






最近学习深度学习,需要先学习Pytorch的框架,为记录细节方便以后复习,便在CSDN上记录一些细节。
一、Pytorch安装
(一)CUDA版本查看
由于我个人在家使用的是笔记本,而且是集显加独显,所以nivida控制面板可能不一样,但最终影响结果不大。

具体操作为通过预览调整图像设置--下方的系统信息--组件的NVCUDA64.DLL的相关信息,得知版本11.6.134。
CUDA下载具体为链接:Window10环境搭建2:下载CUDA_cuda下载-CSDN博客
(二)具体下载
版本选择以及相关命令:如下图
复制命令并学改为:
conda install pytorch torchvision torchaudio pytorch-cuda=11.6 -c pytorch -c nvidia
(三)遇到的问题

我靠忘记保存文字了,无论是在anaconda中的虚拟环境还是非虚拟环境,其实如果你想快速解决就用pip,如果pip不行就重新配置环境(我打了一堆解决问题的过程就没了)
最后附上成功安装图(反正我是重新配置了一下环境,因为我之前安装的python版本是32位,pytorch只能兼容64位,只能重新配置环境了)

二、Pytorch入门
最好的方式肯定是从官方文档入手:PyTorch documentation — PyTorch 2.2 documentation
我跟着学校的课程的进度,采用jupyter notebook记录过程。
(一)张量Tensor
1.概述
张量是Pytorch对所有数据类型的统称,包括0阶张量(scaler常数)、1阶张量(vector向量)、2阶张量(matrix矩阵)、3阶张量。在tensor中,阶可以理解为numpy的轴。二阶张量的向下方向为dim0,向左方向为dim1。三阶张量的向下方向为dim0,向后方向为dim1,向右方向为dim2。
2.创建一个Tensor变量
主要有三种方法,直接Tensor创造,其他数据类型转换而来,还有torch的本身api来创建。


3.常用method和属性
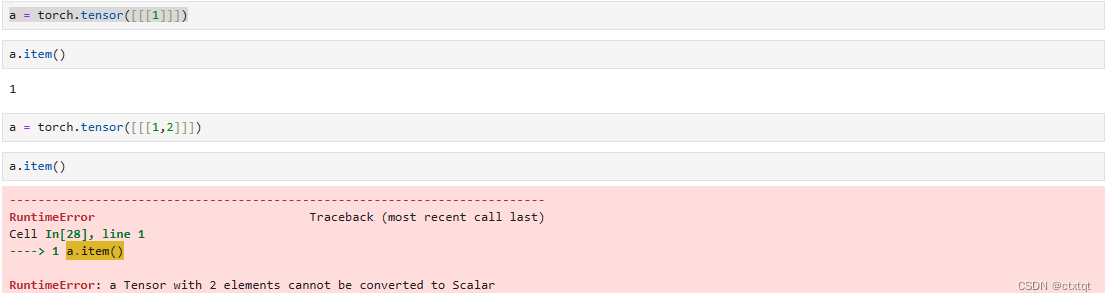
(1)张量名.items:获取tensor中的值
返回的是python的scalar值,不能返回其他元素。因此只能应用于当tensor中仅有一个值时。
(2)torch.numpy:转换为numpy数组
(3)张量名.size:返回tensor的大小
(4)张量名.view:类似于numpy的reshape,但只是浅拷贝并不返回一个全新的副本。-1是指该位置的值等于=元素总数/先前确定的值,若不指定第二个参数则展开为一个元素数目*1的张量

(5)张量名.dim:获取阶数
(6)张量名.max:获取最大值
(7)张量名.transpose(参数顺序无关):交换维数,对于二阶可以不传值,但是对于三阶及三阶以上必须要传值
二维example:

三维example:

(8)张量名.std:计算方差
(9)张量名.permute:交换轴(参数为dim0,dim1,......,dimn-1,n为阶数)

(10) 张量名.new_ones:根据给出的形状参数创建新的张量,para1为行,para2为列,以1填充

(11)torch.add or 张量名.add(张量名) or 张量名.add(张量名)_:张量加法,对于同一形状的张量,直接进行点加。torch.add与张量名.add(张量名)会返回一个新的张量。 张量名.add(张量名)_则原地进行修改


