







目录
2 Google三驾马车 GFS MapReduce BigTable --1.18
6 元数据、Block、DataNode、NameNode、心跳
7 HA模式 HDFS高可用性(教材p36) --2.1.18
9 HDFS数据读写机制(重要)(教材p40) --2.1.22-25
3 主要的名词Resourcemanager,NodeManager,Container,Job,ApplicationMaster
5 一级调度RM,二级调度AM 基于hadoop 2.0的架构(MRv2)
5. 主从架构和双层调度范式,谁是一级调度,谁是二级调度(重要)主要在PPT上
一 绪论
1 大数据5v特点 --1.6
Volume(大量)、Velocity(高速)、Variety(多样)、Value(低密度价值)、Veracity(真实性)
2 Google三驾马车 GFS MapReduce BigTable --1.18
- GFS(分布式文件系统)
- MapReduce(超大集群的简单数据处理)
- BigTable(结构化数据的分布式存储系统)
3 Hadoop的特点 --1.23
- 扩容能力:可靠的存储和处理PB级数据
- 低成本:普通计算机组成集群来处理数据,可达上千个节点
- 高效率:节点上并行处理数据使得速度快
- 可靠性:自动维护数据的多份复制,任务失败后自动重新部署计算任务
4 Hadoop生态系统 (教材p6)
HDFS:分布式存储,数据存储功能
MapReduce:分布式计算框架
HBase:分布式数据库,基于HDFS的NOSQL数据库
Zookeeper:,分布式协调服务框架,hadoop组件管理端
Pig:数据流处理,对MapReduce的抽象
Hive:数据仓库,将结构化的数据文件映射为数据表,将SQL翻译为MapReduce语句进行查询
5、Hadoop的主要版本
p7 1.3.4 最新的3.*,出现了YARN的版本2.0
6 NoSQL有哪些
- 文档数据库(Document Databases):MongoDB、Couchbase和CouchDB。
- 列族数据库(Column Family Databases):HBase和Cassandra
- 键值对数据库(Key-Value Databases):Redis和Memcached
- 图数据库(Graph Databases):Neo4j和OrientDB
- 搜索引擎(Search Engines):Elasticsearch和Solr
7、Hadoop/HBase/Zookeeper属于什么开源项目?
Apache基金会
8、Hadoop的开发语言(Hadoop是用什么语言编写的)
Java
二 HDFS架构
1 三大基本组件 --2.1.2
Hadoop核心组件(教材p5)
HDFS:分布式文件系统,数据存储
YARN:统一资源管理和调度系统,支持多种框架
MapReduce:分布式计算框架,运行于YARN上
2 HDFS特性和局限性(教材p38) --2.1.4-5
特性:
能保存PB级数据量,数据散布在大量节点上,支持更大文件
可靠性、高容错性,多节点数据备份
与MapReduce集成,允许数据在本地计算,减少计算时数据交互
局限性:
不适合低延迟数据访问
不适合大量小文件存储
不支持多用户并发写入及任意修改文件,一次写入多次读取
不支持缓存,每次从硬盘重新读取
3 HDFS block
文件写入hdfs时会被切分为若干个数据块,并在集群中的多个节点上进行分布式存储。数据块的大小是固定的,默认为128MB。数据块是hdfs的最小存储单元。默认情况下,每个数据块有三个副本。
4 HDFS守护进程
- NameNode:它负责管理元数据,协调数据节点之间的数据块复制和数据块的位置管理。
- DataNode:它们分布在不同的节点上。DataNode负责实际存储数据块,并在NameNode的指导下执行数据块的复制、删除和传输操作。DataNode还负责向NameNode报告数据块的健康状况和存储容量等信息。
- Secondary NameNode:辅助NameNode完成某些耗时功能,解放NameNode性能,无法替代NameNode。
5 主从架构 --2.1.10
基本的名词:NameNode SecondaryNameNode DataNode各个节点的功能
基本的名词:数据划分为Block(大小、备份数量……)、元数据、client……
NameNode:主节点(Master),管理元数据
SecondaryNameNode:辅助NameNode完成某些功能,解放Name Node性能,无法替代NameNode
DataNode:从节点(Slave),存储文件的Block。
6 元数据、Block、DataNode、NameNode、心跳
