






尽可能多地收集目标提供的web服务域名资产。
工具
ARL灯塔资产系统揭秘,好用工具背后的优质信息收集思路
根据工具的收集原理去学习手工收集。

首先资产是指Web资产,也就是所给域名下的子域名中提供了Web服务的就是我们要找的。(不需要cms,旁站这些其他的全部找到)
第一步:尽可能地收集目标企业的子域名
第二步:判断该子域名是否提供web服务
而其他的一些操作,是为了在挖洞之前能够更快地熟悉目标的资产,更有针对性地进行测试。
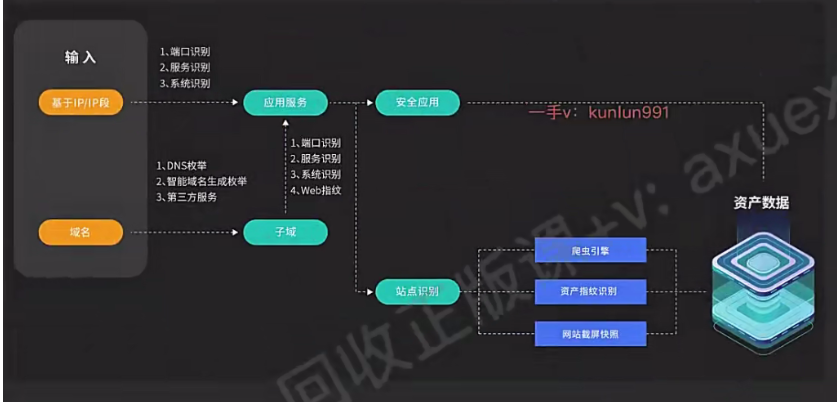
ARL怎么进行这两步
**从四个模块进行补充完善**
**用于收集子域名的模块:**
1、域名爆破
2、域名查询插件(crt.sh、alienvault、cerspotter、fofa、hunter...获取子域名)
3、搜索引擎调用(利用搜索引擎搜索下发目标爬取对应的子域名)
**用于服务&端口探测模块**
1、端口扫描
2、服务识别
**用于辅助渗透测试的模块**(漏扫)
操作系统识别
站点识别(指纹是被)
搜索引擎调用
站点爬虫,爬取对应URL
站点截图
文件泄露检测
nuclei调用用默认POC对站点进行检测
Host碰撞
**用于辅助信息收集模块(精确收集子域名)**
1、DNS字典智能生成(根据已有的域名生成字典进行爆破)
2、ARL历史查询(对arl历史人物结果进行查询用于本次任务)
3、SSL证书获取(对端口进行ssl证书获取)
信息收集的先后顺序十分重要
比如:在进行端口服务探测的时候必须收集足够的IP子域名。
在进行渗透测试信息收集又必须确定目标提供了特定服务。
dns解析,nslookup www.baidu.com
一个域名对应一个ip,有cdn就会返回多个。泛解析就是可能会解析到不存在的域名,需要脚本跑排除掉不存在的域名。
第三方服务就是调用api接口
如果是IP/IP段,会直接进入端口服务系统识别,如果是域名就会进入DNS枚举等收集更多的子域名,再进行端口服务系统指纹扫描
下一步就通过渗透测试做进一步的信息收集,比如搜索引擎调用,指纹识别,爬虫等。
然后将这些数据存入数据库中。
手工信息收集
是自动化信息收集的补充
IP子域名收集模块
尽可能多地收集IP和域名
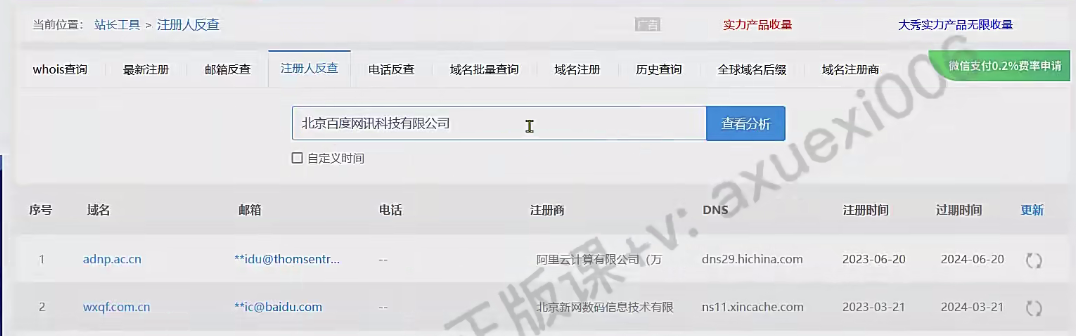
whois反查
whois查询其实就是whois域名查询,因为注册域名需要提供注册人的相关信息。比如联系人,联系邮箱。(站长之家的whois域名查询)
whois反查就是根据whois查询的信息去查询哪些域名拥有相同的联系人,联系邮箱的信息。

