







论文地址:https://arxiv.org/pdf/2311.17117.pdf
项目地址:MooreThreads/Moore-AnimateAnyone (github.com) HumanAIGC/AnimateAnyone:Animate Anyone:用于角色动画的一致且可控的图像到视频合成 (github.com)

1. 模型简介
Animate Anyone是一项角色动画技术,能将静态图像依据指定动作生成动态的角色视频。该技术利用扩散模型,以保持图像到视频转换中的时间一致性和内容细节。该Paddle版本的具体实现借鉴于MooreThreads/Moore-AnimateAnyone。
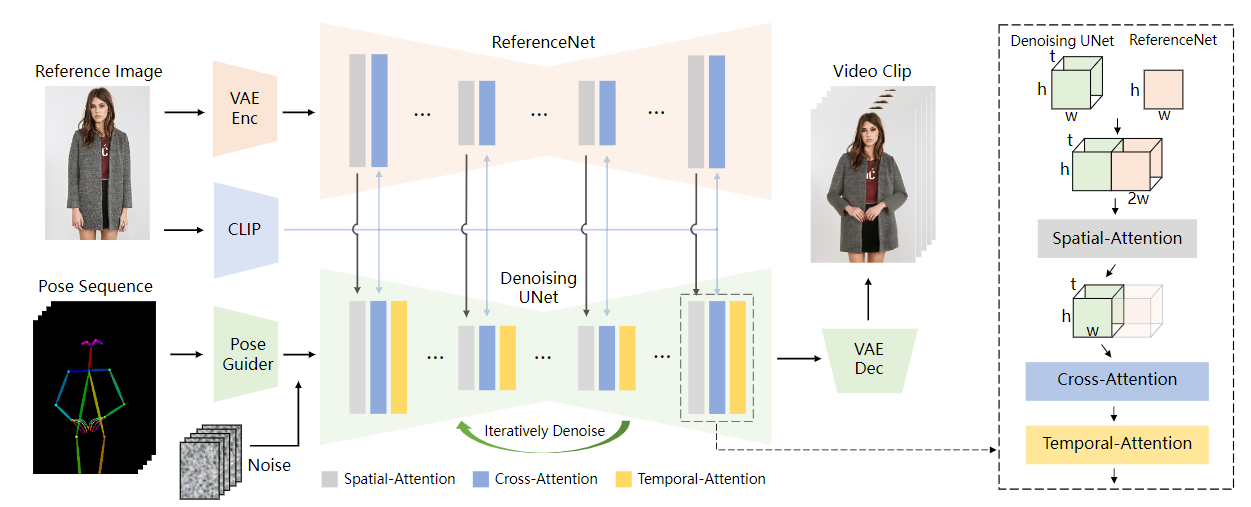
注:上图引自 AnimateAnyone。
先来看一段钢铁侠跳舞吧💃

