







一、输入与输出
1.print()函数(输出用户所表达的东西)

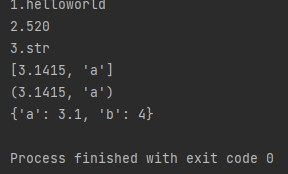
输出格式化整数

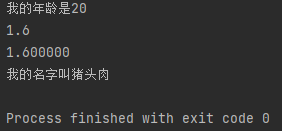
表1
| %c | 字符串及ASCII码 |
| %s | 字符串 |
| %d | 十进制有符号整数 |
| %u | 十进制无符号整数 |
| %o | 八进制无符号整数 |
| %x | 十六进制无符号整数 |
| %X | 十六进制大写无符号整数 |
| %e | 科学计数法的浮点数字 |
| %E | 科学计数法的浮点数字(用E代替e) |
| %f | 用小数点符号的浮点数字 |
| %g | 用%e或%f的浮点数字 |
| %G | 类似于%g的浮点数字 |
| %p | 指针(用十六进制打印值的内存地址) |
| %n | 存储输出字符的数量放进参数列表的下一个变量中 |
表2
| * | 定义宽度或者是精度 |
| - | 常用左对齐 |
| + | 在正数面前显示正号 |
| <sp> | 在正数面前显示空格 |
| # | 在八进制里显示”0“;十六进制里显示”OX“ |
| 0 | 数字前面填充0而不是默认的空格 |
| % | '%%'输出一个单一的’%‘ |
| (var) | 映射变量 |
| m.n | 字段宽为m,位数(精度)为n |
类型转换(float)

2.format()函数格式化输出
format()位置映射


由输出可知,print()函数前面的{}对应了3.141596,而后面的{}对应了926,中间:为分隔符
format()关键字映射

![]()
由输出可知,第一个括号中的server与后面的server=’pig:‘为映射关系,第二个括号中的1和第三个括号中的0为索引值,注明了输出的方向。
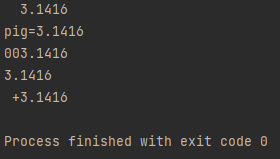
填充对齐
在填充对齐中,”^“为居中对齐,”<“为左对齐,”>“为右对齐。

