







输入一个字符串,打印出该字符串中字符的所有排列。
你可以以任意顺序返回这个字符串数组,但里面不能有重复元素。
示例:
输入:s = "abc"
输出:["abc","acb","bac","bca","cab","cba"]来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/zi-fu-chuan-de-pai-lie-lcof
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
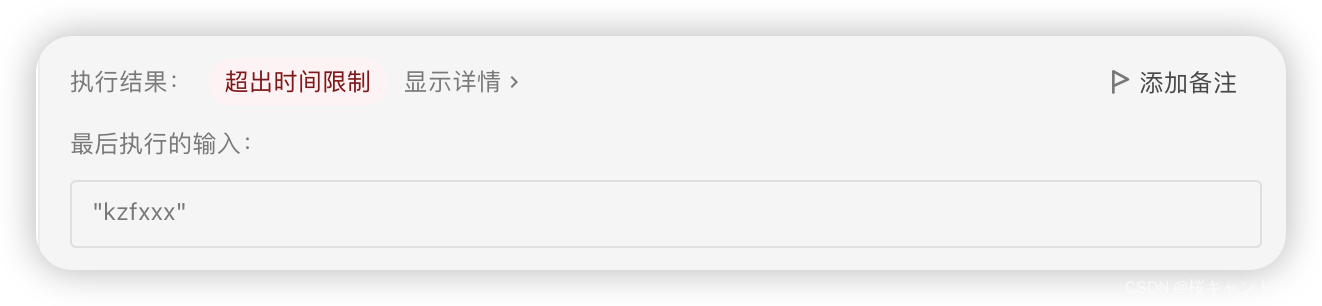
一开始我是想采用回朔法,将全部的情况都列举出来,然后将不符合要求的筛选掉,但是在枚举情况较小的时候这种算法是没有问题的,但是一旦给的字符串长度为5个以上,就会超时。下面是我最初始的写法。
class Solution {
public:
vector<string> permutation(string s) {
int b[26]={0};
for(int i=0;i<s.size();i++)
{
b[s[i]-'a']++;
}
string tmp;
int n=s.size();
result(s,0,n,tmp);
for(int j=0;j<answer.size();j++)
{
int a[26]={0};
string ch=answer[j];
for(int i=0 ;i<ch.size();i++)
{
a[ch[i]-'a']++;
}
for(int i=0;i<ch.size();i++)
{
if(a[ch[i]-'a']!=b[ch[i]-'a'])
{
answer.erase(answer.begin()+j);
j--;
break;
}
}
}
vector<string> final;
final.push_back(answer[0]);
for(auto ch:answer)
{
int flag=0;
for(int i=0;i<final.size();i++)
{
if(ch==final[i])
{
flag=1;
}
}
if(flag==0)
{
final.push_back(ch);
}
}
return final;
}
//i表示当前枚举的是第几位,n表示一共有几位
void result(string &s,int i,int n,string &x){
if(i==n)
{
answer.push_back(x);
return ;
}
for(int j=0;j<n;j++)
{
x.push_back(s[j]);
result(s,i+1,n,x);
x.pop_back();
}
}
private:
vector<string> answer;
};
这是对于官方的代码的解读。
class Solution {
public:
vector<string> rec;
vector<int> vis;
void backtrack(const string& s, int i, int n, string& perm) {
//表示传入字符串中的每一个字符都已经完成了枚举
//将当前枚举出来的结果压入我们的结果集中
if (i == n) {
rec.push_back(perm);
return;
}
for (int j = 0; j < n; j++) {
//如果j位置的数据已经被使用过了,
//或者j大于0并且j-1位置的数据没有被使用过并且j-1位置上的元素还等于j的时候(这就防止了相同的字母因交换顺序而导致的重复的输出结果)
//就跳过当前这次枚举
if (vis[j] || (j > 0 && !vis[j - 1] && s[j - 1] == s[j])) {
continue;
}
//表示我们原数组中j位置的数据已经被使用过了
vis[j] = true;
//将j位置的数据压入当前的枚举对象中。
perm.push_back(s[j]);
//继续递归枚举下一个位置
backtrack(s, i + 1, n, perm);
//回溯,将当前的枚举的数据弹出
perm.pop_back();
vis[j] = false;
}
}
vector<string> permutation(string s) {
//获取字符串s的长度
int n = s.size();
//将我们的vis调整至字符串n的同等大小
//vis数组是用来表示对应的数组位置上的数据是否已经被使用过。
vis.resize(n);
//将字符串s从头到尾进行排序
sort(s.begin(), s.end());
//创建一个空的字符串,用于存储我们每一次枚举的结果
string perm;
backtrack(s, 0, n, perm);
return rec;
}
};
















 105
105











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











