











在数字时代,图像和视频内容爆炸式增长,如何让AI像人类一样精准描述画面中的特定区域,成为计算机视觉领域的核心挑战。传统模型要么丢失细节,要么缺乏上下文,而NVIDIA与UC Berkeley联合团队提出的DAM(Describe Anything Model)彻底改变了这一局面。DAM以图像中的点/框/涂鸦/掩码的形式获取用户指定区域的输入,并生成图像的详细本地化描述。DAM 使用新颖的焦点提示和通过门控交叉注意增强的局部视觉主干将全图像上下文与精细的局部细节集成在一起。它不仅能够根据用户点击、框选或涂鸦生成多粒度的描述,还能在复杂场景中保持细节与全局的完美平衡。更令人惊叹的是,DAM在7大基准测试中刷新纪录,甚至超越GPT-4o等顶级模型。本文将深入解析这一突破性技术,揭开其背后的三大创新:焦点提示、局部视觉主干和半监督数据流水线,以及它如何重新定义细粒度视觉理解。
视觉-语言模型(VLMs)在生成整体图像描述时表现出色,但对特定区域的细致描述往往力不从心,尤其在视频中需考虑时间动态,挑战更大。英伟达推出的 Describe Anything 3B(DAM-3B)直面这一难题,支持用户通过点、边界框、涂鸦或掩码指定目标区域,生成精准且贴合上下文的描述文本。DAM-3B 和 DAM-3B-Video 分别适用于静态图像和动态视频,模型已在 Hugging Face 平台公开。
一、描述一切模型效果示例,着重在于局部详细描述
DAM 深入地挖掘用户指定区域的细微细节。其目标不仅是捕捉对象的名称或类别,还包括微妙的属性,如纹理、颜色图案、形状、特点以及任何视觉上独特的特征。
来看一下 DAM 的图片描述:一只白色的猫,有着浅橙色的耳朵和粉红色的鼻子。这只猫表情轻松,身上的皮毛柔软洁白。

DAM 图片描述:一只中等体型的狗,身上有厚厚的红棕色毛发和脸部、胸部、爪子的白色斑纹。狗长着尖耳朵,蓬松的尾巴,戴着红色的项圈。它的嘴巴张开,露出舌头和牙齿,看起来正处于跳跃的瞬间。

DAM 视频描述:一头身披深棕色皮毛、臀部有一块浅色斑块的母牛,正以一系列动作展现其姿态。起初,母牛略微低着头,展现出平静的神态。随着画面的推进,母牛开始向前移动,双腿舒展,步态稳健而有节奏。其尾端有簇毛,每走一步都会轻轻摆动,为其动作增添一丝流畅感。

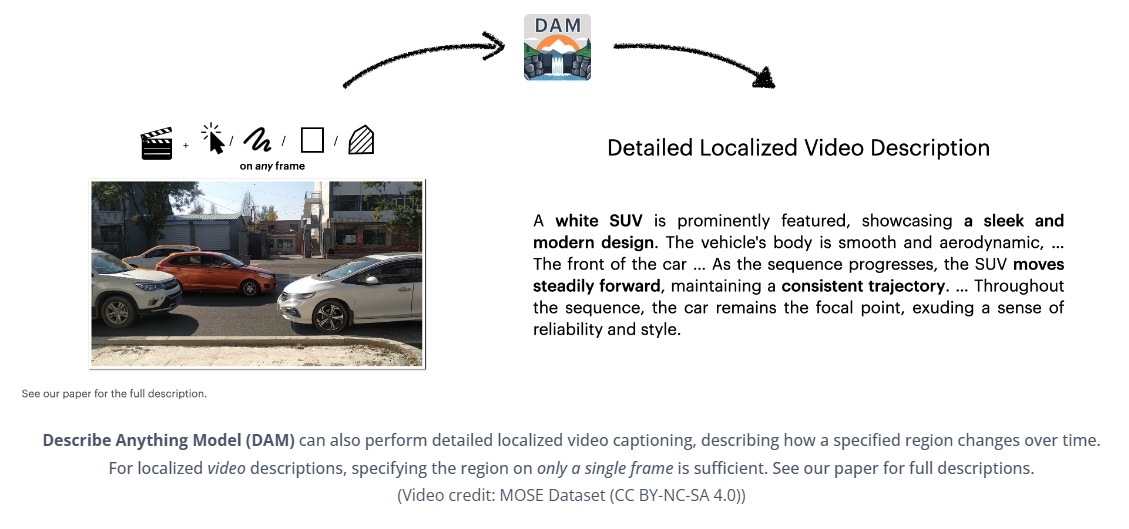
此外,DAM 还可以执行详细的局部视频字幕,描述指定区域随时间的变化。对于局部视频描述,仅指定单个帧上的区域即可。
视频描述:一辆造型流畅的银色SUV占据了显著位置,SUV的前部采用大胆的格栅和锐利的前大灯,赋予其动感而自信的外观。随着镜头的推进,SUV稳步向前,车轮在路面上平稳转动。SUV的尾部配备了时尚的尾灯和精致的扰流板,更增添了其运动美感。在整个镜头中,SUV始终保持着恒定的速度,展现出自信而沉稳的驾驶体验,与车流浑然一体。
二、描述一切模型的突破:细粒度、交互式视觉理解!
DAM的核心创新在于Detailed Localized Captioning (DLC),它能根据用户指定的点、框、涂鸦或蒙版,生成高度精细的区域描述。关键能力:
✅ 像素级细节捕捉:通过平衡焦点区域的清晰度和全局上下文,不仅识别物体类别,还能描述纹理、颜色渐变、形状特征等,这远远超出了一般图像级字幕所能提供的范围。

