




gridsearchcv:
sklearn.model_selection.GridSearchCV
(1)参数
GridSearchCV(estimator, param_grid, scoring=None, fit_params=None, n_jobs=1, iid=True, refit=True, cv=None, verbose=0, pre_dispatch='2*n_jobs', error_score='raise', return_train_score=True)
estimator:所使用的分类器,或者pipeline
param_grid:值为字典或者列表,即需要最优化的参数的取值
scoring:准确度评价标准,默认None,这时需要使用score函数;或者如scoring='roc_auc',根据所选模型不同,评价准则不同。字符串(函数名),或是可调用对象,需要其函数签名形如:scorer(estimator, X, y);如果是None,则使用estimator的误差估计函数。scoring 参数可以设置为什么可以参考这篇博文:https://blog.csdn.net/qq_41076797/article/details/102755893
20221125添加:
多scoring设置:
ps:【学习sklearn.metrics.make_scorer详解】
mae=make_scorer(mean_squared_error,greater_is_better=False)
r2=make_scorer(r2_score,greater_is_better=True)
sc={"mae":mae."r2":r2}
model=gridsearchcv(estimator,x,y,scoring=sc)
但是这样需要设置refit=False,会导致best_param等的无法使用,得不偿失,最好还是使用一个score用于gridsearchcv

补充:多scoring的代码
refit参数:在多指标设置中,需要对此进行设置,以便最终模型可以与之匹配,因为模型的最佳超参数将仅基于单个指标来决定。如果不想要最终模型,并且只想要模型在数据和不同参数上的性能,则可以将其设置为
False,也可以将其设置为评分字典中的任何key。
n_jobs:并行数,int:个数,-1:跟CPU核数一致, 1:默认值。
pre_dispatch:指定总共分发的并行任务数。当n_jobs大于1时,数据将在每个运行点进行复制,这可能导致OOM,而设置pre_dispatch参数,则可以预先划分总共的job数量,使数据最多被复制pre_dispatch次
iid:默认True,为True时,默认为各个样本fold概率分布一致,误差估计为所有样本之和,而非各个fold的平均。
cv:交叉验证参数,默认None,使用三折交叉验证。指定fold数量,默认为3,也可以是yield训练/测试数据的生成器。
refit:默认为True,程序将会以交叉验证训练集得到的最佳参数,重新对所有可用的训练集与开发集进行,作为最终用于性能评估的最佳模型参数。即在搜索参数结束后,用最佳参数结果再次fit一遍全部数据集。
verbose:日志冗长度,int:冗长度,0:不输出训练过程,1:偶尔输出,>1:对每个子模型都输出。
(2)输出
best_estimator_:效果最好的分类器
best_score_:成员提供优化过程期间观察到的最好的评分
best_params_:描述了已取得最佳结果的参数的组合
cv_results_ : dict of numpy (masked) ndarrays:
具有键作为列标题和值作为列的dict,可以导入到DataFrame中。注意,“params”键用于存储所有参数候选项的参数设置列表。
best_index_:具体用法模型不同参数下交叉验证的结果。对应于最佳候选参数设置的索引(cv_results_数组的索引)。
best_index_ : int 对应于最佳候选参数设置的索引(cv_results_数组)
search.cv_results _ ['params'] [search.best_index_]中的dict给出了最佳模型的参数设置,给出了最高的平均分数(search.best_score_)
(3)示例:
fromsklearn.model_selectionimportGridSearchCV
param_grid=[
{'n_estimators': [3,10,30],'max_features': [2,4,6,8]},
{'bootstrap': [False],'n_estimators': [3,10],'max_features': [2,3,4]},
]
forest_reg=RandomForestRegressor()
grid_search =GridSearchCV(forest_reg,param_grid,cv=5,scoring='neg_mean_squared_error')
grid_search.fit(housing_prepared, housing_labels)<br>(grid_search.best_params_)
(4)cv_results_ 参数有:
【学习参考】:machine-learning - rank_test_score 在model.cv_results_ 中代表什么? - IT工具网 (coder.work)
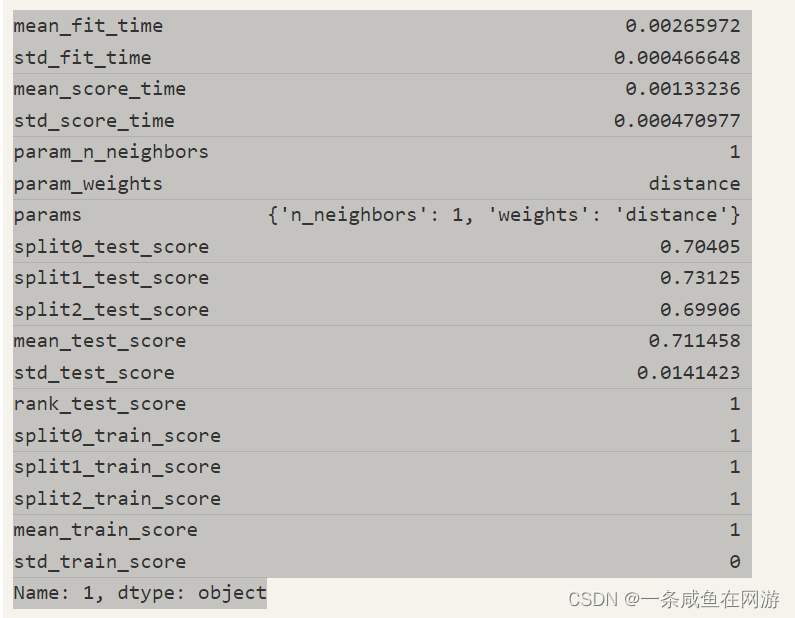
rank_test_score表示基于mean_test_score的网格搜索参数组合的排名.
如果您在网格搜索中尝试 N 个参数组合,rank_test_score从 1 到 N。
导致最低mean_test_score的参数组合会有rank_test_scoreN 和最高的参数组合mean_test_score会有rank_test_score1.
如果您使用 multiple metrics for evaluation (比如,'neg_mean_squared_error' 和 'neg_mean_absolute_error')你会有更多的列(这里是rank_test_neg_mean_squared_error和rank_test_neg_mean_absolute_error),每一个都表示基于各自度量的估计器的等级。
cv_results_可以转为dataframe模式:
result=pd.dataframe(model.cv_results_).set_index([' '])

















 3587
3587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









