






目录
Definitions:
卷积神经网络(Convolutional Neural Networks,CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一 。卷积神经网络具有表征学习(representation learning)能力,能够按其阶层结构对输入信息进行平移不变分类(shift-invariant classification),因此也被称为“平移不变人工神经网络(Shift-Invariant Artificial Neural Networks, SIANN)” 。------来自于百度百科的定义
卷积神经网络是一个层次模型。主要结构包括输入层,卷积层,池化层,激活层,全连接层以及输出层。(卷积神经网络中还有隐含层,包含卷积层、池化层和全连接层3类常见构筑,在一些更为现代的算法中可能有Inception模块、残差块(residual block)等复杂构筑。在常见构筑中,卷积层和池化层为卷积神经网络特有。卷积层中的卷积核包含权重系数,而池化层不包含权重系数,因此在文献中,池化层可能不被认为是独立的层。以LeNet-5为例,3类常见构筑在隐含层中的顺序通常为:输入-卷积层-池化层-全连接层-输出。)
(一)输入层(Input Layer)
卷积神经网络的输入层用来江原始数据或经过预处理的数据输入网络。可以处理多维数据,常见地,一维卷积神经网络的输入层接收一维或二维数组,其中一维数组通常为时间或频谱采样;二维数组可能包含多个通道;二维卷积神经网络的输入层接收二维或三维数组;三维卷积神经网络的输入层接收四维数组 。
以图像任务为例,当输入为彩色RGB图像时,为3D张量,组成三维像素矩阵(H*W*3),若指定个数则为(N*H*W*3);当输入是灰度图像时,由于只有一个颜色通道,可以保存在2D张量中,彩色通道数只有一维,像素矩阵(H*W*1),若指定个数则为(N*H*W*1).
