






华为嵌入式软件开发实习——leetcode面试刷题记录
88数组合并
排序算法
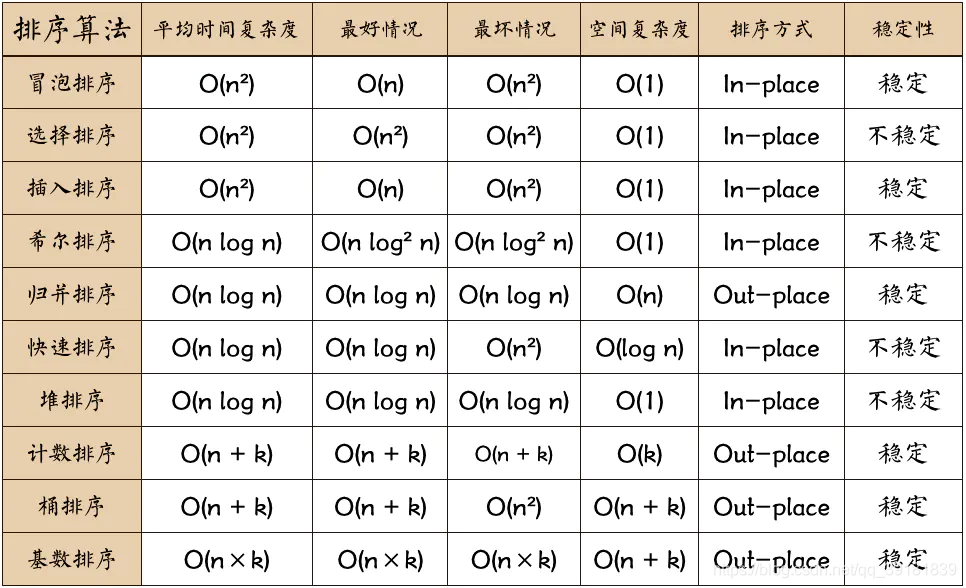
稳定与不稳定
如果一个排序算法能够保持具有相同键值的元素之间的原始相对次序,则称该算法是稳定的。反之,如果排序后这些元素的相对顺序可能发生改变,则称该算法是不稳定的。
插入排序 适用于顺序存储和链式存储 稳定 O(n2)
每一次将一个待排序列的记录,按照其关键字的大小插入到已经排好序的一组记录的适当位置上,直到全部插入。
void insertionSort(std::vector<int>& arr) {`
`int n = arr.size();`
`for (int i = 1; i < n; i++) {`
`int key = arr[i];`
`int j = i - 1;`
`// 将大于key的元素向后移动一个位置`
`while (j >= 0 && arr[j] > key) {`
`arr[j + 1] = arr[j];`
`j = j - 1;`
`}`
`// 插入key到正确的位置`
`arr[j + 1] = key;`
`}`
`}
冒泡排序 稳定 O(n2)
两两比较关键字,如逆序则交换顺序,较大关键字逐渐一端移动,直到序列有序。
选择排序 不稳定O(n2)
基本思想:每一趟排序从待排序的记录中选出关键字最小的记录,按顺序放在已排序的记录中,直到全部排完为止。
void select_sort(int arr[],int n){`
`int k;`
`for(int i = 1; i < n; i++){`
`k = i;`
`for(int j = i+1; j <= n; j++){`
`if(arr[k] > arr[j])`
`k = j;`
`}`
`if(k != i){`
`arr[0] = arr[i]; arr[i] = arr[k]; arr[k] = arr[0];`
`}`
`}`
`}
一直向后找最小的,找到了就替换
稳定性判断

快速排序 (n logn)
对冒泡的改进,采用“分治”的思想,对于一组数据,选择一个基准元素(base),通常选择第一个或最后一个元素,通过第一轮扫描,比base小的元素都在base左边,比base大的元素都在base右边,再有同样的方法递归排序这两部分,直到序列中所有数据均有序为止。
从右边开始查找比66小的数,找到的时候先等一下,再从左边开始找比66大的数,将这两个数借助66互换一下位置,继续这个过程直到两次查找过程碰头。
66 13 51 76 81 26 57 69 23
从右边找到23比66小,互换
23 13 51 76 81 26 57 69 66
从左边找到76比66大,互换
23 13 51 66 81 26 57 69 76
继续从右边找到57比66小,互换
23 13 51 57 81 26 66 69 76
从左边查找,81比66大,互换
23 13 51 57 66 26 81 69 76
从右边开始查找26比66小,互换
23 13 51 57 26 66 81 69 76
此时66左边的数都比66小,66右边的数都比66大,完成一轮排序,对这个数的两边再递归上述方法。
不稳定发生在中枢元素和a[j] 交换的时刻
归并排序 稳定 (n logn)
创建在归并操作上的一种有效的排序算法。算法是采用分治法(Divide and Conquer)的一个非常典型的应用,且各层分治递归可以同时进行。归并排序思路简单,速度仅次于快速排序,为稳定排序算法,一般用于对总体无序,但是各子项相对有序的数列。
-
分解(Divide):将n个元素分成个含n/2个元素的子序列。
-
解决(Conquer):用合并排序法对两个子序列递归的排序。