4.常用切片方法
同Python语法与numpy语法,直接根据张量的具体阶数,找到对应元素的相应位置信息即可:

5.数据类型
tensor中常用数据类型有float、double、uint8、int8、short、int、long、bool等。
可以在创建tensor变量时指定数据类型,语法为dtype=torch.数据类型:

强转类型,语法tensor.数据类型():

6.torch.tensor与torch.Tensor
tensor的首字母大小写有区别,尽量使用小写,因为Tensor内不能指定dtype:

有专门的method可以去指定Tensor类型,比如LongTensor、IntTensor等,dtype是这些方法的属性。

但似乎再使用其他方法时,Tensor提起的会多一些。使用tensor其实和大写没什么区别,如果主动使用Tensor时,可能会有许多限制。
7.tensor直接加减乘除运算

8.CUDA中的tensor
注意torch版本一定是GPU版本,若不是请卸载相关包并重新下载:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu11x
CUDA是NVIDIA推出的通用并行架构平台,可以使得GPU解决复杂的计算问题。
torch.cuda可以使得在cpu和gpu上用同样的方法操作tensor
torch.cuda.is_available() 检查cuda是否可用
torch.device('cuda'or'CPU') 构建一个device对象
torch.to(device) 把张量转换为device的张量

总结:tensor与numpy是非常相似的
(二)使用pytroch完成一次线性回归
1.向前计算相关方法与属性
tensor属性为requires_grad,Default为False,若在创建张量时requires_grad=True,便会记录对于该张量的所有操作。tensor还有一个属性为grad_fn,用于记录做过的操作。
为了防止跟踪历史记录(和使用内存),可以将代码块包装在with torch.no_grad():中。在评估模型时特别有用,因为模型可能具有requires_grad=True的可训练的参数,但是我们不需要在此过程中对他们进行梯度计算。
2.梯度计算相关方法与属性
梯度计算通过method backgrad(),gard()获得导数值
backward()方法根据损失函数,去计算参数的梯度,并且将它累加保存到grad
tensor.data,当tensor中的requires_grad=False,tensor.data == tensor
当requires_grad=True,tensor.data仅仅指的是张量中的数据(浅拷贝)
当张量中requires_grad=True,需要用tensor.detach().numpy() (深拷贝)
3.手动线性回归
导入包以及设置样本数据x,y :

设置参数w(回归方程斜率),b(回归方程的截距):

更新loss值: 回归loss为

优化参数:根据学习率一点一点优化w,b

主体训练过程:

loss值的变化过程:

绘制图像:

图像以及训练过后的w与b,可以看到是与原斜率和截距相差不大:

4.使用pytorch的api完成线性回归
(1)nn.Module类
nn.Module是torch.nn中的一个类,是我们自定义网络的一个基类。通常我们会定义一个类,继承nn.Module。注意继承需要用super()方法,继承Module类的方法和属性。
自定义网络的注意事项:
调用nn.Module的__init__需要使用super(当前类名,self).__init__
必须定义一个forward函数用于定义网络向前计算的过程,利用nn.Linear实现。一般使用Module类中的__call__方法对该我们自己定义的函数进行调用。
nn.Linear主要传入输入数据维度与输出数据维度。Official Docs说是in_features和out_features。nn.Linear也叫全链接层。

注意传入数据的特征数量必须与向nn.Linear内传入的 in_features一致。
(2)优化器类(optimizer)
常见有SGD即随机梯度下降,torch.optim.SGD(参数,学习率),torch.optim.Adm(参数,学习率)。参数通过nn.Module的实例化的parameters()方法来获取,默认获取requires_grad=True的参数。当然,在使用优化器类的时候,同手动线性回归一样,要把在进行优化的时候要把梯度置为0,一般利用zero_grad(),然后利用回归损失函数loss的backward计算梯度,最后利用step()更新参数的值。

(3)损失函数类:
一般传入ytrue和out参数。
均方误差:nn.MSRloss(),回归问题
交叉熵损失:nn.CrossEntropyLoss(),分类问题
交叉熵损失公式: 其中,M为类别数量,y为符号函数,当k == i时为1,反之为0,p为i属于k的概率,为了让p在[0,1]区间,会对数据进行取指数,再求概率,计算方法详看softmax原理。m为样本总数。
(4)线性回归实例:
导入模块

