






项目一 _____(手机流量统计项目)
引言
随着移动互联网的快速发展,手机已经成为人们日常生活中不可或缺的一部分。随之而来的是对手机流量使用情况的关注和管理需求。手机流量统计项目旨在解决用户对手机流量使用情况的监控和分析需求,帮助用户更好地管理其流量消耗,节省费用并优化使用体验。
需求分析
根据手机号的前缀将每个手机号的上行流量、下行流量、总流量进行统计,并将统计结果输出到不同的输出文件中。具体要求是根据手机号的前缀进行分类,以13开头的手机号输出到一个文件,以15开头的手机号输出到另一个文件,其他手机号输出到另一个文件。
为了实现这个需求,首先需要逐行读取access.log数据文件,提取出手机号、上行流量和下行流量等字段。然后根据手机号的前缀进行分类统计,计算每个手机号的上行流量和下行流量之和,得到总流量。最后将统计结果按照手机号前缀写入到不同的输出文件中。
这个需求涉及到文件读取、数据处理、分类统计和文件写入等多个步骤,需要编写程序来实现自动化处理。在编写程序时,需要考虑如何高效地处理大量数据、如何准确提取所需字段、如何正确分类统计数据,并确保结果准确无误地输出到指定的文件中。
通过编写一个脚本或程序来实现这个需求,可以大大提高处理效率并确保结果的准确性。同时,对于不同手机号前缀的处理,可以使用条件判断或映射表来实现分类统计和输出到不同文件的逻辑。
详细思路
Map阶段
首先,在Map阶段,重写map方法,输入文件(access.log)中的每一条记录(文件的偏移量作为输入键,文本行内容作为值),将读入的每一条记录转换为String类型,并以\t作为拆分字符串,取出手机号,上行流量和下行流量等,将电话号码作为键,上行流量和下行流量组成的FlowBean对象作为值,写入到Hadoop的上下文中。
Reduce阶段
在Reduce阶段,重写reduce方法,Reducer将接收到相同手机号的多个FlowBean对象,遍历所有bean,将其中的上行流量,下行流量分别累加到sum_upFlow和sum_dFlow变量中,创建一个新的FlowBean对象,其中包含了累加后的总上行流量和总下行流量,并将这个结果写入到Reducer的上下文中,将Reducer的输出键值对(将电话号码作为键,总上行流量和总下行流量作为值),写入到Hadoop的上下文中。
Shuffle阶段
为了确保相同前缀的手机号被发送到同一个Reducer任务中,可以自定义一个Partitioner类,继承Partitioner抽象类,通过定义一个 HashMap,用于存储前缀和对应的分区号的映射关系,并覆写getPartition()方法。getPartition()方法中,获取键的前两个字符作为前缀,根据手机号的前缀来确定分区,前缀"13"映射到分区号0,将前缀"15"映射到分区号1,其他前缀返回分区号2,确保具有相同前缀的手机号被分配到相同的Reducer任务中。
序列化和反序列化
通过定义一个FlowBean类实现了 Writable 接口,Writable接口是用于序列化和反序列化对象的接口。通过实现 Writable 接口,定义自定义的数据类型,使其可以在 MapReduce 程序中作为键或值进行传输,并在最后调用 toString() 方法输出,将以指定的格式打印对象的内容。
通过上述方式,可以有效地对手机号进行分组,并将每个手机号对应的上行流量和下行流量相加,最终得到总流量。同时,自定义分区类可以确保相同前缀的手机号被正确分配到对应的Reducer任务中,实现按照手机号前缀进行区分的需求。
具体步骤
首先需要创建一个名为FlowBean的类,实现了 Writable 接口,重写 write() 和 readFields()方法,定义了 FlowBean 类的成员变量 upFlow、downFlow 和 sumFlow,以及相应的 get 和 set 方法。这些成员变量用于存储上行流量、下行流量和总流量的值。同时,定义一个带参构造函数和空参构造函数,以便进行对象的初始化。
upFlow : 存储上行流量,
downFlow:存储下行流量,
sumFlow :存储总流量(上行流量加下行流量),
public FlowBean() { } :
空参构造函数,用于反序列化时需要反射调用空参构造函数,
public FlowBean(long upFlow, long downFlow) :
带参构造函数,接受上行流量和下行流量作为参数,并计算总流量。
get 和 set 方法:
用于获取和设置对象的成员变量值,以在外部访问和修改 upFlow、downFlow 和 sumFlow 的值,实现了封装。
write(DataOutput out) 方法:
将对象的字段按照特定顺序写入 DataOutput 流中,按照顺序写入了 upFlow、downFlow 和 sumFlow 字段的值,分别使用 out.writeLong() 方法将它们写入输出流中,读取的顺序必须与写入时的顺序完全一致。
