






 本文介绍了一种结合数组和链表的方法来优化内存使用,通过next数组代替链表中的next操作,用于单链表和双链表的插入、删除和遍历,减少new操作对时间的影响。
本文介绍了一种结合数组和链表的方法来优化内存使用,通过next数组代替链表中的next操作,用于单链表和双链表的插入、删除和遍历,减少new操作对时间的影响。
备注:本篇博客思路借鉴了acwing y总的链表处理思路
一、单链表
1、构建单链表
相信学过数据结构的同学,最初学习创建链表的时候都会这么写:
class Node {
public:
int data;
Node* next
};随后插入数据的时候直接new一个内存空间,即 Node *node = new Node(),再进行修改数据的操作等等。
插入操作:
void insert(int k) {
Node* p = node;
while (k--) p = p->next;
Node* n1 = new Node();
cin >> n1->data;
n1->next = p->next;
p->next = n1;
}但是这种方式的弊端也显现了出来,即new操作的时间很长,对于一些要打算法竞赛的同学来说,
如果一个题目涉及创建几千个几万个内存空间,使用成千上万个new操作会对时间是一个很大的挑
战,因此我们本篇博客采用数组和链表相结合的方式,优化运行时间。
2、数组链表相结合(这里我们先说单链表)
(1)创建next[]数组来顶替链表中的next操作
next数组里面存放的数据代表下一个结点是第几个插入的数。next数组下标表示第几个插入的数
据。下面用图来举例子
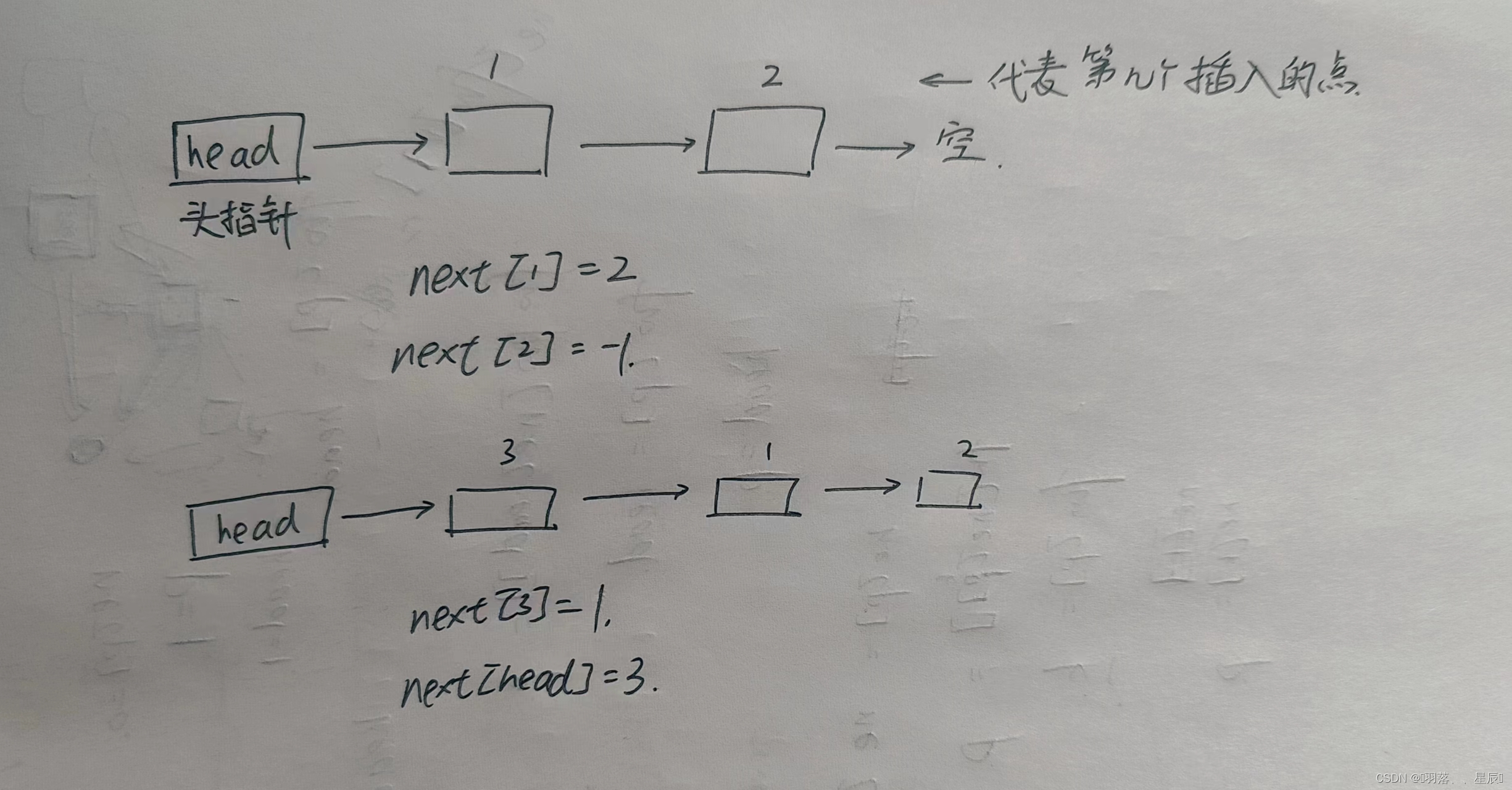
对于上面的第一个链表来说,第一个插入的结点的下一个是第二个插入的节点,因此next[1] = 2。
对于上面的第二个链表来说,第三个插入的数据插到了头结点和head指针中间,后面的结点
1是第一个插入的结点,因此next[3] = 1。
小疑点以及提示:有些小伙伴觉得,数组下标一般是0开始,那么第一个插入的数据是不是下标应该从0开始呢?