定义数据

定义回归模型类

实例化模型

训练主体

设置模型评估模式即预测模式并画图
tips:eval()与train()相对应,一个用于评估一个用于训练,两个模式的部分参数有所不同,所以需要进行转换。

(5)在GPU上执行以上程序
只需要将x与y转换为GPU上的tensor类型就可以了。

但注意,在将模型转换为预测模式后,若需要进行画图操作,需要将对于tensor张量先转换为cpu类型的张量,使用.cpu()即可。
(三)数据集类
当数据量非常大的时候,需要我们将数据顺序打乱,分为一个一个batch,并对数据进行预处理。torch中提供了一个基类,实现对数据的加载。
torch.utils.data.Dataset需要我们去定义一个类去继承该基类,我们需要定义一个__len__方法与__getitem__方法,通过定义len方法获取数据集的长度,通过定义getitem方法获得索引方法
1.利用Dataset加载实例数据:
数据来源:http://archive.ics.uci.edu/ml/datasets/SMS+Spam+Collection
数据集部分内容:
利用pandas实现__len__方法与__getitem__方法

然后对于这个CifarDataset进行实例化就可以访问
 出现了错误,可能是python默认的gdk编码器解码不了该文件的某些字符。
出现了错误,可能是python默认的gdk编码器解码不了该文件的某些字符。
在open文件的时候,加入一个errors = 'ignore',直接忽略掉不可以解码的数据。
读取成功~

2.迭代数据集类:
torch.utils.data.DataLoader类,用于实现批处理数据、打乱数据(类似于洗牌操作)、多线程(multiprocessing)加载数据。
传入参数:
dataset:即Dataset的实例
batch_size:传入数据大小
shuffle:bool,是否打乱数据
num_workers:加载数据的线程数

对于DataLoader求长度,是求样本数/batch_size并向上取整,这是比较好理解的,就算没有满足一个batch_size,也需要用一个batch_size大小的加载器去存放这些数据。
3.torch自带数据集:
torchvision提供图片数据处理相关的API和数据
torchtext提供对文本数据处理相关的API和数据,例如:IMDB(电影评论文本数据)
例如torchvision.datasets.MNIST(root='/files/'(数据存放位置), train=True(是否为训练集), download=True(是否需要下载), transform=(对图像的处理函数)),值得注意的是,此时MNIST继承了Datasets,只要对MNIST进行实例化,就是对于Datasets的实例化对象。
MNIST数据集:
读入数据:
自动创建data文件夹,下载相关数据到data文件夹中
读取第一张图片:
(四)利用Pytorch实现手写数字识别
1.思路与流程分析
首先,需要准备数据,这些需要准备DataLoader。第二,构建模型,这里可以使用torch构造一个深层的神经网络。第三,进行模型的训练,优化参数。第四,模型的保存,封装模型,后续持续使用。最后,模型的评估,使用测试集,观察模型的好坏。
虽然准备数据只需要调用MNIST方法就行了,但是由于该方法返回的是image对象,为了方便进行处理和避免仿射变换(即线性变化加平移),必须要对数据进行标准化处理。标准化处理可以将数值映射至一个[0,1]范围内,避免因为输入数据过大而导致的梯度过大问题,对于如AdaGrad等动态更新学习率的优化算法而言,会导致学习率过小,从而越过最优。还可以移除平均亮度,凸显差异。
torchvision提供了transforms方法对图像进行预处理操作,比如ToTensor,将图像转换为张量。还有Normalize,对图像进行归一化处理。
ToTensor:将 HWC 的图像格式转为 CHW 的 tensor 格式 C指通道数、H指高,W指宽。将 PIL Image 或 numpy.ndarray 转为 tensor。同时也能对RGB类的图像进行归一化。注意,使用前要进行实例化。
Normalize:标准化处理
Compose:类似于scikit-learn中的pipline,对数据进行流水线操作,将多个transform组合在一起。
2.数据准备与处理:
准备训练集:

准备测试集:

