






 文章讲述了考研考生在复习过程中对数据结构、逻辑与物理存储、线性表、链表、栈与队列、数组、字符串处理、树与图理论等IT技术的理解和回顾,包括哈夫曼树、红黑树等高级概念,以及CPU、指令系统和I/O控制的相关内容。
文章讲述了考研考生在复习过程中对数据结构、逻辑与物理存储、线性表、链表、栈与队列、数组、字符串处理、树与图理论等IT技术的理解和回顾,包括哈夫曼树、红黑树等高级概念,以及CPU、指令系统和I/O控制的相关内容。
资料来源:抓码计算机考研(免费)
代码随想录:代码随想录 (programmercarl.com)
今年应届生11408专业课考砸了:341分,408就90分,双非二本跨考昨天晚上拿到调剂复试,未来不知如何,但仍需要坚持下去。408的书我已经看了很多的遍了,可能确实是脑子不聪明,最后考得不好。也可能是对大题的忽视,导致大题得分不好,也可能是985梦太美好,自身能力确实不足。数学也才103分,离自己的目标差了20分,但是回想考研历程,自己的基础确实不好,很难达到那个高度。然后一志愿也不过线,调剂理想学校也要92本,准备许久的机试也是作用不大,人生如戏啊!在12月底完成初试后,一个字没有看,昨天晚上突然了解到调剂学校要问408,这三天赶紧复习一下,此贴大量图片加个人了解,希望能在记录本人复习过程的细节以方便查阅,也能帮助到后来的同学!
考研之路太过坎坷,人生也是起起落落,望12日下午能如愿以偿!
只要意志不认输,没有打败我的,只能使我更强大!
1.数据结构
1.1数据结构概述
简单的就不说了,主要是逻辑结构与存储结构的区分,以及对应类别。
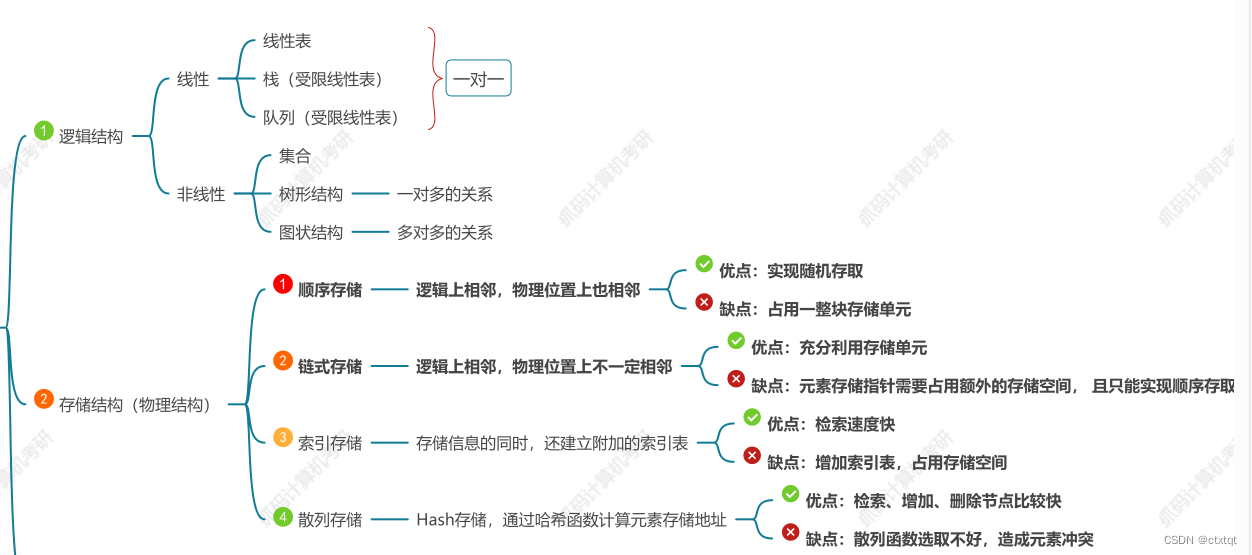
1.1.1逻辑结构:
为了解决问题而出现的一种逻辑上存在的数据结构,比如线性表、 栈、队列。比如说栈,它的先进先出、后进后出其实在计算机内存中都是不存在的,只是我们用人类的逻辑去限制它的运算。再比如说结构体,显然也是一种数据结构,如果是存储着一个student的学号、姓名,但我们认为只要去student.id,就可以获得计算机存储的对应student学号,但这些操作都是编程语言给我们提供的,实际上还是在内存中的一个一个按序排列的存储单元,按照某种方法将其读出的。
线性逻辑结构:线性表、栈、队列
非线性结构:集合、树、图
1.1.2物理结构:
