







目录
上次是将服务器和客户端搭建好,实现了本地的文件传输。但是身份验证却没有实现,另外数据也缺少存储的地方,因此这次计划完成前端的登录验证功能和网页的文件传输下载以及连接数据库。
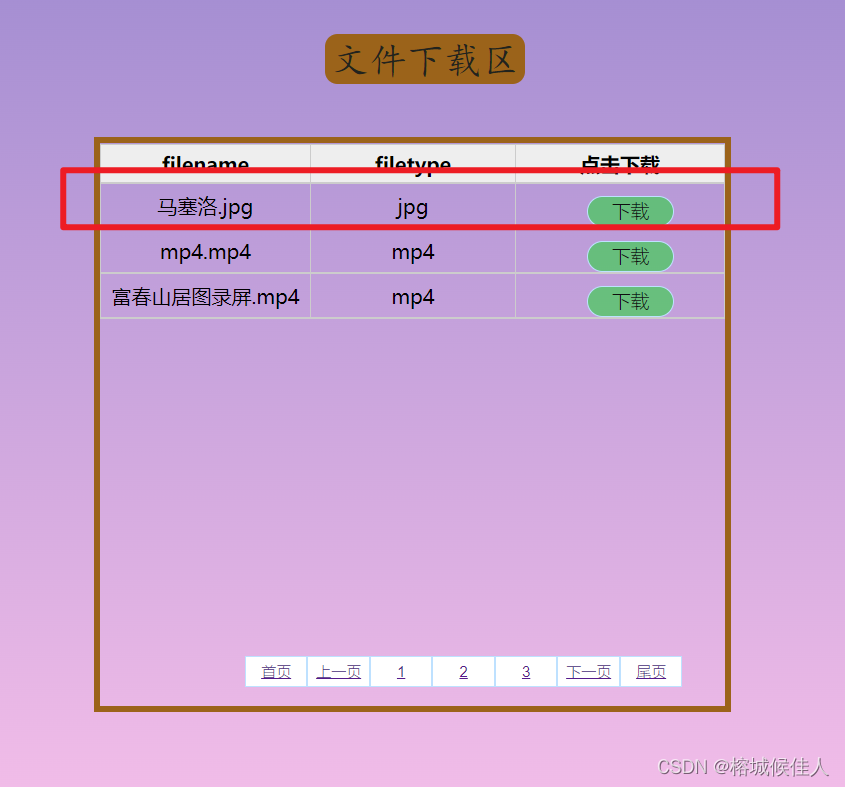
效果展示
一、python连接数据库
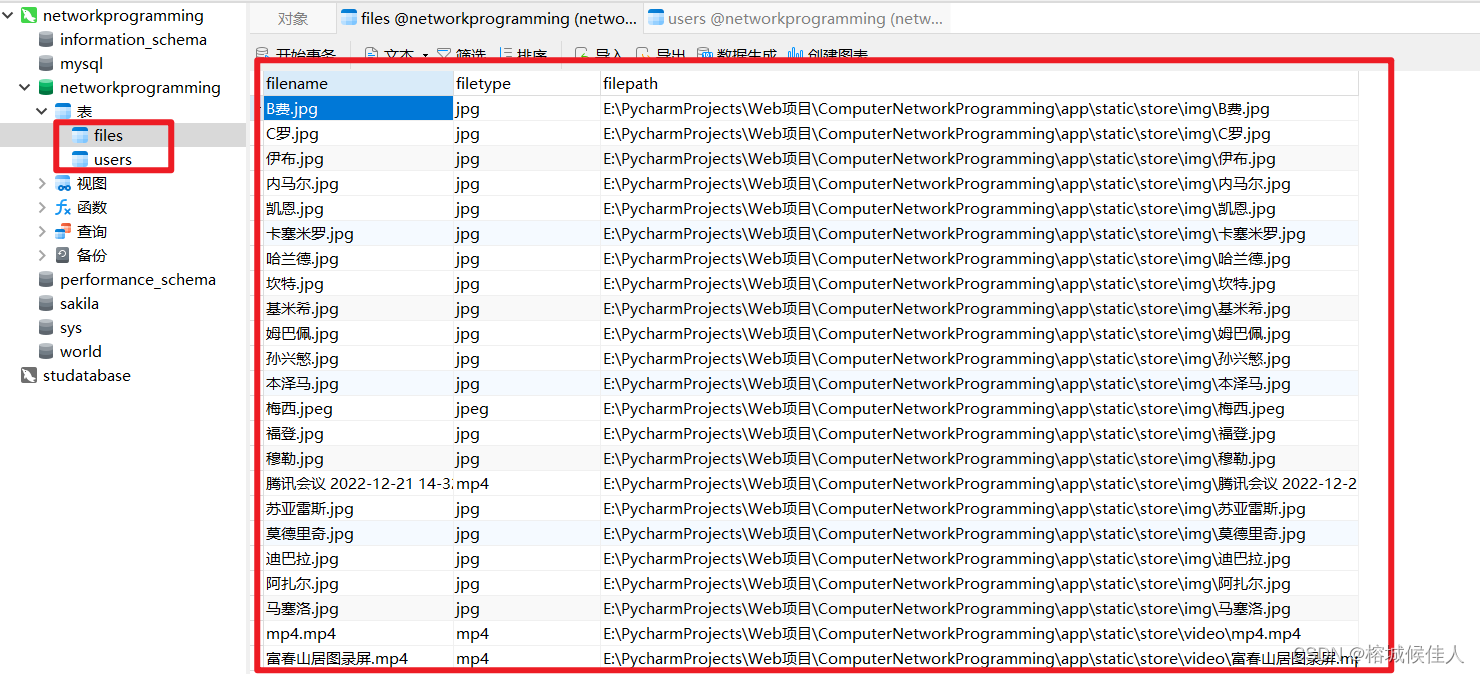
我的登录验证功能是基于数据库实现的,因此首先要连接数据库。我这边采用的工具是:
数据库:MySQL数据库
操纵数据库的工具:Navicat(网上有破解版,很容易搜到)可以可视化操作数据库而不用借助命令行
Python对应的库:pymysql.
版本:都下载最新的就可以了,没有兼容问题
在完成上述工具的下载以后,就可以连接数据库了。
import pymysql
db = pymysql.connect(host='localhost', port=3306, user='root',
password="下载MySQL时自己设置的密码",
db='networkprogramming(在MySQL中创建的数据库的名称)')
cursor = db.cursor()连接数据库的过程就三行代码,导入pymql,然后建立数据库的实例对象db,最后创建用于操作数据库的游标cursor
二、登录验证(前端+后端)
为了实现登录验证的功能,我们需要获取前端表单提供的账号和密码数据,然后在后端进行逻辑验证。
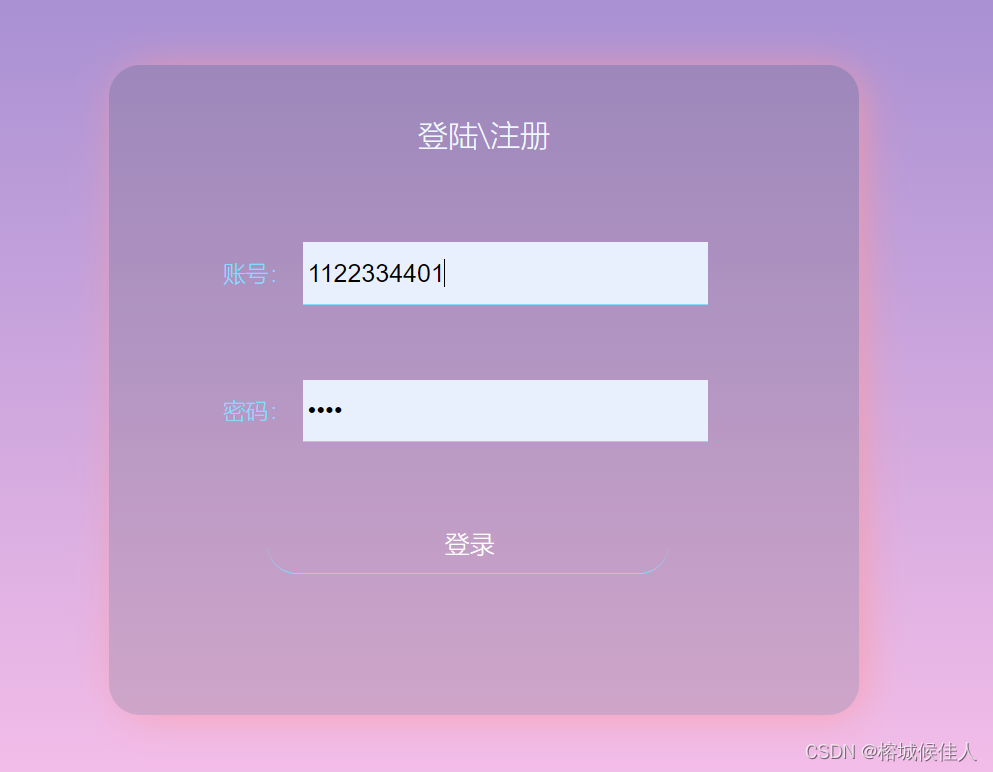
前端的登录页面
首先是前端的登录代码login.html。当然这里我借用了一些样式(通过指定class)和一点点js的内容,但是没有这些依旧可以实现登录验证的功能
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>登陆页面</title>
</head>
<body>
<div class="login">
<h2>登陆\注册</h2>
<div class="login_form">
<form method="POST">
<span>账号:</span>
<input type="text" placeholder="请输入账号" name="count">
<br>
<span>密码:</span>
<input type="password" placeholder="请输入密码" name="pwd">
<div class="btn">
<input type="submit" value="登录" class="login_btn" onclick="login()">
<br>
</div>
</form>
</div>
</div>
</body>对应的样式和js
<script>
function login() {
console.log('登录按钮点击了');
}
</script>
<style>
body {
padding: 0;
margin: 0;
height: 100vh;
display: flex;
justify-content: center;
background-image: linear-gradient(#a18cd1 0%, #fbc2eb 100%);
background-size: cover;
flex: 1;
align-items: center;
}
.login {
text-align: center;
margin: 0 auto;
width: 600px;
height: 520px;
background-color: rgba(87, 86, 86, 0.2);
border-radius: 25px;
box-shadow: 5px 2px 35px -7px #ff9a9e;
}
.login h2 {
margin-top: 40px;
