






本篇文章节选自 决策树的构造 - 数模百科。如果你想了解更多关于决策树算法的信息,请移步 决策树 - 数模百科。
首先讲讲决策树是啥。
举个简单的例子。
小王在他的高尔夫俱乐部碰到了个棘手的事儿——有时候,高尔夫球场上人山人海,员工们忙得跟陀螺似的;而有时候,人迹罕至,员工们就那么干等着,白白领了工资不说,还特别闲得慌。这可急坏了小王。
他琢磨着得想个办法,根据天气情况来猜猜球场会有多少人来。于是,小王就动手记录了那么两周的天气和客人来访的情况,包括了天气是晴是阴还是下雨,有多热多冷,湿不湿,风刮得凶不凶。
小王接着用这堆数据,搭了个决策树模型。这决策树就像一棵树倒挂着,最上头的根部扎满了小王收集的数据,接着一层层往下"分叉",就像树枝一样,一步步筛选出最关键的影响因素。
经过这番折腾,小王发现了点规律:
-
要是天儿多云,呵,那可真是人人都想挥杆,球场热闹非凡。
-
要是晴天,但湿度过了70%,嘿,这天儿就不好了,人们宁愿呆在家里也懒得出门打球。
-
要是下雨加上风儿呼呼的,那就更完了,基本上可以打包票,没人会来。
搞清楚了这些,小王就可以按照天气预报来提前安排员工了。如果预报说是湿哒哒的晴天或者风雨交加,他就可以叫一些员工歇着,因为他知道这种天气客人肯定喜欢。如果是多云或者其他高峰时段的好天气,他就会多叫些临时工来帮忙。这一招,不仅保证了服务不打折,还省下了不少人工费,真是一举两得。
决策树是什么
在决策树算法中,"树"是一种特殊的数据结构,它包含节点和连接这些节点的边。这种结构有一个根节点,该节点下可以有多个子节点,每个子节点也可以有它自己的子节点,以此类推。 这种层次结构形成了一种类似树的结构。
-
根节点(Root Node) 是树的最顶部节点,它没有父节点,但可以有多个子节点。
-
内部节点(Internal Nodes) 是树中的中间节点,它们既有父节点也有子节点。每个内部节点代表一个特征或属性,根据该特征或属性的值将数据集分割成两个或更多的子集。
-
叶节点(Leaf Nodes) 是树的最底部节点,它们有父节点,但没有子节点。叶节点代表一个类别或决策结果。
决策树的目的是为了通过从根节点到叶节点的路径来表示决策过程。每一条从根节点到叶节点的路径都可以看作是一个"如果...那么..."规则,这些规则构成了一个决策过程。
决策树的构造
在实际的数据集中,算法首先会评估数据集里所有的特征,来决定哪一个因素在这个决策过程中起到了关键作用,然后选择这个特征作为决策树的“分支“。它会计算每个特征能带来多大的“决策助力”(具体由信息增益、信息增益率、基尼指数等指标表现),简单来说,就是这个特征能给我们带来多少有用的信息,帮助我们减少选择时的不确定性。特征越能帮我们明确地划分数据,它给决策结果带来的助力就越大。
决策树算法就是不断地重复这个评估和选择特征的过程,这就是所谓的“递归”。我们可以想象大树的每一个分支都代表一个问题和它的答案。每次选择一个特征后,数据集就被分成几个小群体,每个群体都比之前更加纯净,也就是说,群体内部的成员更加相似。然后,算法会在每个小群体上重复之前的评估和选择特征的过程,直到每个群体不能再被细分,或者说,我们已经有足够的信息来作出决定了。