即在内存中数据存放的方式。主要的有顺序存储、链式存储、索引存储、散列存储。
顺序存储:数组
链式存储:链表,用一个next指向下一个存储单元
索引存储:比如说用一个数组记录另外一个数组的中数值为负数的下标
散列存储:哈希表,通过hash函数去进行元素存储地址。比如说找出数组a中重复的数,用空间换时间的想法去完成即可,设置一个大数组b去记录b[a[i]]的值,找出大于1的即可。
1.1.3时间复杂度和空间复杂度:
主要是看循环,没有循环一般为O(1)。有时会有递归,但是递归就去计算被调用函数执行了几次即可。
常见量级比较如下:

1.2线性表和链表:
其实不是特别难,但是要多动手去写,对于基本操作要会写。比如说删除、插入,都要判断该表是否为空或已满。
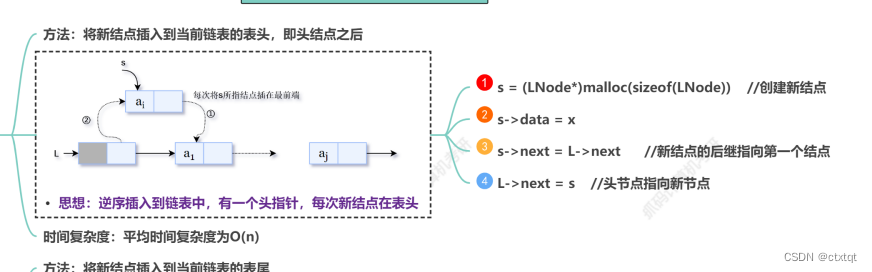
比较难的就是头插法与删除节点i,我的理解是去看一遍代码,然后自己写出来就好啦。

还有特殊的链表:双链表、循环链表、静态链表:
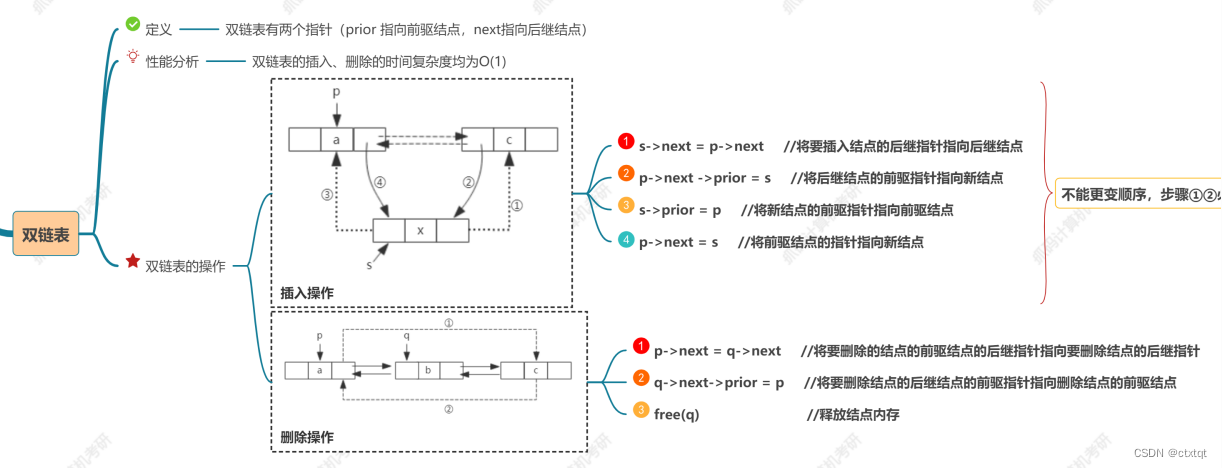
注意循环单链表是最后一个结点的指针指向头结点,可以想象一下。循环双链表同理,头指向尾,尾指向头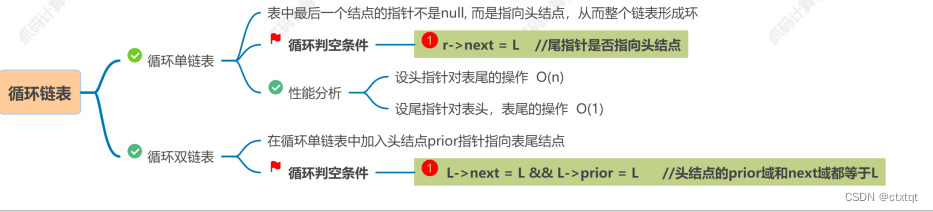
1.3栈与队列:
其实栈只要记住先进后出、后进先出就好啦,其他知识都不难,主要是应用。对了把栈想象为一个开口向下的长方形,top指针是指向栈底的。
队列也是,后进后出、先进先出。
还有一个共享栈,就是把0号栈放左边,1号栈放右边。当top1- 1 = top0时栈满。
1.3.1循环队列:
难点,主要是如何去分析。
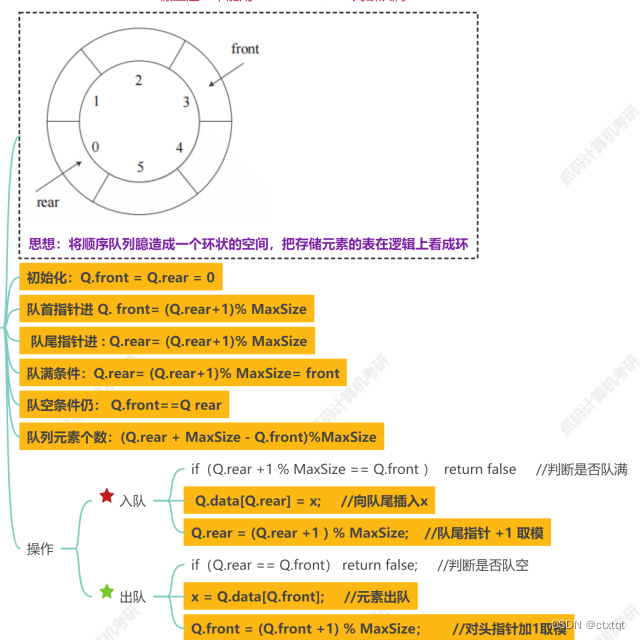
其实循环队列是一个顺序表,只是逻辑上实现为一个循环的队列。我们要知道front与rear的本质是什么,front一定指向的是队头、rear一定指向的是队尾(而且是队尾下一个位置)。所以实际上就不太用关注它们的下标,而是要关注他们两个的差值。如果rear比front小,并不是出错了,而是front可能因为出队移动到了很靠近MaxSize这种位置, 而rear因为加入元素而到了3号这种位置。所以此时计算队中元素,应该是front-rear。但有时会出现rear == front这种问题,我们可以想象,要么队满要么队长为 MaxSize - 1,但是我们很难去判断是哪种,所以比较好的方法是用一个变量去记录长度或者留一个空位,这样当两个指针相遇的时候,就是为空,不可能爆队的,因为入队时我们会限制Q.rear + 1对MaxSize取模不能等于front。