color: aliceblue;
font-weight: 100;
}
.login_form {
padding: 20px;
}
.login_form span {
color: rgb(131, 220, 255);
font-size: 18px;
font-weight: 100;
}
.login_form input {
background-color: transparent;
width: 320px;
padding: 2px;
text-indent: 2px;
color: white;
font-size: 20px;
height: 45px;
margin: 30px 30px 30px 5px;
outline: none;
border: 0;
border-bottom: 1px solid rgb(131, 220, 255);
}
input::placeholder {
color: #fbc2eb;
font-weight: 100;
font-size: 18px;
font-style: italic;
}
.login_btn {
background-color: rgba(255, 255, 255, 0.582);
border: 1px solid rgb(190, 225, 255);
padding: 10px;
width: 240px;
height: 60px;
border-radius: 30px;
font-size: 30px;
color: rgb(100, 183, 255);
font-weight: 100;
margin-top: 15px;
}
.login_btn:hover {
box-shadow: 2px 2px 15px 2px rgb(190, 225, 255);
background-color: transparent;
color: white;
/* 选择动画 */
animation: login_mation 0.5s;
}
/* 定义动画 */
@keyframes login_mation {
from {
background-color: rgba(255, 255, 255, 0.582);
box-shadow: 0px 0px 15px 2px rgb(190, 225, 255);
}
to {
background-color: transparent;
color: white;
box-shadow: 2px 2px 15px 2px rgb(190, 225, 255);
}
}
</style>
</html>
好了,有了上述的前端代码我们就可以构建如下的登录页面了,并且用户提交的账号和密码信息可以在后端通过指定"count"和pwd"来获取
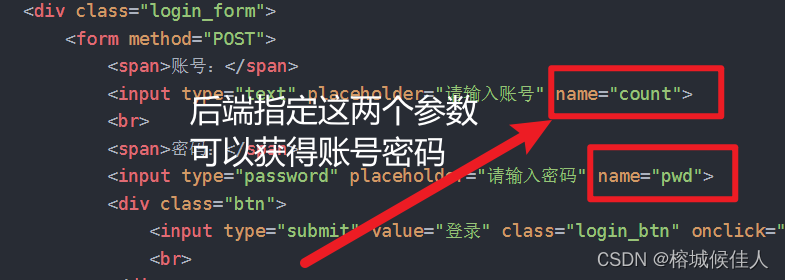

后端结合数据库实现登录验证
后端验证的完整逻辑如下。首先我是借助Flask框架进行网页开发的,因此需要遵循相关的开发规则,但也很简单。
首先需要创建一个flaks实例app,然后定义一个视图函数用来处理登录页面。这里的逻辑就是只要到了"/"这个页面,就会由这个函数执行相关的操作。
app = Flask(__name__)
@app.route('/', methods=["GET", "POST"])
def index():
# 获取提交的账号密码
count = request.form.get('count')
pwd = request.form.get('pwd')
# 连接数据库
try:
db = pymysql.connect(host='localhost', port=3306, user='root', password="下载MySQL时自己设定的密码", db='networkprogramming')
cursor = db.cursor()