✅ 视频动态跟踪:跨帧分析目标变化(如“红色气球从画面左侧飘向右侧,期间逐渐膨胀”)
✅ 指令控制的描述:用户可以引导我们的模型生成不同细节和风格的描述。无论是简短的摘要,还是冗长复杂的叙述,模型都能调整输出。

✅ 零样本的区域保证:模型无需额外的训练数据即可回答有关特定区域的问题。用户可以询问该区域的属性,模型会利用其对本地区域的理解,提供准确的、基于情境的答案。

3. DAM模型架构:细节与上下文的双赢设计
3.1 精准捕捉细节
与传统图像描述(概括整个场景)不同,DLC聚焦于用户指定的局部区域,来生成细致入微的描述。
想象一张照片中一只猫,你不仅需要描述「一只猫在窗台上」,还要深入些几「猫的毛发呈现柔软和灰色条纹,耳朵微微倾斜,眼睛在阳光下闪着琥珀色的光芒」。

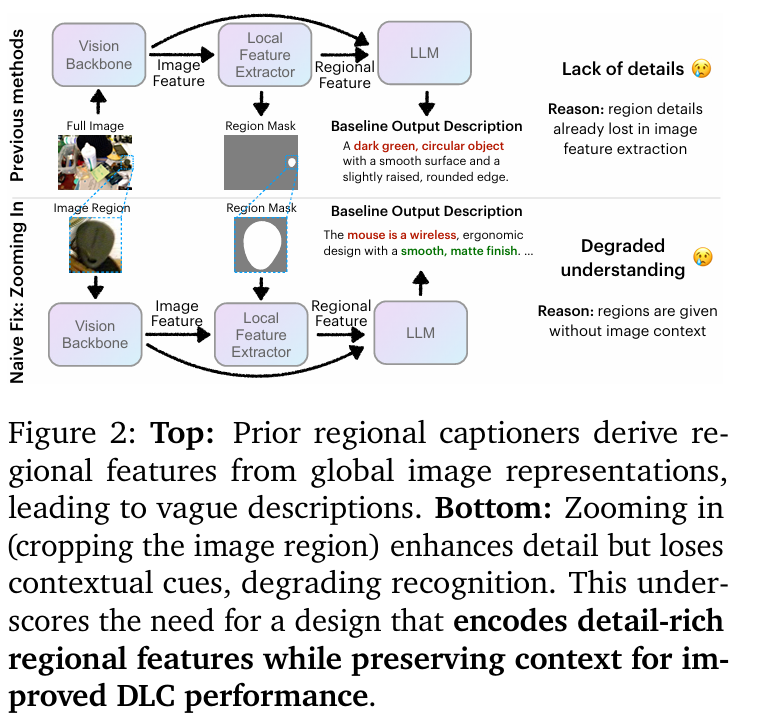
可以看出,DLC的目标是捕捉区域的纹理、颜色、形状、显著部件等特征,同时也要保持与整体场景关联。而在视频领域中,DLC挑战更大,模型需要追目标区域在多个帧中的变化,描述其外观、交互、和细微动态的演变。为了应对DLC复杂需求,Describe Anything Model引入了两大核心创新,让局部细节与全局上下文完美平衡。
3.2 焦点提示 (Focal Prompt)