2. 环境准备
安装新版本ppdiffusers以及该项目相关依赖。
!pip install https://paddlenlp.bj.bcebos.com/models/community/junnyu/wheels/ppdiffusers-0.24.0-py3-none-any.whl --user
!pip install -r requirements.txt3. 模型下载
运行以下自动下载脚本,下载 AnimateAnyone 相关模型权重文件,模型权重文件将存储在./pretrained_weights下面。
!python scripts/download_weights.py
/opt/conda/envs/python35-paddle120-env/lib/python3.10/site-packages/_distutils_hack/__init__.py:33: UserWarning: Setuptools is replacing distutils.
warnings.warn("Setuptools is replacing distutils.")
W0308 18:03:44.355866 10792 gpu_resources.cc:119] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 12.0, Runtime API Version: 11.8
W0308 18:03:44.357172 10792 gpu_resources.cc:164] device: 0, cuDNN Version: 8.9.
Preparing AnimateAnyone pretrained weights...
(…)munity/Tsaiyue/AnimateAnyone/config.json: 100%|█| 746/746 [00:00<00:00, 3.62M
(…)ue/AnimateAnyone/denoising_unet.pdparams: 100%|▉| 3.44G/3.44G [01:42<00:00, 3
(…)yue/AnimateAnyone/motion_module.pdparams: 100%|▉| 1.82G/1.82G [00:07<00:00, 2
(…)aiyue/AnimateAnyone/pose_guider.pdparams: 100%|█| 4.35M/4.35M [00:00<00:00, 2
(…)ue/AnimateAnyone/reference_unet.pdparams: 100%|▉| 3.44G/3.44G [01:58<00:00, 2
Preparing DWPose weights...
4. 模型推理
运行以下推理命令,生成指定宽高和帧数的动画,将存储在./output下。
!python -m scripts.pose2vid --config ./configs/inference/animation.yaml -W 512 -H 784 -L 120
/opt/conda/envs/python35-paddle120-env/lib/python3.10/site-packages/_distutils_hack/__init__.py:33: UserWarning: Setuptools is replacing distutils.
warnings.warn("Setuptools is replacing distutils.")
W0308 18:15:15.202808 14415 gpu_resources.cc:119] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 12.0, Runtime API Version: 11.8
W0308 18:15:15.204226 14415 gpu_resources.cc:164] device: 0, cuDNN Version: 8.9.
Some weights of the model checkpoint at runwayml/stable-diffusion-v1-5 were not used when initializing UNet2DConditionModel: ['conv_norm_out.bias', 'conv_norm_out.weight', 'conv_out.bias', 'conv_out.weight']
- This IS expected if you are initializing UNet2DConditionModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing UNet2DConditionModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
[2024-03-08 18:15:23,465] [ INFO] - Found /home/aistudio/.cache/paddlenlp/ppdiffusers/lambdalabs/sd-image-variations-diffusers/image_encoder/config.json
[2024-03-08 18:15:23,467] [ INFO] - Loading configuration file /home/aistudio/.cache/paddlenlp/ppdiffusers/lambdalabs/sd-image-variations-diffusers/image_encoder/config.json
[2024-03-08 18:15:23,468] [ INFO] - Model config CLIPVisionConfig {
"_name_or_path": "/home/jpinkney/.cache/huggingface/diffusers/models--lambdalabs--sd-image-variations-diffusers/snapshots/ca6f97f838ae1b5bf764f31363a21f388f4d8f3e/image_encoder",
"architectures": [
"CLIPVisionModelWithProjection"
],
"attention_dropout": 0.0,
"dropout": 0.0,
"hidden_act": "quick_gelu",
"hidden_size": 1024,
"image_size": 224,
"initializer_factor": 1.0,
"initializer_range": 0.02,
"intermediate_size": 4096,
"layer_norm_eps": 1e-05,
"model_type": "clip_vision_model",
"num_attention_heads": 16,
"num_channels": 3,
"num_hidden_layers": 24,
"paddlenlp_version": null,
"patch_size": 14,
"projection_dim": 768,
"return_dict": true,
"transformers_version": "4.25.1"
}
[2024-03-08 18:15:23,581] [ INFO] - Already cached /home/aistudio/.cache/paddlenlp/ppdiffusers/lambdalabs/sd-image-variations-diffusers/image_encoder/model_state.pdparams
[2024-03-08 18:15:23,581] [ INFO] - Loading weights file model_state.pdparams from cache at /home/aistudio/.cache/paddlenlp/ppdiffusers/lambdalabs/sd-image-variations-diffusers/image_encoder/model_state.pdparams
[2024-03-08 18:15:24,808] [ INFO] - Loaded weights file from disk, setting weights to model.
[2024-03-08 18:15:26,052] [ INFO] - All model checkpoint weights were used when initializing CLIPVisionModelWithProjection.
[2024-03-08 18:15:26,053] [ INFO] - All the weights of CLIPVisionModelWithProjection were initialized from the model checkpoint at lambdalabs/sd-image-variations-diffusers/image_encoder.
If your task is similar to the task the model of the checkpoint was trained on, you can already use CLIPVisionModelWithProjection for predictions without further training.
pose video has 200 frames, with 30 fps
100%|█████████████████████████████████████████████| 1/1 [01:10<00:00, 70.03s/it]
100%|█████████████████████████████████████████| 120/120 [00:23<00:00, 5.07it/s]
局限性:我们在当前版本中观察到以下缺点:
- 当参考图像具有干净的背景时,背景可能会出现一些伪影
- 当参考图像和关键点之间存在比例不匹配时,可能会出现次优结果。我们还没有实现论文中提到的预处理技术。
- 当运动序列微妙或场景是静态时,可能会出现一些闪烁和抖动。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