-
合并(Combine):合并两个已排序的子序列已得到排序结果。
堆排序 不稳定 (n logn)
堆一般指的是二叉堆,顾名思义,二叉堆是完全二叉树或者近似完全二叉树
1.完全二叉树 2.每个节点的值大于或者等于其子节点的值(最大堆),反之最小堆
一般用数组来表示堆,下标为 i 的结点的父结点下标为(i-1)/2;其左右子结点分别为 (2i + 1)、(2i + 2)
① 将待排序的序列构造成一个最大堆,此时序列的最大值为根节点
② 依次将根节点与待排序序列的最后一个元素交换
③ 再维护从根节点到该元素的前一个节点为最大堆,如此往复,最终得到一个递增序列
#include <iostream>
#include <algorithm>
using namespace std;
void max_heapify(int arr[], int start, int end) {
//建立父节点指标和子节点指标
int dad = start;
int son = dad * 2 + 1;
while (son <= end) { //若子节点指标在范围内才做比较
if (son + 1 <= end && arr[son] < arr[son + 1]) //先比较两个子节点大小,选择最大的
son++;
if (arr[dad] > arr[son]) //如果父节点大于子节点代表调整完毕,直接跳出函数
return;
else { //否则交换父子内容再继续子节点和孙节点比较
swap(arr[dad], arr[son]);
dad = son;
son = dad * 2 + 1;
}
}
}
void heap_sort(int arr[], int len) {
//初始化,i从最后一个父节点开始调整
for (int i = len / 2 - 1; i >= 0; i--)
max_heapify(arr, i, len - 1);
//先将第一个元素和已经排好的元素前一位做交换,再从新调整(刚调整的元素之前的元素),直到排序完毕
for (int i = len - 1; i > 0; i--) {
swap(arr[0], arr[i]);
max_heapify(arr, 0, i - 1);
}
}
int main() {
int arr[] = { 3, 5, 3, 0, 8, 6, 1, 5, 8, 6, 2, 4, 9, 4, 7, 0, 1, 8, 9, 7, 3, 1, 2, 5, 9, 7, 4, 0, 2, 6 };
int len = (int) sizeof(arr) / sizeof(*arr);
heap_sort(arr, len);
for (int i = 0; i < len; i++)
cout << arr[i] << ' ';
cout << endl;
return 0;
}
sort(nums1.begin(), nums1.end());//升序 针对vector<int>
80删除重复项2
一定注意nums[i]=nums[i+1]溢出的问题。
快慢指针
初始值为2
169多数元素
哈希表
155最小栈
150逆波兰数
atoi(token.c_str())
如果 token 确实是一个数字,代码接下来调用 atoi 函数来将这个数字字符串转换成一个整数值。atoi(代表 “ASCII to Integer”)是 C 标准库函数,用于将字符串转换为整数。
token.c_str():这个方法返回token字符串的 C 风格字符串版本(即以 null 终止的字符数组)。atoi需要这种类型的输入,因为它是一个 C 标准库函数,不直接接受 C++ 的std::string对象。
2两数相加
逆序存放,可以对应位相加再进位。
%取余数,/取整数