元数据管理机制(教材p35) --2.1.11
元数据:存储文件路径、文件副本数量、文件块所处的服务器位置等。
元数据保存在NameNode中
内存元数据:meta data,元数据查询
硬盘元数据镜像文件:fsimage,持久化存储元数据
数据操作日志:edits,将更改记录进去,可以此运算出元数据
元数据管理过程:
系统启动,读取fsimage和edis至内存,形成内存元数据meta data, client向NameNode发起数据增删查请求,NameNode在接受请求后在内存元数据中执行操作,并返回结果给client,如果是增删操作,则同时记录数据操作日志edits。Secondary NameNode在合适的时间将操作日志合并到fsimage中
心跳机制(重要) --2.1.21
NameNode和DataNode的故障恢复(教材39)
NameNode故障恢复:
如果进行了高可用性配置,发生NameNode故障时,由zookeeper通过选举机制选取一个备用名称节点切换为激活状态,保证hadoop正常运行。
如果没有进行高可用性配置,系统把NameNode的核心文件同步复制到SecondaryNameNode(备份名称节点)中,当发生NameNode故障时,通过SecondaryNameNode中的FsImage和EditLog文件恢复NameNode。
DataNode故障恢复:
每个DataNode定期(默认3秒)向NameNode发送心跳信息,报告自己的状态。如果DataNode发生故障没有定时向NameNode发送心跳,就会被NameNode标记为“宕机”,该节点上所有数据不可读,NameNode不会向其发送任何I\O请求。
NameNode定期检查数据块的副本数量,小于冗余因子(即设定的副本数)时启动冗余复制,在其他正常数据节点生成副本。
心跳过程:数据节点主动发送请求及要报告的信息,名称节点被动回复需要传达的信息或指令。NameNode没有收到周期性send heartbeat,则认为该数据节点失效,将失效节点中的bolock重新备份到其他数据节点。
7 HA模式 HDFS高可用性(教材p36) --2.1.18
hadoop2.x中引用HDFS名称节点高可用框架。
配置两个相同的NameNode,一个为active mode活跃模式,另一个为standby mode待机模式,两个node数据保持一致,活动节点失效,则待机节点切换为活动节点,保证hadoop正常运行。
HA模式(高可用名节点)(High Availability NameNode),不需要再配置SecondaryNameNode,CheckPoint通过Standby NameNode实现。
JournalNode是轻量化节点,用于两个NameNode之间通信,需要配置3个以上节点。
8 DataNode容错机制
DataNode的故障管理由NameNode负责
DataNode故障将导致:
节点失去响应
本节点的block数据失效
如果NameNode不及时发现有故障的DataNode
1、会将client的请求频繁分配到故障节点中,降低系统效率,或导致client数据读取或操作失败
2、未能及时将DataNode中丢失的block重新备份,这时如果陆续有其他DataNode失效,将可能导致一部分block永久丢失
关键问题:NameNode如何发现故障DataNode
心跳机制
9 HDFS数据读写机制(重要)(教材p40) --2.1.22-25
写入机制:
用户客户端请求Hadoop客户端,执行文件上传,上传的文件写入hadoop客户端的临时目录,当文件写入数据量超过block(Hadoop1.x缺省64MB,2.x缺省128MB)大小时,请求NameNode申请数据块。NameNode返回数据块ID及存储数据块的DataNode地址列表,hadoop客户端根据地址列表向DataNode写入数据块。客户端写入一个数据块后,在DataNode之间异步进行数据块复制,最后一个DataNode上数据块写入完成后,发送一个确认信息给前一个DataNode,第一个DataNode返回确认信息给客户端,数据写入完毕。客户端向NameNode发送最终确认信息。
删除机制与此相同,删除请求到达后,文件不会立即被执行删除,而是移动到/trash目录(回收站),一段时间后再执行删除。
读取机制:
用户客户端请求Hadoop客户端,请求返回指定文件,hadoop客户端向NameNode发送读文件请求。NameNode查询meta data并返回文件数据对应的数据块ID及存储数据块的DataNode地址列表,该列表按照DataNode与客户端的距离进行排序。客户端在距离最近的数据节点上读取数据,如果读取失败,则从另一个副本所在数据节点读取数据。读取到所有block后合并成文件。