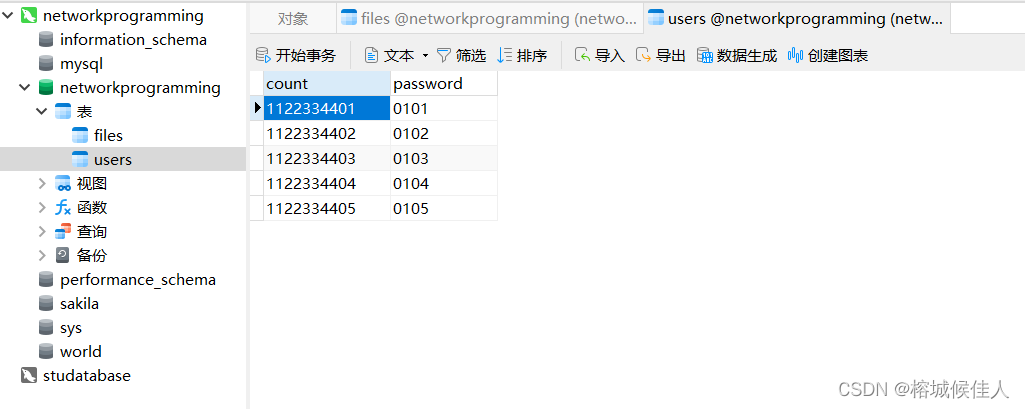
sql = 'select * from users'
cursor.execute(sql)
result = cursor.fetchall()
# 登录验证
flag = False
for info in result:
if count == info[0] and pwd == info[1]:
flag = True
break
if flag:
print("登录成功!")
db.commit()
return redirect(url_for("upload"))
else:
print("登录失败!")
return render_template("login.html")
except pymysql.Error as e:
print(f"发生错误:{str(e)}")
traceback.print_exc()
db.rollback()
db.close()
return render_template('login.html', msg='数据库连接失败!请重新登录')
首先获取登录界面输入的账号和密码,然后再连接数据库,之后取出数据库中的users表中的所有数据,然后一个一个验证,数据库中有这条记录的话,就使用redirect重定向函跳转到数据上传的页面。否则重新返回登录的页面。当然整个逻辑是嵌套在一个try except中,如果连接数据库失败也会返回登录页面并提示数据库连接失败。
好的,那么到此为止我们的身份验证功能就算是完成了,只要用户账号密码正确,则可以进入到文件上传页面,否则需要重新输入账号密码。(注册功能暂时没有提供,因此需要直接在数据库中添加用户,后续有时间应该会添加添加功能,和登录的逻辑是类似的)
三、网页版文件的上传下载
为了实现借助网页实现最终的文件上传下载,我们需要先让网页可以上传文件到客户端的数据库中,再借由之前实现的客户服务模式由客户端把文件上传到服务端所在的数据库;下载是一样的道理,先由服务端的数据库把文件传输给客户端的数据库,再由网页的下载功能下载客户端中的数据,从而实现网页版的TCP文件传输服务。
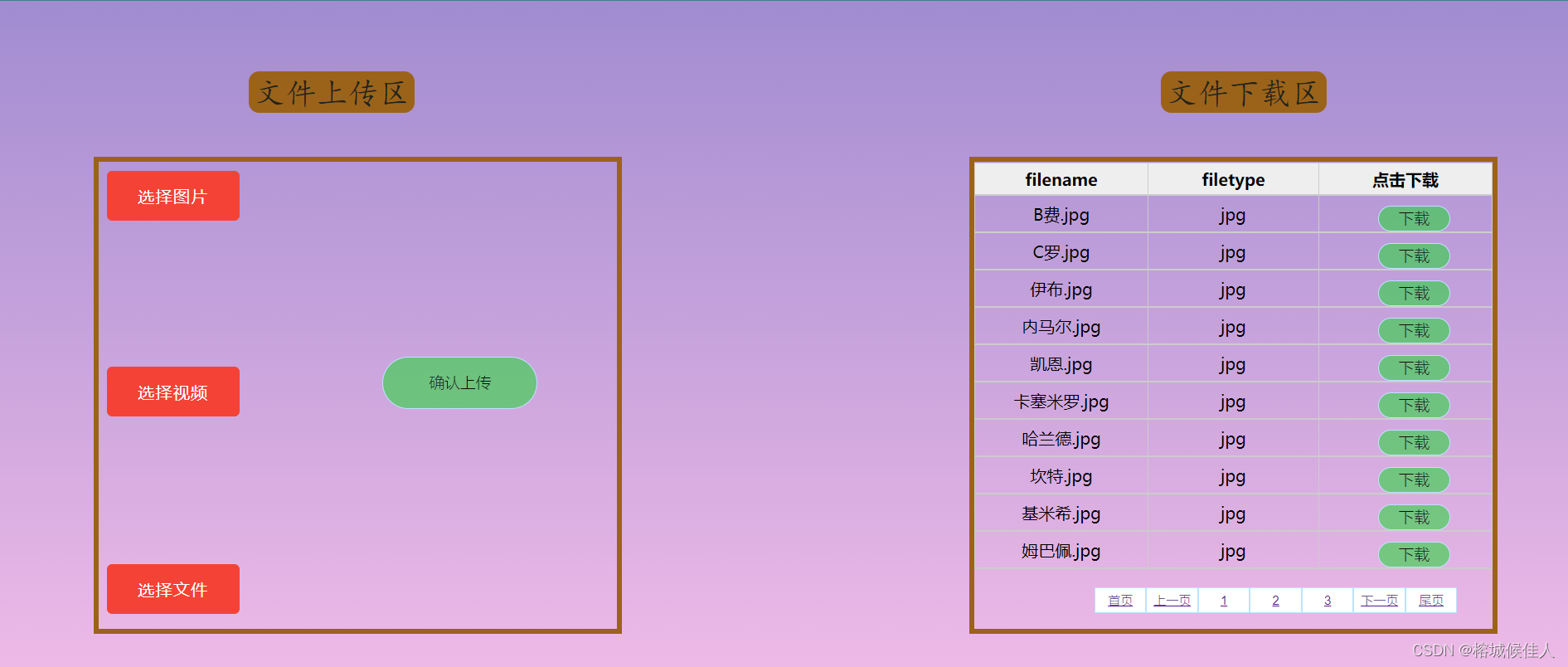
因此,这里我们首先要做的事让我们的文件上传页面upload.html可以提供本地文件上传和下载服务。
upload.html提供文件上传与下载服务
<body>
<div>
<p id="upload">文件上传区</p>
</div>
<div>
<p id="download">文件下载区</p>
</div>
<div id="upload-area">
<form action="/process" method="POST" enctype="multipart/form-data">
<input id="selectimg" type="file" class="clip" name="img">
<label for="selectimg" class="button">选择图片</label>
<br><br><br><br><br><br><br>
<input id="selectvideo" type="file" class="clip" name="video">
<label for="selectvideo" class="button">选择视频</label>
<br><br><br><br><br><br><br>
<input id="selecttxt" type="file" class="clip" name="file">
<label for="selecttxt" class="button">选择文件</label>
<input type="submit" value="确认上传" class="up" onclick="login()">
<br><br><br><br><br><br><br>
</form>
</div>