指针尽量留取头节点,保证有入口
ListNode *resultnode=new ListNode(sum%10); 创建val=sum%10的节点
53最后一个单词的长度
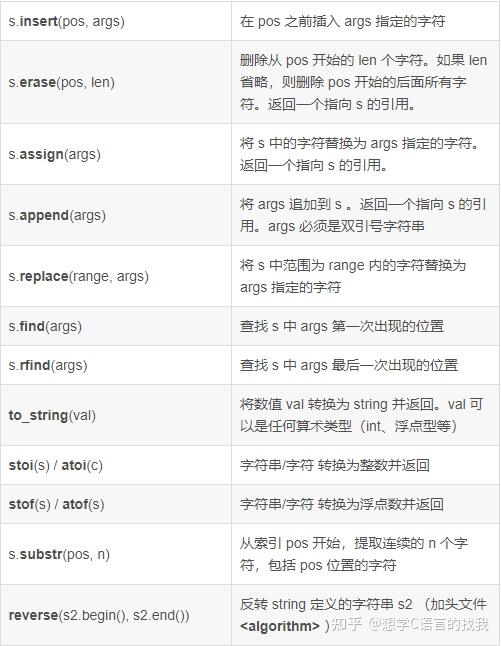
isalnum(c) // 当是字母或数字时为真
isalpha(c) // 当是字母时为真
isdigit(c) // 当是数字是为真
islower(c) // 当是小写字母时为真
isupper(c) // 当是大写字母时为真
reverse(s2.begin(), s2.end()); // 反转 string 定义的字符串 s2
stringstream类是<sstream>头文件中定义的流之一, 它的操作类似于cin、cout,常用于数据类型的转换(字符串转为数值型),除此之外还能用来对字符串进行分割操作
istringstream是一个从 头文件中提供的类,用于从字符串中进行输入操作,类似于从文件或标准输入(例如键盘)读取。istringstream` 对象将一个字符串转换为一个输入流,从而允许你像处理标凈输入流(cin)一样使用字符串数据。
getline
getline(istream &__is, string &__str, *char* __delim)
__is – Input stream. 输入流
__str – Buffer to store into. 用于接收的变量
__delim – Character marking end of line. 终止符
void Stringsplit(string str,const const char split)
{
istringstream iss(str); // 输入流
string token; // 接收缓冲区
while (getline(iss, token, split)) // 以split为分隔符
{
cout << token << endl; // 输出
}
}
字符串与字符
14最长公共前缀
减少str[i]=str[i+1]的使用,边界太容易出问题
使用常数赋值代替。
数据库相关
·内连接
交集

-- join
select * from A join B on A.id = B.id
-- inner join
select * from A inner join B on A.id = B.id
-- 逗号的连表方式就是内连接
select * from A , B where A.id = B.id
左外连接(左连接的全称)和左连接

-- left join
select * from A left join B on A.id = B.id
-- left outer join
select * from A left outer join B on A.id = B.id
连接条件 (ON A.id = B.id): 这个条件指定了如何将 A 表和 B 表的行匹配起来。在这个例子中,当 A 表中某行的 id 值与 B 表中某行的 id 值相等时,这两行就会被连接起来。
左外连接: 这意味着 A 表中的所有行都会出现在查询结果中。如果 A 表中的某行在 B 表中没有找到匹配的 id,则 B 表中的所有列在结果集中对应的值将会是 NULL。

右外连接同理
全连接 并集
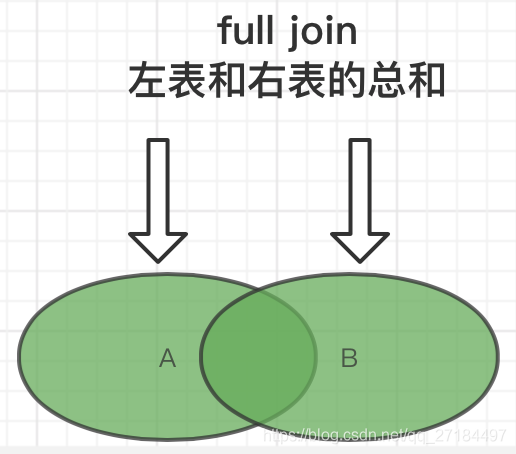
select * from a left join b on a.id = b.id
union
select * from a right join b on a.id = b.id
设计模式
工厂模式 标准化、批量生产
- **Factory:**工厂角色-负责实现创建所有实例的内部逻辑.
