






无监督学习中,所有的数据都没有打label,就是没有对比的目标了。但是其实不是没有目标了,在Auto-Encoders的过程里,它的目标就是他自己,如下图,他这个就相当于一个卷积层,和CNN的区别就在于,它的输出层=输入层(784=784),因为他要重建它自己,而CNN的输出层是类数,为了分类。另一个区别就是:Auto-Ecoders的中间有一个neck,它可以升维,也可以降维。
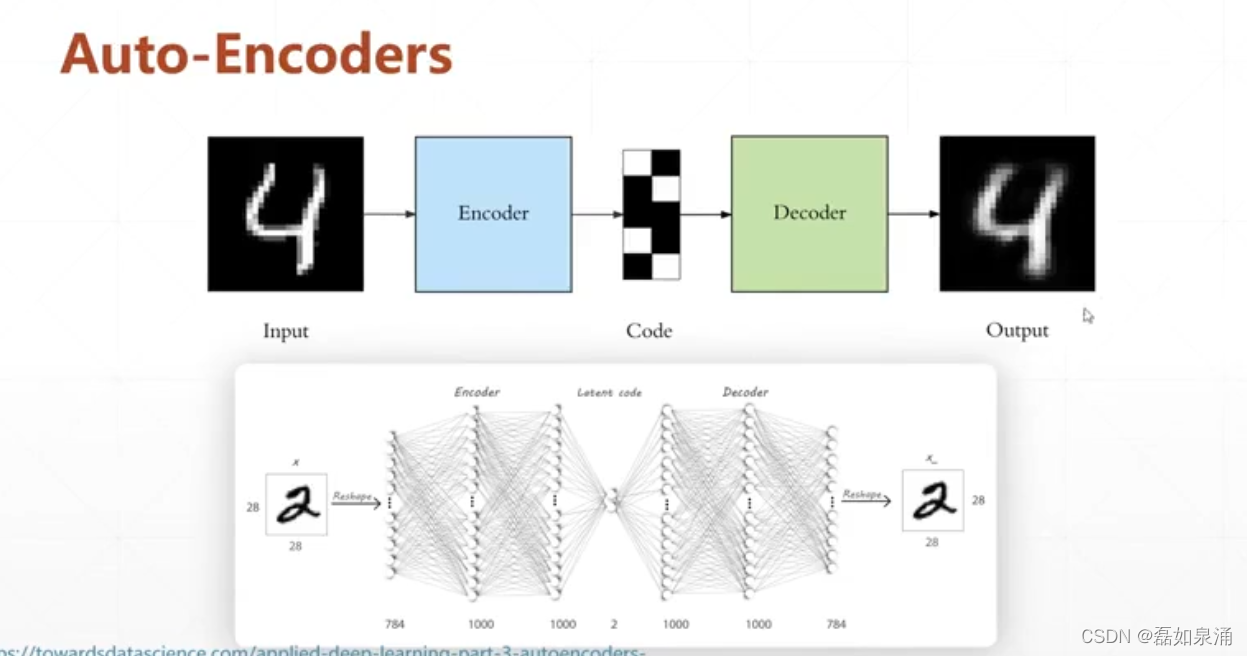
还有一个问题是Auto-Ecoders如何去训练
一般来说是loss function可求导的情况就可以进行训练工作。

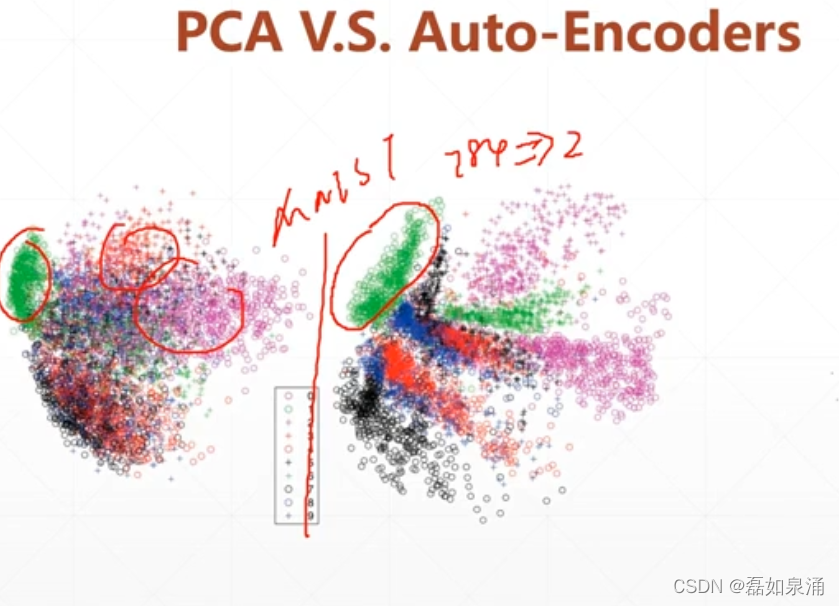