(二)卷积层(Convolution Layer)
卷积层通常用作对输入层输入的数据进行特征提取。卷积层越多,特征提取能力越强。卷积操做实质上是对俩个像素矩阵进行点乘求和的数学操作。其中一个矩阵为输入的数据矩阵,另一个则是卷积核(滤波器或特征矩阵),所求结果为原始图像中提取的局部特征。
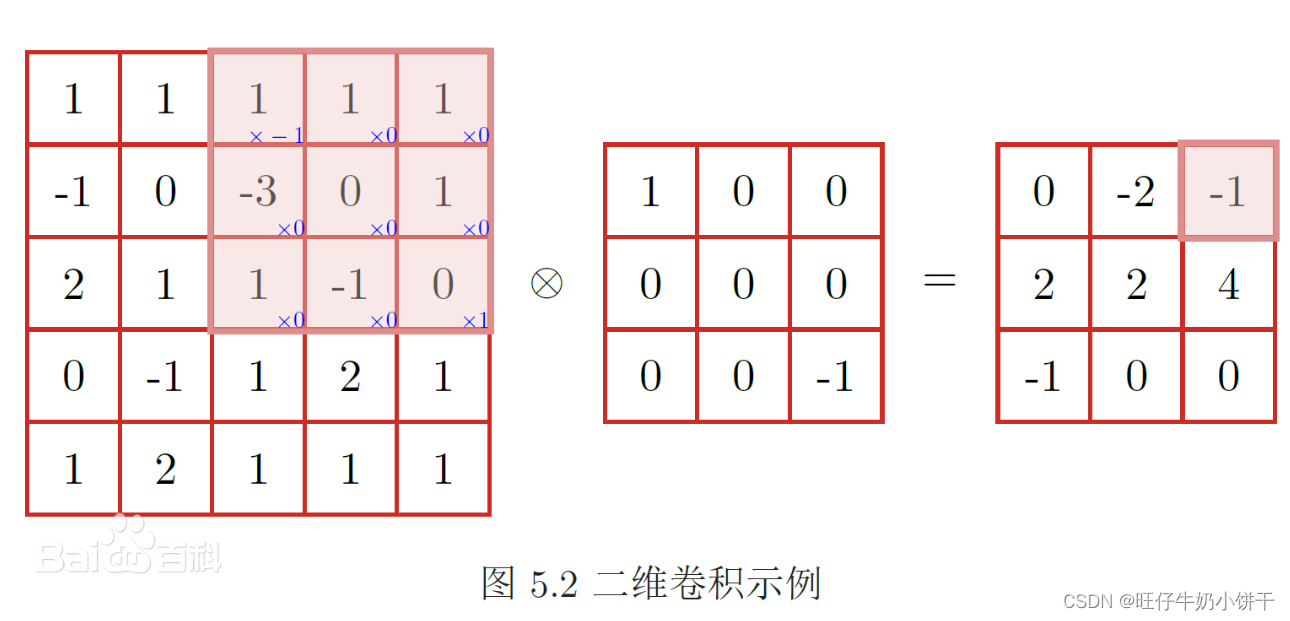
卷积核是会根据设定的步长进行移动,如stride=1则每次平移一位。计算方法就是每个网格元素与卷积核对应网格元素相乘再相加,所得的值作为新的矩阵中的元素。
卷积层中的基本参数
- 卷积核大小(Kernel Size ):定义了卷积核的感受野。
从底层优化角度来看,3*3的卷积核最优,但近来超大卷积核7*7,21*21也带来了不错的性能。另外,俩个3*3的卷积核效果相当于一个5*5的卷积核,且计算量与参数量均有减少---轻量化)
- 步长(stride):设置卷积核在卷积过程中移动的步长。
一般设置为1,代表每次滑动距离为1--这种方式能够覆盖所有相邻位置的特征,并将其进行组合。如果设置其他数值(>1)则相当于对特征组合进行下采样。
- 填充(padding):当卷积核尺寸与输入图像矩阵不匹配时需要进行一定的填充策略。
一般padding用于边界处位置,以保证卷积输出与输入的维度一致。
- 输入通道数(In Channels):指定卷积操作时卷积核的深度==卷积核的channel数。
默认为与输入特征矩阵通道数(深度)一致。
- 输出通道数(Out Channels):指定卷积核个数。
若设置与输入通道数一样,可以保证输入输出维度的一致性;若采用比输入通道更小的值,则能够减少网络整体的参数量。
- Out channel=卷积核个数=下一层卷积的in channel (池化层不改变channel)
(三)激活层(Activation Layer)