1.3.2 双端队列:
Python collections中的deque,允许两边输入输出。
1.4数组:
主要是压缩存储,但复试不太可能会考。对于初试来说,主要是会模拟存储的过程,自己就可以推导公式了。然后还有一些特殊矩阵,学过线代应该都了解。还有稀疏矩阵的存储方法:数组存储和十字链表存储法。
1.5串以及KMP算法:
C++的string,python的string类型。不难,但是KMP算法难!
KMP算法就是用子串去匹配主串,如果是暴力匹配,时间复杂度就为O(m*n)。如果用KMP,就是O(m+n)
主要是next数组求法,手动我会,就是求前后缀最大长度。但是对于代码,我只能死记硬背,真的理解不了这个过程。
附上代码随想录的代码:
class Solution:
def getNext(self, next, s):
j = -1
next[0] = j
for i in range(1, len(s)):
while j >= 0 and s[i] != s[j+1]:
j = next[j]
if s[i] == s[j+1]:
j += 1
next[i] = j
def strStr(self, haystack: str, needle: str) -> int:
if not needle:
return 0
next = [0] * len(needle)
self.getNext(next, needle)
j = -1
for i in range(len(haystack)):
while j >= 0 and haystack[i] != needle[j+1]:
j = next[j]
if haystack[i] == needle[j+1]:
j += 1
if j == len(needle) - 1:
return i - len(needle) + 1
