






Smale-FWI 入门培训(二)
一、深度学习中的卷积是什么?
深度学习中的卷积操作(ConvolutionOperation)是卷积神经网络(CNN)的核心组成部分,其基本原理是通过局部感受野和权值共享提取输入数据的局部特征。
-
核心思想
局部感受野:卷积核仅覆盖输入的一小块区域(如3×3),通过滑动窗口逐块处理,捕捉局部特征(如边缘、纹理)。
权值共享:同一卷积核在整个输入上滑动并重复使用,显著减少参数量(与全连接层相比)。 -
关键参数
卷积核大小(Kernel Size):如3×3、5×5,决定感受野大小。
步长(Stride):滑动窗口移动的步长(如1或2),影响输出尺寸。
填充(Padding):
Valid:不填充,输出尺寸缩小。
Same:填充使输出尺寸与输入一致。
输入/输出通道:
多通道输入(如RGB图像)需3D卷积核(如3×3×3)。
多个卷积核可提取不同特征,生成多通道输出。 -
多维扩展
多通道输入:每个输入通道与对应的卷积核通道卷积,结果求和得到单通道输出。
多卷积核:每个卷积核生成一个输出通道,堆叠构成多通道特征图。 -
可视化理解
动态演示:可参考GIF动画,直观展示卷积核滑动计算过程。
注意:蓝色地图是输入,青色地图是输出。
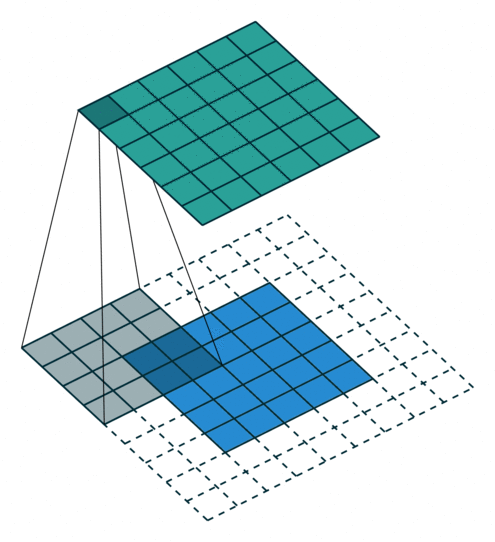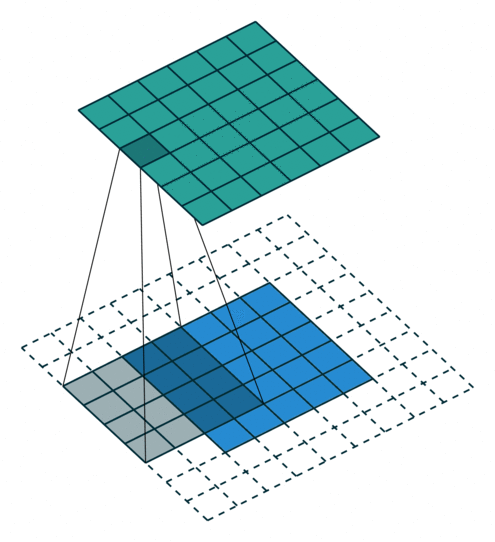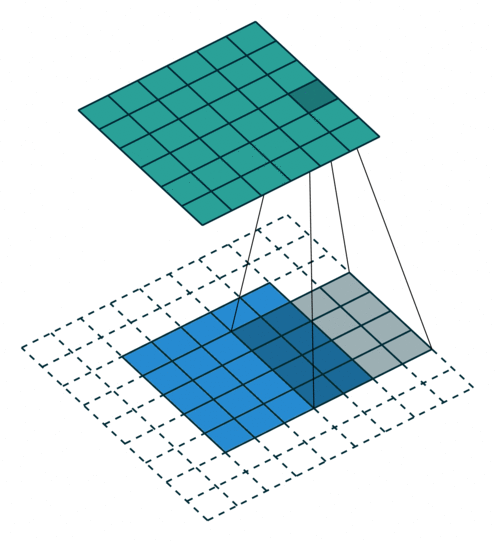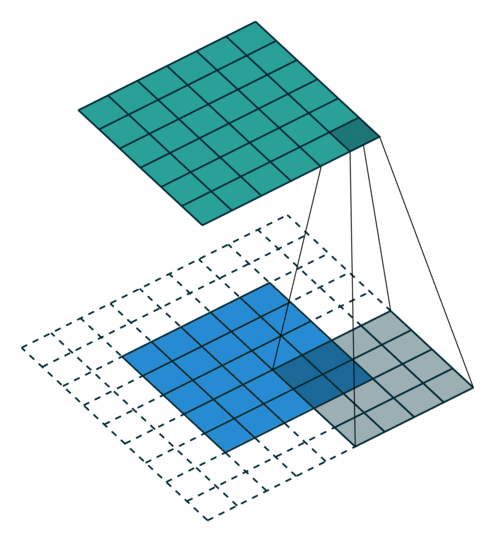
二、常见卷积操作的变形
-
转置卷积(Transposed Convolution)
作用:用于上采样(如分割任务中恢复分辨率),俗称“反卷积”(实际是正向操作)。
原理:通过在卷积操作中使用反向填充和步长,扩大上层特征图的尺寸,常用于生成网络(如GAN)和编码器-解码器架构。即通过填充和步长调整扩大输出尺寸(如输入2×2 → 输出4×4)。 -
可变形卷积(Deformable Convolution)
核心思想:
标准卷积的固定结构(例如3×3网格)无法有效适应形状多变或具有非刚性特征的物体(如各种姿态或表情的人物图像)。 就引入动态偏移量,让卷积核的采样点可以根据输入自适应调整位置,从而增强模型对于复杂几何形状的适应能力。 -
深度可分离卷积(Depthwise Separable Convolution)
作用:过减少参数量和计算量来加速模型,适合移动设备。
原理:将卷积拆分为两个步骤:首先执行逐通道卷积(DepthwiseConvolution),然后使用1x1卷积(PointwiseConvolution)进行混合。 -
动态卷积(Dynamic Convolution)
作用:跟据输入动态决定卷积的权重,使模型更灵活适应不同类型的输入。
原理:过一个条件网络来生成卷积核,从而根据输入数据调整卷积操作。
卷积操作变形有很多,后面看到了再来补充~
三、Dense block(密集块)