再根据反查的信息,查出来的新邮箱进行邮箱反查。
如果出现域名查询为违禁词,比如百度,那么可以用注册人,注册公司去反查。
注册人查询可以利用企查查去查。
ICP备案查询
是一项对事业单位、企业和个人的网站进行监管的措施,必须备案并获取许可证,才可以向公众提供商业互联网信息服务。(企业不可操作)
[ICP/IP地址/域名信息备案管理系统](https://beian.miit.gov.cn/#/Integrated/index)
用备案号查询

通过burpsuite批量获取
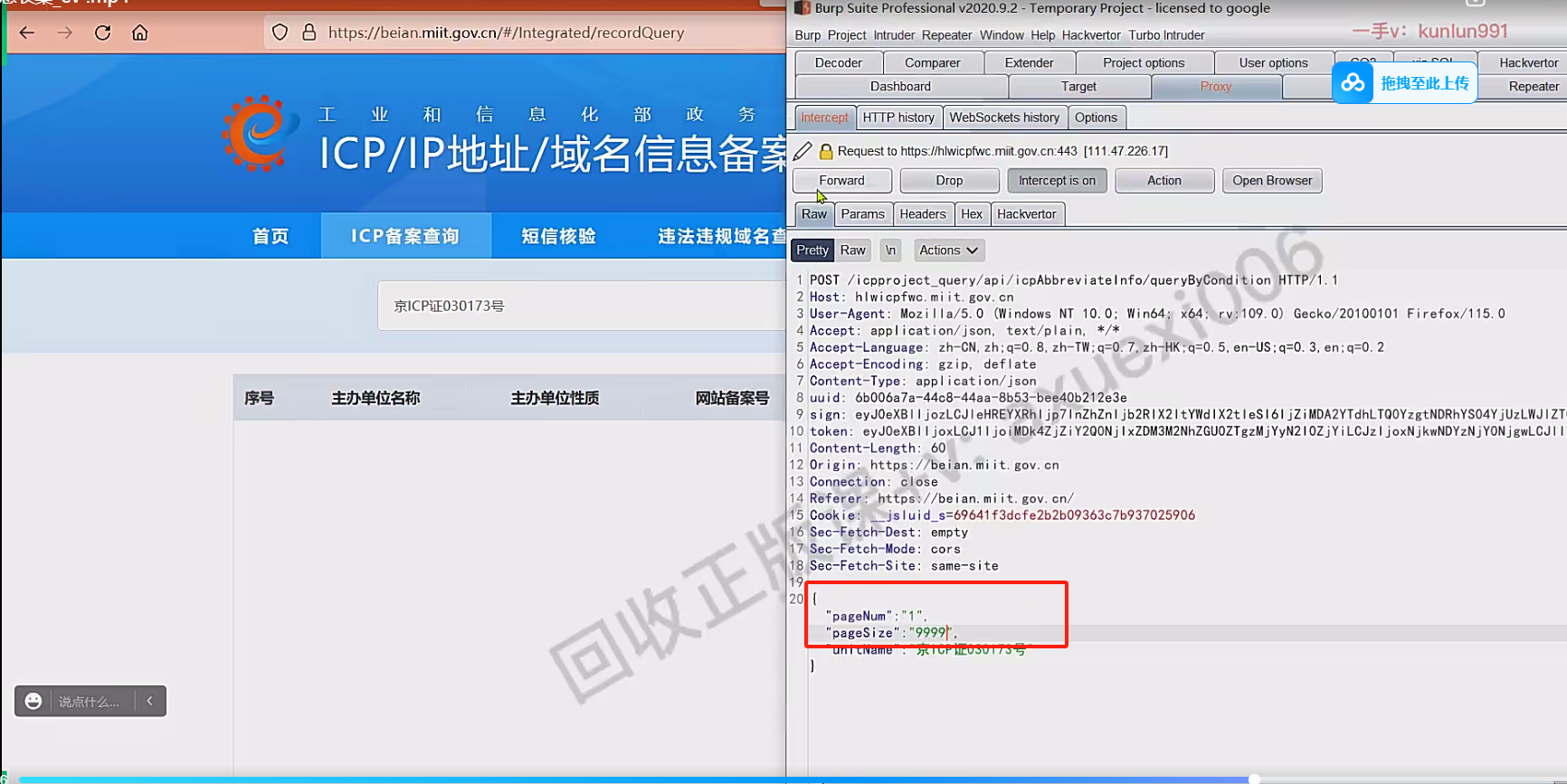
将pageNum修改为1,pageSize修改为9999
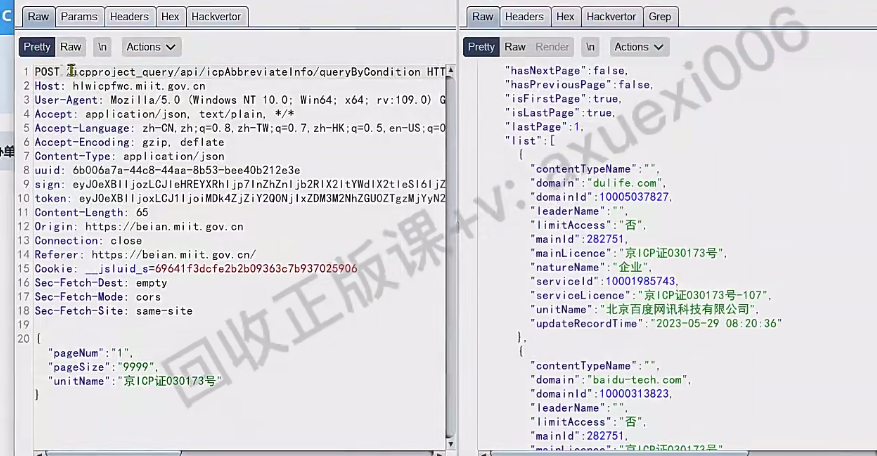
放包获取更多域名。
Virustotal Api调用
可以直接通过编写python脚本,调用api获取子域名
[VirusTotal - Home](https://www.virustotal.com/gui/home/upload)
import requests
import time
API_KEY = "" # 替换成你的真实API密钥
def get_all_subdomains(domain):
subdomains = []
cursor = None
url = f"https://www.virustotal.com/api/v3/domains/{domain}/subdomains"
while True:
params = {"limit": 40} # 单次请求最大数量
if cursor:
params["cursor"] = cursor
headers = {"x-apikey": API_KEY}
try:
response = requests.get(url, headers=headers, params=params)
response.raise_for_status()
data = response.json()
# 提取子域名
if "data" in data:
subdomains += [item["id"] for item in data["data"]]
print(f"已获取 {len(subdomains)} 个子域名...")