return -1可以简单的理解为三个步骤,初始化、处理前后缀相同、不同的情况。如果是将前缀表-1,就是让next[0]=-1。如果不匹配且j>=0,就让j=next[j],即前后缀不同,相同的时候就是j+=1,然后跳出循环时就让next[i]=j。具体匹配的时候,就将s[i]换成主串就好了,删除 next[i]=j即可。
1.6树与二叉树:
1.6.1前中后序的递归和迭代、层序遍历的迭代算法:
以前序迭代为例:
用一个栈,按照右左前的顺序入栈即可,并在当前节点入栈后插入None,然后整体node为None时,就出栈。这个算法可以理解为标记了先要出栈的节点,相比于王道书上的要好记得多,当然,也是代码随想录的方法!
def PreOrderTraversal(root):
stack = []
res = []
stack.append(root)
while stack:
node = stack.pop()
if node:
if node.right:
res.append(node.right)
if node.left:
stack.append(node.left)
stack.append(node)
stack.append(None)
else:
node = stack.pop()
res.append(node.val)
return res层序遍历:
用一个队列存放当前一层元素,然后用一个for循环访问当前一层节点,并且让这层所有节点的左右孩子一个一个入栈。
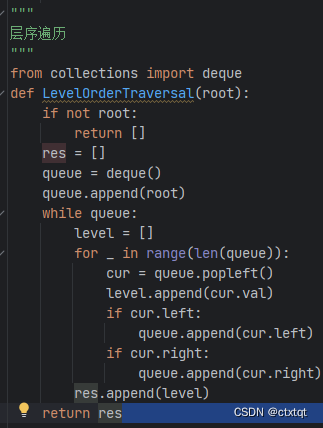
1.6.2完全二叉树:
即按照层序遍历的方式遍历,最后一个节点的父节点的下一个右兄弟一定没有孩子,即度为1的节点只能为1或0。为1的时候最后一个节点没有右兄弟,为0的时候,即节点个数为奇数时。
1.6.3线索二叉树:
代码不算重要,但是概念很重要左右tag为0时,指向的是左右节点,tag为1时,指向的是前驱或后继。由于是按序列来构建线索的,所以自然有前中后构造方法,但是记住前中后序遍历方法,其实不难。暴力一点的方法就是用一个pre记录上一个节点。
1.6.4树和森林:
双亲表示法:对一个节点设置一个指针指向其双亲节点。顺序存储
孩子表示法:链式存储,将每个结点的孩子节点练成一个单链表
孩子兄弟表示法:即左孩子表示第一个孩子,右孩子表示下一个兄弟
至于树和森林的遍历与用孩子兄弟表示法所表示的二叉树的遍历的转换关系:只要模拟一下,牢记孩子兄弟表示法,应该是比较好理解。