- **Product:**抽象产品角色-是所创建的所有对象的父类,负责描述所有实例所共有的公共接口。
- **ConcreteProduct:**具体产品角色-是创建目标,所有创建的对象都充当这个角色的某个具体类的实例


**优点:**客户类和工厂类分开。消费者任何时候需要某种产品,只需向工厂请求即可。消费者无须修改就可以接纳新产品。
**缺点:**是当产品修改时,工厂类也要做相应的修改
单例模式
优缺点
- 优点:全局只有一个实例,便于统一控制,同时减少了系统资源开销。
- 缺点:没有抽象层,扩展困难。
应用场景
适合需要做全局统一控制的场景,例如:全局唯一的编码生成器。
装饰模式
- **Component:**抽象构件
- **ConcreteComponent:**具体构件
- **Decorator:**抽象装饰类
- **ConcreteDecorator:**具体装饰类
优缺点
- 优点:比继承更加灵活(继承是耦合度很大的静态关系),可以动态的为对象增加职责,可以通过使用不同的装饰器组合为对象扩展N个新功能,而不会影响到对象本身。
- 缺点:当一个对象的装饰器过多时,会产生很多的装饰类小对象和装饰组合策略,增加系统复杂度,增加代码的阅读理解成本。
适用场景
- 适合需要(通过配置,如:diamond)来动态增减对象功能的场景。
- 适合一个对象需要N种功能排列组合的场景(如果用继承,会使子类数量爆炸式增长)
策略模式
优缺点
- 优点:策略模式提供了对“开闭原则”的完美支持,用户可以在不修改原有系统的基础上选择算法或行为。干掉复杂难看的if-else。
- 缺点:调用时,必须提前知道都有哪些策略模式类,才能自行决定当前场景该使用何种策略。
试用场景
一个系统需要动态地在几种可替换算法中选择一种。不希望使用者关心算法细节,将具体算法封装进策略类中。
注意事项
一定要在策略类的注释中说明该策略的用途和适用场景。
代理模式
淘宝店客服总是会收到非常多的重复问题,例如:有没有现货?什么时候发货?发什么快递?大量回答重复性的问题太烦了,于是就出现了小蜜机器人,他来帮客服回答那些已知的问题,当碰到小蜜无法解答的问题时,才会转到人工客服。这里的小蜜机器人就是客服的代理。

观察者模式
优缺点
- 优点:将复杂的串行处理逻辑变为单元化的独立处理逻辑,被观察者只是按照自己的逻辑发出消息,不用关心谁来消费消息,每个观察者只处理自己关心的内容。逻辑相互隔离带来简单清爽的代码结构。
- 缺点:观察者较多时,可能会花费一定的开销来发消息,但这个消息可能仅一个观察者消费。
适用场景
适用于一对多的的业务场景,一个对象发生变更,会触发N个对象做相应处理的场景。例如:订单调度通知,任务状态变化等。
注意事项
避免观察者与被观察者之间形成循环依赖,可能会因此导致系统崩溃。
new与malloc的区别
1、属性
new和delete是C++关键字,需要编译器支持;
malloc和free是库函数,需要头文件。
2、参数
使用new操作符申请内存分配时无须指定内存块的大小,编译器会根据类型信息自行计算。
malloc则需要显式地指出所需内存的尺寸。
3、返回类型
new操作符内存分配成功时,返回的是对象类型的指针,类型严格与对象匹配,无须进行类型转换,故new是符合类型安全性的操作符。
而malloc内存分配成功则是返回**void *** ,需要通过强制类型转换将void*指针转换成我们需要的类型。
4、内存区域