激活层主要由激活函数构成,即在卷积层输出的线性结果上加入非线性因子,让输出的特征图具有非线性关系,能够更好的拟合那些复杂的函数。
| 名称 | 图像 | 用途 | 缺点 |
| Sigmoid | 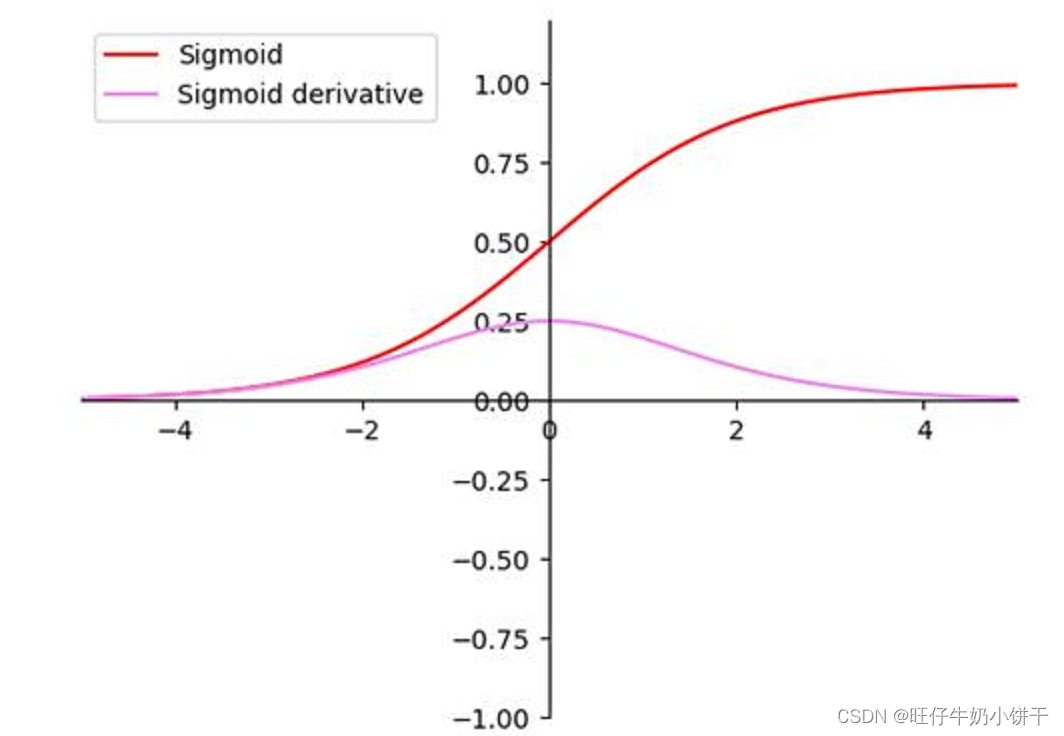 | 将输入映射(0,1)区间,用来做二分类。对于一个极大的负值输入,它输出的值接近于0;对于一个极大的正值输入,它输出的值接近于1。 | 反向传播时会存在梯度爆炸和梯度消失现象;且输出不是以0为中心,会降低学习效率。 |
| tanh | 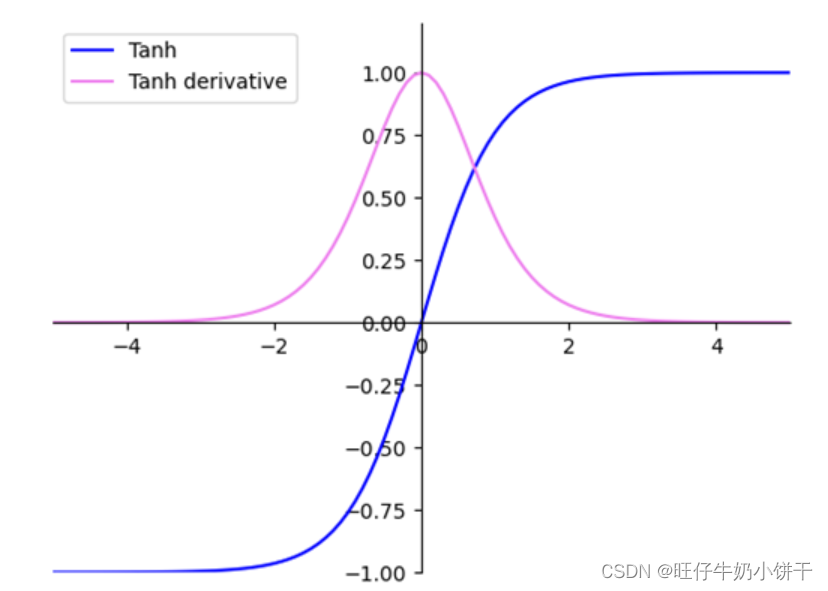 | tanh可以将输入映射到(-1,1)区间,解决Sigmoid不是以0为中心输出的问题 | 梯度消失问题和幂运算导致训练时间长 |
| ReLU | 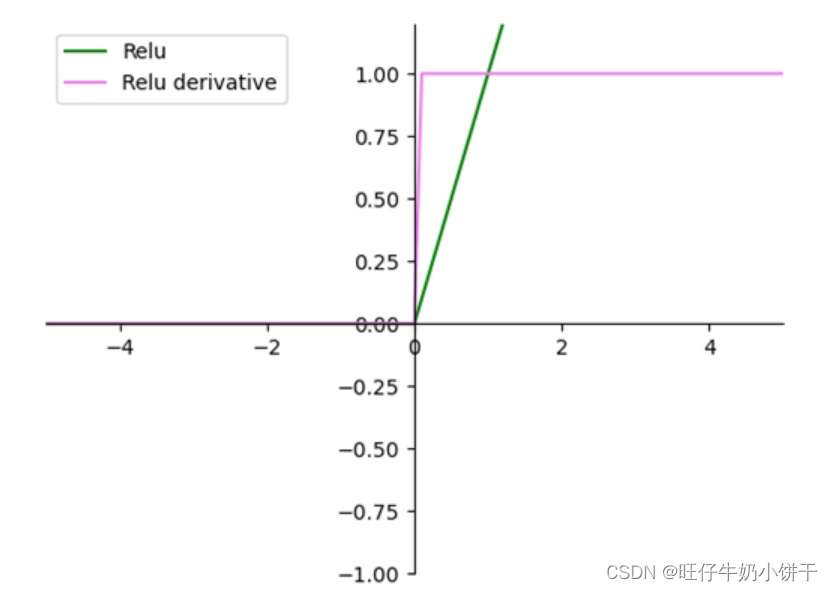 | ReLU将所有负值取作0,正值保持不变 | 解决梯度消失问题且收敛速度快。但输出不是以0为中心,且可能某些神经单元永远不会被激活,导致相应参数不能被更新 |
| Leaky ReLU | 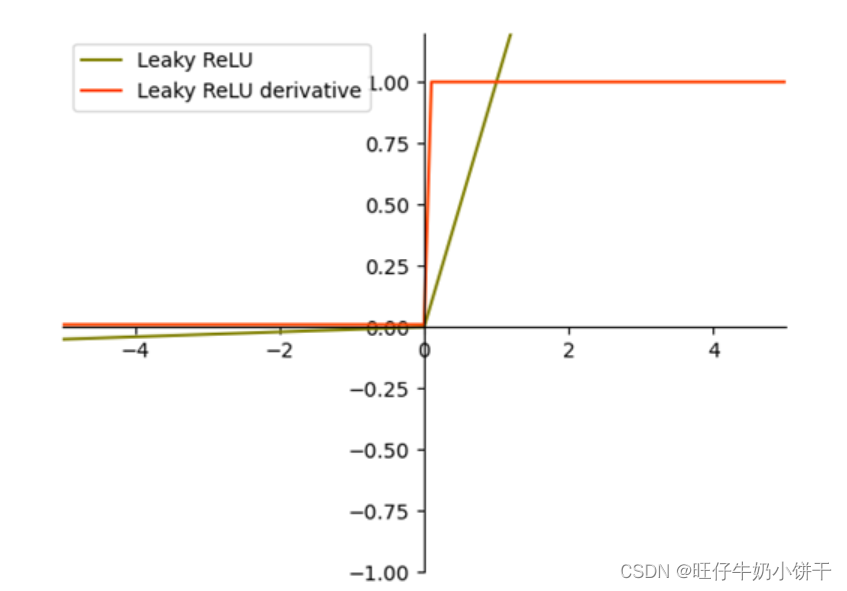 | Leaky ReLU与ReLU很相似,仅在输入小于0的部分,值为负,且有微小的梯度 | 解决ReLU无效神经元的部分,但效果不一定总是好于ReLU |
| SiLU | 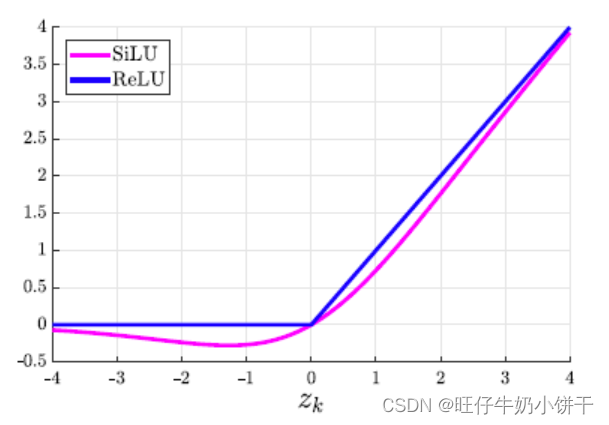 | 对于较大的值,SiLU 的激活大约等于ReLU的激活。 与 ReLU最大的不同,SiLU 的激活不是单调递增的。 | 优点:无上界,有下界,平滑 无上界:避免过拟合 有下届:正则化效果更强 平滑:处处可导,容易训练 |
| Mish |  | 在ImageNet上效果比ReLU和Swish都更好 | 优点:无上界、无下界、光滑、非单调(自身就有正则化效果,使函数更加平滑,更容易泛化)。 |
