






降水数据是我们在各项研究中最常用的气象指标之一!之前我们给大家分享了来自国家青藏高原科学数据中心发布的1961—2022年全国范围的逐日降水栅格数据!(可查看之前的文章获悉详情)!
本次我们分享的是我国1961——2022年的省市县三级的逐日降水量数据,数据包括excel和shp两种数据格式,数据单位为毫米,数据坐标为WGS1984!该数据是基于上面提到的1961—2022年全国范围的逐日降水栅格数据(0.1°分辨率),依据行政边界数据(包括全国省份行政边界、地级市行政边界、区县行政边界),合计行政边界内每日降水量的平均值得到的。
以下为数据的详细信息:
01 数据预览
①省份层级的逐日降水数据
首先,我们先来看看省份层级的逐日降水数据,数据包括excel和shp两种格式!
需要说明的是:由于是逐日数据,一年有365天,而年份又包括1961-2022年这62年,数据量太大,没法保存到一个excel或shp里面因此,每年的数据保存为一个excel和shp里面,地级市和区县同理!
我们先以2022年1月1号——1月10号为例,来预览一下省份层级excel格式的逐日降水数据:
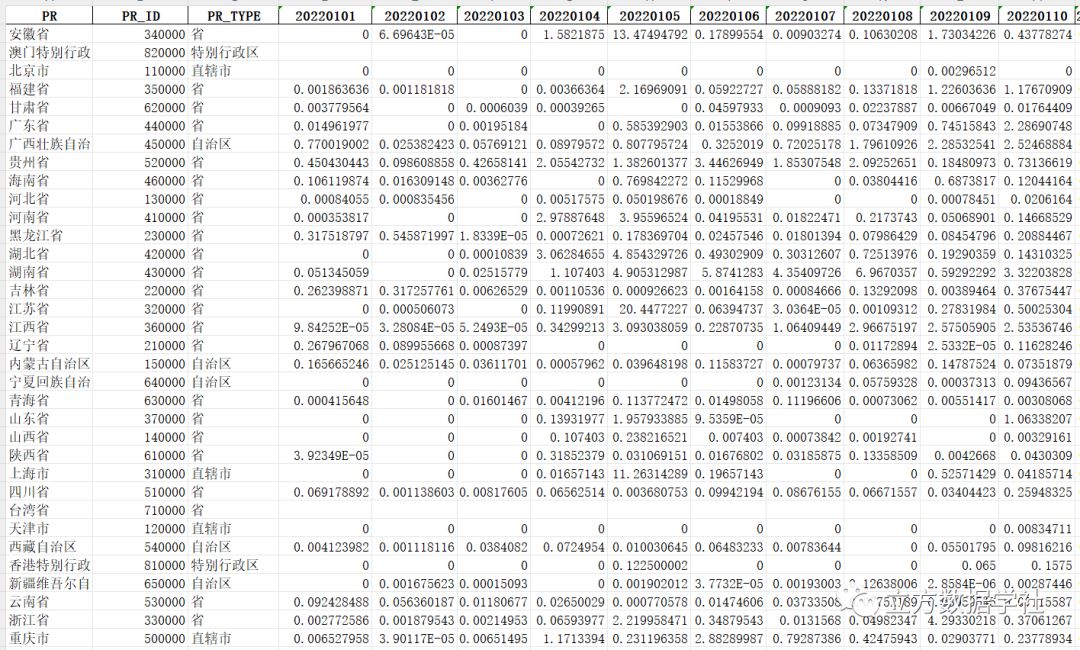
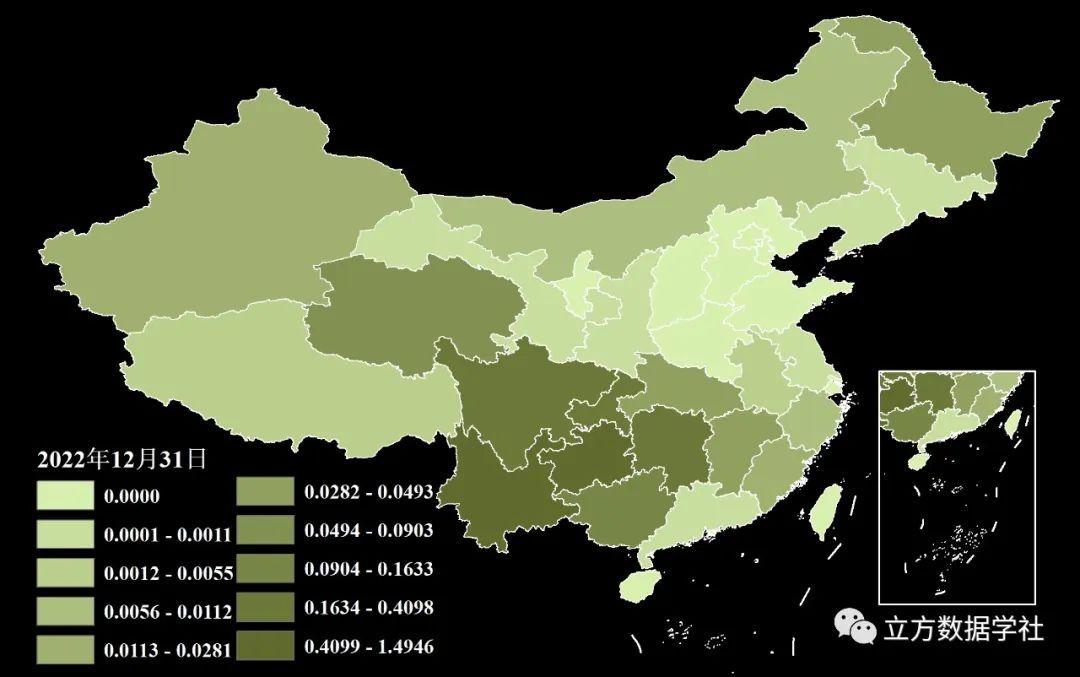
下面我们再以2022年12月31号的数据为例,来预览一下省份层级shp格式的逐日降水数据:
②地级市层级的逐日降水数据
下面我们来看看地级市层级的逐日降水数据,数据包括excel和shp两种格式!
我们先以2022年1月1号——1月10号为例,来预览一下地级市层级excel格式的逐日降水数据:
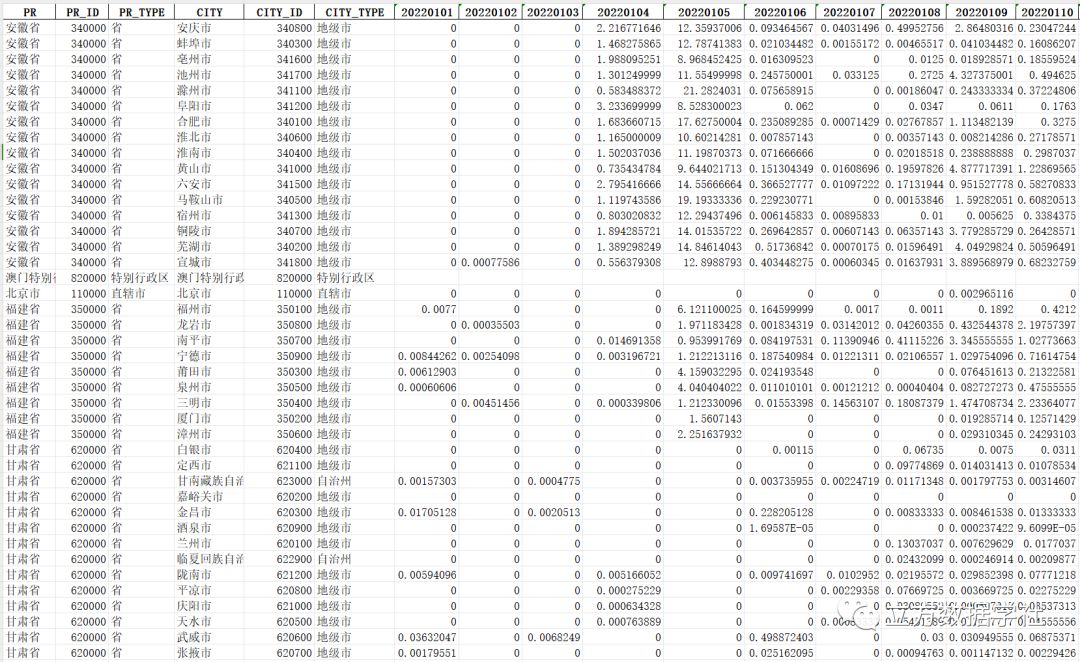
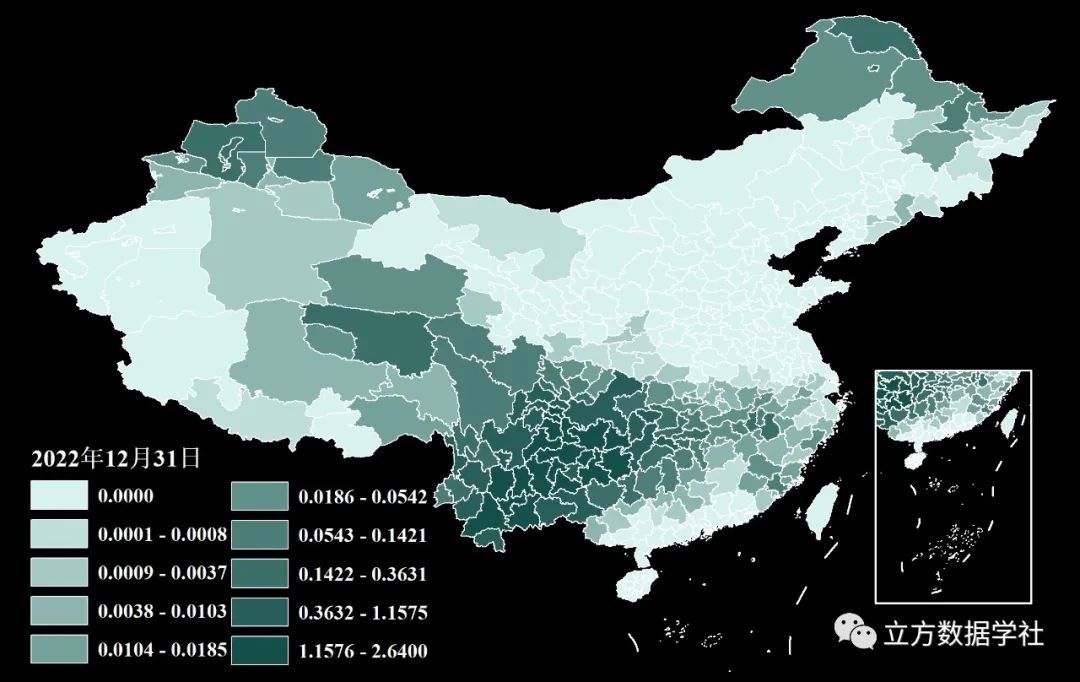
下面我们再以2022年12月31号的数据为例,来预览一下地级市层级shp格式的逐日降水数据:
③区县层级的逐日降水数据