本人觉得,这样表示不是很直观,每当要查询第k个数据的时候还要进行减1操作,但是我们不能放着下标为0啥也不表示,因此我们把head结点下标当作0,我们把空结点当作下标为-1(即next[head] = -1,初始时候head指针指向空结点),遍历链表的话,当遍历到下标为-1的结点时退出循环。
注:下标为-1就退出循环,不会出现next[-1]的情况
(2)数据层面
原先链表采用类或结构体,里面涉及一个data变量。这里我们依旧采用数组,用一个数据数组来存储第几个插入的节点的数据值。
例如第二个插入的点里面存储了数据2,就是data[2] = 2。
(3)插入头结点操作详解
void insert_head() {
int x;
cin >> x;
// 插入操作的数据层面
dat[p] = x;
// 插入操作的指针层面
ne[p] = ne[head];
ne[head] = p;
p++;
}这里的p是一个全局变量,起一个索引的作用,函数执行时表示第几个插入的数据。
这里初始化了p = 1,意味着我们要插入第一个结点。
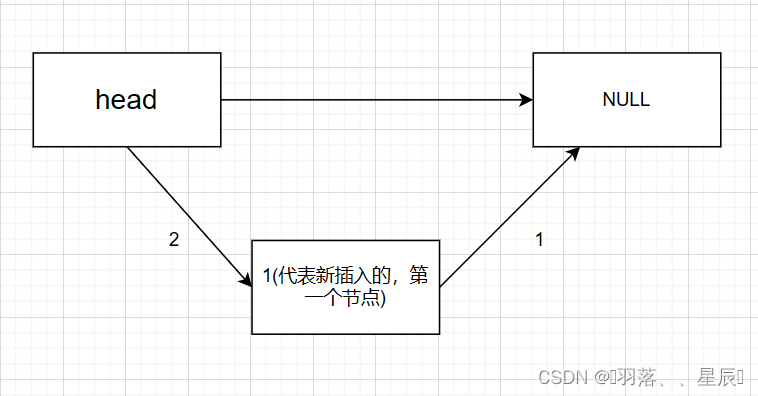
按照链表插入数据的思路,我们先让新插入的结点的next指向NULL(代码编写就是next[1] = -1)
再让next[head]重新赋值为p(p我们刚说表示第几个插入的数据),这也很好的诠释了next数组的意义:下标表示这是第几个插入的数据,数组保存的数值是下一个连接他的结点是第几个插入的数。
执行完毕后p++,表示之后再插入就是第二个插入的数据.
(3)关于链表遍历
这里遍历不再是刚开始学的链表那种 p = p->next。
我们这里采用next数组进行遍历,从head开始遍历。一直到下标为-1停止循环。
这里next数组充当了next指针作用,每一个数组里存放的数据都是下一个结点对应的第几个插入的数,而data数组里下标也表示第几个插入的数,因此用一个共有变量i,data[i]表示存的数据,ne[i]表示下一个数据是第几个插入的。
void show() {
cout << "数据" << " " << "第几个插入的数" << endl;
for (int i = ne[head]; i != -1; i = ne[i]) {
cout << dat[i] << " " << i << endl;
}
}(4)完整代码展示(插入操作和插入头结点操作相似)
# include <iostream>
using namespace std;
const int N = 100;
int head;
int dat[N], ne[N], p; // 分别表示,下标为N的点存的数据,下标为N的点下一个存储的空间的下标,p是游标.