1.6.5二叉排序树:
一句话,左子树节点的所有值>根节点的值>右子树节点的值,对该树进行中序遍历可以得到有序序列。
主要是构造算法:
设置两个函数,一个用于找打插入位置(递归),一个用于遍历有序序列。
1.6.6平衡二叉树:
对于复试不难,就是一句话,任何一个结点的左右子树高度之差的绝对值不能大于1。
但对于初试而言,就是插入操作:
但如果你会思考的话,其实不用记,只要你能把他通过旋转操作,转换为平衡二叉树,其实都是对的。
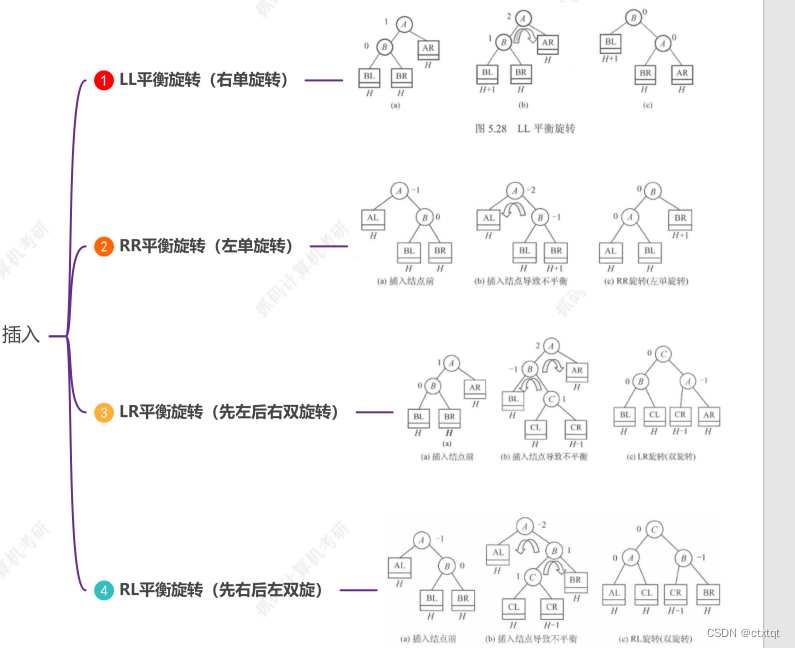
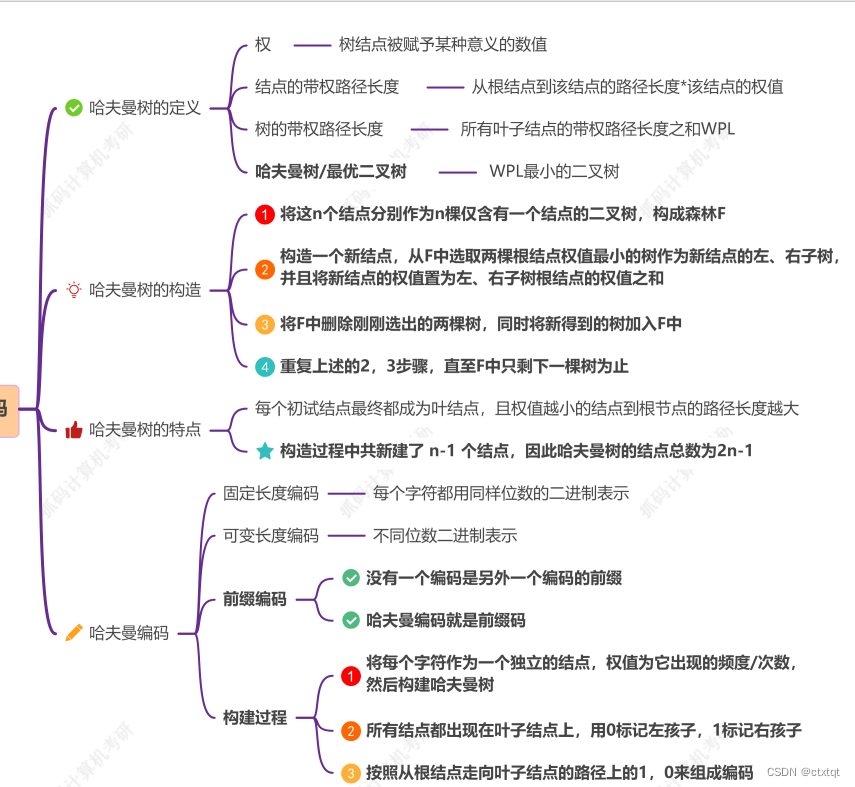
1.6.7哈夫曼树:
不多说,记住就好:
在构造哈夫曼树时,在选择最小结点时一定要记得加上已构造二叉树的根结点哦!
1.6.8红黑树:
我感觉是不重要,24好像没考。只要记住基本性质就好了,查找时间复杂度为(log2n):

1.7图:
复试重难点!
1.7.1重要概念:
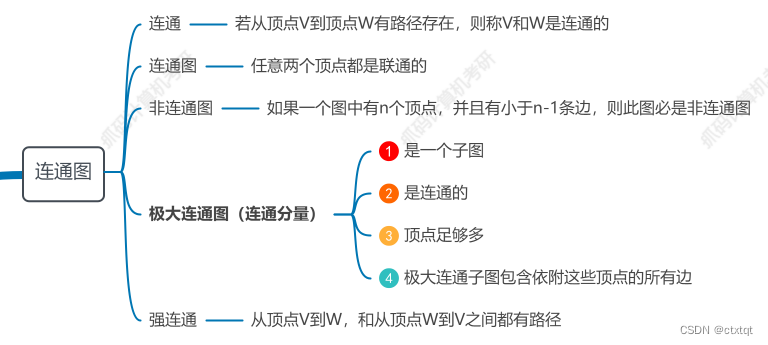
与极大连通对应的是极小连通图。极小连通图是子图且边尽可能少的连通图。
1.7.2存储结构:
邻接矩阵法:主对角线上的元素值均为0,然后一般是对称矩阵。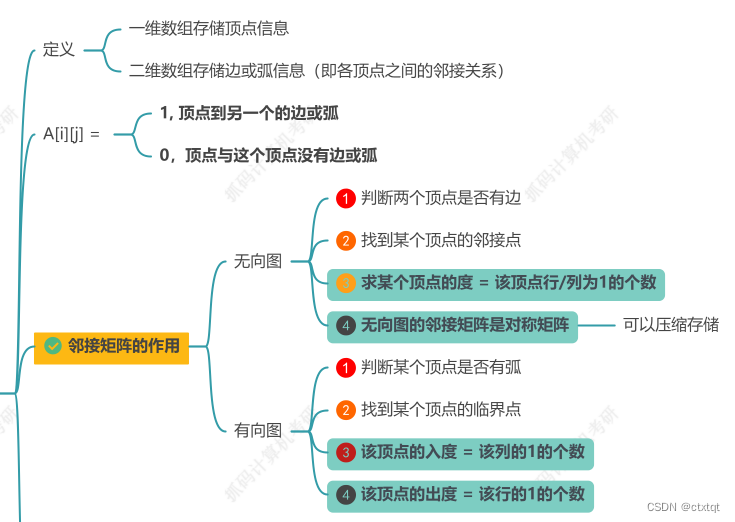
邻接表
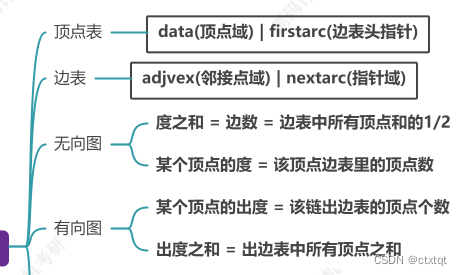
十字链表:有向图链式结构 邻接多重表:无向图链式结构
1.7.3广度优先遍历:
类似于树的层序遍历,用一个队列去存放结点,然后将这个结点的所有邻接点遍历完,并用visit数组进行标记,出队,遍历下一个邻接点。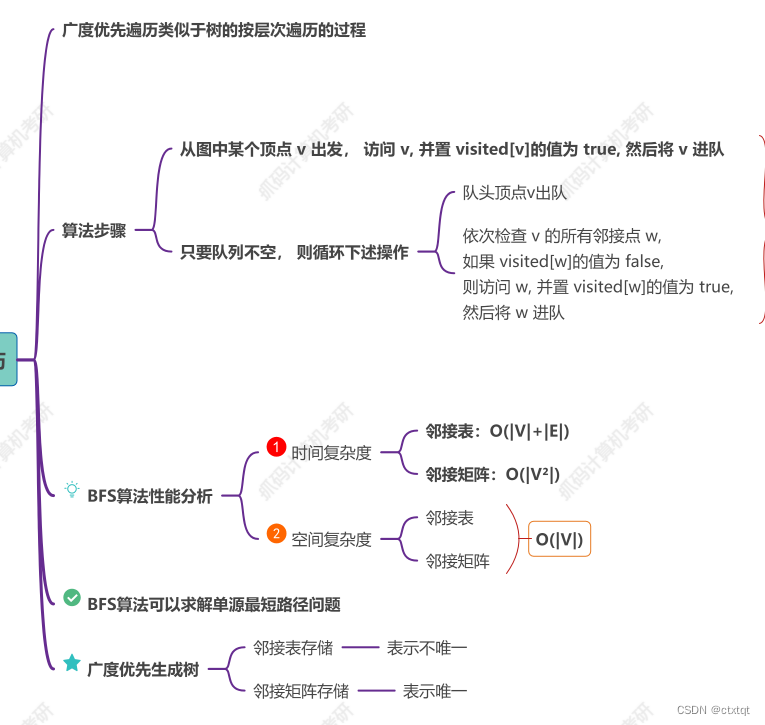
1.7.4深度优先遍历:
尽可能深的去遍历结点,类似于树的先序遍历。采用递归的方法,实现起来较为简单。

1.7.5图的应用:
最小生成树主要是:普里姆和克鲁斯卡尔算法。普里姆主要是一直选可连通的最小边,克鲁斯卡尔算法是选整个图的最小边。
迪杰斯特拉算法即是求最短路径的算法
弗洛伊德算法求每个顶点之间的最短路径问题。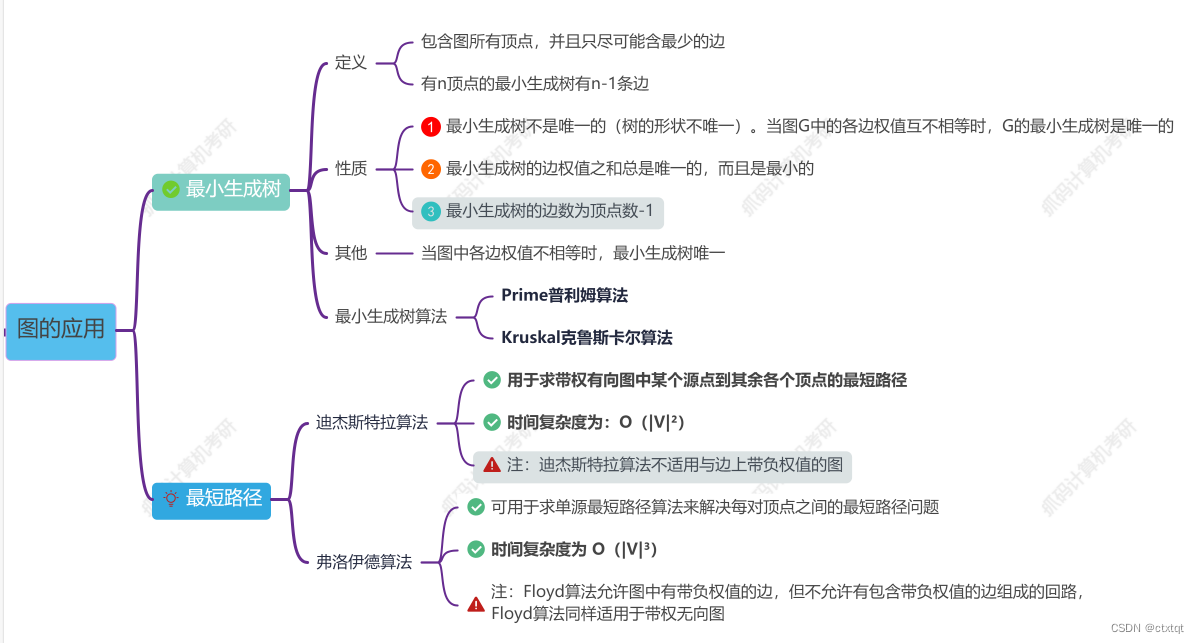