<div id="download-area">
<table border="0" cellspacing="0" cellpadding="0">
<tr>
<th>filename</th>
<th>filetype</th>
<th>点击下载</th>
</tr>
{% for index in index_list %}
<tr>
<td>{{ results[index - 1][0] }}</td>
<td>{{ results[index - 1][1] }}</td>
<td><a href="{{ results[index - 1][2] }}" download="{{ results[index - 1][0] }}">
<button class="down">下载</button>
</a></td>
</tr>
{% endfor %}
</table>
<nav aria-label="Page navigation" id="pagination">
<ul class="pagination">
{{ html|safe }}
</ul>
</nav>
</div>
</body>这里分文件上传与下载介绍
文件上传部分(前端)
在文件上传部分我们利用了一个form表单,并且指定了enctype="multipart/form-data"属性,这样就允许一个表单有多个输入,最后利用一个上传按钮把所有输入的文件一起提交到指定地址/process。
<div id="upload-area">
<form action="/process" method="POST" enctype="multipart/form-data">
<input id="selectimg" type="file" class="clip" name="img">
<label for="selectimg" class="button">选择图片</label>
<br><br><br><br><br><br><br>
<input id="selectvideo" type="file" class="clip" name="video">
<label for="selectvideo" class="button">选择视频</label>
<br><br><br><br><br><br><br>
<input id="selecttxt" type="file" class="clip" name="file">
<label for="selecttxt" class="button">选择文件</label>
<input type="submit" value="确认上传" class="up" onclick="login()">
<br><br><br><br><br><br><br>
</form>
</div>文件上传部分(后端)
然后在后端利用process视图函数对提交来的文件进行保存到客户端数据库的处理
@app.route('/process', methods=['POST'])
def process():
# 接收上传来的文件并保存
if request.method == 'POST':
img = request.files['img']
if img:
img_name = img.filename # 接收图片名称
img_type = img_name.split('.')[-1] # 图片类型
img_path = os.path.join(r'E:\PycharmProjects\Web项目\ComputerNetworkProgramming\app\static\store\img',
img_name)
store(img_name, img_type, img_path) # 存到数据库
img.save(img_path)
print(f'{img_name}已保存至数据库!')
