






1.特殊token
[cls],[sep],[pas],[unk]
2.皮尔逊系数
利用metric矩阵获得评价指标
def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = predictions.reshape(len(predictions))
return {
'pearson': np.corrcoef(predictions, labels)[0][1]
}3.bert
Bidirectional Encoder Representations from Transformers
1)embedding
word embedding,sentence embedding,position embedding(和transformer不同)的原理:lookup table。O(1)的时间复杂度

先线性计算得到Q,K,V再分头对各自的Q,K,V进行计算,计算结果直接concat
2)feedforward
先降维后升维:768-->768*4-->768
3)warm up
一开始抑制后层参数的学习率,给前面参数一个缓冲优化的时间,以促进前后层的同步优化。
学习率缓慢爬升到一个较大的值,再开始下降,而不是传统的直接从一个较大的值开始下降。
4)notes
bert中15%的token被mask
在15%中有80%被替换为[mask]标记,10%的随机token和10%的原始token
当前token为[mask]时,根据上下文token的信息推断当前token
当前token为原始token即正常的单词,输出就直接照抄输入
填入 random token的目的是让模型时刻堤防,在任意 token 的位置都需要把当前 token 的信息和上下文推断出的信息相结合,判断当前token是否为原始token。
在做句子分类等任务时,输出[cls]的信息就行了
bert是双向编码器,[cls]肯定包含句子中的所有信息,在计算attention时自身和自身的关联性最大,但是[cls]没有实际意义,所以在输出时更加看重自身对结果没有影响。
4.Roberta
Robustly optimized BERT approach
更多的数据
动态mask
去除NSP任务
增大batch_size=8k
bytes_level BPE编码的tokenizer(5w+词库大小)
5.Albert
A Lite BERT
参数矩阵分解