new做两件事:分配内存和调用类的构造函数,delete是:调用类的析构函数和释放内存。
而malloc和free只是分配和释放内存。
new操作符从自由存储区(free store)上为对象动态分配内存空间,
而malloc函数从堆上动态分配内存。
自由存储区是C++基于new操作符的一个抽象概念,*凡是通过new操作符进行内存申请,该内存即为自由存储区。*而堆是操作系统中的术语,是操作系统所维护的一块特殊内存,用于程序的内存动态分配,C语言使用malloc从堆上分配内存,使用free释放已分配的对应内存。自由存储区不等于堆,如上所述,布局new就可以不位于堆中。

java的各种锁
乐观锁与悲观锁
乐观锁
乐观锁(Optimistic Locking)基于这样的假设:冲突在系统中出现的频率较低,因此只在提交更新时才检查是否有冲突发生,而不是在数据读取时就立即锁定。
工作方式:
- 乐观锁通常通过在数据库表中使用版本号或时间戳字段来实现。每次记录被更新时,这个版本号或时间戳都会增加。
- 当事务试图提交更新时,系统会检查该记录自事务开始以来是否被其他事务更改过(即版本号或时间戳是否发生变化)。
- 如果中间没有其他事务对数据进行了修改,则更新成功;如果数据在读取后和更新前被其他事务更改过,则当前事务会回滚,通常伴随着一个冲突的解决策略。
悲观锁
悲观锁(Pessimistic Locking)是一种认为冲突在多用户系统中总是会发生的策略,因此在进行任何操作之前,都会先锁定数据,防止其他用户对同一数据进行修改。
工作方式:
- 当事务开始读取记录时,悲观锁将阻止其他任何事务修改这些记录,直到拥有锁的事务完成操作。
- 在传统的数据库系统中,悲观锁可能是通过数据库本身提供的锁机制实现,如行锁或表锁。
- 悲观锁可以有效避免数据的并发问题,如更新丢失、脏读和不可重复读
总结
- 如果你的应用经常面临多用户并发修改数据的情况,可能需要使用悲观锁来确保数据的一致性和完整性。
- 如果并发修改不那么频繁,使用乐观锁可以提高应用性能,因为它在大多数时间不需要持有锁,从而减少了锁竞争的开销。
公平锁与非公平锁
公平锁指按照锁申请的顺序来获取锁,线程直接进入队列中,队列中的第一个线程才能获取锁。非公平锁指多个线程获取锁时,直接尝试获取锁,只有当线程未获取到锁时才放入队列中。
公平锁的优点是不会造成饥饿,但整体性能会比非公平锁低,因为除等待队列中的第一个线程,其它线程都需要进行阻塞和唤醒操作。而非公平锁有几率直接获得锁,减少了线程阻塞和唤醒的次数,但可能会造成饥饿。因此在饥饿无影响或不会产生饥饿的场景下优先考虑非公平锁
可重入锁与不可重入锁
- 可重入锁又称递归锁,是指同一线程在外层获取锁后,进入内层方法再次获取同一锁时会自动获取锁。可重入锁的好处是可以一定程度避免死锁。
排他锁与共享锁
- 排它锁和共享锁的主要区别在于互斥资源锁是否能被多个线程同时持有。同时只能被一个线程持有称为排它锁;当能够被多个线程同时持有称为共享锁。
MySQL的锁
在数据库中,锁是用于管理对数据库资源的并发访问的一种机制。锁的主要目的是确保数据的一致性和完整性,在多用户环境下,防止数据因为同时被多个事务访问而产生冲突。锁机制可以确保每个事务都像在隔离的环境中执行一样,不被其他事务的操作干扰。
表锁
LOCK TABLES tablename WRITE; -- 加写锁
LOCK TABLES tablename READ; -- 加读锁
UNLOCK TABLES; -- 释放锁
行锁