下面我们来看看区县层级的逐日降水数据,数据包括excel和shp两种格式!
我们先以2022年1月1号——1月10号为例,来预览一下区县层级excel格式的逐日降水数据:
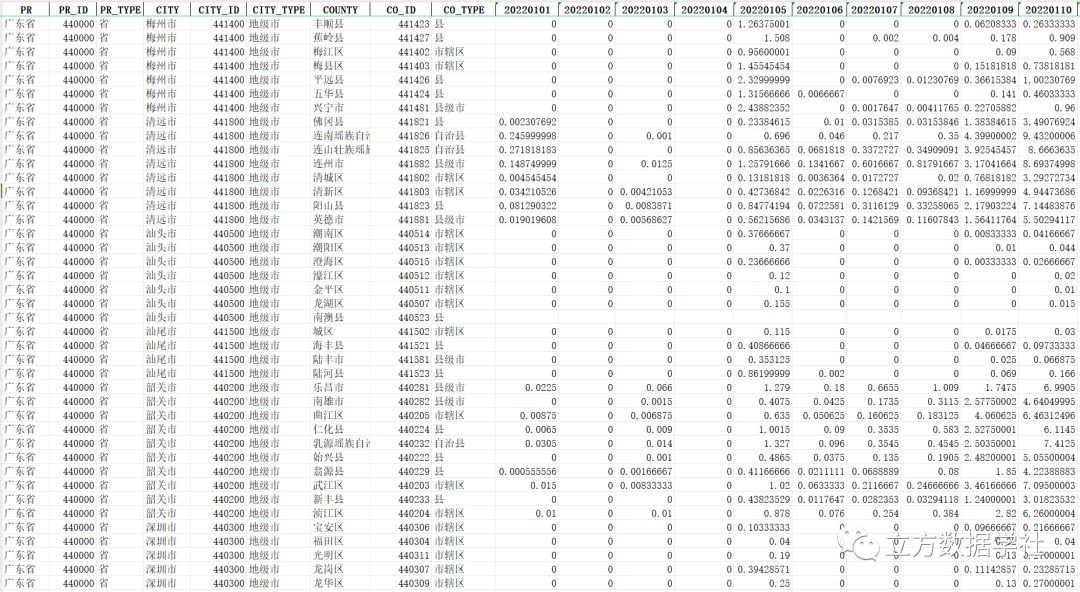
下面我们再以2022年12月31号的数据为例,来预览一下区县层级shp格式的逐日降水数据:
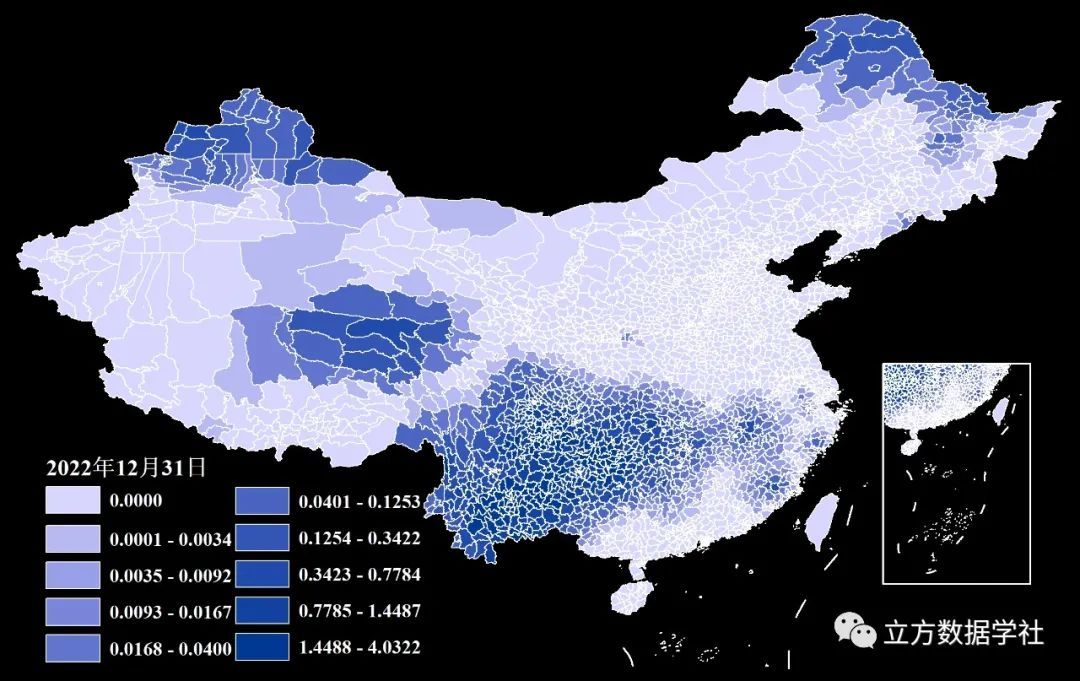
02 数据详情
数据来源:
原始数据来源于国家青藏高原科学数据中心发布的1961—2022年全国范围的逐日降水栅格数据!关于原始数据的介绍戳我跳转。
数据处理说明:
基于上述原始数据,我们采用从‘数读城事’公众号获取的省市县三级的行政区划shp数据,分别汇总各个省份(地级市和区县同理)内所有栅格日降水量的平均值得到每个省份(地级市和区县同理)的日降水量数据。
数据格式:
xlsx和shp格式
数据单位:
毫米(mm)
时间范围:
1961-2022年(逐日)
数据坐标:
GCS_WGS_1984
空间范围:
全国省市县三级
数据缺失:
该数据缺少我国港澳台的数据
数据的引用:
缪驰远, 韩静雅, 苟娇娇. (2023). 中国逐日降水数据集(1961-2022,0.1°/0.25°/0.5°). 国家青藏高原科学数据中心.
https://doi.org/10.11888/Atmos.tpdc.300523. https://cstr.cn/18406.11.Atmos.tpdc.300523. 如有数据使用需求请严格按照官方平台的要求进行引用,更多数据详情和引用要求可以查看官网获悉!
文末下方是我们的公众号名片,我们将定期介绍各类城市数据以及数据的可视化和分析技术,有关1961—2022年我国省市县三级的逐日降水量数据,欢迎大家多多关注我们进行了解!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