在发现Auto-Ecoders之前,都是在用PCA的方法降维。
(1)PCA是一种线性的变换,有本身的局限性,因为分类的数据的形态,一般都是非线性的
效果如下图:

人脸的图片,下面一行是PCA
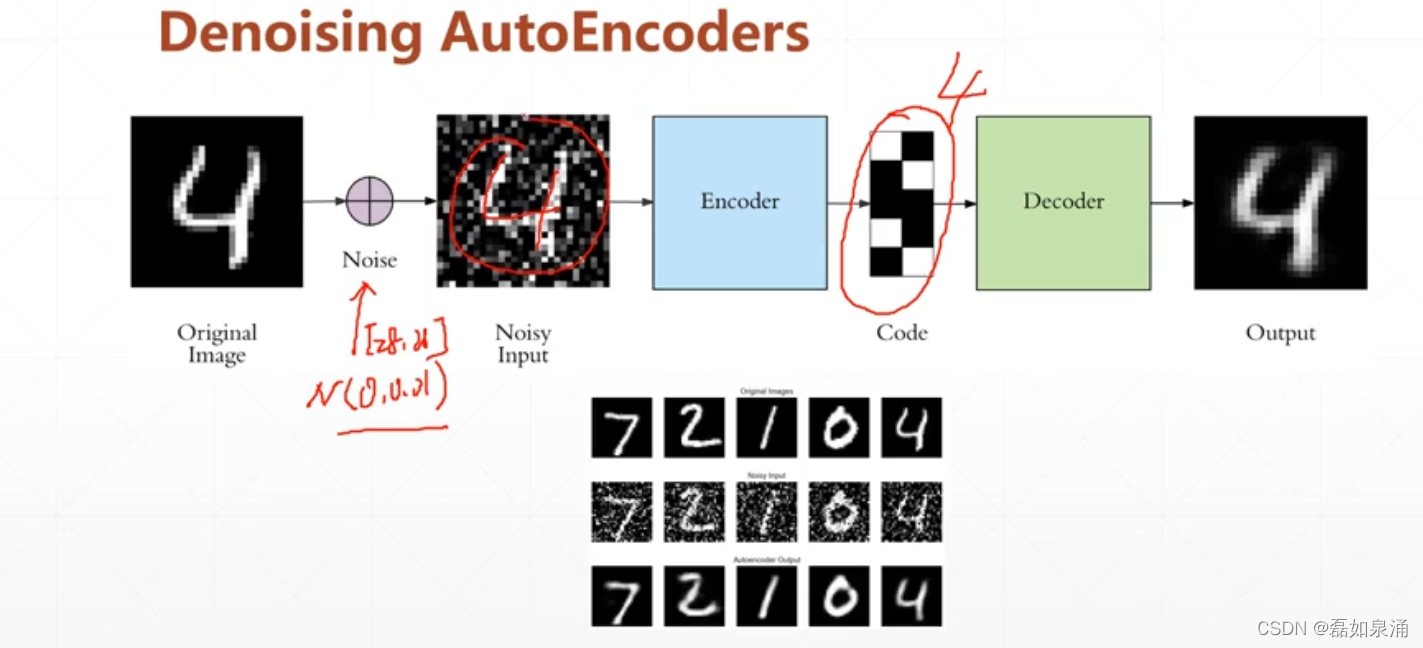
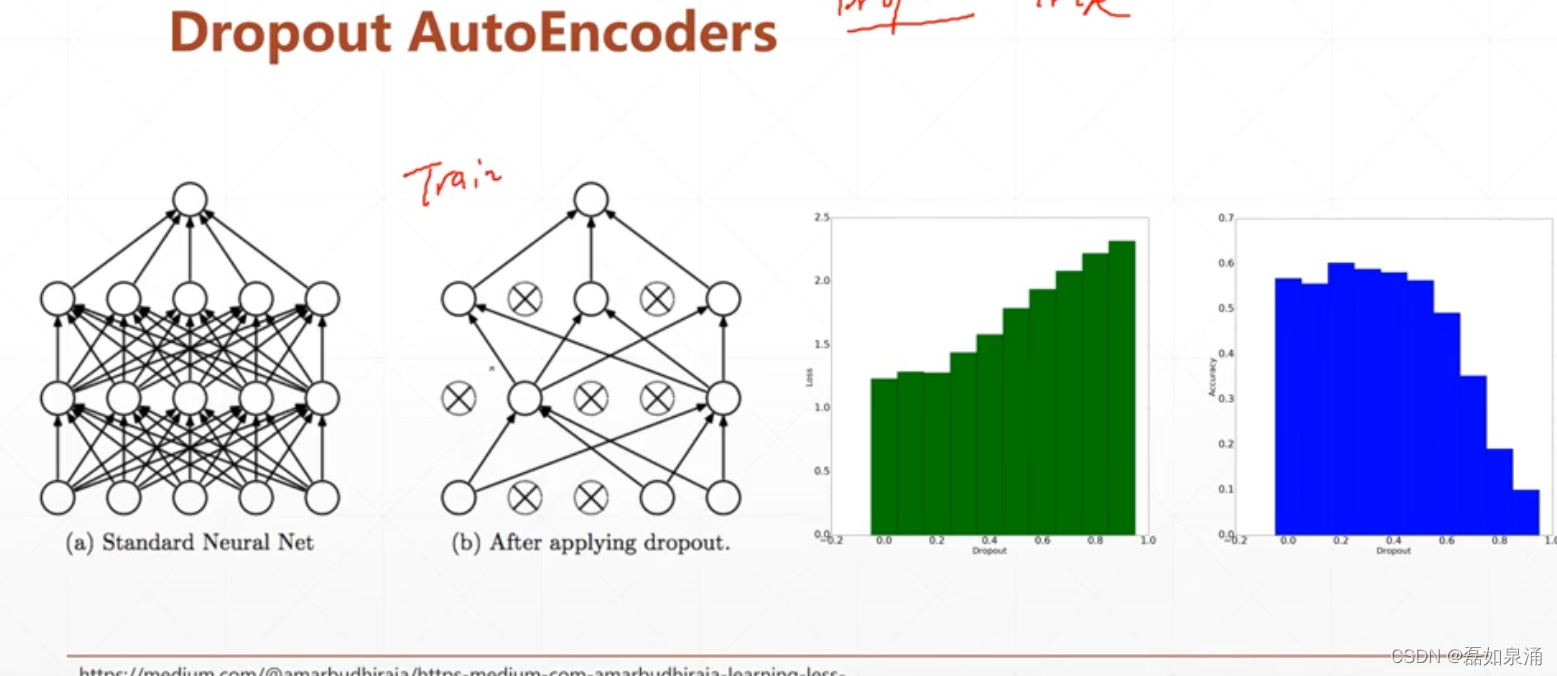