(四)池化层(Pooling Layer)
池化层又称下采样层(Downsampling Layer),在卷积层进行特征提取后,输出的特征图会被传递至池化层进行特征选择和信息过滤,用于对感受野内的特征进行筛选,提取区域中最具有代表性的特征。
常见的池化操作可分为最大池化(Max Pooling),平均池化(Average Pooling)和求和池化(Sum Pooling),其分别提取感受野内最大,平均与总和的特征值作为输出。(其中yolov5中SPPF模块里使用的就是最大池化)。
(五)全连接层(Full Connected Layer)
全连接层位于特征提取之后,将前一层所有神经元与当前层的每个神经元相连接, 对提取的特征进行非线性组合以得到输出。全连接层本身不被期望具有特征提取能力,而是试图利用现有的高阶特征完成学习目标。(所以说全连接层参数量也是最多的)
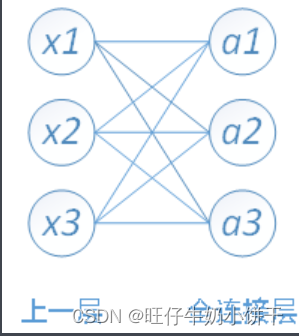
在一些卷积神经网络中,全连接层的功能可由全局均值池化(global average pooling)取代 ,全局均值池化会将特征图每个通道的所有值取平均,即若有7×7×256的特征图,全局均值池化将返回一个256的向量,其中每个元素都是7×7,步长为7,无填充的均值池化。
(六)输出层(Output Layer)
卷积神经网络中输出层的上游通常是全连接层,因此其结构和工作原理与传统前馈神经网络中的输出层相同。其输出形式面向具体任务。对于图像分类问题,输出层使用逻辑函数或归一化指数函数(softmax function)输出分类标签;在物体识别(object detection)问题中,输出层可设计为输出物体的中心坐标、大小和分类;在图像语义分割中,输出层直接输出每个像素的分类结果 。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











