







 文章介绍了斯皮尔曼等级相关系数,这是一种在-1到1之间的度量,适用于两组数据的等级关系。当数据满足单调关系时,即使不满足正态分布和线性关系,也可使用斯皮尔曼系数。对于小样本,可通过临界值表进行假设检验;大样本则通过统计量和p值判断。在选择相关系数时,若数据是连续、正态且线性的,首选皮尔逊系数;否则,应使用斯皮尔曼系数,尤其对于定序数据。
文章介绍了斯皮尔曼等级相关系数,这是一种在-1到1之间的度量,适用于两组数据的等级关系。当数据满足单调关系时,即使不满足正态分布和线性关系,也可使用斯皮尔曼系数。对于小样本,可通过临界值表进行假设检验;大样本则通过统计量和p值判断。在选择相关系数时,若数据是连续、正态且线性的,首选皮尔逊系数;否则,应使用斯皮尔曼系数,尤其对于定序数据。
两种最为常用的相关系数:皮尔逊 pearson相关系数和斯皮尔曼spearman等级相关系数。
一、什么是斯皮尔曼相关系数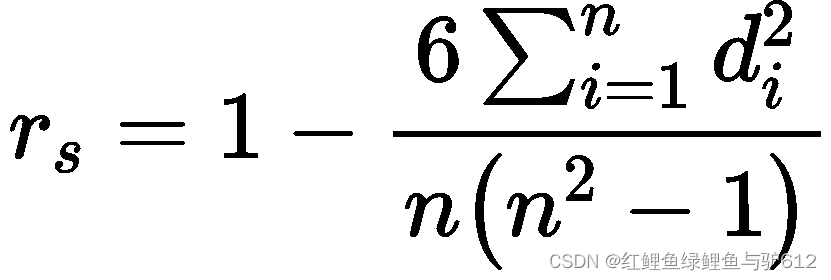
这个相关系数的范围在-1和1之间
X,Y为两组数据,Xi与Yi之间存在等级差,等级是指将它所在的一列数据按照从小到大排序后,这个数所在的位置,例如下图:
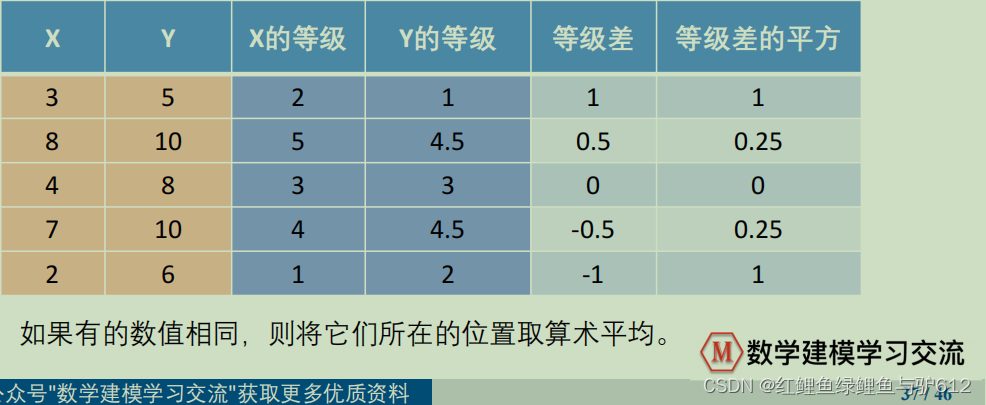
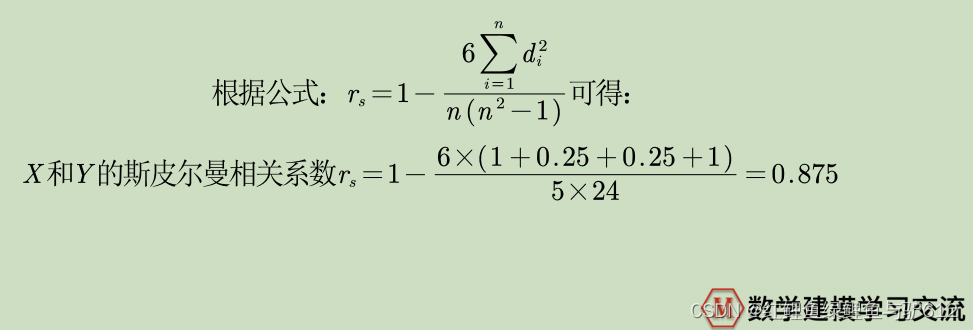
当X和Y的等级差为0时,那这个斯皮尔曼的相关系数就为1,因为等级差的平方为0,可以看出等级差的平方也为0,代入斯皮尔曼相关系数计算公式中可得斯皮尔曼相关系数为1;同理可得,如果X和Y的等级数完全相反时(X=1,Y=n X=2,Y=n-1…),这个斯皮尔曼相关系数就为-1(负相关)
斯皮尔曼相关系数被定义为等级之间的皮尔逊相关系数
二、斯皮尔曼相关系数的假设检验
1.小样本