Dense Block(密集块) 是卷积神经网络(CNN)中的一种关键结构,由论文《Densely Connected Convolutional Networks》(DenseNet,2017)提出。它的核心思想是通过密集连接(Dense Connection),让每一层的输入来自前面所有层的输出,从而最大化特征重用、缓解梯度消失问题,并显著减少参数量。
(1)密集连接机制:
在传统CNN中,第
l
l
l层的输入仅来自第
l
-
1
l-1
l-1层的输出(如ResNet通过残差连接融合
l
-
1
l-1
l-1和
l
-
2
l-2
l-2层)。
DenseBlock中,第
l
l
l层的输入是前面所有层(第
0
0
0到
l
-
1
l-1
l-1层)输出的拼接
(Concatenation)
(2)Dense Block的结构设计:
每个Dense Block由多个密集层(Dense Layer)堆叠而成,每个密集层包含以下操作:
- BatchNormalization(BN): 标准化输入。
- ReLU激活函数 : 引入非线性
- 1x1卷积(BottleneckLayer,可选): 降低通道数,减少计算量
- 3×3卷积 : 提取空间特征。
四、Spatial Attention Module(空间注意力模块)
空间注意力模块是注意力机制在计算机视觉中的一种应用,用于动态调整特征图中不同空间位置的重要性权重。它通过分析特征图的空间关系,自动学习“关注哪里”,从而增强关键区域的响应,抑制无关背景。
1. 核心思想:
让网络自动聚焦于特征图中的重要区域(如目标物体所在位置)。
对输入特征图的每个空间位置(H×W)生成一个权重矩阵(范围0~1),权重越高表示该位置越重要。
2. 可视化示例:
输入特征图 (C×H×W) 空间注意力权重 (1×H×W) 输出特征图 (C×H×W)
[ 0.1, 0.3, 0.5 ] [ 0.2, 0.8, 0.6 ] [ 0.02, 0.24, 0.30 ]
[ 0.2, 0.4, 0.6 ] × [ 0.1, 0.9, 0.4 ] = [ 0.02, 0.36, 0.24 ]
[ 0.3, 0.5, 0.7 ] [ 0.3, 0.7, 0.5 ] [ 0.09, 0.35, 0.35 ]
注:权重高的区域(如0.9)特征被增强,低权重区域(如0.1)被抑制。
五、Pre-trained Module(预训练模块)
预训练模块是指在大规模数据集上预先训练好的神经网络模型(或其中部分结构),可以直接用于新任务或作为特征提取器。它是迁移学习(Transfer Learning)的核心工具,能显著降低训练成本并提升小数据场景下的模型性能。
总结
1.技术迁移
可以将计算机视觉技术(如可变形卷积、注意力机制)可迁移到地震数据处理中,也可以将自然图像处理中的成熟模块(如预训练模型、密集连接)迁移到地震数据特征提取、边界定位等任务中。
2.模块化
可以在模型设计中灵活组合网络组件,灵活组合也是创新。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