readFields(DataInput in) 方法:
从 DataInput 流中读取字段的值,并将其设置回对象的对应字段中。
按照序列化时的顺序,依次读取了 upFlow、dFlow 和 sumFlow 字段的值,分别使用 in.readLong() 方法从输入流中读取这些值,读取的顺序必须与写入时的顺序完全一致。
接下来,编写一个FlowCountMapper类(Map Task),继承自 Hadoop 的 Mapper 类,并重写了 map 方法,map 方法接受三个参数:key、value 和 context。key 表示输入的键,value 表示输入的值,context 用于写入输出。将 Text 类型的输入值 value 转换为字符串类型,并将其存储在 line 变量中。
接着,使用制表符 \t 对 line 进行分割,得到一个字符串数组 fields,然后从中提取出手机号码和上行流量、下行流量的值,将手机号码作为键,创建一个新的 FlowBean 对象,将上行流量和下行流量作为参数传入,并将这个键值对写入到 Hadoop 的上下文中。
String phoneNbr = fields[1]; // 取出手机号
long upFlow = Long.parseLong(fields[fields.length-3]); // 取出上行流量
long downFlow = Long.parseLong(fields[fields.length-2]); // 取出下行流量
// 将电话号码作为键,上行流量和下行流量组成的FlowBean对象作为值
context.write(new Text(phoneNbr), new FlowBean(upFlow, downFlow));
然后,编写一个FlowCountReducer类(Reduce Task),继承自 Hadoop 的 Reducer 类,并重写了 reduce 方法,reduce 方法接受三个参数:key、values 和 context。key 表示输入的键,即手机号,values 是一个 Iterable 对象,包含了同一手机号对应的多个 FlowBean 对象,context 用于写入输出,初始化了两个变量 sum_upFlow 和 sum_downFlow,用于存储累加后的总上行流量和总下行流量,遍历 values,即同一手机号对应的多个 FlowBean 对象,将每个 FlowBean 对象中的上行流量和下行流量分别累加到 sum_upFlow 和 sum_downFlow 变量中,创建一个新的 FlowBean 对象 resultBean,其中包含了累加后的总上行流量和总下行流量,并将这个结果写入到 Reducer的上下文中。
for(FlowBean bean: values){
// 遍历Reducer接收到的所有FlowBean对象(上行流量和下行流量数据)
sum_upFlow += bean.getUpFlow(); // 获取当前bean对象的上行流量
sum_dFlow += bean.getdFlow(); // 获取当前bean对象的下行流量
}
// 创建一个新的FlowBean对象,其中包含了累加后的总上行流量和总下行流量
FlowBean resultBean = new FlowBean(sum_upFlow, sum_dFlow);
// resultBean是包含总上行流量和总下行流量的FlowBean对象,写入到HDFS
context.write(key, resultBean);
此外,需要定义了一个名为 ProvincePartitioner 的类,继承Partitioner类,重写了 getPartition()方法,根据手机号的前缀将不同手机号分配到不同的Reducer任务中。指定了输入键值对的类型为 <Text, FlowBean>,在类中定义了一个静态的 HashMap类型的 province 变量,用于存储前缀和对应的分区号的映射关系。在静态初始化块中,将前缀 “13” 映射到分区号 0,将前缀 “15” 映射到分区号 1,重写了 getPartition() 方法,该方法根据键的前缀来确定数据应该分配到哪个 Reducer 分区,首先,从键中获取前两个字符作为前缀,然后,根据前缀在 province中查找对应的分区号,如果找到则返回该分区号;否则返回默认的分区号 2。
// 初始化proviceDict,用于存储前缀和对应的分区号的映射关系
public static HashMap<String, Integer> province= new HashMap<String, Integer>();
// 前缀"13"映射到分区号0,将前缀"15"映射到分区号1
static {
province.put(“13”, 0);
province.put(“15”, 1);
}
// 获取键的前两个字符作为前缀
String prefix = key.toString().substring(0, 2);