3.构建模型:
全连接层:即当前一层的神经元和前一层的神经元相互链接,实现对于前一层数据的变换。
模型为四层的神经网络,包括输入层和两个全连接层和输出层。
数据处理流程为数据输入至第一个全链接层,经过激活函数处理输入至第二个全连接层,最后经过变化输出结果。
那么必须要注意的是,激活函数的选取与使用、每一层数据的形状、模型的损失函数。
(1)激活函数的选取与使用:
一般使用Relu函数,一般使用torch.nn.functional.relu进行导入。Relu函数是选取对应数据和0中的最大值,实际上是将负值舍去了。
(2)模型中数据的形状:
最开始输入数据的形状为[batch_size,1,28,28],MNIST数据集的每张图片的长宽为28x28,灰白图片仅有一个通道数。
形状修改为[batch_size,28x28],矩阵乘法对二阶张量生效,与batch_size无关。
第一个全连接层的输出形状:[batch_size,28](可以理解为最开始的数据乘以了一个形状为[28x28,28])的矩阵。
激活函数不改变形状,第二个全连接层输出形状为[batch_size,10],数据只有十个类别
(3)模型的损失函数:
一般对于二分类问题,会采用sigmoid函数求这个数据属于该类别的概率值(将数据的特征值映射至[0,1],公式为 ,z为预测值)。但对于多分类问题,一般使用softmax计算该数据属于该类别的概率值。将softmax传入对数交叉熵得到的损失函数为交叉熵损失。
torch有两种方式实现交叉熵损失,一个是之前学习到的nn.CrossEntropyLoss()类,传入参数为输入值与target值。另外一个是利用nn.functional的log_softmax方法(传入参数为计算对象与维度值,维度值一般为-1),主要是计算log(softmax值)。nll_loss即带权损失(传入计算对象,target),主要是计算权重然后求和取平均值加负号。
这里选用第二种方法计算loss,最后定义模型如下:

4.模型训练:
首先实例化模型与优化器,这里采用Adam(动态更新学习率),学习率为1e-3。然后定义train函数,将模式设置为训练模式,然后获取训练集,遍历数据集迭代器,每次都将梯度置为0,然后向前计算,得到返回值。这里的返回值是取了对数的softmax值,然后计算带权loss。接着反向传播,计算各参数的梯度,利用优化器类的step进行更新。一般神经网络参数的初始值都不用去设定,torch已经设定好了,我们只用提供数据,神经网络会自动将参数更新至一个较好的状态。其中的print操作是为了实时观察,训练的情况。

5.模型的保存与加载:
torch提供save方法保存模型以及优化器,传入参数为模型实例化的state_dict(),以及对应文件保存路径,但注意是pt格式文件。模型加载通过模型实例化对象的load_state_dict方法,传入参数为torch.load(对于文件路径)。

6.模型的测试:
其实与训练过程非常相似,但不需要对参数进行更新,需要收集loss和准确率。output的shape为[batch_size,10],求output的最大值其实就是每一个样本预测值的最大概率值,keepdim参数是保持为一个shape为[batch_size,10]二阶张量。max返回最大值以及最大值的位置。因此pred的形状为[[batch_size,1]。最后在计算loss的平均值和与correct的平均值就好了。

7.结果:
将数据准备与处理封装成一个函数:

main函数为:

并将模型训练五次并测试五次的结果为:
未训练的结果:
![]()
第一次:

最后一次:

可以看到准确率大大提高且loss也降低到一个非常不错的水平。最开始预测率仅为0.08,甚至不如自己蒙的概率,自己每次蒙对的概率也有0.1。
-----------------4.4更新线--------------------
历时四天,终于算是torch入门,但是显然对于torch的各个api肯定还是不熟悉的。但作为一个学徒,其实把每一个api记住也是不现实的。只有用到再去查询,才是学习这些拓展包的最好方法。pytorch入门告一段落~
-----------------4.6更新线--------------------
学到一个序列化容器的内容,更新一下:
三、Pytorch的序列化容器
(一)nn.Sequential
nn.Sequential类似于流水线化pipline的思想。在构建神经网络模型的时候,可以将对input的处理构造类传入其中,比如nn.Linear、激活函数等传入,然后调用该类的实例化对象就可以得到结果。
(二)nn.BatchNorm1d
经过BN操作,可以使得数据范围处在[0,1]范围,改善了因为数据数值而导致的梯度消失和梯度爆炸问题。
(三)nn.Dropout
参数的随机失活,等同于nn.LSTM中的dropout参数,不过这个应用面更加广泛。















 707
707











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