if request.method == 'POST':
video = request.files['video']
if video:
video_name = video.filename # 接收图片名称
video_type = video_name.split('.')[-1]
video_path = os.path.join(r'E:\PycharmProjects\Web项目\ComputerNetworkProgramming\app\static\store\video',
video_name)
store(video_name, video_type, video_path)
video.save(video_path)
print(f"{video_name}已保存至数据库!")
if request.method == 'POST':
file = request.files['file']
if file:
file_name = file.filename # 接收图片名称
file_type = file_name.split('.')[-1]
file_path = os.path.join(r'E:\PycharmProjects\Web项目\ComputerNetworkProgramming\app\static\store\file',
file_name)
store(file_name, file_type, file_path)
file.save(file_path)
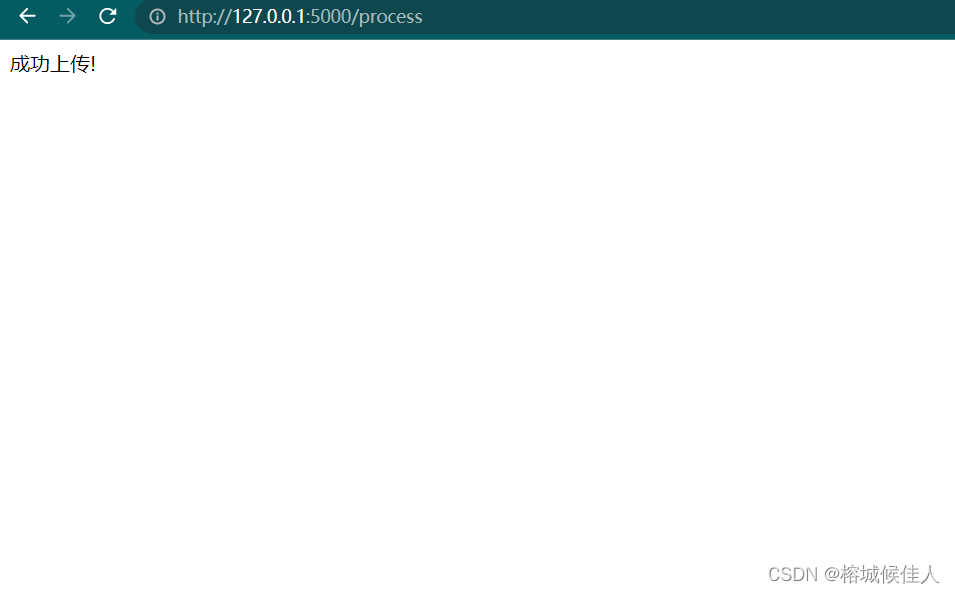
print(file_name)
return '成功上传!'这里我们分别对三种上传的文件进行接收,以第一个图片为例,其他两个类似。我们首先利用request.files['img']接收前端上传的img,然后分别获取它的名称和文件类型,随后指定本地保存路径(也是客户端的数据库的路径,我的电脑相当于所有的客户端的数据库),然后调用store()方法把文件存到数据库中。(store()函数下面有讲解)
 store()函数:连接数据库,然后把传入的参数(即文件的信息)利用sql的插入语句存入到数据库中(这一步也相当于实现了客户端传输给服务端,但是还没真正调用客户端和服务器,后面会调用)。
store()函数:连接数据库,然后把传入的参数(即文件的信息)利用sql的插入语句存入到数据库中(这一步也相当于实现了客户端传输给服务端,但是还没真正调用客户端和服务器,后面会调用)。
def store(name, type, path):
"""数据存储到数据库"""
db = pymysql.connect(host='localhost', port=3306, user='root', password="下载MySQL时设定的密码", db='networkprogramming')
cursor = db.cursor()
sql = 'insert into files(filename,filetype,filepath) values(%s,%s,%s)'
data = (name, type, path)
cursor.execute(sql, data)
db.commit()
db.close()到这里我们就结合前后端实现了文件的网页版上传和保存到客户端的数据库(其实也已经保存到了服务器的数据库,即MySQL数据库,但是还没调用我们的程序而已。)
文件下载部分
网页的文件下载其实很简单,利用a标签就可以实现,关于这个问题还困扰了我一段时间,并最终写在了这篇文章中html利用a标签实现下载本地的文件,大家可以看这篇文章获得更详细的说明。
<div id="download-area">
<table border="0" cellspacing="0" cellpadding="0">
<tr>
<th>filename</th>
<th>filetype</th>