:>2代表向右对齐两格
3.读写文件open()的使用

open()函数运用形式:open(filename,mode)filename是字符串的值,mode是打开的模式。
完整的语法格式为:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
- file: 必需,文件路径(相对或者绝对路径)。
- mode: 可选,文件打开模式
- buffering: 设置缓冲
- encoding: 一般使用utf8
- errors: 报错级别
- newline: 区分换行符
- closefd: 传入的file参数类型
- opener: 设置自定义开启器,开启器的返回值必须是一个打开的文件描述符。
mode 参数有:
模式 描述 t 文本模式 (默认)。 x 写模式,新建一个文件,如果该文件已存在则会报错。 b 二进制模式。 + 打开一个文件进行更新(可读可写)。 U 通用换行模式(不推荐)。 r 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 rb 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 r+ 打开一个文件用于读写。文件指针将会放在文件的开头。 rb+ 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 w 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 wb 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 w+ 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 wb+ 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 a 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 ab 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 a+ 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 ab+ 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 默认为文本模式,如果要以二进制模式打开,加上 b 。
file 对象
file 对象使用 open 函数来创建,下表列出了 file 对象常用的函数:
序号 方法及描述 1 关闭文件。关闭后文件不能再进行读写操作。
2 刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。
3 返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。
4 如果文件连接到一个终端设备返回 True,否则返回 False。
5 返回文件下一行。
6 从文件读取指定的字节数,如果未给定或为负则读取所有。
7 读取整行,包括 "\n" 字符。
8 读取所有行并返回列表,若给定sizeint>0,则是设置一次读多少字节,这是为了减轻读取压力。
9 设置文件当前位置
10 返回文件当前位置。
11 截取文件,截取的字节通过size指定,默认为当前文件位置。
12 将字符串写入文件,返回的是写入的字符长度。
13 向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。
4.str()函数与repr()函数
str()函数与repr()函数在很多时候是相同的,除了字符串类型以外——字符串类型会在外层多一层引导,这种特性在eval()操作的时候会有显著的效果。另外一个区别是,当需要直接用对象进行输出调用时用repr(),print()输出调用时用str()。
简单来说,str()函数和repr()函数的区别在于:
str()函数:将值转化为适宜人阅读的字符串的形式,是面向客户的。
repr()函数:将值转化为供解释器读取的字符串形式,是面向程序员的。
将整型转换为字符串
>>> a = 123 #int类型
>>> type(a)
<class 'int'>
>>> str(a)
'123'
>>> type(str(a))
<class 'str'>
>>> print(str(a)) #print输出时会去掉引号,但是仍然是str类型
123
>>> repr(a)
'123'
>>> type(repr(a))
<class 'str'>
>>> print(repr(a))
123
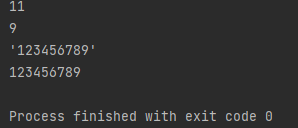
>>> len(repr(a)) #转换后的数据都是'123',所以长度是3
3
>>> len(str(a)) #转换后的数据都是'123',所以长度是3
3将字符串再转换为字符串
>>> repr('abd') #repr转换后是在'abd'的外层又加了一层引号
"'abd'"
>>> str('abd') #str转换后还是原来的值
'abd'
>>> str('abd') == 'abd'
True
>>> repr('abd') == 'abd'
False
>>> len(repr('abd')) #repr转换后的字符串和str转换后的字符串个数都是不一样的
5
>>> len(str('abd'))
3当我们把一个字符串传给 str() 函数再打印到终端的时候,输出的字符不带引号。而将一个字符串传给 repr() 函数再打印到终端的时候,输出的字符带有引号。
造成这两种输出形式不同的原因在于:
print 语句结合 str() 函数实际上是调用了对象的 __str__ 方法来输出结果。而 print 结合 repr() 实际上是调用对象的 __repr__ 方法输出结果。下例中我们用 str 对象直接调用这两个方法,输出结果的形式与前一个例子保持一致。
>>> print('123456789'.__repr__())
'123456789'
>>> print('123456789'.__str__())
123456789不同数据类型的不同处理
某对象没有适于人阅读的解释形式的话, str() 会返回与repr()等同的值。很多类型,诸如数值或链表、字典这样的结构,针对各函数都有着统一的处理方式。
代码实例:
>>> listA = [1,2,3]
>>> str(listA)
'[1, 2, 3]'
>>> repr(listA)
'[1, 2, 3]'
>>>结果是相同的。
而字符串和浮点数,它们的处理方式不同。
注意:Python3和Python2版本str函数处理浮点数时是不同的,Python3版本下,str和repr会返回相同的结果,Python2下则不会, 具体看下面的例子:
Python3版本:
>>> string = 'Hello, PythonTab.com'
>>> str(string)
'Hello, PythonTab.com'
>>> repr(string)
"'Hello, PythonTab.com'"
>>> str(1.0/7.0)
'0.14285714285714285'
>>> repr(1.0/7.0)
'0.14285714285714285'Python2版本:
>>> str(1.0/7.0)
'0.142857142857'
>>> repr(1.0/7.0)
'0.14285714285714285'两个函数之间的对比:


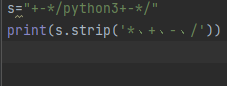
strip() 方法
用于移除字符串头尾指定的字符(默认为空格)或字符序列。
注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
语法
strip()方法语法:
str.strip([chars]);
参数
- chars -- 移除字符串头尾指定的字符序列。
返回值
返回移除字符串头尾指定的字符生成的新字符串。
5.input()函数与raw_input()函数(接收用户输入的函数)
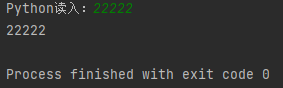
python raw_input() 用来获取控制台的输入。
raw_input() 将所有输入作为字符串看待,返回字符串类型。
注意:input() 和 raw_input() 这两个函数均能接收 字符串 ,但 raw_input() 直接读取控制台的输入(任何类型的输入它都可以接收)。而对于 input() ,它希望能够读取一个合法的 python 表达式,即你输入字符串的时候必须使用引号将它括起来,否则它会引发一个 SyntaxError 。
除非对 input() 有特别需要,否则一般情况下我们都是推荐使用 raw_input() 来与用户交互。
注意:python3 里 input() 默认接收到的是 str 类型。
1、在 Python2.x 中 raw_input( ) 和 input( ),两个函数都存在,其中区别为:
- raw_input( ) 将所有输入作为字符串看待,返回字符串类型。
- input( ) 只能接收“数字”的输入,在对待纯数字输入时具有自己的特性,它返回所输入的数字的类型( int, float )。
2、在 Python3.x 中 raw_input( ) 和 input( ) 进行了整合,去除了 raw_input( ),仅保留了 input( ) 函数,其接收任意任性输入,将所有输入默认为字符串处理,并返回字符串类型。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