特征选择
咱们买手机,一般都会关注几个点:价格、品牌、性能、外观、电池续航力等等。这些点就好比是决策树里面的“特征”,它们都会影响咱们最后的选择。
现在,假设你要帮朋友选一款手机,你朋友给你说了她的一些需求。比方说,她希望手机不要太贵,电池要用得久,还要能拍出好看的照片。这时,你就要在所有的特征中选出几个最关键的来决定买哪款手机。这个过程,就叫做特征选择。
我们可以把这个过程想象成一棵树,树的根部是你帮你朋友开始选手机的那一刻。每一个分叉点就是一个决策点,也就是需要考虑的一个特征。
首先,你可能会先看价格,因为你朋友说了不要太贵的。那么价格这个特征就好比是决策树的第一个分叉点,你会根据价格把手机分成两拨:贵的一拨,便宜的一拨。
然后,在价格合适的那一拨里面,你可能会考虑电池续航力。这个电池续航力就是决策树的第二个分叉点。这样一来,便宜的手机里面,又被你分出了电池续航力好和不好的两类。
最后,你可能会在电池续航力好的这一类中,再根据拍照功能来选。拍照功能就是决策树的第三个也是最后一个分叉点。这步操作之后,你就能挑出几款既便宜、电池又耐用、拍照又好的手机了。
通过这样一层层筛选下来,你就能把最适合你朋友的那款手机选出来。这整个过程,就像是一棵树一样,从树根到树梢,一步步缩小选择的范围,直到挑选出最佳的选项。
所以,特征选择就是要在众多可能影响决策的特征中挑出最有帮助、最能影响最终决策的那几个关键点。就像是在选手机时筛选出价格、电池续航力和拍照功能这几个最关键的特征,帮助我们做出最后的购买决定一样。
特征选择决定了每个节点应该基于哪个特征进行分割。特征选择的目标是选择出能最有效地分割数据集的特征,即选择出能使得分割后的子集尽可能纯净(即同一子集中的样本尽可能属于同一类别)的特征。
特征选择主要有三种评估指标。
信息增益
在了解信息增益之前,我们先来聊一聊“熵”这个概念。在信息论的世界里,熵是用来描述信息有多么“杂乱无章”的一个量度。你可以把它想象成一个盛满了各种颜色小球的大罐子,如果小球的颜色五花八门,那么你随手抓一把出来,每次都会有新奇的颜色组合,这个状态就很“熵”。而如果小球都是一个颜色,那么每次看到的都是一样的,就没有什么“熵”了。
那么,信息增益又是什么呢?它其实跟我们生活中的“排除法”很像。想象一下,你在猜谜,谜底是一种水果,有很多种可能。如果有人告诉你这个水果是黄色的,那么你的猜测范围就缩小了,不确定性减少了。同样,在决策树中,我们希望找到那种能让我们的“猜测”更准确的线索,这种线索就是特征。通过计算不同特征的信息增益,我们能知道哪个特征在分类时更有帮助,更能减少不确定性。
信息增益(Information Gain)来源于信息论中的熵(Entropy)概念。在决策树中,我们使用信息增益来度量通过某特征对数据集进行划分,能够减少多少信息的不确定性。也就是说,我们通过计算每个特征的信息增益,来选择信息增益最大的特征进行分割,即选择这个特征对数据集进行划分,目的是最大化减少后续决策的不确定性,从而提高模型对数据的分类准确性。
信息增益计算公式为:
信息增益 = 父节点的熵 - 所有子节点的熵加权之和.