通过「焦点提示」机制,DAM能够同时处理全图和目标区域的放大视图,这确保它在捕捉细微特征同时,不丢失整体场景的背景信息。
3.3 局部视觉骨干网络 (Localized Vision Backbone)
DAM的视觉骨干网络通过空间对齐的图像和掩码,融合全局与局部特征。利用门控交叉注意力层,模型将详细的局部线索与全局上下文无缝整合。新参数初始化为0,保留了预训练能力,从而生成更丰富、更具上下文关联的描述。
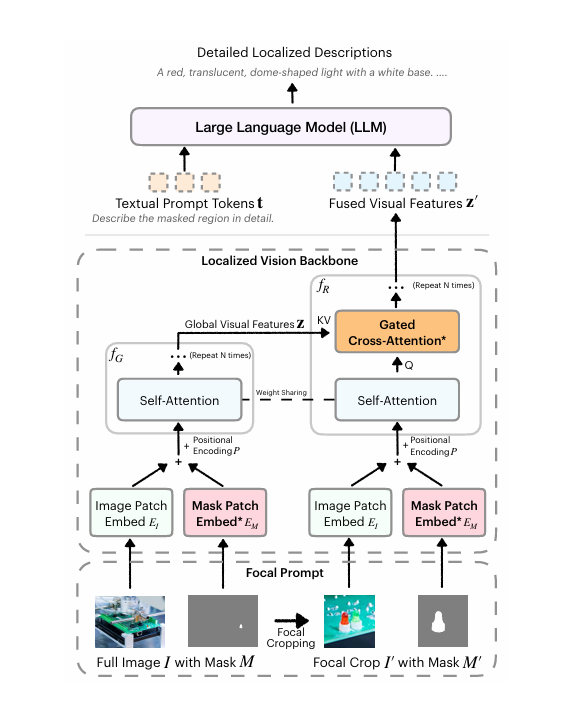
这种架构让DAM在生成关键词、短语,甚至是多句式的复杂描述时,都能保持高精度和连贯性。
DLC-SDP :破解数据瓶颈
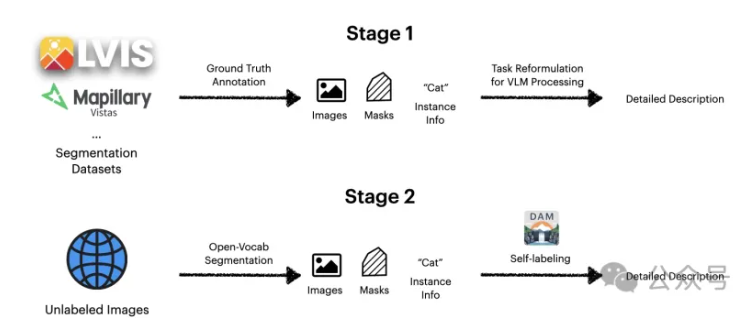
要知道,高质量的DLC数据集极为稀缺,限制了模型的训练。为此,研究团队设计了基于半监督学习的流水线(DLC-SDP),通过两阶段策略构建大规模训练数据。
-
阶段一,是从分割数据集扩展。利用现有分割数据集短标签(猫),通过视觉-语言模型生成丰富的描述(灰色短毛猫,耳朵直立。
-
阶段二,自训练未标记的图像,通过半监督学习,DAM对未标记的网络图像生成初始描述,并迭代精炼,形成高质量的DLC数据。
DLC-Bench :重定义评估标准