NameNode需要通过心跳机制收集DataNode生存状态,不会将失效的DataNode位置返回给客户端。
客户端:Client。代表用户通过与NameNode和DataNode交互来访问整个HDFS,整个HDFS运行在内网,与外界隔离,只有Client可以接受外界命令,确保系统安全。
10 Hadoop安装类型 --2.2.2
单机模式:Stand-Alone Mode
运行在一个单独的JVM中,便于开发调试
伪分布式集群模式:Pseudo-Distributed Cluster
各节点在不同的Java进程中,用于模拟集群环境
多节点集群安装模式:Multi-Node Cluster
各节点安装在不同的系统中,可用于生产的集群环境
11 常用的虚拟机
VMware:最大的虚拟机厂商,有自己的云(虚拟化)系统
Oracle Virtualbox:开源免费
Xen:开源免费
KVM:开源免费
Hyper-v:微软windows自带
Genymotion:Android系统虚拟机
12 安装大致的流程
创建多个虚拟机
配置SSH远程登录
(SSH免密配置原理:
通信加密类型:对称加密(DES、3DES、AES等,加解密使用相同密钥,速度块,适合大量数据加密,密钥可能泄露),非对称加密(RSA,加密使用公钥,解密使用私钥。速度慢,适合小数据加密。应用:数据使用AES加密,AES密钥使用RSA加密传送或保存,区块链、勒索病毒等使用此原理)
SSH默认密码验证:
配置RSA非对称加密验证,即免密访问。
原理:在主节点生成公/私钥对,将公钥传给其他节点)
安装配置JDK
安装配置hadoop
关闭防火墙
启动HDFS
13 常见的配置文件
Java和hadoop环境变量配置在/etc/profile,
配置完后source /etc/profile,让新的环境变量PATH生效
/etc/hosts : IP地址 主机名 表示映射关系
/etc/hostname : 主机名 当前主机的主机名
14 常见Linux命令:
cd、ls、mkdir、cat、jps等,vi编辑器的常用命令
常见错误:command not found,file or directory no exists
启动/停止Hadoop的命令 start-all.sh/stop-all.sh start-dfs.sh/start-yarn.sh
15 Hadoop常见配置文件
core-site.xml:NameNode的地址 hadoop数据的存储目录
文件系统相关配置 安全相关配置 Hadoop 配置目录和日志目录
hdfs-site.xml:nn web端访问地址(HDFS 的主节点 NameNode)
2nn web端访问地址(Secondary NameNode)
NameNode 和 DataNode 配置
容错和高可用性配置 块大小和副本数配置
数据传输和网络配置 HDFS 故障处理和恢复配置
yarn-site.xml:ResourceManager相关配置 NodeManager相关配置 容器资源配置
Workers:配置工作节点列表,资源,环境
NameNode运行在主节点(在core-site.xml中配置)
SecondaryNameNode可在主节点运行(在hdfs-site.xml中配置)
DataNode一般在从节点运行(在workers中配置)
16 HDFS守护进程、YARN守护进程
HDFS守护进程:
NameNode(主节点):负责管理文件系统的命名空间和元数据,存储文件系统的元数据信息。
Secondary NameNode(辅助名称节点):定期合并和检查NameNode的编辑日志,帮助恢复损坏的文件系统元数据。
DataNode(从节点):存储实际的数据块,负责数据的读取和写入操作。
YARN守护进程:
ResourceManager(资源管理器):负责集群作业和资源的管理和分配,接收应用程序的资源请求,并进行资源的调度。
NodeManager(节点管理器):在每个节点上运行,负责管理节点上的资源,接收来自ResourceManager的任务,并监控任务的执行状态。
ApplicationMaster(应用程序主管):每个运行在YARN上的应用程序都有一个ApplicationMaster,负责协调应用程序的执行,包括任务的分配和监控。
主节点守护进程:
NameNode(主节点)
ResourceManager(资源管理器)
从节点守护进程:
DataNode(从节点)
NodeManager(节点管理器)
17 HDFS命令
-ls -mkdir -get(-copyToLocal) -put(-copyFromLocal)
18 异常分析
无DataNode的情况下,能否 -ls?