小样本情况(n≤30),查临界值表,将样本相关系数r与表中的临界值进行比较,当样本相关系数r≥表中的临界值,才能得出显著的结论,原假设为r=0,备择假设为r≠0,我的理解:在算出一个样本相关系数之后,通过显著性水平和样本数定位到临界值,当样本相关系数的大小大于等于这个临界值之后才能接受原假设,就是这个相关系数和0没有显著性差异,否则拒绝原假设,接受备择假设-样本相关系数和0有显著性差异。
2.大样本
用r构造一个新的统计量,看看这个统计量是不是服从标准正态分布
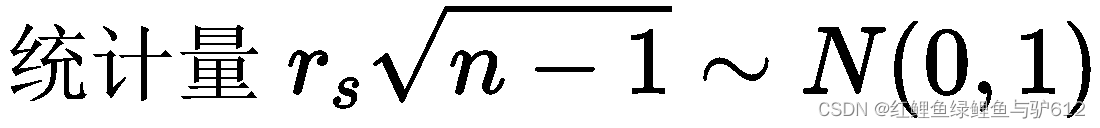
然后再计算出这些检验值的p值qiu与0.05相比较
构造过程如下:
 求p值的过程
求p值的过程
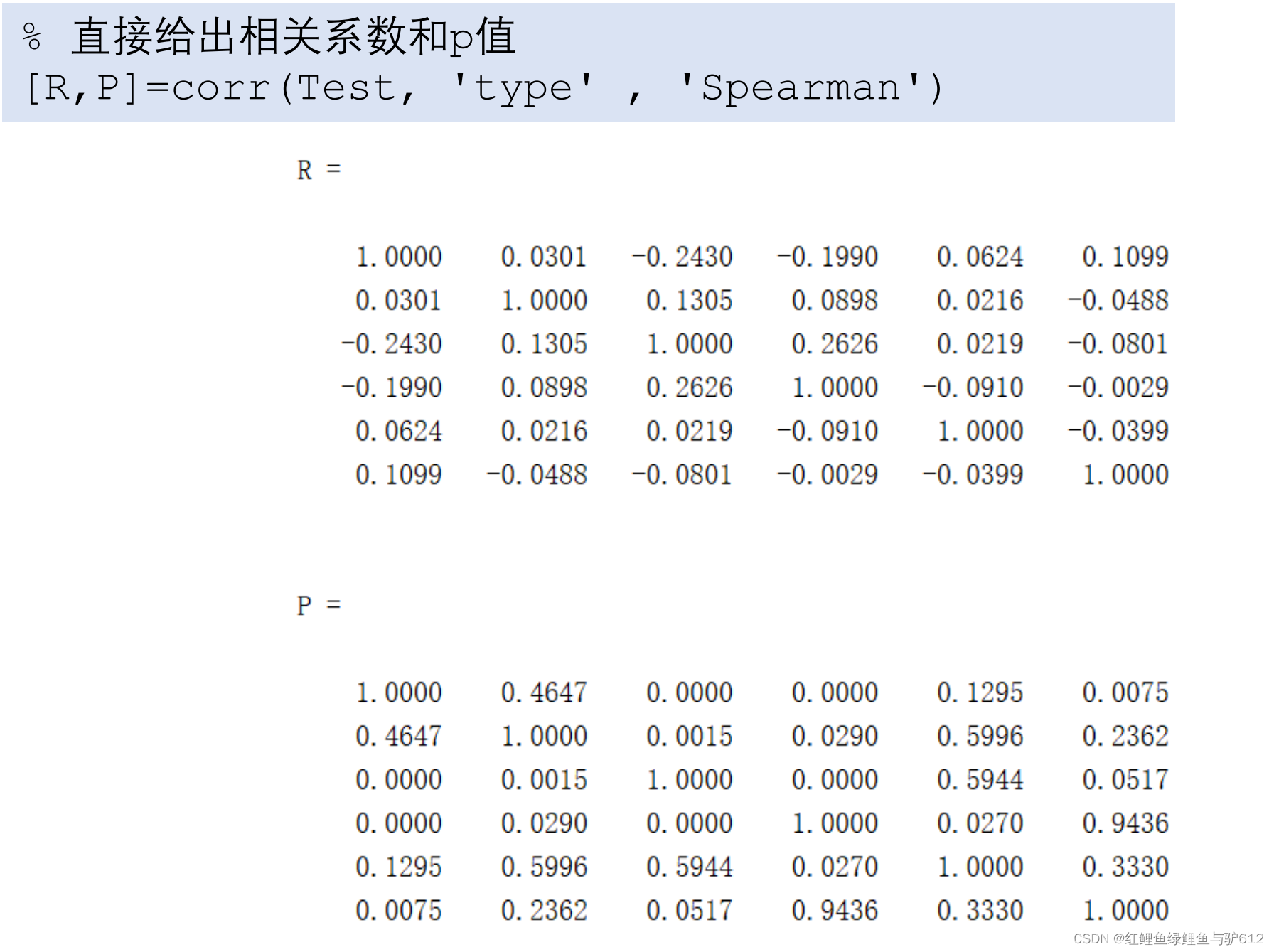
三、斯皮尔曼相关系数和皮尔逊相关系数的选择
斯皮尔曼相关系数的适用条件比皮尔逊相关系数要广,只要数据满足单调关系(例如线性函数、指数函数、对数函数等)就能够使用。
1. 连续数据,正态分布,线性关系,用 pearson 相关系数是最恰当,当然用spearman 相关系数也可以, 就是效率没有 pearson 相关系数高。2. 上述任一条件不满足,就用 spearman 相关系数,不能用 pearson 相关系数。3. 两个定序数据之间也用 spearman 相关系数,不能用 pearson 相关系数。
定序数据 是指仅仅反映观测对象等级、顺序关系的数据,是由定序尺度计量形成的,表现为类别,可以进行排序,属于品质数据。例如:优、良、差;我们可以用 1 表示差、 2 表示良、 3 表示优,但请注意,用 2 除以 1 得出的 2 并不代表任何含义。定序数据最重要的意义代表了一组数据中的某种逻辑顺序。















 3570
3570











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









