






 本文详细介绍了决策树在分类和回归问题中的应用,包括特征选择、数据分割、停止条件、模型生成和剪枝,以及使用sklearn库的实际代码示例。数模百科提供了全面的学习资源和支持。
本文详细介绍了决策树在分类和回归问题中的应用,包括特征选择、数据分割、停止条件、模型生成和剪枝,以及使用sklearn库的实际代码示例。数模百科提供了全面的学习资源和支持。
本篇文章节选自 决策树分类 - 数模百科 和 决策树回归 - 数模百科,如果你想了解更多关于决策树的信息,请移步 决策树 - 数模百科
在看这篇文章之前,强烈建议大家先阅读这篇文章 【数模百科】一篇文章讲清楚决策树如何进行构造和剪枝-CSDN博客
分类问题
步骤与详解
决策树算法的主要步骤是先进行特征选择,根据这个特征对数据集进行分割,将其划分为两个子集,以递归的方式重复上述操作,直到满足某个停止条件。在生成树的过程中和结束后对决策树进行适当的剪枝操作以提高其泛化性。最后用生成好的决策树模型进行预测。
特征选择
决策树的构建始于选择最佳的特征来分割数据。这通常是通过计算每个特征的信息增益(或其他类似的度量)来完成的。详见文章顶部的链接文章。
分割数据
一旦我们选择了最佳的特征,我们就根据该特征的每个可能的取值来分割数据。每个取值都会生成一个子节点。然后,我们在每个子节点上重复特征选择和分割的过程,直到满足某个停止条件。
停止条件
我们会继续在每个子节点上重复特征选择和分割的过程,直到满足某个停止条件。常见的停止条件有:
-
所有样本都属于同一类别
-
没有剩余的特征
-
增加分支不能显著提高数据的纯度
当满足停止条件时,我们将当前节点标记为叶节点,叶节点代表一个类别。
生成决策树
通过以上步骤,我们就生成了一个决策树。决策树的每个内部节点代表一个特征,每个分支代表一个可能的取值,每个叶节点代表一个类别。
使用决策树进行分类
当我们得到一个新的样本时,我们可以使用决策树进行分类。从根节点开始,根据样本在每个节点的特征取值来决定走哪个分支,直到达到一个叶节点。叶节点的类别就是我们对样本的预测结果。
代码
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
import matplotlib.pyplot as plt
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建决策树分类器并训练
clf = DecisionTreeClassifier(max_depth=3)
clf.fit(X_train, y_train)
# 预测测试集
y_pred = clf.predict(X_test)
# 可视化决策树
fig, ax = plt.subplots(figsize=(12, 12))
tree.plot_tree(clf, filled=True)
plt.show()这段代码首先加载了鸢尾花数据集,然后将数据集划分为训练集和测试集。接着,创建一个决策树分类器,并使用训练集对其进行训练。然后,使用训练好的决策树分类器对测试集进行预测。最后,将训练好的决策树进行可视化展示。