可以,原因:目录结构存储在namenode中的,不需要访问datanode
There are 0 datanode(s) running and 0 node(s) are excluded in this operation.
(当前运行的datanode个数为0,不包含节点个数为0。)
能否-get/-put?
不能,原因,上传下载文件需要访问datanode
19 HDFS JavaAPI用途
fileSystem.copyFromLocalFile(本地路径,hdfs路径):从本地路径复制文件到hdfs
fileSystem.copyToLocalFile(hdfs路径,本地路径):从hdfs复制文件到本地路径
HDFS REST API
HDFS Java API是HDFS命令的抽象,支持远程访问HDFS
应用程序能够以和读写本地数据系统相同的方式从HDFS读取数据,或者将数据写入到HDFS
其他语言访问HDFS使用REST API
20 HDFS和YARN各守护进程的启动顺序
HDFS守护进程的启动顺序:
NameNode(主节点)
DataNode(从节点)
Secondary NameNode(辅助名称节点)
YARN守护进程的启动顺序:
ResourceManager(资源管理器)
NodeManager(节点管理器)
ApplicationMaster(应用程序主管)
13 HDFS命令(重要)
start-all.sh/stop-all.sh
1 hadoop fs -ls <path>
列出指定目录下的内容,支持pattern匹配。输出格式如filename(full path)<r n>size.n代表备份数。
2 hadoop fs -lsr <path>
递归列出该路径下所有子目录信息
3 hadoop fs -du<path>
显示目录中所有文件大小,或者指定一个文件时,显示此文件大小
4 hadoop fs -dus<path>
显示文件大小 相当于 linux的du -sb s代表显示只显示总计,列出最后的和 b代表显示文件大小时以byte为单位
5 hadoop fs -mv <src> <dst>
将目标文件移动到指定路径下,当src为多个文件,dst必须为目录
6 hadoop fs -cp <src> <dst>
拷贝文件到目标位置,src为多个文件时,dst必须是个目录
7 hadoop fs -rm [skipTrash] <src>
删除匹配pattern的指定文件
8 hadoop fs -rmr [skipTrash] <src>
递归删除文件目录及文件
9 hadoop fs -rmi [skipTrash] <src>
为了避免误删数据,加了一个确认
10 hadoop fs -put <> ... <dst>
从本地系统拷贝到dfs中
11 hadoop fs -copyFromLocal<localsrc>...<dst>
从本地系统拷贝到dfs中,与-put一样
12 hadoop fs -moveFromLocal <localsrc>...<dst>
从本地系统拷贝文件到dfs中,拷贝完删除源文件
13 hadoop fs -get [-ignoreCrc] [-crc] <src> <localdst>
从dfs中拷贝文件到本地系统,文件匹配pattern,若是多个文件,dst必须是个目录
14 hadoop fs -getmerge <src> <localdst>
从dfs中拷贝多个文件合并排序为一个文件到本地文件系统
15 hadoop fs -cat <src>
输出文件内容(文件输出到stdout)
hadoop fs -text <src>
输出文件内容(文件输出为文本格式)
16 hadoop fs -copyToLocal [-ignoreCre] [-crc] <src> <localdst>
与 -get一致
hadoop fs -moveToLocal
17 hadoop fs -mkdir <path>
在指定位置创建目录
18 hadoop fs -setrep [-R] [-w] <rep> <path/file>
设置文件的备份级别,-R标志控制是否递归设置子目录及文件
19 hadoop fs -chmod [-R] <MODE[,MODE]...|OCTALMODE>PATH
修改文件权限, -R递归修改 mode为a+r,g-w,+rwx ,octalmode为755
20 hadoop fs -chown [-R] [OWNER][:[GROUP]] PATH
递归修改文件所有者和组
21 hadoop fs -count[q] <path>
统计文件个数及占空间情况,输出表格列的含义分别为:DIR_COUNT.FILE_COUNT.CONTENT_SIZE.FILE_NAME,如果加-q 的话,还会列出QUOTA,REMAINING_QUOTA,REMAINING_SPACE_QUOTA