在输入的embedding矩阵采用矩阵分解i降低参数量,bert模型隐藏层维度和attention维度是一样的H(768),实际上在刚开始进行embedding没有进行attetion时,每个token的embedding和上下文无关,attention之后才和上下文相关。
colab_size=V,隐藏层维度为E-->参数量为V*E+E*H,H>>E
比原来的V*H参数显著降低
跨层之间参数共享
全共享(attention层和全连接层都共享)是比单纯共享attention层的效果要差的,但是全共享d减少的参数实在太多了,所以作者采用的为全共享
base模型有12层,12层的参数共享
SOP
用sop代替nsp
nsp任务是主题预测,只要句子的主题预测即判断前后句子为在同一文档,难度太小
sop判断句子的语序,如果句子的顺序排列正确则视为匹配成功,如果句子顺序排列错误则代表匹配失败。
n-gram MASK
预测mask片段而不是单个wordpiece,每个片段的长度取值n(论文里取最大为3)。根据公式取1-gram、2-gram、3-gram的概率分别为6/11,3/11,2/11。越长概率越小。
6.ERINE
ERINE1.0
Enhanced Representation through Knowledge Integration
mask方式
mask有3层:单个分词,短语,实体
单个分词:written
短语:a series of
实体:J.K.Rowling
训练数据
增加了多轮对话的数据,即可以是QQR、QRQ等等。sentence emdedding-->dialogue embedding
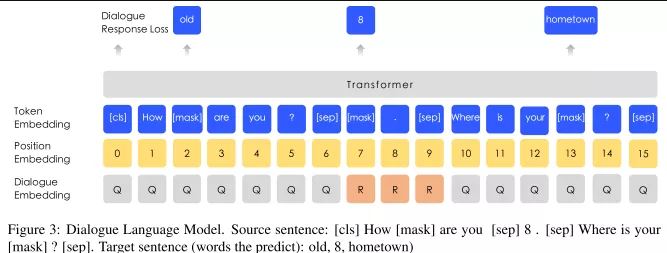
ERNIE2.0
A Continual Pre-training framework for Language Understanding
核心在于多任务学习和持续训练
多任务学习:
词汇:预测被mask的token,预测大小写,预测token和文本的关系
语法:把句子打乱识别正确顺序,分类句子之间的距离(0:相连,1:同一文档不相连,2:不同文档)
语义:计算相似度,提问和搜索返回的关系(0:有关且用户点击,1:有关用户未点击,2:无关)
持续训练(2个步骤)
构建无监督预训练任务
通过多任务学习增量地更新 ERNIE 模型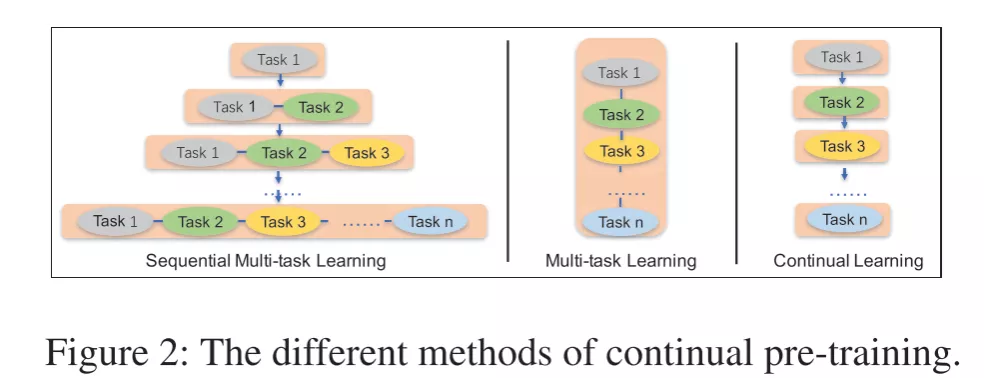
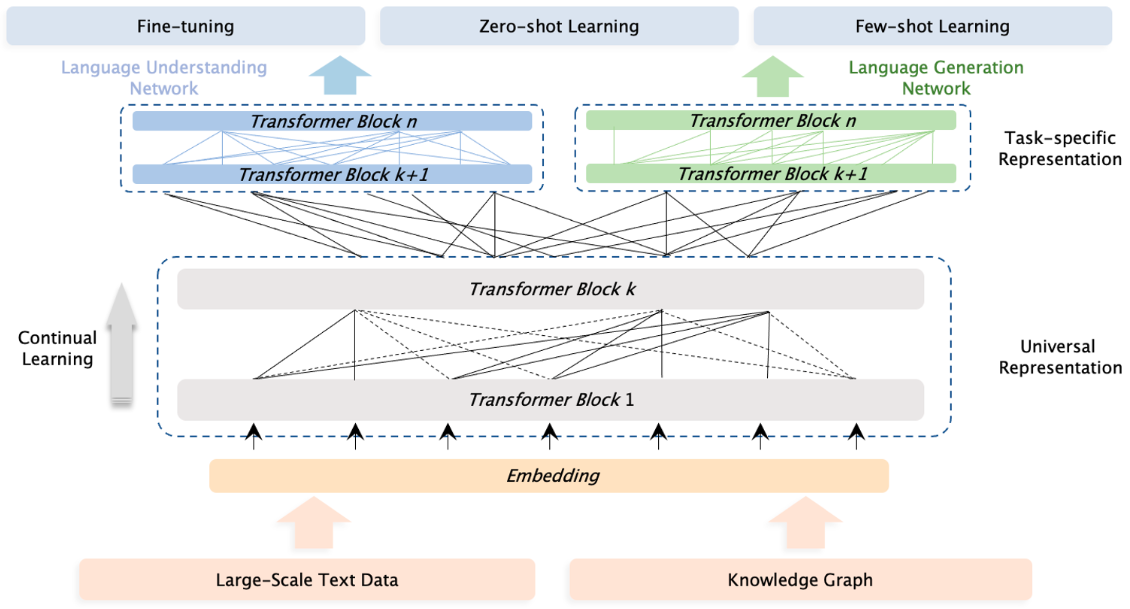
ERNIE3.0
Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
上下两层网络结构:
Universal Representation Module:捕获通用的基础特征
结构为多层Transformer-XL(Transformer-XL:transformer+rnn的思想)
需要注意的一点是,记忆循环机制只有在自然语言生成任务上会使用。
Task-specific Representation Module:适配不同下游任务(生成和理解),抽取不同的特征
根据不同的任务分为两种模型
自编码模型:用于自然语言理解问题,比如分类,实体识别,关系抽取
自回归模型:用于自然语言生成问题,比如对话
同样采用Transformer-XL的网络
三种级别的预训练任务
Word-aware Pre-training Task:对单个分词,短语,实体进行mask
Structure-aware Pre-training Tasks:打断句子顺序对句子进行排序(看作多分类任务,当打乱句子的个数为n时,分类数为n的阶乘个:n!),预测两个句子之间的距离(三分类任务,0:同一文章且相邻,1:同一文章不相邻,2:不同文章)
Knowledge-aware Pre-training Tasks:预测实体关系
【给定一个三元组<head, relation, tail>和一个句子,mask掉三元组中的实体关系relation(或者句子中的单词word),预测relation(或word)。
当预测实体关系的时,模型不仅需要考虑三元组中head和tail实体信息,同时也需要根据句子的上下文信息来决定head和tail的关系,从而帮助模型来理解知识。
当预测句子中的单词word时,模型不仅需要考虑句子中的上下文信息,同时还可以参考三元组<head, relation, tail>的实体关系。】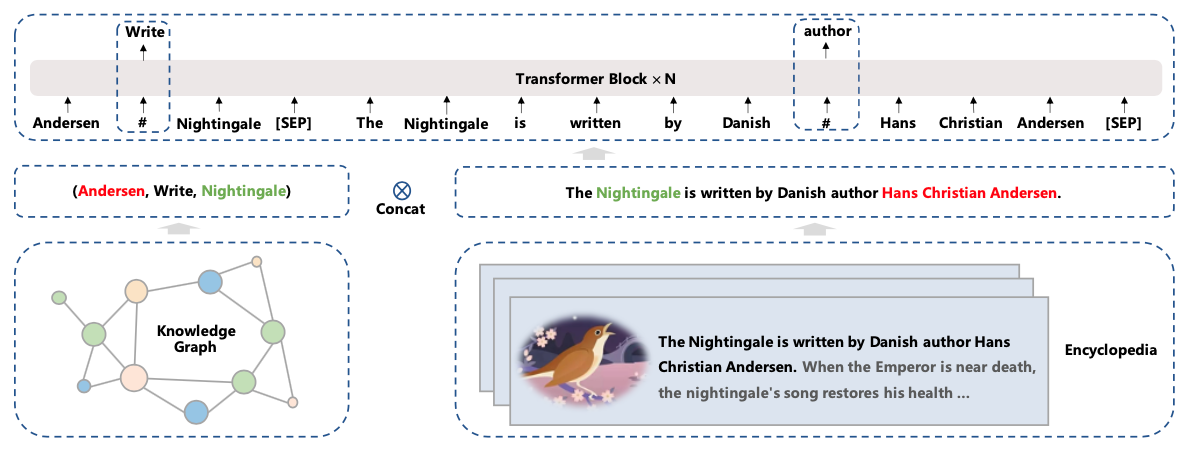
7.ELECTRA
Efficiently Learning an Encoder that Classifies Token Replacements Accurately
大体框架:三个步骤
mask:随机选择15%的token进行mask
【取消了bert的80%[MASK],10%unchange, 10%random replaced的操作,bert如此做是为了缓解预训练与微调时的不匹配,而在electra中没必要,因为electra在finetuning时使用的是其discriminator部分,所以不存在不匹配的现象】