SELECT * FROM tablename WHERE condition FOR UPDATE; -- 对选中的行加写锁
SELECT * FROM tablename WHERE condition LOCK IN SHARE MODE; -- 对选中的行加读锁
其它锁子
- 互斥锁加锁失败后,线程释放CPU,给其他线程;
- 自旋锁加锁失败后,线程会忙等待,直到它拿到锁;
持有互斥锁的线程在看到锁已经有主了之后,就会礼貌的退出,等待之后锁释放时自己被系统唤醒;而自旋锁呢,它居然在反复的询问锁使用完了没有,这实在是… 我写个while循环反复争夺资源,那不就是自旋锁咯?不会吧,不会吧,不会真的有人用自旋锁吧?谁更轻松高效这不是一目了然吗?
互斥锁
-
优点
- 能效:由于等待锁的线程会进入睡眠状态,因此不会占用CPU资源,从而提高了系统的能效。
- 公平性:大多数操作系统实现的互斥锁机制都会尽力保证等待锁的线程不会饿死(即,它们最终会获得锁)。
-
缺点
- 上下文切换成本:线程从运行状态到睡眠状态的转换涉及到上下文切换,这可能是资源消耗较大的操作。
- 死锁风险:不当使用可能导致死锁,尤其是在复杂的锁定方案中。
-
使用场景
当线程需要长时间持有锁时。
在锁的竞争不频繁,但保持锁的时间较长的情况下。
自旋锁
- 优点
- 响应时间:自旋锁不涉及线程的睡眠和唤醒,可以提供更快的响应时间,因为线程始终处于运行状态。
- 简单高效:对于锁持有时间非常短的情况,自旋锁通常比互斥锁更高效。
- 缺点
- CPU资源消耗:由于线程会持续运行而不是睡眠,它会占用大量CPU资源,这在单核处理器上尤其不利。
- 无公平性:自旋锁通常不保证公平性,容易造成线程饥饿。
使用场景
- 锁持有时间非常短。
- 多核系统中,CPU资源足够时。
上下文切换

互斥锁的临界区大小问题
在并发编程中,临界区指的是多个进程或线程访问共享资源的代码段。为了确保数据的一致性和避免竞态条件(Race Condition),我们使用互斥锁来对临界区进行保护。
一个临界区越小,意味着只有很少的代码需要在同一时间内被一个线程或进程访问。这有以下几个好处:
-
减少竞争:当临界区越小,只有很少的代码需要互斥访问共享资源,这样可以减少线程之间的竞争。这可以提高系统的吞吐量和性能。
-
减少死锁风险:当临界区越小,锁的持有时间就会减少,从而降低了出现死锁的可能性。死锁是指两个或多个进程无限期地等待对方释放资源的情况。
-
提高并发性:临界区越小,就有更多的线程可以并发地进行计算,而不需要等待其他线程完成。
然而,将临界区划分得太小也会带来一些问题:
-
锁开销:互斥锁的获取和释放都需要一定的开销。如果临界区太小,那么频繁地获取和释放锁可能会导致额外的开销,从而降低性能。
-
数据局部性:如果临界区的代码太散布,那么访问共享资源的次数可能会增加。这可能会导致更多的缓存失效,从而降低系统性能。
因此,在设计并发程序时,需要找到一个平衡点,将临界区划分为足够小的代码段,以最大程度地减少竞争和提高并发性,同时避免将临界区划分得过于细小引起的额外开销。
局部变量、静态变量、全局变量
局部变量就是函数内定义的变量。存储在栈区。一般是不初始化的。作用域为函数内。
全局变量就是定义在函数外的变量。存储在常量区。初始化为0的,有一个初始值。作用域为全局,一直存在,直到程序结束。 可以给不同文件通信。
遇到const,就会退化为静态变量的作用域,只能在本文件中作用。如果想要在文件外使用const 全局变量,就需要在const外面加上个extern。