其中,熵的计算公式为:
其中 p 是该节点中每个类别的样本占比。这个公式表示,如果我们随机抽取一个样本,那么我们的不确定性(也就是需要多少信息才能确定这个样本的类别)是多少。
对于所有子节点的熵之和,计算步骤如下:
假设一个父节点被分割成了多个子节点,我们需要计算每个子节点的熵,然后再计算所有这些子节点熵的加权和。以下是分步骤的解释:
-
计算每个子节点的熵: 对于每个子节点,我们使用熵的公式来计算其熵值。如果子节点 j 有 k 个类别,那么子节点 j 的熵 H_j 可以计算如下:
其中 p_{ij} 是子节点 j 中第 i 个类别的样本所占的比例。
-
计算每个子节点的权重: 每个子节点的权重是它的样本数量除以父节点的总样本数量。如果子节点 j 有
个样本,父节点有 N 个样本,那么子节点 j 的权重
是:
。
-
计算加权熵: 最后,我们计算每个子节点的加权熵,然后将它们加起来得到所有子节点的熵之和(简称总熵)。加权熵是每个子节点的熵乘以其权重:

其中 j 是子节点的索引。
例如,如果我们有一个数据集,其中有15个样本是正例,5个样本是反例,那么这个数据集的熵就是 。
接下来,根据某个特征划分得到两个子节点:
-
第一个子节点有10个正例和0个反例,权重为0.5,熵为0,因为这个节点是纯的(所有样本属于同一类别)。
-
第二个子节点有5个正例和5个反例,权重为0.5,熵为1,因为这个节点的样本完全不纯,它的不确定性最大。
所以通过这个特征进行划分后,我们得到的总熵就是,所以这个特征的信息增益就是原始熵0.81减去0.5,等于0.31。
在决策树中,我们通常选择信息增益最大的特征进行划分。
然而信息增益有一个缺点: 对可取值数目多的特征有所偏好 。比方说,如果有个属性能取好多种值,用它来给数据分组,那结果就是能分出一堆细分得跟扁豆米似的小组。这种分法好像很细致,因为它把不确定性降到很低,但这其实可能是假象,因为这个属性有可能跟我们要预测的结果只是不经意间撞个正着,并不是真的有什么预测的大能力。结果就是,咱们的模型就好比小孩子画饼,看着美味实则泛不起波澜——就是过拟合了,拿去应对新情况的时候,它可能就束手无策了。举个例子,就像用指纹来判断人是不是爱吃巧克力。指纹这东西嘛,每个人的都不一样,看似能帮我们把人群分得清清楚楚,每个人都归到自己专属的小组里。但这真能告诉我们谁嘴馋谁不馋吗?显然是行不通的。如果我们真的用指纹来判断爱好,那遇到新人的时候,这招就不灵了,因为它根本就没有办法预测出新的情况。简而言之,这就好比是没有远见的小聪明,学到的东西只能在旧知识里打转,一旦要跳出来面对新场景,就束手无策了。
信息增益率
信息增益率(Information Gain Ratio)是对信息增益的一种改进,目的是为了减少信息增益对可取值数目多的特征的偏好。
信息增益率是在信息增益的基础上,加入了一个调整因子,这个调整因子是特征A的熵(也叫做固有值Intrinsic Value,也就是被选择用来划分这个数据集的特征的熵),它与数据集的熵不同。特征的熵计算的是特征A的不同取值所产生的分布的熵,它反映了特征A的取值的多样性。如果特征A的取值非常多样,每个取值的样本数量大致相等,那么特征A的熵就会很高。通过这个值来调整信息增益,可以减少信息增益对多值特征的偏好。
信息增益率的计算公式为:
信息增益率=信息增益 / 特征的熵.
其中,特征的熵计算公式与上述熵的计算公式相同,只是 p 变为该特征每个取值的样本占比。