三 YARN
1 YARN是什么
统一资源管理和调度系统。将集群资源划分为多个容器(Containers),每个容器可以分配给一个应用程序进行计算。
2 YARN主从架构(守护进程)
主从节点Resourcemanager,NodeManager,也是其守护进程(教材74)
Master:ResourceManager,集群中各个节点的管理者。负责集群资源的管理和分配,接收应用程序的资源请求,并进行资源的调度。
Slave:NodeManager,集群中单个节点的代理。在每个节点上运行,负责管理节点上的资源,接收来自ResourceManager的任务,并监控任务的执行状态。
3 主要的名词Resourcemanager,NodeManager,Container,Job,ApplicationMaster
ResourceManager:接受Client请求,执行一级调度scheduler
NodeManager:执行作业任务job,执行二级调度ApplicationMaster
Container(容器):YARN的资源抽象,封装多维度资源。由Container提供资源给对应的任务。Application和ApplicationMaster均需要计算资源,均运行在Container中,用户提交的job以Application的方式执行。
ApplicationsManager:运行在ResourceManager中,管理YARN中所有的ApplicationMaster
ApplicationMaster:管理一个application,运行在NodeManager的Container中,每个Application由一个ApplicationMaster负责管理,接收Container的进度汇报,为Container请求资源,ApplicatioinMaster通过心跳向ResourceManager汇报Application进度和资源状态。
Job(作业):用户提交至YARN的一次计算任务,由Client提交至ResourceManager。MapReduce中每个作业对应一个Application,Spark中作业的每个工作流对应一个Application,效率更高,Apache Slider中多用户共享一个长期Application,系统响应更快。
4 Yarn调度器(三种)
FIFO Scheduler (先进先出调度器)
Capacity Scheduler (容器调度器)
Fair Scheduler (公平调度器)
5 一级调度RM,二级调度AM 基于hadoop 2.0的架构(MRv2)
一级调度:ResourceManager接收作业,在指定NodeManager节点上启动ApplicationMaster,在scheduler中执行调度算法为ApplicationMaster分配资源,管理各个AM。
二级调度:ApplicationMaster运行在NodeManager上,向ResourceManager请求资源,接受RM的资源分配后在NM上启动Container,在Container中执行Application,并监控Application执行状态。
6 YARN的工作流程(教材75-76) --3.13
Client向ResourceManager提交作业a(Job)
1 ResourceManager在调度器(scheduler)中创建一个AppAttempt用于管理作业a的调度。
NodeManager1向ResourceManager提交心跳,ResourceManager通过ApplicationsManager将作业a的ApplicationMaster分配到NodeManager1。
ResourceManager通过RPC调用NodeManager1中的startContainer方法,在NodeManager1中为作业a启动Container0(作业的0号容器)
NodeManager1在Container0中为作业a启动ApplicationMaster
ApplicationMaster向ApplicationsManager发送请求注册并初始化自身,计算自身所需资源,并向RM发起资源请求
ResourceManager将ApplicationMaster的资源请求放入scheduler资源队列中,由scheduler分配资源,获得资源后向指定的NodeManager分配相应的Container,等下一次心跳
ApplicationMaster向ResourceManager发送心跳
ResourceManager返回ApplicationsManager分配好的Container
ApplicationMaster向对应的NodeManager发起RPC调用,启动分配的Container.