<th>点击下载</th>
</tr>
{% for index in index_list %}
<tr>
<td>{{ results[index - 1][0] }}</td>
<td>{{ results[index - 1][1] }}</td>
<td><a href="{{ results[index - 1][2] }}" download="{{ results[index - 1][0] }}">
<button class="down">下载</button>
</a></td>
</tr>
{% endfor %}
</table>
<nav aria-label="Page navigation" id="pagination">
<ul class="pagination">
{{ html|safe }}
</ul>
</nav>
</div>除了下载之外,在网页部分还有一个重要的部分就是如何分页展示自己服务器数据库中的文件信息,这个我觉得这篇博客讲得很清楚,我后端的部分代码也是借鉴它的修改的。https://dalin.blog.csdn.net/article/details/80295101![]() https://dalin.blog.csdn.net/article/details/80295101
https://dalin.blog.csdn.net/article/details/80295101
那么网页前端的文件下载和展示功能就已经全部完成, 后端的话其实就是需要利用到这个类,它最终返回的就是每个分页的超链接
# coding: utf-8
# 作者(@Author): Messimeimei
# 创建时间(@Created_time): 2022/12/23 17:00
"""实现前端分页展示"""
from urllib.parse import urlencode
class Pagination(object):
"""
自定义分页
"""
def __init__(self, current_page, total_count, base_url, params, per_page_count=10, max_pager_count=11):
try:
current_page = int(current_page)
except Exception as e:
current_page = 1
if current_page <= 0:
current_page = 1
self.current_page = current_page
# 数据总条数
self.total_count = total_count
# 每页显示10条数据
self.per_page_count = per_page_count
# 页面上应该显示的最大页码
max_page_num, div = divmod(total_count, per_page_count)
if div:
max_page_num += 1
self.max_page_num = max_page_num
# 页面上默认显示11个页码(当前页在中间)
self.max_pager_count = max_pager_count
self.half_max_pager_count = int((max_pager_count - 1) / 2)
# URL前缀
self.base_url = base_url
# request.GET
import copy
params = copy.deepcopy(params)
get_dict = params.to_dict()
self.params = get_dict
@property
def start(self):
return (self.current_page - 1) * self.per_page_count
@property
def end(self):