1.7.6拓扑排序:
主要是算法思想,每次选择一个入度为0的结点进行删除,删除以该点为起始边的所有有向边。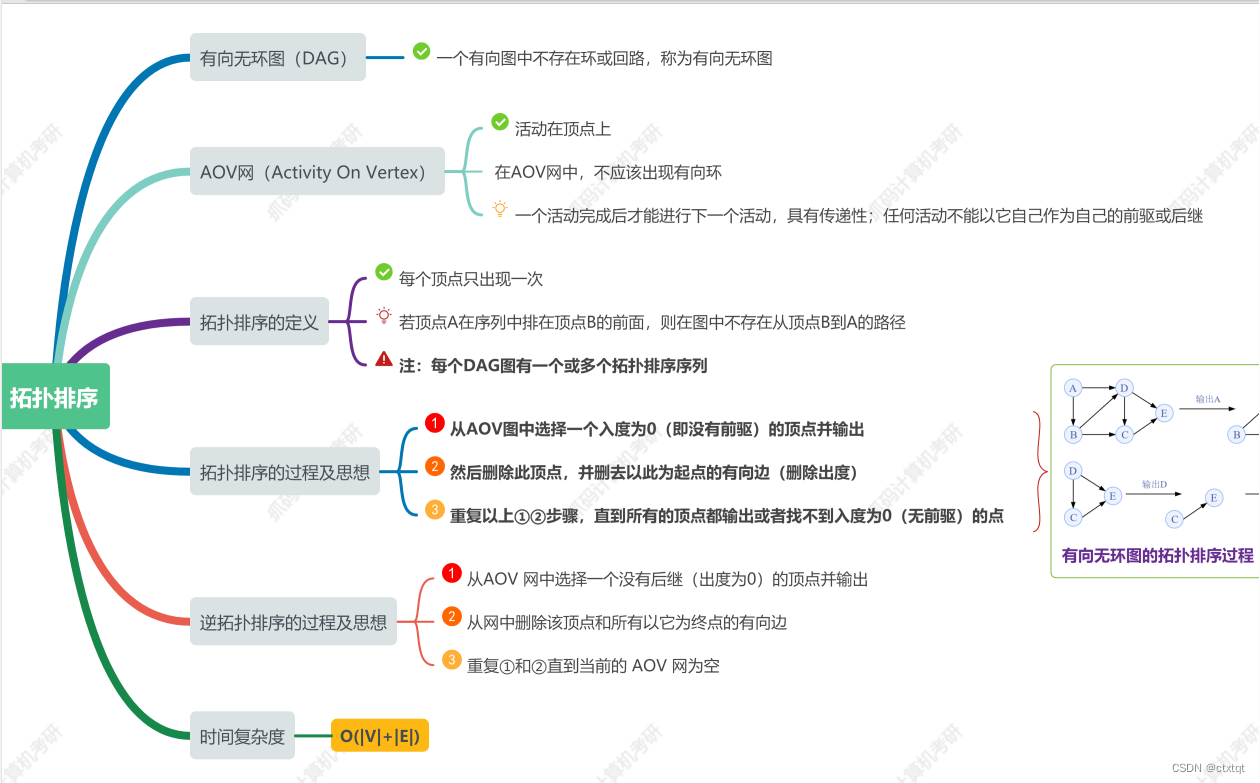 1.7.7关键路径:
1.7.7关键路径:
一般都是数值最大的那条路径,也是完成整个工程的最短时间。计算关键路径的方法,求Ve、Vi,Ve是最早、Vi是最晚事件发生实际。e是活动最早、I是活动最晚。活动的最迟-最早为0,则该条路径上的活动就是关键活动之一。按照拓扑排序的顺序,求出最早,逆拓扑排序求出最迟。e(i)其实就是起始边的顶点Vi,I(i)其实就是Ve减去对应边上的权值。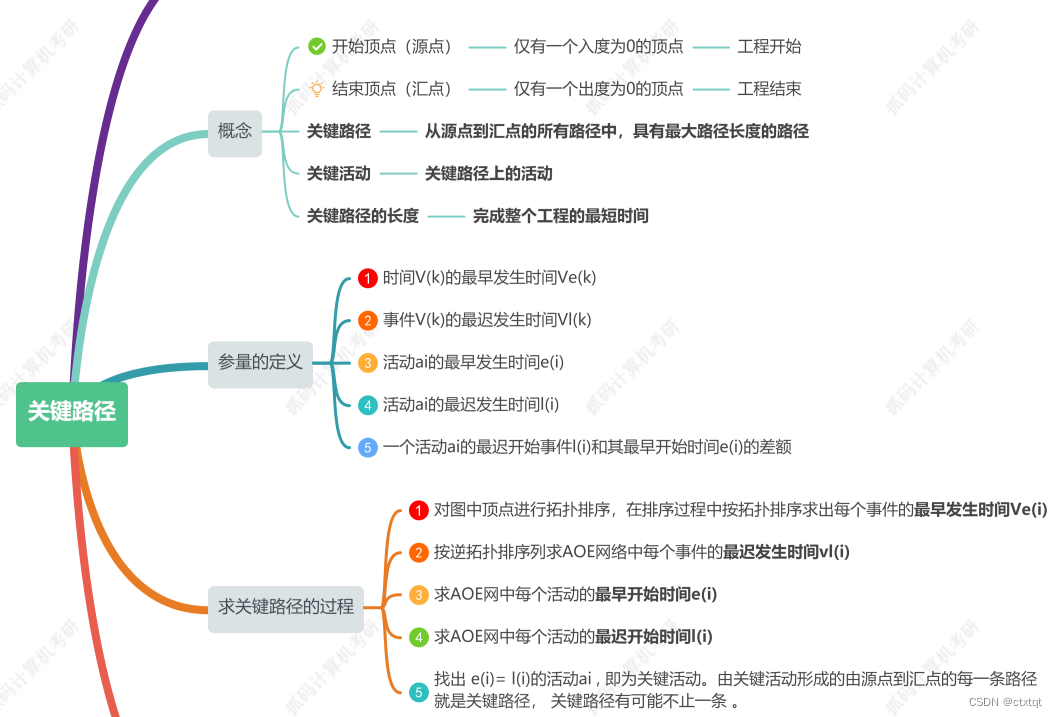
1.8查找
不太重要,主要是二分还有分块查找,还有B树、B+树和哈希查找。
B树、B+树复试不太可能会问,只要知道是B树一个平衡的查找树,是满二叉树,然后叶节点有序,B+树就是叶节点之间有指针。具体的插入删除:
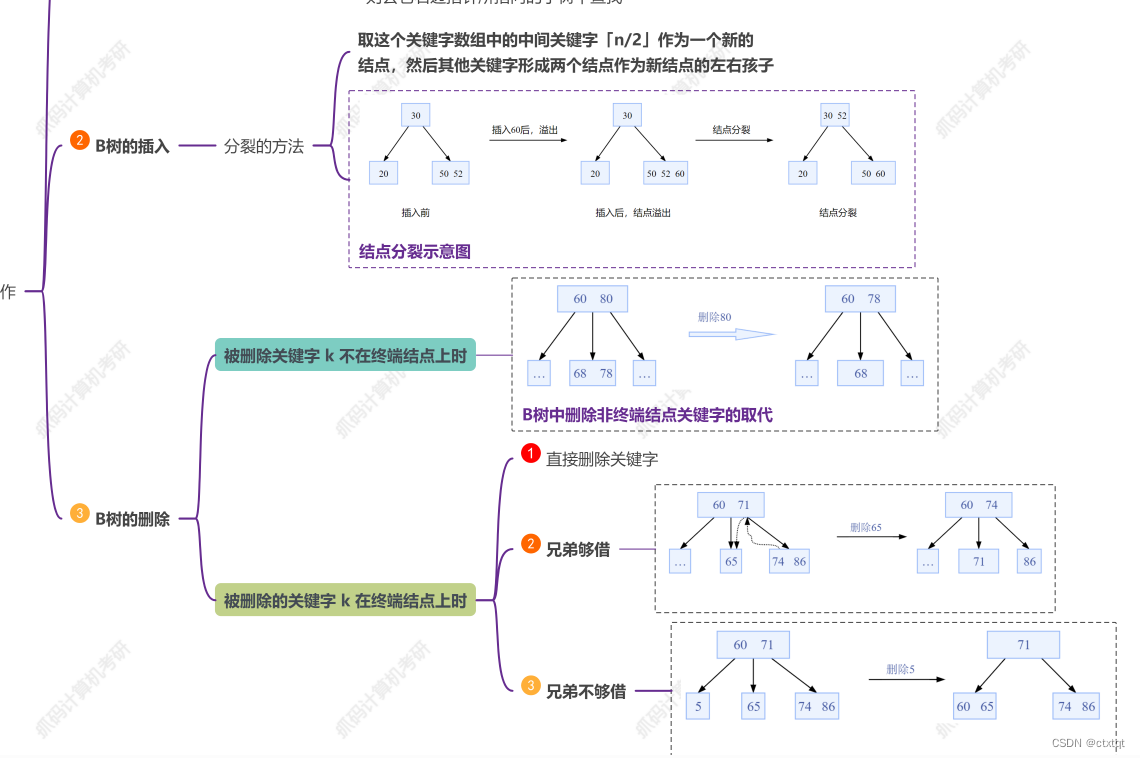
1.9九大排序:
因为python、c++现在都有sort了,其实具体实现肯定是很少,只有靠算法思想了。
插入排序:稳定:
即如果找到小于前驱的数,就查询其中该数可以插入的位置。也可以用二分法进行查找。

希尔排序,不稳定。即最开始把顺序表分为几个间隔相同的数据 ,然后进行插入排序。然后不断缩小间隔,直至整张表都有序。
冒泡,稳定:
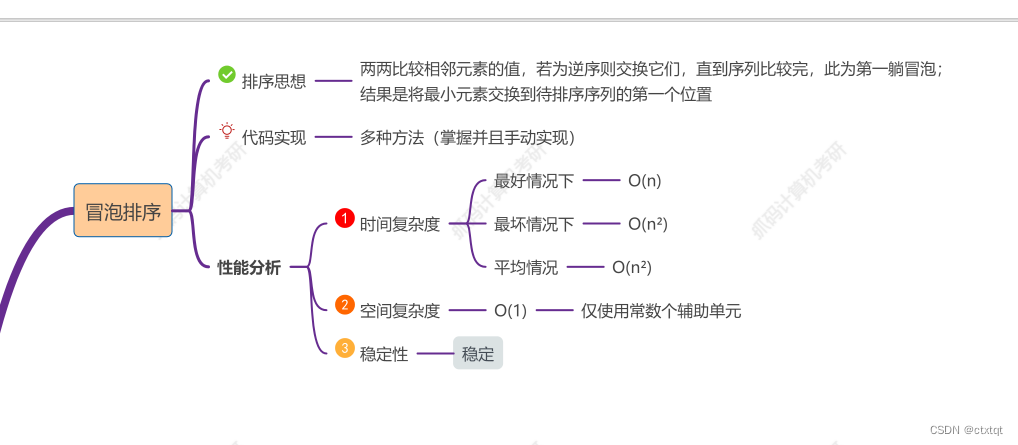
快排,重点,不稳定,最优:
先将整表进行初步排序,设置low、high,设置一个枢轴值,先找比枢轴值小,将其放左边,比枢轴值大的,放右边。然后进行递归,将high = 对应枢轴值下标减1,然后一直缩小high的范围,直至左边有序,然后将low按照初始枢轴位置不断加1,直至右边有序。
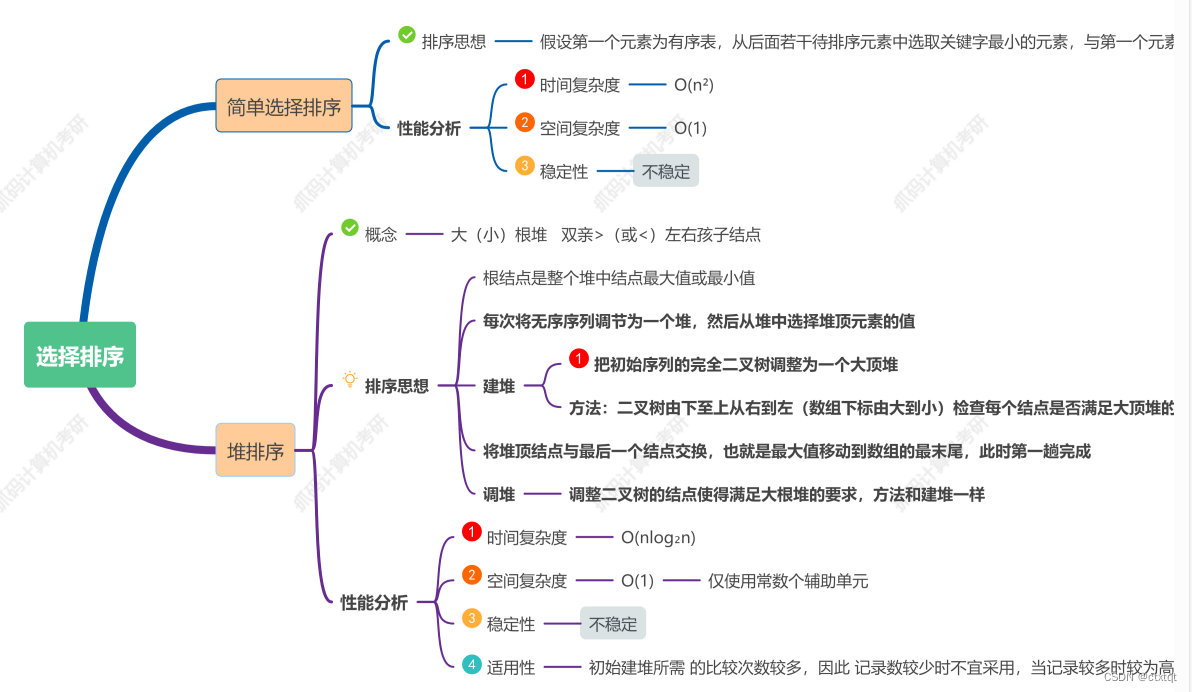
 选择排序、堆排,均不稳定:
选择排序、堆排,均不稳定:
归并排序,是唯一个复杂且稳定的算法:
用一个新数组去存放排序结果,即先用递归将序列划分为最小的单位,然后进行排序,直至整表有序。

这个思维导图的递归部分有问题,应该是:
MegreSort(A, low, mid - 1)
