






6.1ConcurrentHashMap实现原理与使用
1.hashmap实现原理
1.7版本:数组+链表。用的是头插法,所以会出现多线程的时候产生环
1.8版本:数组+链表+红黑树。链表长度>8变红黑树,<6变链表。出现碰撞用的是尾插法
2.currenthashmap实现原理
1.7版本:采用锁机制,在对某个子hash进行操作时,将该Segment锁定,不允许对其进行非查询操作,想对HashEntry操作需要先获取Segment。
1.8版本:CAS无锁算法,这种乐观操作在完成前进行判断,如果符合预期结果才给予执行,对并发操作提供良好的优化.
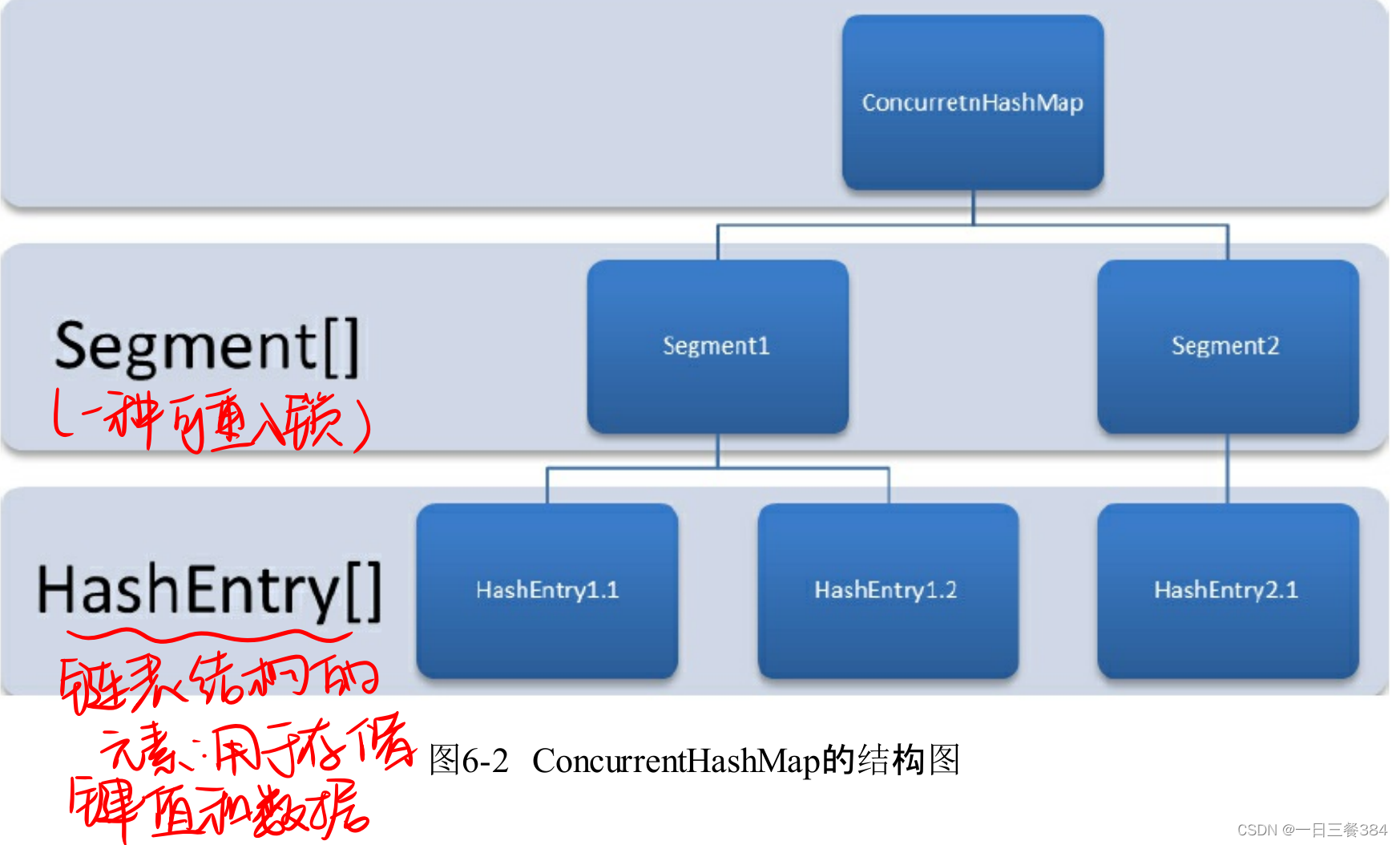
3.hashmap扩容会导致哪些问题
1.7版本中采用的是头插法会出现死循环
1.8版本中采用尾插法,会出现数据覆盖的问题
4.hashtable和hashmap和Concurrenthashmap的区别
hashmap:线程不安全。因为不同步的问题,多线程场景下是不安全的,容易出现数据不一致的问题,在单线程场景下非常推荐使用
hashtable:全部加锁
Concurrenthashmap:分为很多子hashMap,再进行加锁(读写锁)
Concurrenthashmap是可以代替hashtable的,hashtable因为锁住全部线程的安全性可以说是非常强,concurrenthashmap对部分上锁安全性肯定没有hashtable高,但是对于大量数据情况下,hashtable因为锁全部会导致处理时间长,此时concurrenthashmap当然会比hashtable好。
6.2有哪些阻塞队列
ArrayBlockingQueue:数组结构组成的有界阻塞队列
LinkedBlockingQueue:链表结构 有界阻塞队列
PriorityBlockingQueue:支持优先级排序的无界阻塞队列
DelayQueue:使用优先级队列实现的无界阻塞队列
应用场景:缓存系统的设计,定时任务调度
SynchronousQueue:不存储元素的阻塞队列
LinkedTransferQueue:链表结构组成的无界阻塞队列
LinkedBlockingDeque:链表结构组成的双向阻塞队列
6.4Fork/Join框架(没有也能实现)
1.任务拆分代码
int moddel=(start+end)/2
CountTask leftTask=new CountTask(start,model)
CountTask rightTask=new CountTask(middle + 1,end)
//执行子任务
leftTask.fork();
rightTask.fork();
//等待子任务执行完,并得到其结果
int leftResult=leftTask.join();
int rightResult=rightTask.join();
//合并子任务
sum=leftResult+rightResult();没弄太明白。。。等我再补,有没有大佬啊啊啊啊啊啊















 773
773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