// 根据不同的前缀返回不同的分区号
if (proviceDict.containsKey(prefix)) {
return proviceDict.get(prefix);
} else {
// 其他情况返回分区号 2
return 2;
}
整个开发过程还需要编写Driver类来配置和启动MapReduce作业,设置输入输出路径、指定Mapper和Reducer类、设置分区处理类等。通过这些步骤,可以完成对手机号流量的统计并按照前缀分别输出到不同的文件中。这种方式可以有效地对数据进行处理和分析,来满足需求。
运行结果截图
分区一(前缀 “13”)
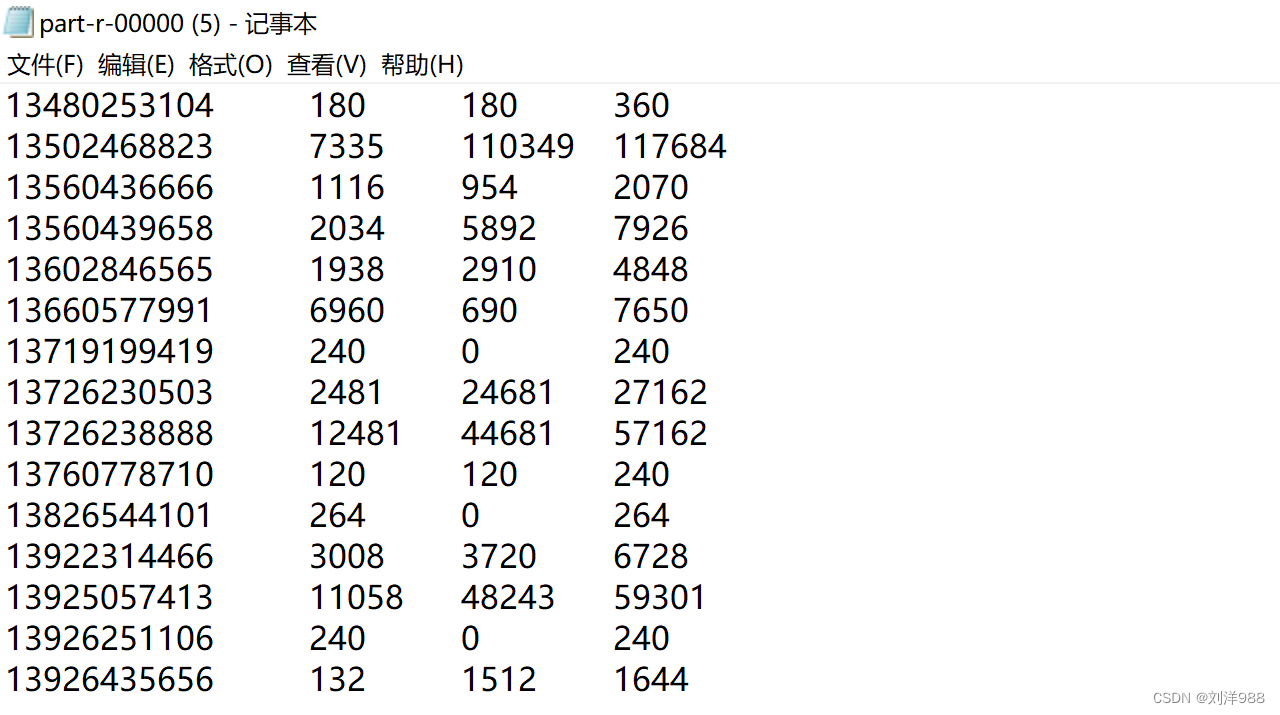
分区二(前缀 “15”)

分区三(前缀 其他)

代码展示
PhoneBean
//实现了Hadoop中的Writable接口,用于在MapReduce程序中传输自定义对象
public class PhoneBean implements Writable{
//包含上行流量、下行流量和总流量的数据对象
private long upFlow;
private long downFlow;
private long addFlow;
//反序列化时,需要反射调用空参构造函数,所以要显示定义一个
public PhoneBean(){}
//提供了一个带参构造函数和一个空参构造函数,用于对象的初始化。
public PhoneBean(long upFlow, long downFlow) {
this.upFlow = upFlow;
this.downFlow = downFlow;
this.addFlow = upFlow + downFlow;
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getAddFlow() {
return addFlow;
}
public void setAddFlow(long addlow) {
this.addFlow = addFlow;
}
/**
* 序列化方法
*/
//用于将对象序列化为字节流和从字节流反序列化为对象
//分布式环境中,数据需要在不同的节点之间进行传输和交换,
//而不同节点之间的通信可能涉及到不同的编程语言、操作系统和硬件平台。通过将对象序列化为字节流
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(addFlow);
}
/**
* 反序列化方法
* 注意:反序列化的顺序跟序列化的顺序完全一致
*/
@Override
public void readFields(DataInput in) throws IOException {
upFlow = in.readLong();
downFlow = in.readLong();
addFlow = in.readLong();
}
@Override
//重写了toString方法,方便在输出时打印对象的内容
public String toString() {
return upFlow + "\t" + downFlow + "\t" + addFlow;
}
}
PhoneCountMapper
//Map阶段 (PhoneCountMapper)
static class PhoneCountMapper extends Mapper<LongWritable, Text, Text, FlowBean>{
@Override
//PhoneCountMapper类继承自Mapper类,重写了map方法,用于处理输入的每一行数据
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//长整型(long)的Writable类型
//将一行内容转成string
String line = value.toString();
//切分字段
String[] fields = line.split("\t");
//取出手机号
String phone = fields[1];
//取出上行流量下行流量
long upFlow = Long.parseLong(fields[fields.length-3]);
long downFlow = Long.parseLong(fields[fields.length-2]);
//将电话号码作为键,上行流量和下行流量组成的FlowBean对象作为值,写入到Hadoop的上下文中
context.write(new Text(phone), new FlowBean(upFlow, downFlow));
}
}
PhoneCountReducer
//Reduce阶段 (PhoneCountReducer)
static class PhoneCountReducer extends Reducer<Text, FlowBean, Text, FlowBean>{