例如,假设我们有一个关于天气情况的数据集,我们想要预测是否适合户外活动(是或否),数据集中有两个特征:风速(高、中、低)和温度(热、温和、凉爽)。我们的目标是决定使用哪个特征来分割数据集。
我们假设原数据集的分布如下:
-
适合户外活动(是):5个样本
-
不适合户外活动(否):5个样本
数据集的原始熵(H)为:
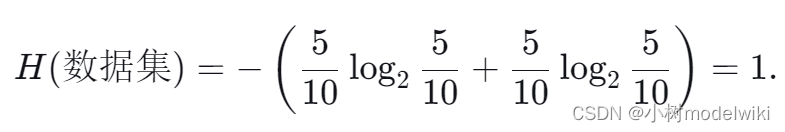
现在我们假设“风速”特征的分布如下,以便符合原始的类别分布:
-
高风速:4个样本(1个是,3个否)
-
中风速:4个样本(2个是,2个否)
-
低风速:2个样本(2个是,0个否)
每个子集的熵计算如下:
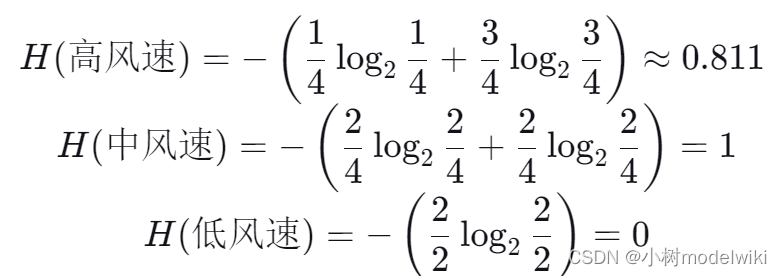
“风速”特征的条件熵:
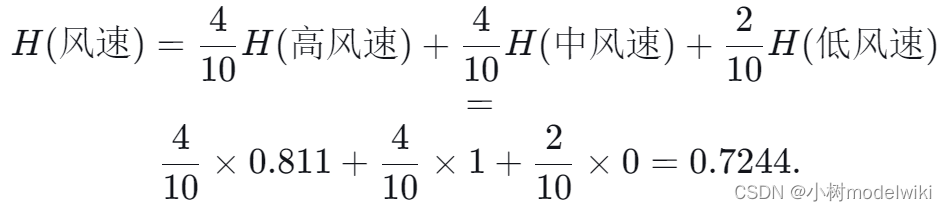
“风速”特征的信息增益:
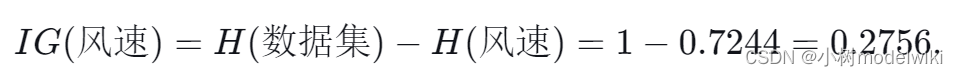
然后,我们计算“风速”特征的熵:
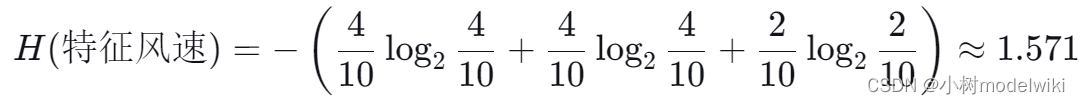
得到信息增益率:

在决策树中,我们通常会选择信息增益率最大的特征进行划分。
基尼指数
基尼指数(Gini Index)来源于经济学中的基尼系数,用来度量财富分配的不均匀性。在决策树中,基尼指数用来度量数据的不纯度或者混乱度,基尼指数越小,数据的不纯度越低,分类效果越好。
基尼指数的计算公式为:
其中 p 是该节点中每个类别的样本占比。
这个公式实际上表示的是,如果我们随机抽取两个样本,它们属于不同类别的概率。因此,基尼指数实际上反映了分类错误的概率,这也就是为什么基尼指数越小,分类效果越好的原因。
例如,如果我们有一个数据集,其中有15个样本是正例,5个样本是反例,那么这个数据集的基尼指数就是 。
在构造决策树时,我们通常会选择基尼指数最小的特征进行划分。
决策树生成
决策树生成主要有三种算法。
ID3算法
ID3 (Iterative Dichotomiser 3) 算法是一种贪心算法,由罗斯·昆兰在1986年提出,用于生成决策树。其主要步骤如下:
从根节点开始,对每个节点进行以下操作:
-
如果所有样本都属于同一类别,则该节点为叶节点,类别为该类别;
-
否则,计算所有特征的信息增益,选择信息增益最大的特征进行分割,生成子节点;
-
对每个子节点递归执行以上步骤。
ID3 算法使用信息增益作为特征选择的标准。信息增益计算公式如下:
其中,IG(D, a) 是特征 a 的信息增益,H(D) 是数据集 D 的熵,V 是特征 a 的所有取值, 是数据集 D 中特征 a 取值为 v 的样本子集,
是子集
的熵。
熵的计算公式如下:
其中,K 是类别数目, 是数据集 D 中类别 k 的样本占比。
ID3 算法的缺点:
-
不能处理连续特征
-
容易偏向于取值多的特征
-
没有考虑过拟合问题
C4.5算法
C4.5 算法是罗斯·昆兰在1993年提出的,是对 ID3 算法的改进。C4.5 算法在特征选择时使用信息增益率,而不是信息增益,以此来减少对取值多的特征的偏好。此外,C4.5 算法对连续特征进行了处理,并引入了剪枝技术来处理过拟合问题。
C4.5 算法的主要步骤如下:
-
从根节点开始,对每个节点进行以下操作:
-
如果所有样本都属于同一类别,则该节点为叶节点,类别为该类别;
-
否则,计算所有特征的信息增益率,选择信息增益率最大的特征进行分割,生成子节点;
-
对每个子节点递归执行以上步骤。
-
-
生成完整的决策树后,对决策树进行剪枝。
在 C4.5 算法中,信息增益率的计算公式为:
其中,GR(D, a) 是特征 a 的信息增益率,IG(D, a) 是特征 a 的信息增益,IV(a) 是特征 a 的固有值(Intrinsic Value),用来度量特征 a 的取值分布情况。
对于连续特征,C4.5 算法会先对其进行离散化处理,具体方法是将连续特征的所有可能取值按照升序排序,然后取相邻两个取值的中点作为候选切分点,选择信息增益率最大的切分点进行分割。
对于过拟合问题,C4.5 算法在生成完整的决策树后,会使用剪枝处理。
CART算法
CART(Classification and Regression Tree)算法是由Breiman等人在1984年提出的。CART算法是一种二叉决策树,即每个内部节点都有两个子节点。并且,CART算法既可以用于分类问题,也可以用于回归问题。
CART算法的主要步骤如下:
从根节点开始,对每个节点进行以下操作:
-
如果所有样本都属于同一类别(对于分类问题),或者所有样本的输出值相同(对于回归问题),则该节点为叶节点,类别为该类别或输出值为该输出值;
-
否则,计算所有特征的所有可能的二分切分点的基尼指数(对于分类问题)或平方误差(对于回归问题),选择基尼指数最小或平方误差最小的特征和切分点进行分割,生成子节点;
-
对每个子节点递归执行以上步骤。
在分类问题中,基尼指数的计算公式为:
其中,Gini(D, a) 是特征 a 的基尼指数,K 是类别数目, 是数据集 D 中类别 k 的样本占比。
在回归问题中,平方误差的计算公式为:
其中,MSE 是平方误差,N 是样本数目, 是第 i 个样本的输出值,
是所有样本输出值的均值。
CART算法也使用剪枝处理来解决过拟合问题。
剪枝处理
首先我们回顾一下决策树。决策树就像是一个挑选路线的指示牌,通过一系列的是非问题来帮你做决定。比如说,你想预测明天会不会下雨,决策树可能会问:“今天云多吗?”、“湿度高不高?”根据你的回答,它会告诉你最后的预测结果。
但问题来了,如果这个指示牌上的指示太多太复杂,你不仅跟着它走得晕头转向,而且有时候它给出的建议可能在其他情况下就不太管用了。这就是所谓的过拟合——决策树太过于匹配我们手头上的这点数据,反而丢失了一些普遍性,导致它在面对新情况时判断失误。
为了解决这个问题,就有了剪枝处理。剪枝就像是给这个决策树进行了一次“瘦身”,去掉一些不那么重要的分叉,使得这个树模型更加简洁、更具有泛化能力。这样,当有新情况出现时,决策树就能更加稳健地做出预测。
那么,为啥要发明剪枝呢?主要是为了防止决策树变得太复杂,以至于只能解决眼前的数据,对新的数据无能为力。通过剪枝,模型就能更好地推广到其他数据上,即提高模型的泛化能力。
决策树剪枝在任何你需要使用决策树模型的地方都很有帮助。无论是在银行判断是否批贷款,在医院预测病情发展,还是在商店推荐商品,只要是需要通过一系列判断来得出结论的场景,剪枝处理都能帮助决策树模型变得更加强大、更加适用。简而言之,剪枝就是为了让决策树不仅能在当前数据上表现好,也能在未来遇到新情况时,依然能做出靠谱的判断。
决策树的剪枝处理是为了解决决策树容易过拟合的问题,通过减少决策树的复杂度(如减少决策树的深度或叶节点数目)来防止过拟合。
剪枝处理主要有预剪枝和后剪枝两种方法。
预剪枝
预剪枝就像是我们在种树时,边种边修剪的过程。我们的目的是种一棵既健康又不会长得乱七八糟的树。在树苗长大的过程中,我们会时不时地观察它的每一个分叉,思考一下:如果让这个分叉继续长下去,它能不能让整棵树变得更好?是不是每个分叉都有它存在的价值呢?
