







目录
一、首先导入我们的数据包
import sqlite3
import pandas as pd
二、创建数据表
//定义我们对数据库的操作,创建一个gdp的表格,其中包含以下四个字段
//city字段包含的字符串长度为20
//province字段,字符串长度为20
//year字段类型为整型
//gdp字段类型为四字节的浮点值
query='CREATE TABLE gdp(city VARCHAR(20),province VARCHAR(20),year INTEGER,gdp REAL)'
//conn为我们的油标,用来操作我们的数据库
//这里我们使用sqlite3.connect链接到我们的mydata.sqlite的数据库,如果当前不存在这个数据库,就创建一个
conn=sqlite3.connect('mydata.sqlite')
//execute执行我们query中的SQL代码
conn.execute(query)
//提交操作,如果不输入commit代码,刚才对于数据进行的操作将不会生效
conn.commit()三、输入数据
//使用我们列表将我们的数据传入
data=[('上海','',2018,32679),('北京','',2018,30320),('深圳','广东',2018,24691)]
//将我们的数据传入我们的gdp表格中,其中?表示对于我们data中每一组数据中的四个元素的匹配
stmt='INSERT INTO gdp VALUES(?,?,?,?)'
//executemany为执行多行操作的意思,然后将我们的数据和我们的操作代码传入
conn.executemany(stmt,data)
//提交我们刚才进行的操作,如果不使用commit方法的话,刚才我们对于数据进行的操作都不会生效
conn.commit()四、从MySQL中读取数据
//执行操作,从我们的gdp表格中读取全部的数据(conn已经链接了我们的mydata.sqlite表格)
cursor=conn.execute('select*from gdp')
//将我们的cursor中的全部记录逐行返回,cursor为一个迭代器,我们需要用fetchall来获取我们迭代器中的全部元素
rows=cursor.fetchall()
//将我们的rows中的数据转换为pd表格类型的数据,然后指定我们的行索引
q=pd.DataFrame(rows,columns=[x[0] for x in cursor.description])
print(q)这是我们的cursor中的数据 
这是我们的rows中的数据,以列表的形式返回。
这是cursor.description中的数据 ,其将每个元素的类型返回,我们发现只有列表内每一个元组才是我们需要的columns的元素,所以我们使用了一个lamda表达式将我们每一个元组中的第一个元素组成一个列表,形成我们的行索引
然后我们的print(q)就获得了我们的数据

五、如何使用我们的Navicat来查看我们的刚才创建的数据表
首先在我们执行了上面的代码后,我们发现我们在Python的当前目录下,多了一个mydata.sqlite文件
右键,复制引用路径可以查看到当前mydata.sqlite的文件目录

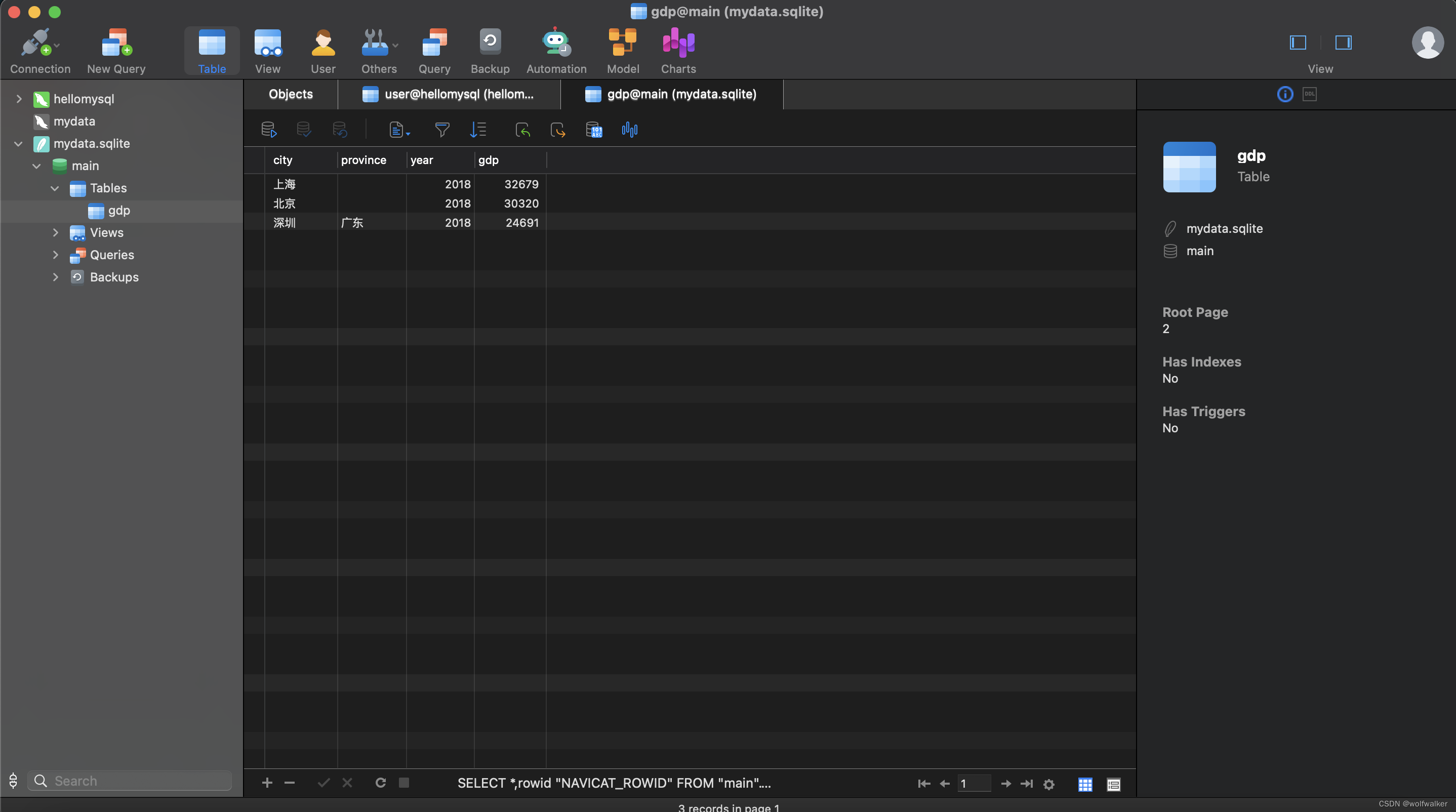
打开我们的Navicat,链接新的SQLite数据库

输入我们刚才的mydata.sqlite也就是我们创建的数据库名,然后将我们的文件目录选择刚才我们复制的目录,这里的username可以自己指定,这里的password是创建MySQL时候的密码

点击save,然后打开我们的mydata.sqlite文件,我们就可以看到我们的gdp表,然后点开我们的GDP表,就可以查看到我们刚刚输入的数据。
















 1253
1253











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