plot_tree函数生成的是决策树的图形表示。决策树是一种树形结构,其中每个内部节点表示一个特征(或属性),每个分支代表一个决策规则,每个叶节点代表一个输出(或结果)。
在plot_tree生成的图中:
-
每个节点都显示了一个判断条件,用来决定下一步的方向。例如,
X[3] <= 0.8表示如果第4个特征(索引从0开始)小于或等于0.8,那么就走左边的分支,否则走右边的分支。 -
gini表示该节点的不纯度,如果所有的样本都属于同一个类别,那么gini系数就是0,表示纯度最高。 -
samples表示进入这个节点的样本数量。 -
value表示这个节点中每个类别的样本数量。 -
class表示这个节点最终的预测结果,它是基于这个节点中样本数量最多的类别来确定的。 -
每个节点下面的分支代表满足该节点条件后的下一步决策。
-
叶子节点(没有子节点的节点)表示决策结果,即预测的类别。
运行结果:

回归问题
用于回归问题的决策树通常被称为回归树。回归树的主要思想和分类树类似,但它预测的是连续值,而不是离散的类别。
步骤与详解
回归树算法的主要步骤是先进行特征选择,根据这个特征对数据集进行分割,将其划分为两个子集,以递归的方式重复上述操作,直到满足某个停止条件。在生成树的过程中和结束后对回归树进行适当的剪枝操作以提高其泛化性。最后用生成好的回归树模型进行预测。
特征选择
回归树的特征选择通常基于最小化均方误差(MSE)或最小化平均绝对误差(MAE)。具体来说,我们需要对每一个特征,尝试所有可能的分割点,然后计算每个分割点的MSE或MAE。通常选择能使MSE或MAE最小的特征和分割点。
例如,假设我们有一个特征A,我们可以尝试将数据集 D 根据特征A的每个可能取值划分为两部分,然后计算每个划分的MSE。
对于每个分割点 t ,计算分割后的MSE或MAE。以MSE为例,公式如下:
其中, 和
是根据特征A的取值 t 划分的两个子集,
和
是两个子集的目标变量的均值。
这个公式的具体含义是:
-
计算子集
的目标变量的均值
和子集
的目标变量的均值
。
-
对于
。
-
对于
-
将这两部分的MSE求和,得到当前分割点 t 下的总MSE。
分割数据
一旦我们确定了最佳的特征和分割点,我们就可以根据这个特征和分割点将数据集划分为两个子集。然后,在每个子集上,我们重复特征选择和分割的过程。
停止条件
我们会继续在每个子节点上重复特征选择和分割的过程,直到满足某个停止条件。常见的停止条件有:
-
所有样本的目标变量都相同
-
没有剩余的特征
-
增加分支不能显著减小MSE或MAE
当满足停止条件时,我们将当前节点标记为叶节点。
确定叶节点的值
在回归问题中,叶节点的值通常是所有样本的目标变量的均值或中位数。这个值就是我们对到达这个叶节点的样本的预测结果。
剪枝
为了防止过拟合,我们通常需要对决策树进行剪枝。剪枝可以是预剪枝(在构建决策树的过程中进行)或后剪枝(在构建完决策树后进行)。剪枝的目标是找到一个平衡,使模型在训练数据上的表现良好,同时也能在未见过的数据上泛化。