void init() {
head = 0;
ne[head] = -1;
p = 1;
}
// 针对头节点的插入(插入到head和头节点之间)
void insert_head() {
int x;
cin >> x;
// 插入操作的数据层面
dat[p] = x;
// 插入操作的指针层面
ne[p] = ne[head];
ne[head] = p;
p++;
}
// 删除第k个插入的结点的后面一个结点
void del_k() {
// 第k个插入的数据
int k;
cin >> k;
if (ne[k] == -1) cout << "第" << k << " 个插入的数据后面没有数据" << endl;
else if (k == 0) {
head = ne[head];
}
else {
ne[k] = ne[ne[k]];
}
}
// 在第k个数据后面插入数据
void insert_k() {
cout << "选择你要插入的数据: ";
int x, k;
cin >> x;
cout << "选择第几个插入数据后面插入: ";
cin >> k;
dat[p] = x;
ne[p] = ne[k];
ne[k] = p;
p++;
}
void show() {
cout << "数据" << " " << "第几个插入的数" << endl;
for (int i = ne[head]; i != -1; i = ne[i]) {
cout << dat[i] << " " << i << endl;
}
}
二、双链表
1、构建双链表
双链表一大优势相比与单链表的话,就是可以找到上一个结点,这样一旦能找到上一个节点,就可
以执行在某个节点左边插入数据或者删除某个节点操作。
class Node {
public:
int data;
Node* next;
Node* prior;
};
Node* node;2、双链表的插入操作(插入到第k个数据后面)
void insert(int k) {
Node* p = node;
while (k--) p = p->next;
Node* n1 = new Node();
cin >> n1->data;
n1->next = p->next;
p->next->prior = n1;
n1->prior = p;
p->next = n1;
}3、利用数组优化这一过程
(1)构建以及插入头结点
双链表相比单链表多了一个front指针,因此我们在开一个front数组,存的便是上一个结点对应第几个插入的数据。下标表示本元素是第几个插入的数据。
int head, tail; // head的数据直接表示head头节点所指向的数据空间.
int dat[N], ne[N], fro[N], p; // 分别表示,下标为N的点村的数据,下标为N的点下一个存储的空间的下标,p是游标.
void init() {
tail = 90;
head = 0;
p = 1;
ne[head] = tail;
fro[head] = -99;
fro[tail] = head;
}
// 针对头节点的插入(插入到头节点后面一个)
void insert_head() {
int x;
cin >> x;
// 插入操作的数据层面
dat[p] = x;
// 插入操作的指针层面
ne[p] = ne[head];
fro[ne[head]] = p;
fro[p] = head;
ne[head] = p;
p++;
}这里设置了head以及tail,我们设定tail结点的下标为90,循环到90的时候退出。
(2)在第k个插入的数据后面再插入一个数
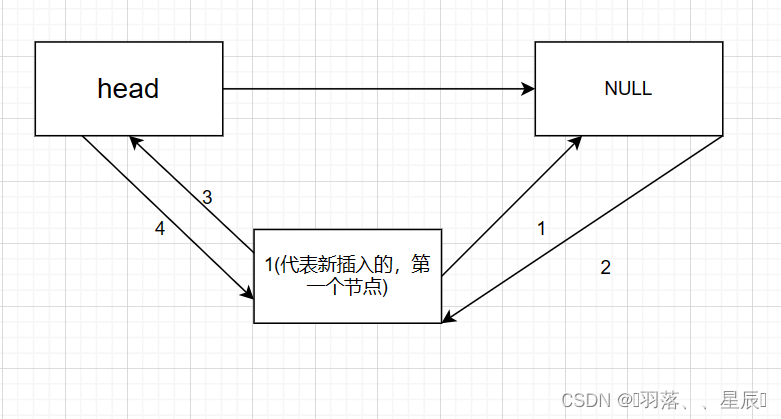
如上图所示,1234代表执行顺序,也可以2和3对调,先找到要插入的点的左右节点再把next和prior指针分别补充完毕。
插入代码展示:
// 在第k个数据后面插入数据
void insert_k() {
cout << "选择你要插入的数据: ";
int x, k;
cin >> x;
cout << "选择第几个插入数据后面插入: ";
cin >> k;
dat[p] = x;
ne[p] = ne[k];
fro[p] = k;
fro[ne[k]] = p;
ne[k] = p;
p++;
}(3)删除第k个插入的结点
删除思路和链表思路一样,找到要删除的结点,让该节点上一个结点的next指针指向要删除的结点
的下一个结点即可。这里删除不是释放该地址空间,而是遍历的时候跳过该点即可。
代码思路:
// 删除第k个插入的数据
void delK() {
int k;
cout << "输入你想删除第几个插入的数据: ";
cin >> k;
ne[fro[k]] = ne[k];
fro[ne[k]] = fro[k];
}














 1036
1036











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