生成mask掉的token:目标函数和bert一样,希望能够还原原本的token
判断生成的token是否正确:对每个token进行二分类,判断是否为原本的token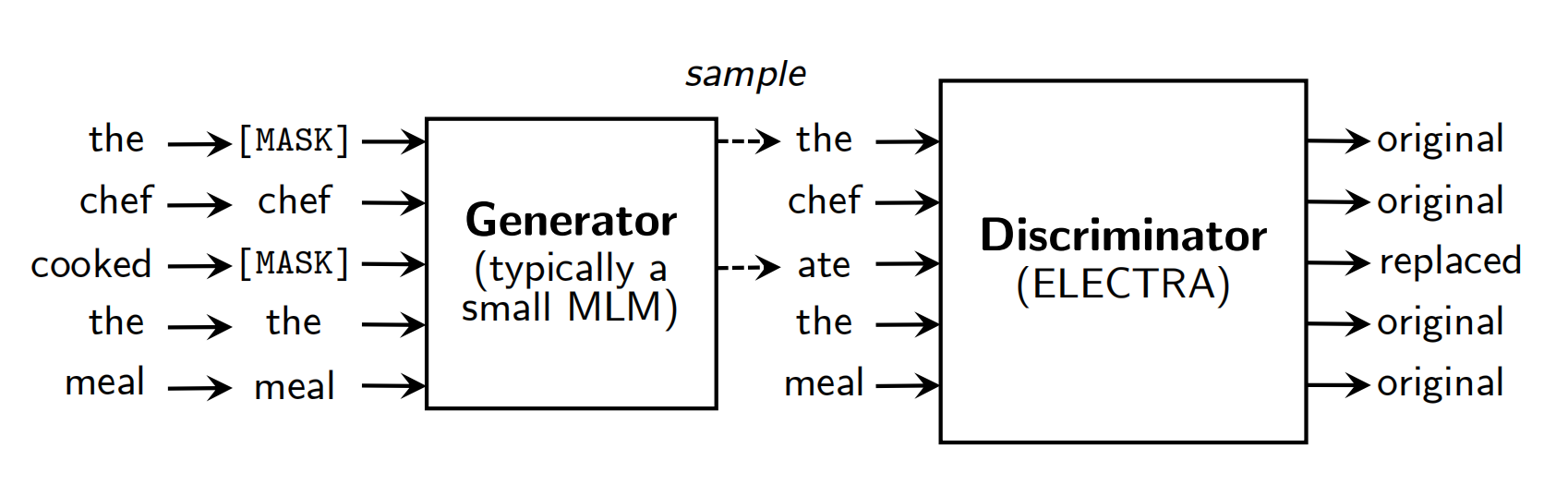
ELECTRA模型精讲-CSDN博客
NLP中的预训练语言模型(五)—— ELECTRA - 微笑sun - 博客园 (cnblogs.com)
权重共享
generator和discriminator之间存在weight共享,但是并不是所有的参数都共享,如果是这样的话,那需要两者的size一样,所以模型只共享了generator的embedding 权重。
为什么会选择共享embedding 权重呢,主要的原因是generator采用了MLM的方式训练,MLM根据token周围的context预测该token,可以很好地学习到embedding的表示。
生成器维度大小
模型在生成器大小为鉴别器大小的1/4-1/2时工作得最好。
生成器太厉害,判别器学习不到东西。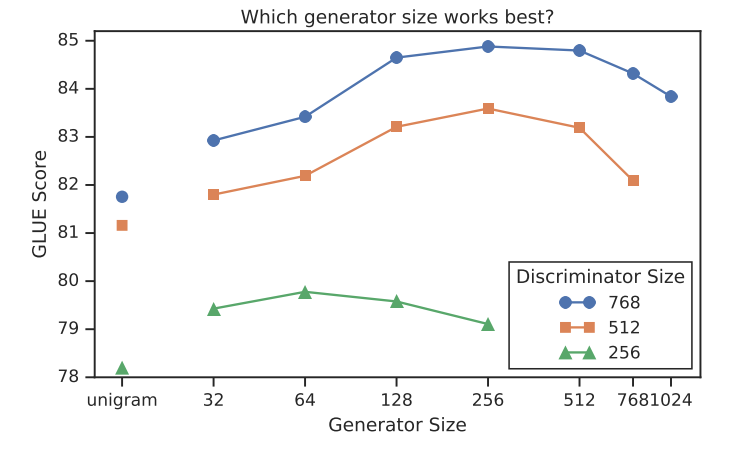
n.Deberta
背景:在attention矩阵中,对角线的值最大(即自己-自己的关联性最高),实际需求不光要关注本身还应关注本身的上下文。
与bert的区别:
结构侧:
在输入的input embedding不在加入position embedding
在input经过编码后
在encoder与enhance mask decoder端通过相对位置计算分散注意力
enhance mask decoder和transformer中的decoder没关系
在原始bert的倒数第二层,插入了一个分散注意力计算
训练侧:
训练时加入数据扰动
mask不替换词,替换成词的pos-embedding
debert用的是相对位置编码
m.参数选择
num_warmup_steps:一般设置在0.1-0.2(samples_num/batch_size)*epochs*num_warmup_steps
learning_rate:(base)(2-5)e-5 (large)小于等于2e-5(以0.5e-5为步长进行调整,调整时预训练语言模型越大,学习率应该越小)
seed:输入幸运数字















 1017
1017

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