如果我们发现某个分叉长出来后,可能不会对整棵树有什么好处,甚至还可能让树长得杂乱无章,那我们就会提前下手,把这个分叉给剪掉。这样做的好处是什么呢?首先,它可以避免我们的树长出太多没必要的枝条,保持树的整洁和健康;其次,我们也省下了更多的精力和资源,因为没有让那些没必要的枝条继续长下去。
在决策树模型中,这种“边种边剪”的做法就是预剪枝。具体来说,就是在我们构建决策树的时候,不是盲目地让树的每个分支都长下去,而是先评估一下,如果让这个节点继续分下去,能不能让我们的模型变得更强大,能不能让我们的模型在面对新情况时表现得更好。如果答案是“不行”,那我们就在这里停下来,不再继续让它分下去了,把它定为一个叶节点,也就是树的一个末端节点。这样,我们的决策树就会更加精简,运行起来也更加高效,不会浪费时间在那些没有帮助的分支上。
评估的标准可以有很多,比如信息增益、信息增益率等,这里以基尼系数作为评估标准为例。
基尼系数的计算公式为:
其中,D 是当前节点的数据集,K 是类别的数量, 是第 k 类在当前节点的概率。
现在我们以基尼系数为参照按照预剪枝的策略来决定是否分割当前节点。以下是具体步骤:
-
计算当前节点的基尼系数。 这是预剪枝的第一步,用于评估当前节点的不纯度。
-
计算分割当前节点后,其子节点的基尼系数。我们需要对每个可能的分割计算加权后的基尼系数,公式如下
其中,
是在特征 A 的第 i 个取值下的子数据集,
是
-
比较分割前后的基尼系数。我们通过计算基尼系数的减少量(基尼增益)来衡量分割的效果:
如果基尼增益 ΔGini(D, A) 大于0,表示分割后的数据集纯度提高了;如果 ΔGini(D, A) 小于或等于0,表示分割不会增加数据集的纯度,甚至可能降低。
-
根据基尼增益的结果来决定是否对当前节点进行分割。如果基尼增益小于等于0,则停止分割并将当前节点标记为叶节点。如果基尼增益大于0,并且其他预剪枝的条件(如深度限制、最小样本数等)也满足,可以继续分割。
举一个简单的例子来说明这个过程:
假设当前节点包含以下数据集 D:
| 类别 | 数量 |
|---|---|
| A | 30 |
| B | 10 |
基尼系数为: Gini(D) = 1 - ( (30/40)^2 + (10/40)^2 ) = 1 - (0.5625 + 0.0625) = 0.375.
现在假设有一个特征可以将数据集分为两个子集D1和D2:
D1:
| 类别 | 数量 |
|---|---|
| A | 20 |
| B | 5 |
D2:
| 类别 | 数量 |
|---|---|
| A | 10 |
| B | 5 |
D1的基尼系数为:Gini(D1) = 1 - ( (20/25)^2 + (5/25)^2 )= 0.32.
D2的基尼系数为:Gini(D2) = 1 - ( (10/15)^2 + (5/15)^2 ) = 0.4444.
加权后的基尼系数为: Gini(D|A) = (25/40) * 0.32 + (15/40) * 0.4444 ≈ 0.368.