return self.current_page * self.per_page_count
def page_html(self):
# 如果总页数 <= 11
if self.max_page_num <= self.max_pager_count:
pager_start = 1
pager_end = self.max_page_num
# 如果总页数 > 11
else:
# 如果当前页 <= 5
if self.current_page <= self.half_max_pager_count:
pager_start = 1
pager_end = self.max_pager_count
else:
# 当前页 + 5 > 总页码
if (self.current_page + self.half_max_pager_count) > self.max_page_num:
pager_end = self.max_page_num
pager_start = self.max_page_num - self.max_pager_count + 1 # 倒这数11个
else:
pager_start = self.current_page - self.half_max_pager_count
pager_end = self.current_page + self.half_max_pager_count
page_html_list = []
# {source:[2,], status:[2], gender:[2],consultant:[1],page:[1]}
# 首页
self.params['page'] = 1
first_page = '<button class="alabel"><a href="%s?%s">首页</a></button>'.encode("utf-8").decode("utf-8") % (
self.base_url, urlencode(self.params),)
page_html_list.append(first_page)
# 上一页
if self.current_page == 1:
self.params["page"] = 1
else:
self.params["page"] = self.current_page - 1
if self.params["page"] < 1:
pervious_page = '<button class="alabel"><a href="%s?%s" aria-label="Previous">上一页</span></a></button>'.encode(
"utf-8").decode(
"utf-8") % (self.base_url, urlencode(self.params))
else:
pervious_page = '<button class="alabel"><a href = "%s?%s" aria-label = "Previous" >上一页</span></a></button>'.encode(
"utf-8").decode("utf-8") % (
self.base_url, urlencode(self.params))
page_html_list.append(pervious_page)
# 中间页码
for i in range(pager_start, pager_end + 1):
self.params['page'] = i
if i == self.current_page:
temp = '<button class="alabel"><a href="%s?%s">%s</a></button>' % (self.base_url, urlencode(self.params), i,)
else:
temp = '<button class="alabel"><a href="%s?%s">%s</a></button>' % (self.base_url, urlencode(self.params), i,)
page_html_list.append(temp)
# 下一页
self.params["page"] = self.current_page + 1
if self.params["page"] > self.max_page_num:
self.params["page"] = self.current_page
next_page = '<button class="alabel"><a href = "%s?%s" aria-label = "Next">下一页</span></a></button>'.encode(
"utf-8").decode(
"utf-8") % (self.base_url, urlencode(self.params))
else:
next_page = '<button class="alabel"><a href = "%s?%s" aria-label = "Next">下一页</span></a></button>'.encode("utf-8").decode(
"utf-8") % (
self.base_url, urlencode(self.params))
page_html_list.append(next_page)
# 尾页
self.params['page'] = self.max_page_num
last_page = '<button class="alabel"><a href="%s?%s">尾页</a>'.encode("utf-8").decode("utf-8") % (
self.base_url, urlencode(self.params),)
page_html_list.append(last_page)
return ''.join(page_html_list)
然后再利用返回的超链接实现分页操作。下面的代码就是文件下载部分的后端,其实主要是在获得所有分页的超链接以后再在前端循环展示对应分页的数据。(我这里可能讲的不是很清楚,大家还是参考上面的博客,看懂了就可以自己修改分页代码了)当然我这里的分页展示还有个小缺点就是不能用省略号代替中间的分页,也就是说会把所有分页的页码展示出来,这肯定会导致浏览器的满屏溢出,因此后面还需要修改。
@app.route("/upload", methods=['POST', "GET"])
def upload():
results, number = show()
li = []
for i in range(1, number + 1):
li.append(i)
pager_obj = Pagination(request.args.get("page", 1), len(li), request.path, request.args,
per_page_count=10)
index_list = li[pager_obj.start:pager_obj.end]
html = pager_obj.page_html()
return render_template('uplode.html', results=results, index_list=index_list, html=html)四、期待最后网页和后端的TCP文件传输代码相互关联起来
好的,那么计算机网络的期末大作业:python语言实现基于socket的网络编程就大体完工,当然还差最后一部分就是和上一篇文章中的客户端服务器代码相关联起来,这样才算真正意义上的完成网页版TCP文件传输服务。下一篇文章应该就可以彻底完结了。
















 1173
1173











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