# 检查是否有下一页
cursor = data.get("meta", {}).get("cursor")
if not cursor:
break
# 免费版API速率限制保护
time.sleep(15) # 调整延迟时间(付费版可减少)
except Exception as e:
print(f"请求失败: {e}")
break
return subdomains
# 主程序
domain = input("请输入要查询的域名(例如:example.com): ").strip()
print(f"正在扫描 {domain},请稍候...")
results = get_all_subdomains(domain)
print(f"\n共找到 {len(results)} 个子域名:")
for sub in sorted(results):
print(sub)
with open(f"{domain}_subdomains.txt", "w") as f:
f.write("\n".join(results))端口服务识别模块
目的在于识别资产开放的端口以及服务。
Nmap
支持很多参数,主要拿来端口探测和服务识别。
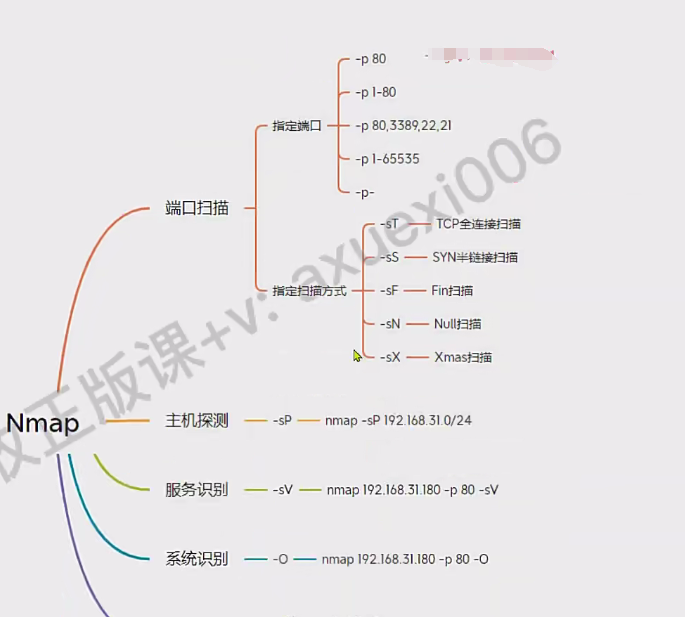
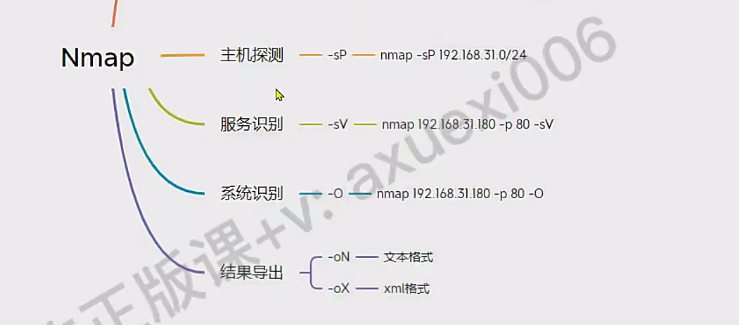
如果要进行端口服务识别
nmap -p 1-65535 -sV -O DOMAIN/IP -oN domain.txt
masscan
5min能扫完整个互联网的端口扫描工具。
但是必须要有ip才可以端口扫描,所以要进行c段扫描。
masscan -p 0-65535 192.168.1.0/24 --rate=999999
再对存活的ip进行端口扫描
masscan 192.168.1.1 -p 1-65535 --rate=999999
渗透测试信息收集模块
目的收集资产更多信息
Goby-- 漏扫工具
afrog --可以对收集到的域名IP进行Poc验证
afrog.exe -t IP/DOAMIN


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