基尼增益为:
因为 大于0,我们可以考虑根据这个特征去分割数据集,以提高模型的泛化能力。如果
小于或等于0,我们就不分割当前节点,并把它标记为叶节点。
后剪枝
做决策就像是在庞大的树上攀爬,每一次选择都是沿着不同的枝条前进。这棵树,就是我们的决策树模型。但有时候,树枝太多,反而让树变得复杂难以把握。这时候,我们就需要进行一番修剪,而这个过程,俗称“后剪枝”。
后剪枝,就像是在树长成之后,拿起园艺剪,审视每一颗小树苗,决定哪些需要留下,哪些应该剪掉。这样做的目的,是为了让整棵树显得不那么杂乱,更加清晰、简洁。
具体到我们的决策树模型,后剪枝就是把那些复杂的、细小的枝条砍掉,这些枝条可能只是模型过于细致的想象,对于我们理解整个问题并没有太大帮助,甚至可能导致模型太过于钻牛角尖,只在特定情况下才对,而忽略了更广泛的情况。这种情况,我们称之为过拟合。
通过后剪枝,我们可以让模型变得更加通用,就像是剪过枝的树更能抵御风雨一样,模型也能更好地适应新的数据。与预剪枝相比,后剪枝好比是让树先自由生长,再精心修整,而预剪枝则是在树刚刚发芽就开始限制其生长。因此,后剪枝通常会保留更多的枝条,让树的生长更自然,也因此它的学习能力更强,懂得的东西更多,对未来未知情况的适应能力就更强。也就是说,后剪枝相比预剪枝,一般能保留更多的分支,有更好的学习能力,因此泛化错误率通常会低于预剪枝。
具体步骤如下:
-
生成决策树:首先,我们需要构建一棵完整的决策树,这棵树通常会根据训练数据集长得很"深"和"繁茂",因此很容易对训练数据产生过拟合。
-
自底向上剪枝:剪枝的过程是自底向上的,意味着我们从树的叶节点开始,逐步向上检查每个非叶节点。对于每个节点,我们都会考虑如果把这个节点的所有子树剪掉(即,把这个节点变成一个叶节点),对模型泛化能力的影响。
-
评估剪枝效果:为了评估剪枝的效果,我们需要使用一个独立的验证数据集。验证集不参与训练,用来模拟模型在实际应用中遇到未知数据的情况。我们会计算每次潜在剪枝操作前后决策树在验证集上的准确率。准确率的计算公式是:
准确率 = 预测正确的样本数量 / 总样本数量.如果某次剪枝操作能够让模型在验证集上的准确率提高,那么我们就执行这次剪枝。
-
重复剪枝过程:继续执行步骤2和步骤3,不断地对决策树进行自底向上的评估和可能的剪枝操作。这个过程会一直重复,直到进一步的剪枝不再带来验证集准确率的提升。
后剪枝的过程可能会持续一段时间,直到达到某个停止条件,比如决策树结构稳定下来不再发生变化,或者是达到了预设的最大迭代次数。在整个过程中,关键的是要密切监控模型在验证集上的表现,以此作为是否进行剪枝的依据。通过这种方式,后剪枝有助于平衡模型的复杂度和泛化能力,最终得到一个既不过于简单,又不过于复杂的决策树模型。
本篇文章节选自数模百科 —— 决策树的构造 - 数模百科。
数模百科是一个由一群数模爱好者搭建的数学建模知识平台。我们想让大家只通过一个网站,就能解决自己在数学建模上的难题,把搜索和筛选的时间节省下来,投入到真正的学习当中。
我们团队目前正在努力为大家创建最好的信息集合,从用最简单易懂的话语和生动形象的例子帮助大家理解模型,到用科学严谨的语言讲解模型原理,再到提供参考代码。我们努力为数学建模的学习者和参赛者提供一站式学习平台,目前网站已上线,期待大家的反馈。
如果你想和我们的团队成员进行更深入的学习和交流,你可以通过公众号数模百科找到我们,我们会在这里发布更多资讯,也欢迎你来找我们唠嗑。















 1001
1001











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