MegreSort(A, mid + 1, high) 基数排序:稳定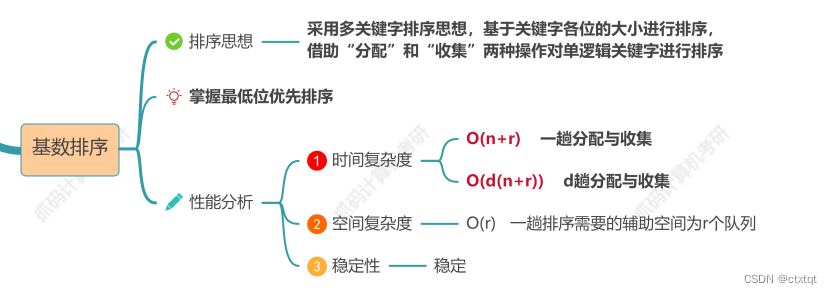
1.10:外部排序:
复试不太可能考,不太好描述过程。就知道:最佳归并树用哈夫曼树的思想实现、多路平衡归并与败者树实现置换选择排序。
2.计组
2.1计算机概述:
主要是时MAR与MDR的功能,MAR用于暂存从PC读出的地址,MDR暂存从主存读出或写入主存的数据。
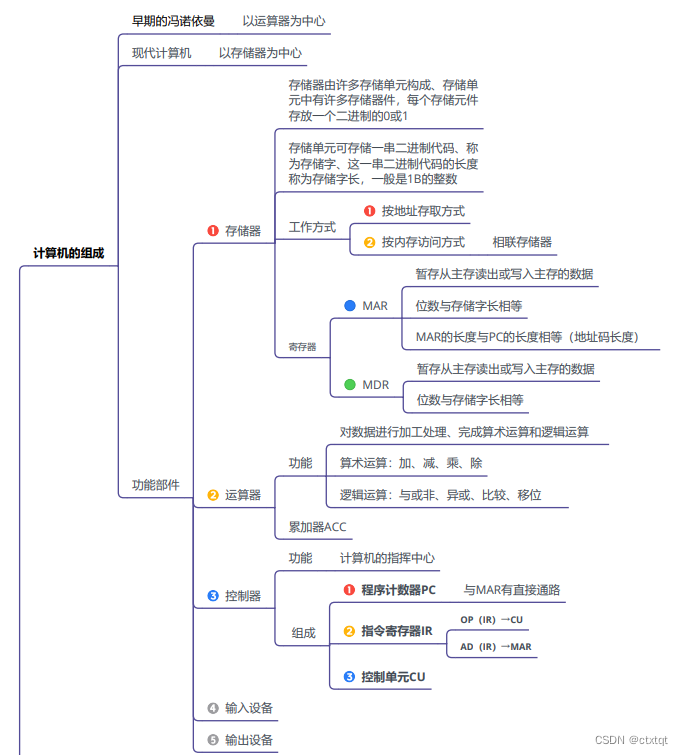
主要是计算机的工作过程,取指、译码、间址、执行、中断。
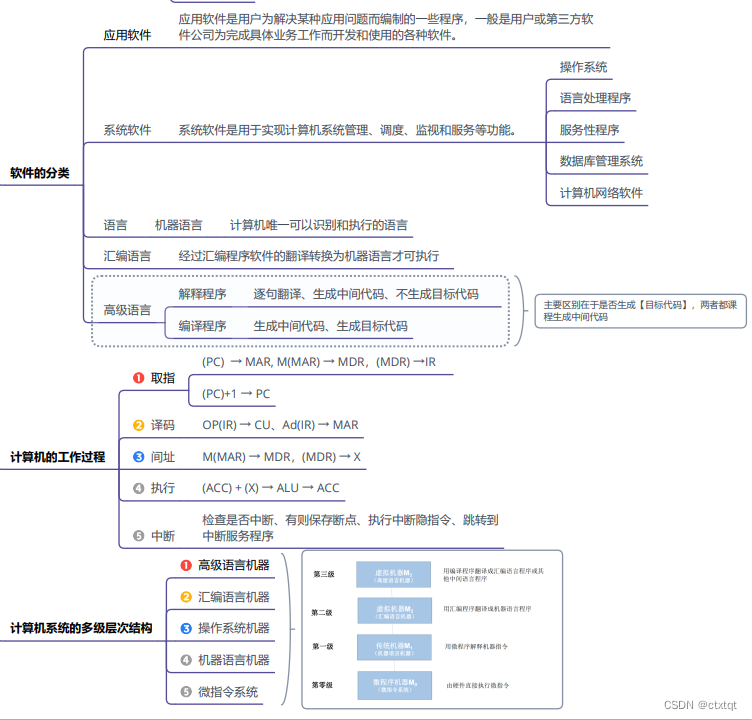
基本的衡量指标,主要是cpI、主频(时钟频率)、cpu执行时间(执行一个程序所花费的时间)。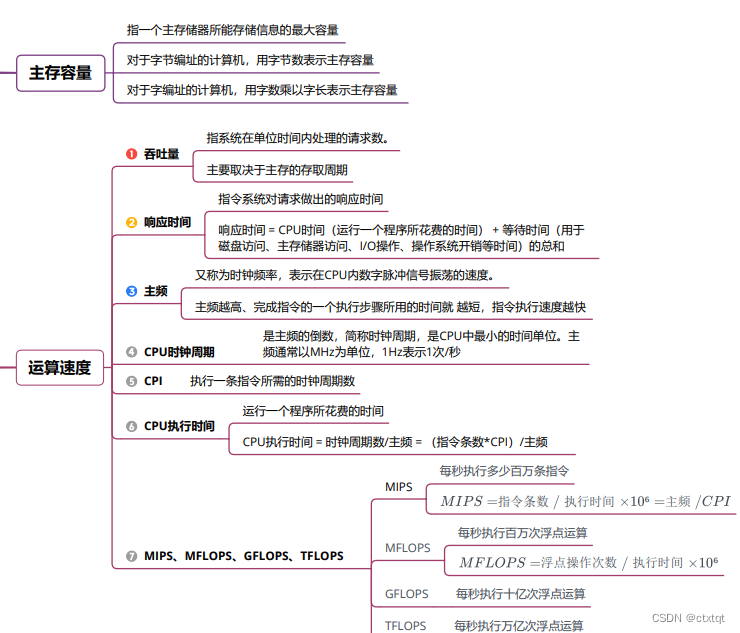
2.2数据表示与运算:
常见进制:二进制、八进制、十六进制。
真值,即我们正常生活中所用到的数字。
机器数,计算机内存存储的内容,一般是2进制。
主要是定点数的表示与运算,正数、负数的原码与补码之间的转化关系。
还有浮点数的IEEE754标准,运算过程:对阶、小阶向大阶看齐,尾数求和、规格化。

2.3存储器:
重点,SRAM与DRAM的区别,SRAM一般用来做cache、DRAM一般用来做大容量存储器。 ROM一般是是指只读存储器,但EPROM是可以擦除的。还有闪存存储器,可以快速进行擦除重写的存储器。
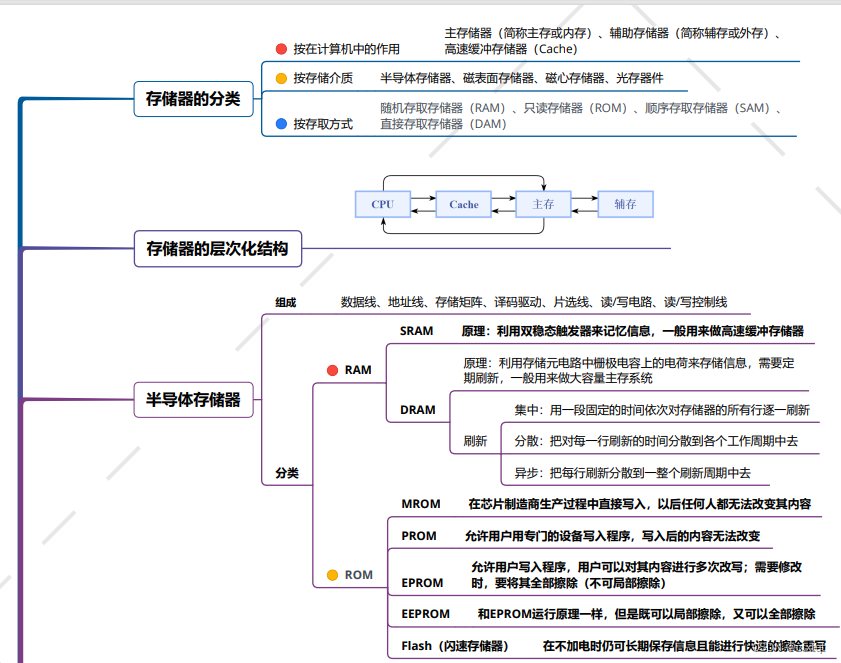
主存与CPU的连接,如果主存与CPU的连线是一一对应的就不用扩展。如果需要扩展,主要是位扩展、字扩展、字位扩展。位扩展指的是增加数据线位数即增加存储字长、字扩展指的是增加地址线位数,即存储单元个数。

外存:
主要是磁盘的性能指标计算。
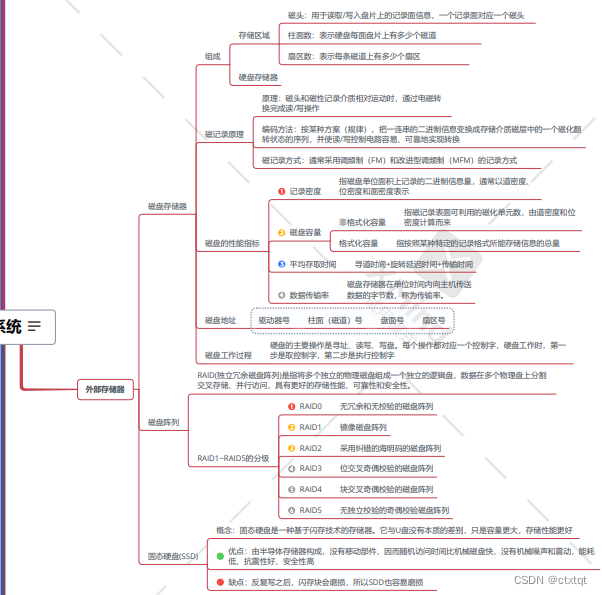
要理解低位交叉和高位交叉的区别,低位可以简单理解为横向访问存储器,高位可以理解为纵向访问存储器。低位交叉的低位地址为体号,高位地址为体内地址。对于高位交叉编址而言,则是相反的。

cache的常见算法,直接映射与全相联映射、组相联映射的地址映射与转换。