//FlowCountReducer类继承自Reducer类,重写了reduce方法,用于对相同手机号的流量数据进行累加操作。
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {
long sum_upFlow = 0;
long sum_downFlow = 0;
//遍历所有bean,将其中的上行流量,下行流量分别累加
//在Reducer阶段中对传入的Bean对象进行累加操作,
//将所有Bean对象中的上行流量和下行流量分别累加到sum_upFlow和sum_downFlow变量中。
for(Bean bean: values){ //遍历Reducer接收到的所有Bean对象(上行流量和下行流量数据)
sum_upFlow += bean.getUpFlow(); //获取当前bean对象的上行流量
sum_downFlow += bean.getDownFlow(); //获取当前bean对象的下行流量
}
//创建一个新的Bean对象,其中包含了累加后的总上行流量和总下行流量,并将这个结果写入到Reducer的上下文中
Bean sumBean = new Bean(sum_upFlow, sum_downFlow);
//sumBean是包含总上行流量和总下行流量的Bean对象,写入到HDFS。
context.write(key, sumBean);
}
}
PhonePartitioner
public class PhonePartitioner extends Partitioner<Text, Bean> {
//指定了输入键值对的类型为Text, FlowBean
public static HashMap<String, Integer> province = new HashMap<String, Integer>();
//初始化province
//用于存储前缀和对应的分区号的映射关系
static {
province.put("13", 0);
province.put("15", 1);
}
//前缀"13"映射到分区号0,将前缀"15"映射到分区号1
@Override
//重写了getPartition方法,该方法根据键的前缀来确定数据应该分配到哪个Reducer分区
public int getPartition(Text key, Bean value, int numPartitions) {
String prefix = key.toString().substring(0, 2);
// 获取键的前两个字符作为前缀
// 根据不同的前缀返回不同的分区号
if (province.containsKey(prefix)) {
return province.get(prefix);
} else {
// 其他情况返回分区号 2
return 2;
}
}
}
Driver
Job job = Job.getInstance(conf);
//指定本程序的jar包所在的本地路径
//设置作业运行时使用的Jar包,这里使用FlowCount类所在的Jar包
job.setJarByClass(FlowCount.class);
//指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(FlowCountMapper.class);
job.setReducerClass(FlowCountReducer.class);
//指定mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
//指定最终输出的数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
//指定我们自定义的数据分区器
job.setPartitionerClass(ProvincePartitioner.class);
//同时指定相应“分区”数量的reducetask
job.setNumReduceTasks(3);
//指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
//指定job的输出结果所在目录
FileOutputFormat.setOutputPath(job, new Path(args[1]));
遇到的问题及解决方案
| 遇到的问题 | 解决方案 |
|---|---|
| 在pom.xml文件中导入坐标超时报错 | 通过使用国内的阿里云镜像解决 |
| Java 运行版本低于编译类文件用的版本 | 使用支持当前 Java 版本编译器来编译代码 |















 7491
7491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