静态变量就是加了static的变量。 static int a = 1 存储在常量区。初始化为0的,有一个初始值。作用域:只能自己看到。定义在函数里的,只能在函数里面被看到,在文件里的,只能被文件看到。 全局的一个计数器之类的操作。
全局变量就是定义在函数外的变量。存储在常量区。初始化为0的,有一个初始值
静态变量就是加了static的变量。 static int a = 1 存储在常量区。初始化为0的,有一个初始值
static的作用
static存在的意义,就是把一个变量和一个作用域绑定,在这个作用域,它都存在,但离开了这个作用域,这个变量就不存在。(可以结合上述静态变量理解)
static应用在函数上,这个函数就只能在本文件内部使用,事实上,基本上所有的函数,默认都是static。
而static作用在类上,这个函数也就只能在这个类里面调用了。
tips:static 不要和extern混着用
全局变量和静态变量定义(而非声明)在头文件中会带来什么后果?
因为头文件,最后是直接替换到对应的.cc文件中的。
这就意味着,把全局变量定义到.h中,是找死,因为.h会被很多文件包涵,编译不过。
而静态变量定义在头文件中,包涵.h的.cc文件,都会有一个静态变量。这样副本太多了。一般还是避免一下。
深拷贝与浅拷贝
浅拷贝就比如像引用类型,而深拷贝就比如值类型。
浅拷贝是指源对象与拷贝对象共用地址,仅仅是引用的变量不同(名称不同)。对其中任何一个对象的改动都会影响另外一个对象。
举个例子,一个人一开始叫张三,后来改名叫李四了,可是还是同一个人,不管是张三缺胳膊少腿还是李四缺胳膊少腿,都是这个人倒霉。
深拷贝是指 源对象与拷贝对象互相独立数据复制 ,其中任何一个对象的改动都不会对另外一个对象造成影响。拥有各自的内存地址。
个变量就不存在。(可以结合上述静态变量理解)
static应用在函数上,这个函数就只能在本文件内部使用,事实上,基本上所有的函数,默认都是static。
而static作用在类上,这个函数也就只能在这个类里面调用了。
tips:static 不要和extern混着用
全局变量和静态变量定义(而非声明)在头文件中会带来什么后果?
因为头文件,最后是直接替换到对应的.cc文件中的。
这就意味着,把全局变量定义到.h中,是找死,因为.h会被很多文件包涵,编译不过。
而静态变量定义在头文件中,包涵.h的.cc文件,都会有一个静态变量。这样副本太多了。一般还是避免一下。
深拷贝与浅拷贝
浅拷贝就比如像引用类型,而深拷贝就比如值类型。
浅拷贝是指源对象与拷贝对象共用地址,仅仅是引用的变量不同(名称不同)。对其中任何一个对象的改动都会影响另外一个对象。
举个例子,一个人一开始叫张三,后来改名叫李四了,可是还是同一个人,不管是张三缺胳膊少腿还是李四缺胳膊少腿,都是这个人倒霉。
深拷贝是指 源对象与拷贝对象互相独立数据复制 ,其中任何一个对象的改动都不会对另外一个对象造成影响。拥有各自的内存地址。
举个例子,一个人名叫张三,后来用他克隆(假设法律允许)了另外一个人,叫李四,不管是张三缺胳膊少腿还是李四缺胳膊少腿都不会影响另外一个人。比较典型的就是Value(值)对象,如预定义类型Int32,Double,以及结构(struct),枚举(Enum)等。

















 836
836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









