






引言
协同过滤算法是一种推荐系统算法,通过分析用户的历史行为数据(如评分、点击、购买记录等)来推荐用户可能感兴趣的物品。主要有两种类型:
-
基于用户的协同过滤:根据用户之间的相似性来推荐物品。如果两个用户在过去的行为中喜欢相似的物品,那么他们可能对同样的物品感兴趣。
-
基于物品的协同过滤:根据物品之间的相似性来推荐物品。如果一个用户喜欢某个物品,那么与该物品相似的其他物品也有可能被推荐给该用户。
协同过滤算法不需要事先对物品或用户进行特征提取,而是直接利用用户行为数据进行推荐。它是推荐系统中常用且有效的算法之一,能够帮助用户发现新的、个性化的物品。
协同过滤算法的原理
根据用户群体对产品偏好的数据,发现用户之间的相似性或者物品之间的相似性,并基于这些相似性为用户作推荐。
-
基于用户的协同过滤算法(User-based Collaborative Filtering)
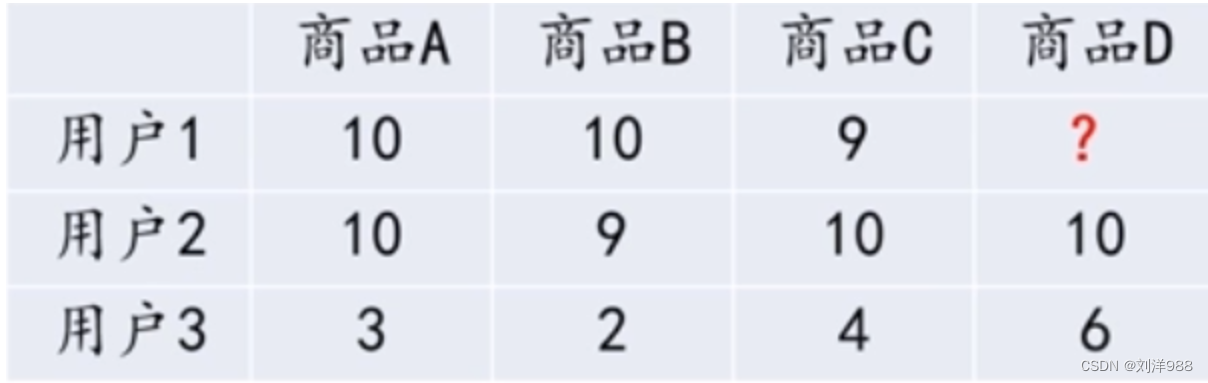
其本质是:寻找相似的用户,进而对用户推荐相似用户关注的产品。如下表所示,用户1和用户2都给商品A,B,C打了高分,那么可以将用户1和用户2划分在同一个用户群体,此时若用户2还给商品D打了高分,那么就可以将商品D推荐给用户1。
-
基于物品的协同过滤算法(Item-based Collaborative Filtering)
其本质是:根据用户的历史偏好信息,将类似的物品推荐给用户
如下表所示,图书A和图书B都被用户1,2,3购买过(1表示购买,0表示未购买),那么可以认为图书A和图书B具有较强的相似度,即可判断喜欢图书A的用户同样也会喜欢图书B。当用户4购买图书B时,根据图书A和图书B的相似性,可将图书A推荐给用户4。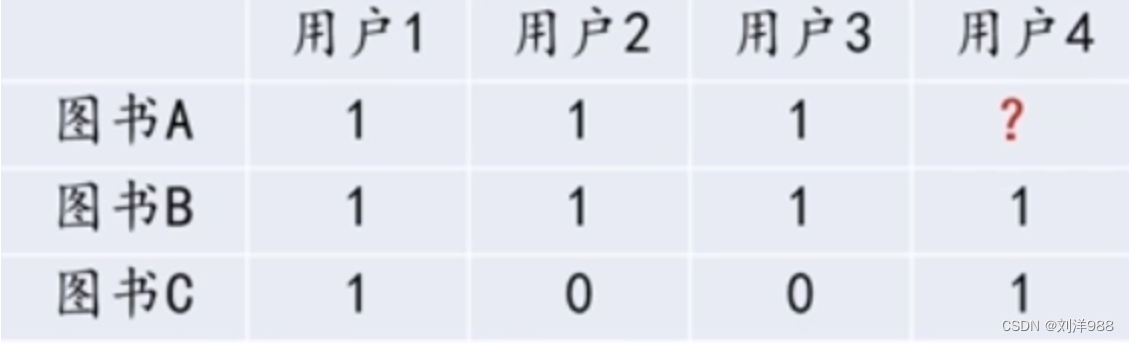
相似度计算的常用方法
-
欧式距离
∑ i = 1 n ( X i ( a ) − X i ( b ) ) 2 \Large \sqrt{\sum_{i=1}^n{(X_i^{(a)}-X_i^{(b)})}^2} i=1∑n(Xi(a)−Xi(b))2 -
余弦相似度
c o s θ = < a , b > ∣ ∣ a ∣ ∣ ∣ ∣ b ∣ ∣ \Large cos\theta = \frac{<a,b>}{|| a|||| b||} cosθ=∣∣a∣∣∣∣b∣∣<a,b>
- 皮尔逊相关系数
r = C o v ( X , Y ) S X S Y \Large r=\frac{Cov(X,Y)}{S_XS_Y} r=SXSYCov(X,Y)
相似度计算的Python实现
- 欧式距离的Python实现
import pandas as pd
df = pd.DataFrame([[5, 1, 5], [4, 2, 2], [4, 2, 1]], columns=['用户1', '用户2', '用户3'], index=['物品A', '物品B', '物品C'])
import numpy as np
dist = np.linalg.norm(df.iloc[0] - df.iloc[1])
- 余弦相似度的Python实现
import pandas as pd
df = pd.DataFrame([[5, 1, 5], [4, 2, 2], [4, 2, 1]], columns=['用户1', '用户2', '用户3'], index=['物品A', '物品B', '物品C'])
from sklearn.metrics.pairwise import cosine_similarity
# 对两两样本之间(此处是物品之间)做余弦相似度矩阵
item_similarity = cosine_similarity(df)
pd.DataFrame(item_similarity, columns=['物品A', '物品B', '物品C'], index=['物品A', '物品B', '物品C'])
- 皮尔逊相关系数的Python实现
from scipy.stats import pearsonr
X = [1, 3, 5, 7, 9]
Y = [9, 8, 6, 4, 2]
corr = pearsonr(X, Y)
print("皮尔逊相关系数r的值为:",corr[0],"显著性水平P值为:",corr[1])
相关系数在DataFrame中的应用
在计算相关系数的场景里,DataFrame的corrwith()和corr()方法经常被使用。
-
corrwith()
dataframe.corrwith()用于计算行或列之间的成对相关关系
-
corr()
dataframe.corr()用于计算DataFrame中所有列的成对相关性
import pandas as pd
