






前言
电商是一种通过互联网进行商品和服务交易的新型贸易形式。随着互联网的普及和人们生活中越来越多的事物都变得数字化,电商已经成为现代社会中不可或缺的一部分。电商平台为消费者提供了方便快捷的购物体验,为商家提供了广阔的市场和高效的销售渠道。然而,电商平台上的数据量巨大,数据类型多样,数据流量高峰时间突然增加,这为数据分析和挖掘带来了巨大挑战。
Hadoop 是一个开源的分布式文件系统(HDFS)和分布式计算框架(MapReduce),它可以处理大规模数据并提供高性能、高可靠性和高可扩展性。Hadoop 在电商领域具有广泛的应用,可以帮助电商平台更好地挖掘数据价值,提高营销和销售效果。
一、项目需求
根据电商日志文件,分析:
- 统计页面浏览量(每行记录就是一次浏览)
- 统计各个省份的浏览量 (需要解析IP)
- 日志的ETL操作(ETL:数据从来源端经过抽取(Extract)、转换(Transform)、加载(Load)至目的端的过程)
为什么要ETL:没有必要解析出所有数据,只需要解析出有价值的字段即可。本项目中需要解析出:ip、url、pageId(topicId对应的页面Id)、country、province、city
数据为trackinfo_20130721.txt电商日志文件:
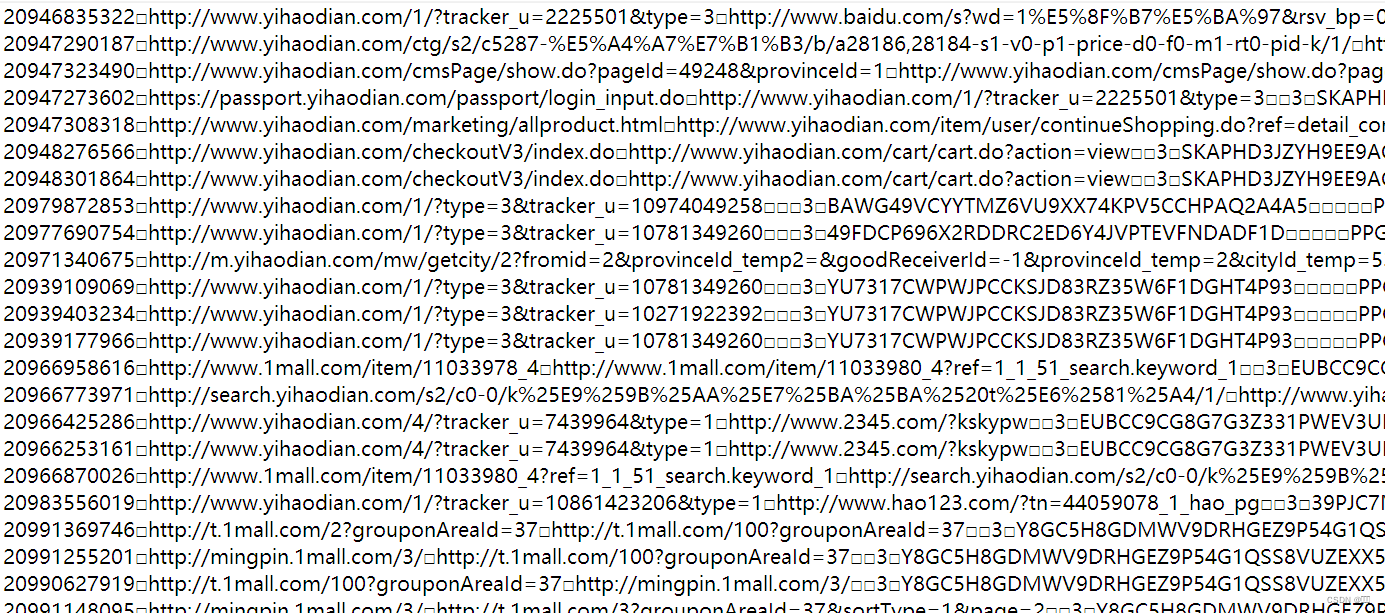
二、开发步骤
1.分析数据
通过对数据的分析,可以得出对我们有用的字段的位置:
- IP:第十四个字段
- url:第二个字段
- pageId:第十一个字段
- time:第十八个字段
我们首先需要将这些字段从日志文件中提取出来,才能进行接下来的操作。
2.创建Maven项目
创建项目并配置好本地仓库:

配置好pom.xml文件,在其中添加Hadoop依赖:
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.0</version> //此处添加自己的Hadoop版本
</dependency>
</dependencies>
后续请看下一篇文章:
需要代码:https://blog.csdn.net/2303_77130695/article/details/139606448
已有代码,待运行:https://blog.csdn.net/2303_77130695/article/details/139628997















 8049
8049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