(一个ApplicationMatser对应一个Application,根据任务情况可拥有多个Container)
Container启动后,用于执行用户的作业Application,并向ApplicationMaster汇报进度,ApplicationMaster负责整个Application中的Container的生命周期管理。
ApplicationMaster为Container向ResourceManager请求资源。
作业执行完毕,ApplicationMaster向ResourceManager申请注销资源。
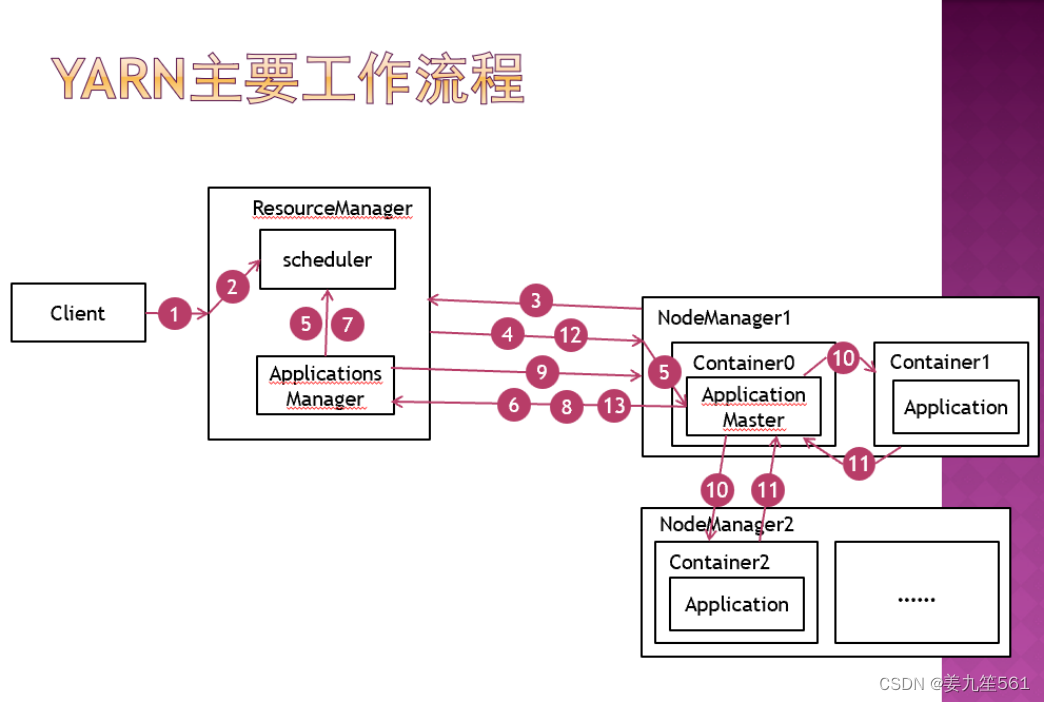
5. 主从架构和双层调度范式,谁是一级调度,谁是二级调度(重要)主要在PPT上
ResourceManager作为一级调度,将资源分配给二级调度ApplicationMaster
ResourceManager通过Scheduler(调度器)执行一级调度
调度器—》Container的分配信息—》ApplicationMasterà执行Container的创建—》Application














 813
813











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