df = pd.DataFrame([[5, 4, 4], [1, 2, 2], [5, 2, 1]], columns=['物品A', '物品B', '物品C'], index=['用户1', '用户2', '用户3'])
# 物品A与其他物品的皮尔逊相关系数
A = df['物品A']
corr_A = df.corrwith(A) # 等同于corr_A = df.corrwith(A,axis=0)
# 皮尔逊系数表,获取各物品(列)的皮尔逊相关系数
df.corr()
电影智能推荐系统代码实现
# 读取数据
import pandas as pd
movies = pd.read_excel('电影.xlsx')
movies = movies.loc[:, ~movies.columns.str.contains('Unnamed')]
movies.head()
score = pd.read_excel('评分.xlsx')
score.head()
# 合并电影数据和评分数据
df = pd.merge(movies, score, on='电影编号')
df.head()
# 计算每部电影的评分均值,并组装成DataFrame
ratings = pd.DataFrame(df.groupby('名称')['评分'].mean())
# 添加评分次数列
ratings['评分次数'] = df.groupby('名称')['评分'].count()
# 根据评分次数降序排序
ratings.sort_values('评分次数', ascending=False).head()
# 创建透视表
user_movie = df.pivot_table(index='用户编号', columns='名称', values='评分')
user_movie.tail()
user_movie.shape
# 智能推荐
FG = user_movie['阿甘正传(2031)'] # FG阿甘英文名称的缩写
pd.DataFrame(FG).head()
# axis默认为0,计算user_movie各列与FG的相关系数
corr_FG = user_movie.corrwith(FG)
similarity = pd.DataFrame(corr_FG, columns=['相关系数'])
similarity.head()
# 删除相关系数是NaN的数据
similarity.dropna(inplace=True)
similarity.head()
# 合并DataFrame
similarity_new = pd.merge(similarity, pd.DataFrame(ratings['评分次数']), left_index=True, right_index=True)
similarity_new.head()
# 筛选出评分次数超过20次的电影数据,并按照相关系数降序排序
similarity_new[similarity_new['评分次数'] > 20].sort_values(by='相关系数', ascending=False).head(10)
补充——groupby()分组代码
import pandas as pd
# 创建DataFrame对象
data = pd.DataFrame([['三国', '王刚', 6, 8], ['盗梦空间', '王二', 8, 6], ['盗梦空间', '张三', 10, 8], ['海上钢琴师', '刘勇', 8, 8], ['海上钢琴师', '赵五', 8, 10]], columns=['电影名称', '影评师', '观前评分', '观后评分'])
# 根据"电影名称"分组,然后对每一组的“观后评分”计算平均值
data.groupby('电影名称')['观后评分'].mean()
# 也可以通过DataFrame的形式展示结果
data.groupby('电影名称')[['观后评分']].mean()
#对分组后的多个列求平均值
data.groupby('电影名称')[['观前评分', '观后评分']].mean()
# 通过多个字段分组
data.groupby(['电影名称', '影评师'])[['观后评分']].mean()
# 统计分组后每一组对应列的次数
count = data.groupby('电影名称')[['观后评分']].count()
# 修改列名称
count = count.rename(columns={'观后评分':'评分次数'})















 70
70

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