那么,如何公平地评估DLC模型。传统方法主要依赖文本重叠,但这无法全面反映描述的准确性和细节。为此,研究团队提出了全新基准DLC-Bench。通过LLM判断,检查描述的正确细节和错误缺失,而非简单对比文本。
DAM仅能生成详细描述,还具备强大的灵活性和交互性。
碾压GPT-4o,刷新SOTA
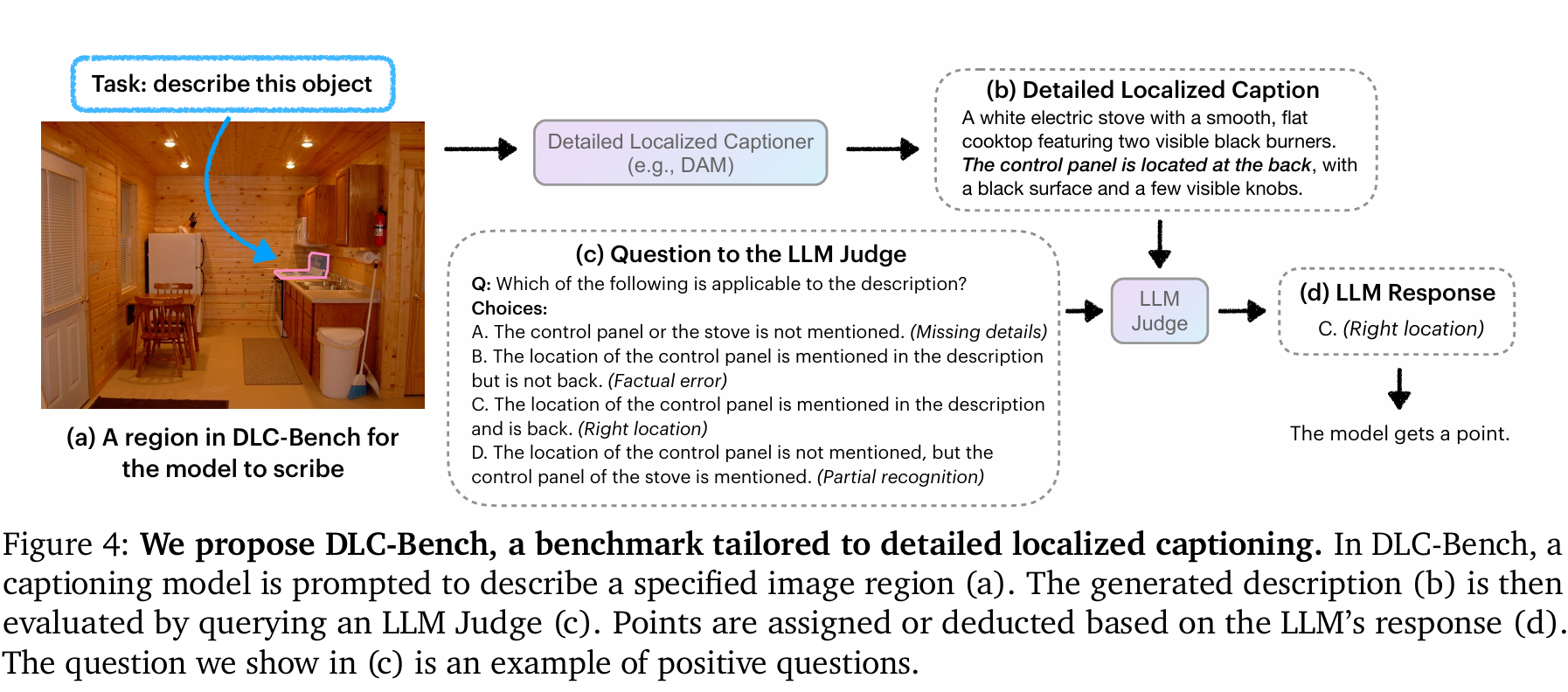
在DLC-Bench和其他7个涵盖图像与视频的基准测试中,DAM全面超越现有模型,树立了新的标杆。如下表2所示,DAM在具有挑战性的 PACO 基准测试中表现出色,创下了89高分。而在零样本评估在短语级数据集Flickr30k Entities上,新模型相比之前的最佳结果平均相对提升了7.34%。此外,零样本评估在详细描述数据Ref-L4 上,DAM在基于短/长语言的描述指标上分别实现了39.5%和13.1%的平均相对提升。
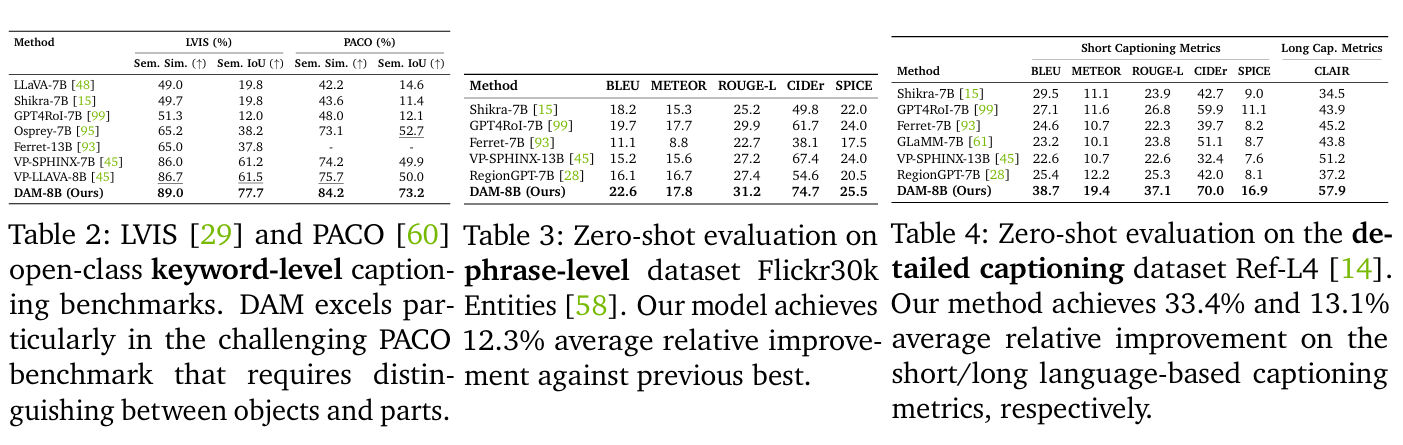
在研究人员提出的DLC-Bench测试中,DAM在详细局部描述方面优于之前的仅API模型、开源模型和特定区域VLM。
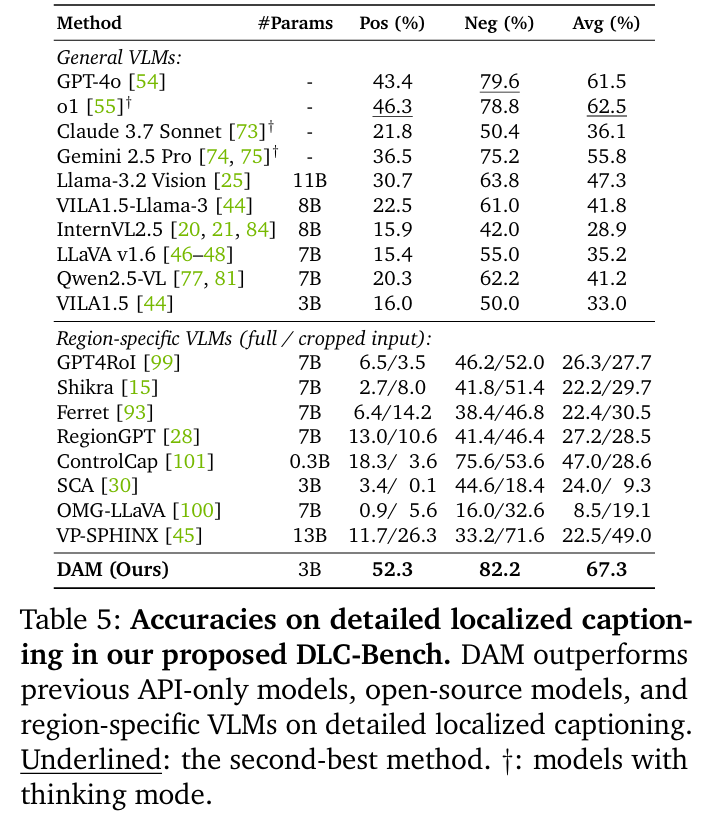
下表6所示,DAM在详细局部视频字幕方面刷新SOTA。
总而言之,DAM的优势主要有三大点:更详细、更准确;更少幻觉;多场景适用。
它的强大能力为众多应用场景打开了大门,未来诸如数据标注、医疗影像、内容创作等领域,都可以加速落地。

Demo 测试
大家也可以上传自己的图片测试一下效果, 描述任何事物 - 由 nvidia 推出的 Hugging Face 空间 — Describe Anything - a Hugging Face Space by nvidia
参考文章
Describe Anything: Detailed Localized Image and Video Captioning
Describe Anything: Detailed Localized Image and Video Captioning
英伟达华人硬核AI神器,「描述一切」秒变细节狂魔!仅3B逆袭GPT-4o
从分割一切到描述一切!从笼统概括到细粒度区域描述!英伟达开源DAM模型:指令控制的字幕生成
英伟达发表DAM模型:让AI“看见”细节,精准描述图像与视频的每一处角落 - 知乎



















 671
671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