预测
最后,当我们得到一个新的样本时,我们可以使用决策树进行预测。从根节点开始,根据样本在每个节点的特征取值来决定走哪个分支,直到达到一个叶节点。叶节点的值就是我们对这个样本的预测结果。
代码
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor, plot_tree
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
# 加载波士顿房价数据集
boston = load_boston()
X = boston.data
y = boston.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建决策树回归器并训练
reg = DecisionTreeRegressor(max_depth=3)
reg.fit(X_train, y_train)
# 预测测试集
y_pred = reg.predict(X_test)
# 计算并打印均方误差
mse = mean_squared_error(y_test, y_pred)
print('均方误差为:', mse)
# 可视化决策树
plt.figure(figsize=(15,10))
plot_tree(reg, filled=True, feature_names=boston.feature_names)
plt.show()这段代码加载了波士顿房价数据集,将数据集划分为训练集和测试集。然后,创建一个决策树回归器,并使用训练集对其进行训练。使用训练好的决策树回归器对测试集进行预测。计算并打印了预测结果的均方误差,用于评估回归器的性能。最后对分类结果进行可视化展示。
运行结果:
均方误差为: 13.491273032995437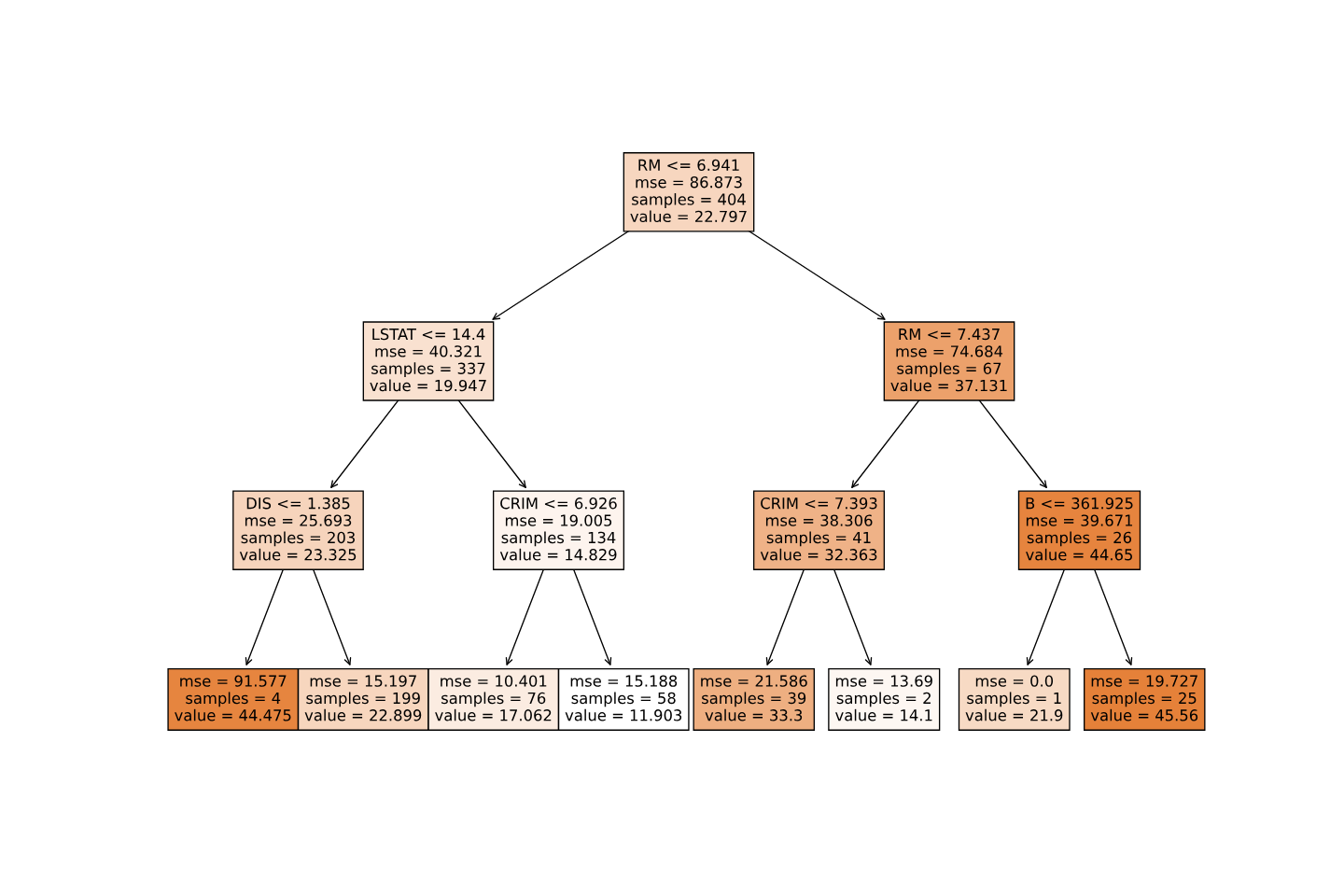
本篇文章节选自 决策树分类 - 数模百科 和 决策树回归 - 数模百科,如果你想了解更多关于决策树的信息,请移步 决策树 - 数模百科
数模百科是一个由一群数模爱好者搭建的数学建模知识平台。我们想让大家只通过一个网站,就能解决自己在数学建模上的难题,把搜索和筛选的时间节省下来,投入到真正的学习当中。
我们团队目前正在努力为大家创建最好的信息集合,从用最简单易懂的话语和生动形象的例子帮助大家理解模型,到用科学严谨的语言讲解模型原理,再到提供参考代码。我们努力为数学建模的学习者和参赛者提供一站式学习平台,目前网站已上线,期待大家的反馈。
如果你想和我们的团队成员进行更深入的学习和交流,你可以通过公众号数模百科找到我们,我们会在这里发布更多资讯,也欢迎你来找我们唠嗑。















 1121
1121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









