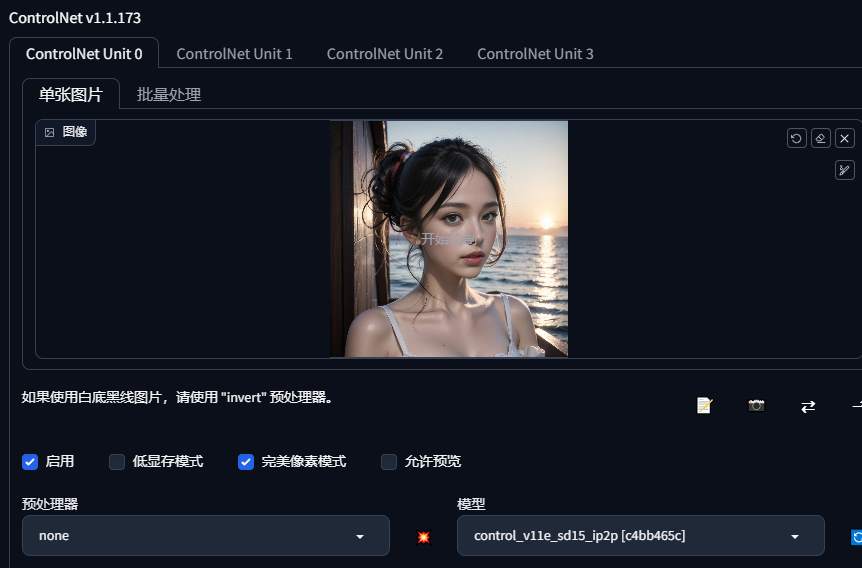
6.pix2pix
可以根据提示词转换天气,重绘幅度减一点
 ](https://tianfeng.space/wp-content/uploads/2023/05/uTools_1684381083944.png)
](https://tianfeng.space/wp-content/uploads/2023/05/uTools_1684381083944.png)

7.seg
也是目标物体分割的一种算法,之前说一个插件sd-webui-segment-anything,这个可以对人物手动分割部分做改动,这个就是偏室内设计这种(人物效果好像一般),有室内设计可以下一个设计大模型,然后做风格转变,这边没下大模型,不做演示
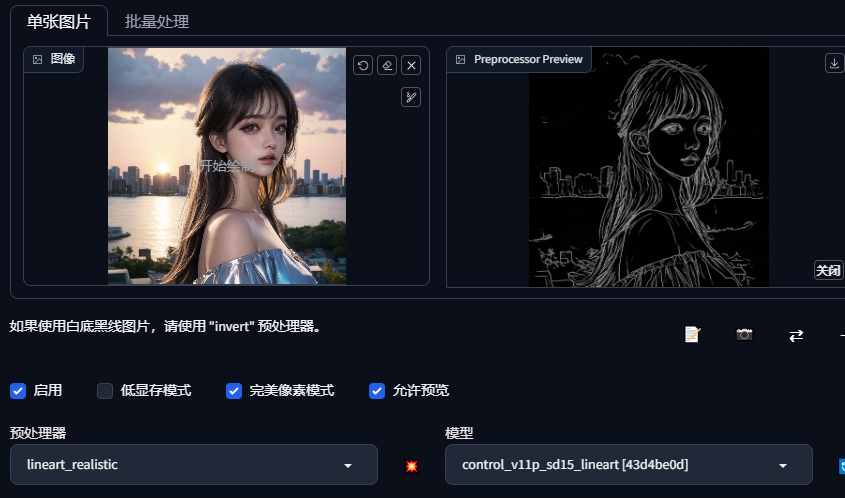
8.canny和linear
canny边缘检测算法通过一个阈值区间来选取人物边缘的线条,然后对提出的线条进行绘制,如果有线稿,可以不用预处理,可以直接controlnet进行处理
lineart边缘在绘画中的作用是定义和分离不同的形状和元素,使画面更加清晰和易于理解。它还可以增强绘画的立体感和深度感。(这个更好用一点,自己尝试看看)
还有很多边缘检测算法hed等等,都可以试试,通过预处理提取线稿,controlnet画图

四、总结
本文介绍一些常用的插件,很适合新手宝宝,还有推荐一些大模型,已经绘图的一些技巧,希望对你们有帮助。
















 939
939











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