下面推出一些Auto-Ecoders的一些变种。
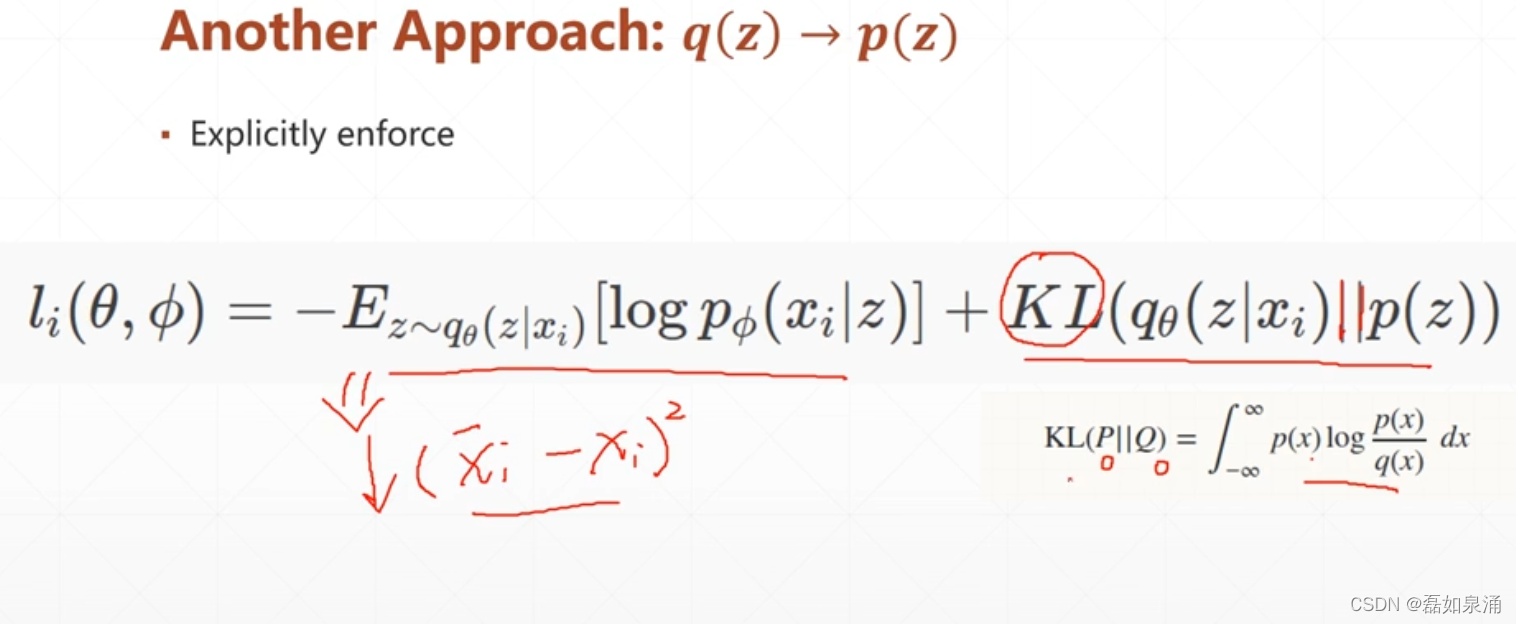
后边这部分可以理解为,p和q相差越大时,这个值越大,pq越重叠,这个值越小。

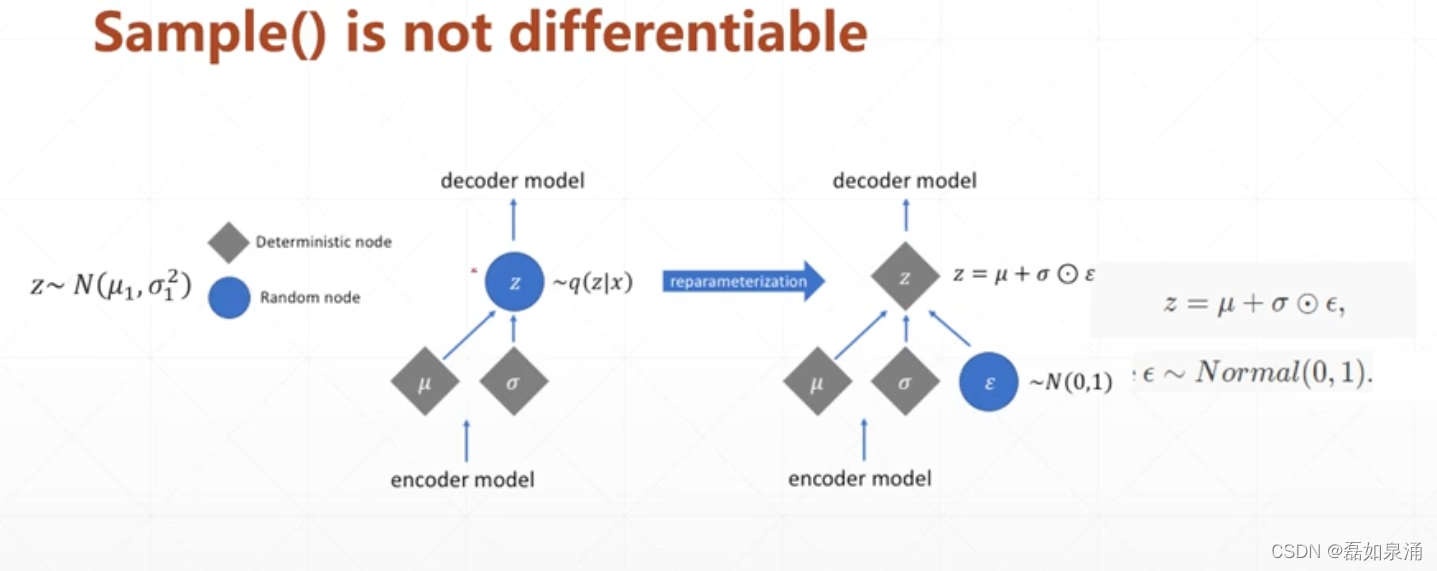
但是此时还少一步,
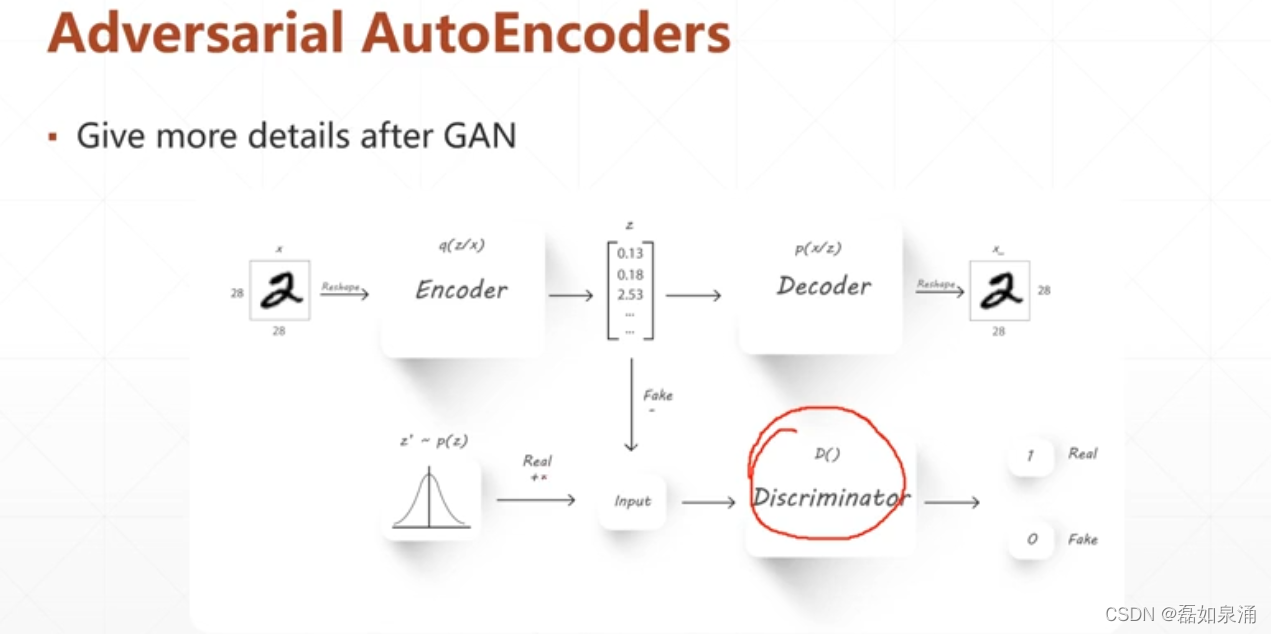
Auto-Ecoders(AE) vs VAE

下面的人脸也是VAE识别到的,并且还自动加了背景虚化。
但是这些东西,和GAN比起来,差太多了














 1277
1277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