还有主要的替换算法,写策略:直写法(同时写回cache和主存),写回法(不写回主存,只有当cache数据被换出时才写回主存)。
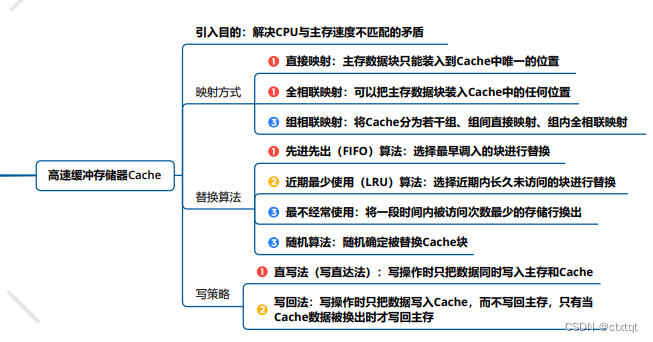
虚存:
主要是明白比如页式存储的虚拟地址转换为物理地址的过程,加入TLB的过程也要了解。

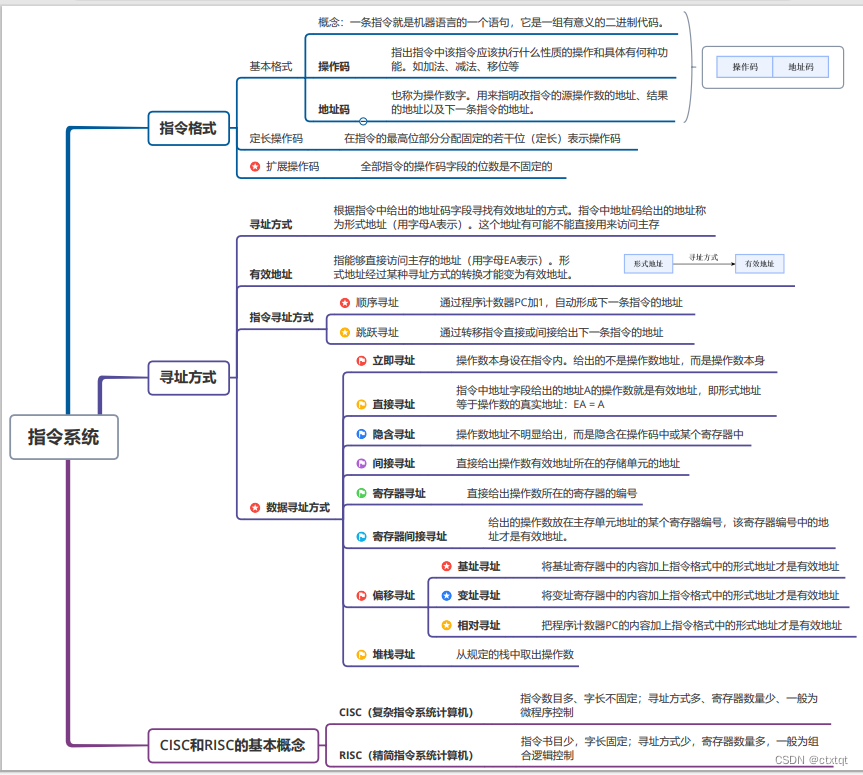
2.4指令系统 :
常见的数据寻址方式与指令的构成是重点。
指令中的形式地址是指令中的地址码部分,形式地址可以通过寻址方式转换为有效地址。
还有CISC和RISC的基本概念。CISC适用于微指令控制器,RISC适用于硬布线控制器。
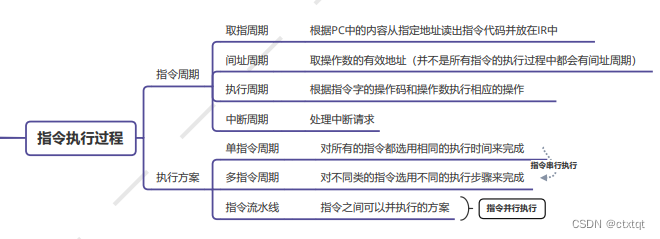
2.5CPU:
指令周期的四个阶段,还有执指令执行方式。
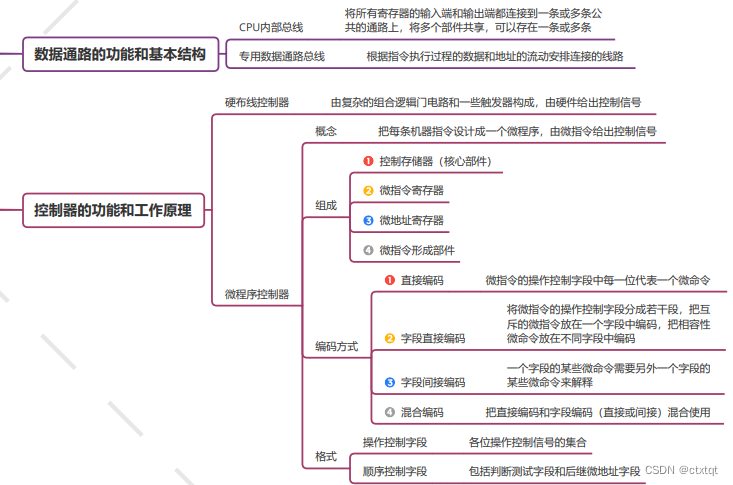
硬布线、微程序控制的特点。尤其是微程序控制器的组成、编码方式、指令格式。
异常与中断:
异常发生的位置、种类。中断的分类与发生的位置。

多处理器:
主要知道各个结构的代表,与对应类别。MISD是不存在的

指令流水线:
主要是分类、影响因素、性能指标、常见冒险的处理方式、多发技术,分类不太重要。
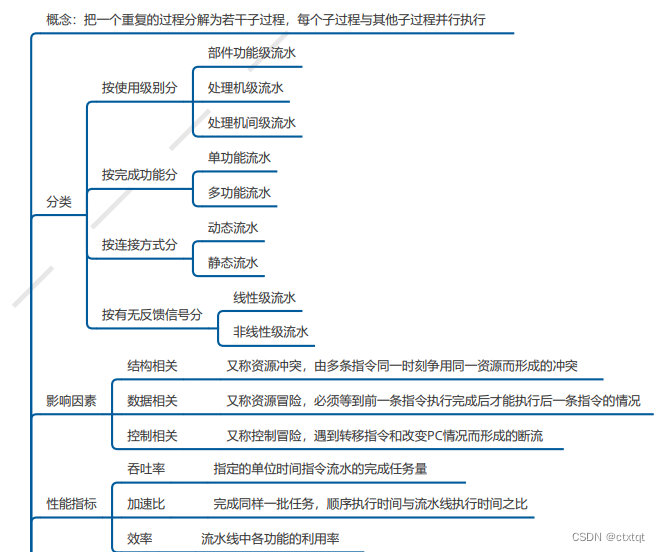
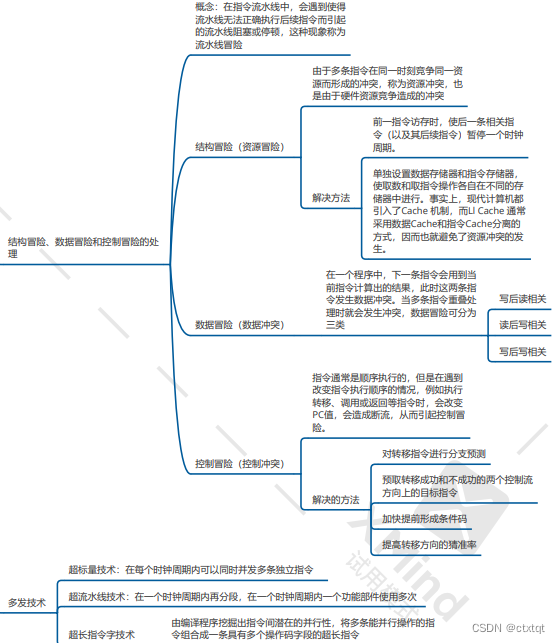
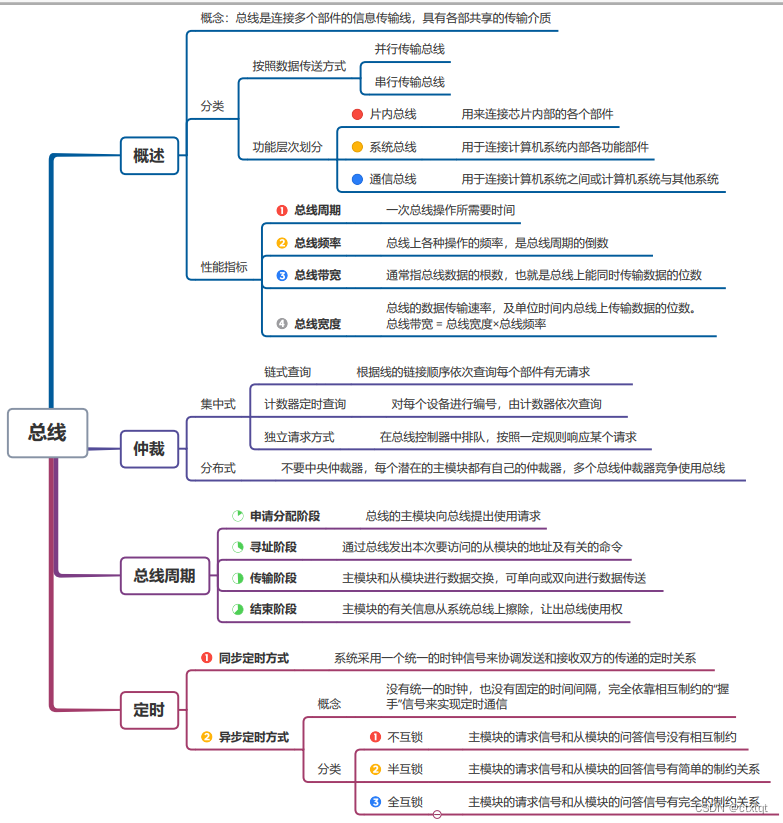
2.6总线:
总线,不太重要。考到的主要是性能指标。
2.7I/O:
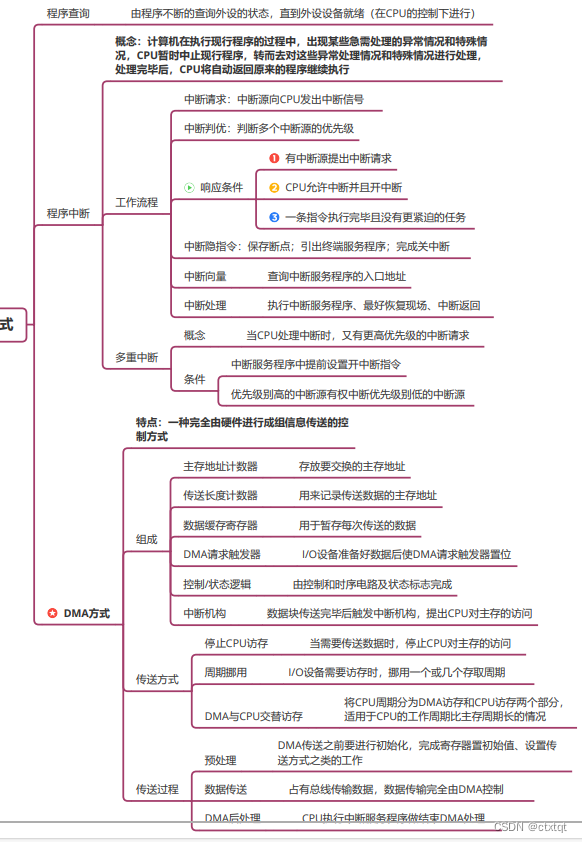
输入输出是对主机而言,主要的控制方式是常考点。
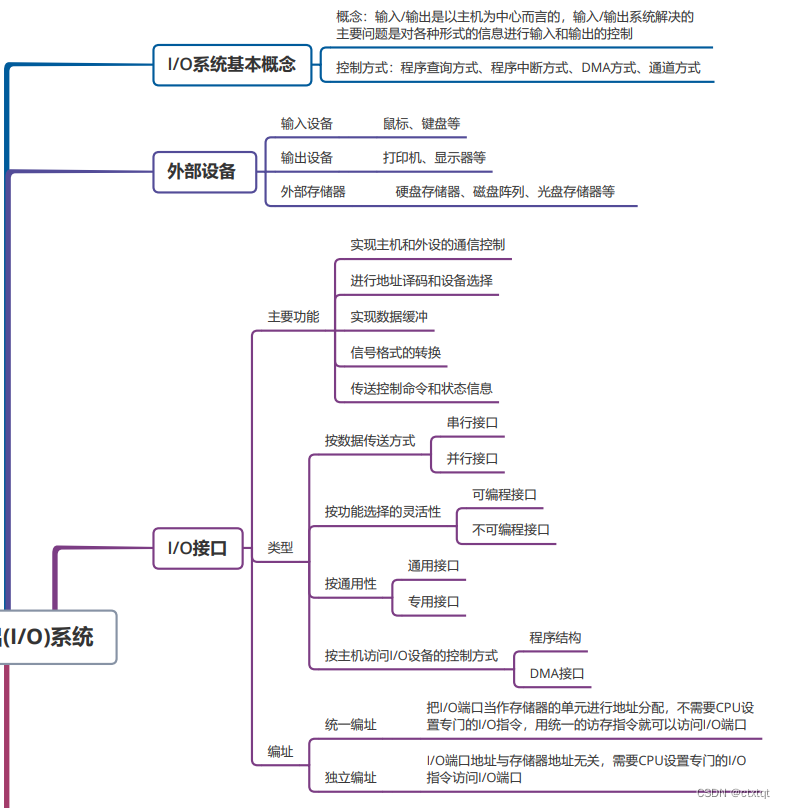
程序查询、程序中断、DMA方式。
理解这些方法不难,主要是计算题。
中断服务程序:保存现场、开中断(多重中断)、执行中断服务程序、恢复主程序现场、执行中断返回程序(与中断隐指令相反)。


















 3190
3190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









