






土地覆盖数据是我们在各项研究中经常使用的数据,土地覆盖数据可以帮助我们确定哪儿是建设用地,哪儿是水域,哪儿是农田等!土地覆盖数据的来源有多种,我们之前分享过多种来源的土地覆盖数据,包括1米分辨率土地覆盖数据,World Cover数据集的2021年的10米土地覆盖数据和Esri 的2017-2023年10米土地覆盖数据(可查看之前的文章获悉详情)。
这些来源的土地覆盖数据虽然精度不错,但是数据年份普遍较短,本次我们分享一个长时序的用地覆盖数据!该数据是武汉大学的杨杰和黄昕教授发布的1985年——2023年的中国30米分辨率的逐年土地覆盖数据!数据格式为栅格数据(.tif格式)。该数据持续更新,8月份刚刚更新了2023年的数据。另外,需要说明的是该数据的具体年份为:1990—2023年,另外提供了1985的数据,1986—1989年这四年的数据缺失!
杨杰和黄昕教授使用谷歌地球引擎上的335,709 张 Landsat 图像,在谷歌地球引擎(GEE)平台上制作了第一个源自Landsat的中国年度土地覆盖数据集annual land cover(CLDC)。该数据包括9种用地类型,分别为:农田、森林、灌木、草原、水域、冰雪、裸地、不透水面、湿地。
原始数据包括全国数据和分省(34个省级行政区)数据,为方便大家使用,我们进一步裁剪出分市的数据(371个地级市),数据量约100G,一起提供给大家方便大家使用!如下图:

另外,可能有些同学不知道如何对该用地数据进行可视化。我们做好了该数据的可视化样式提供给大家,大家只需要按照下文中的教程可视化即可!
大家可以自己按照我们下文的数据下载方式自己下载!也可以在公众号回复关键词 322 按照转发要求获取我们下载好并处理过的数据!以下为数据的详细介绍:
01 数据预览
我们先来看一下全国范围的数据,以2023年为例来预览一下:

我们再来看一下分省的数据,以2023年湖北省为例来预览一下:
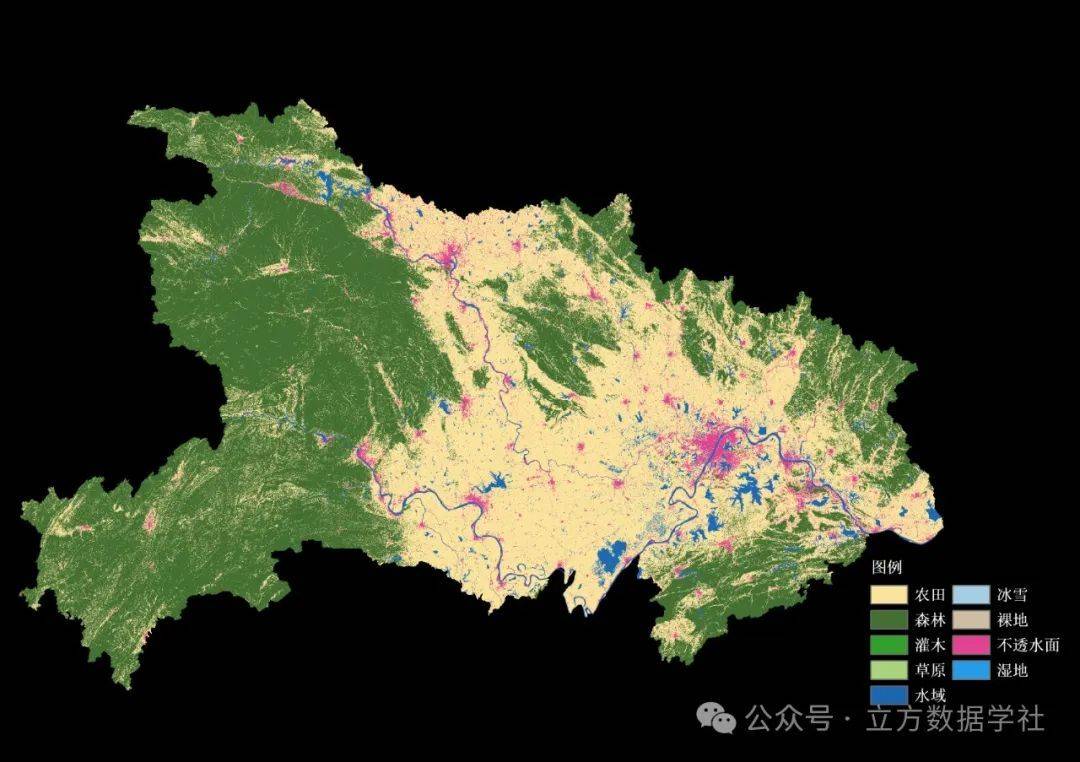
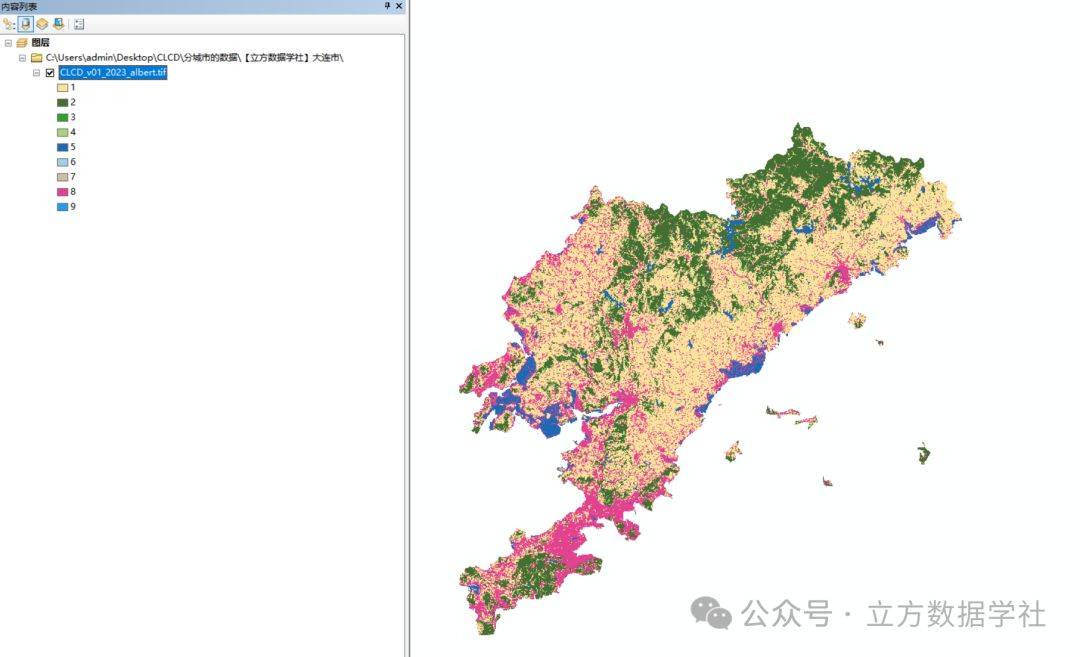
接下来我们再来看一下分市的数据,以2023年武汉市为例来预览一下:
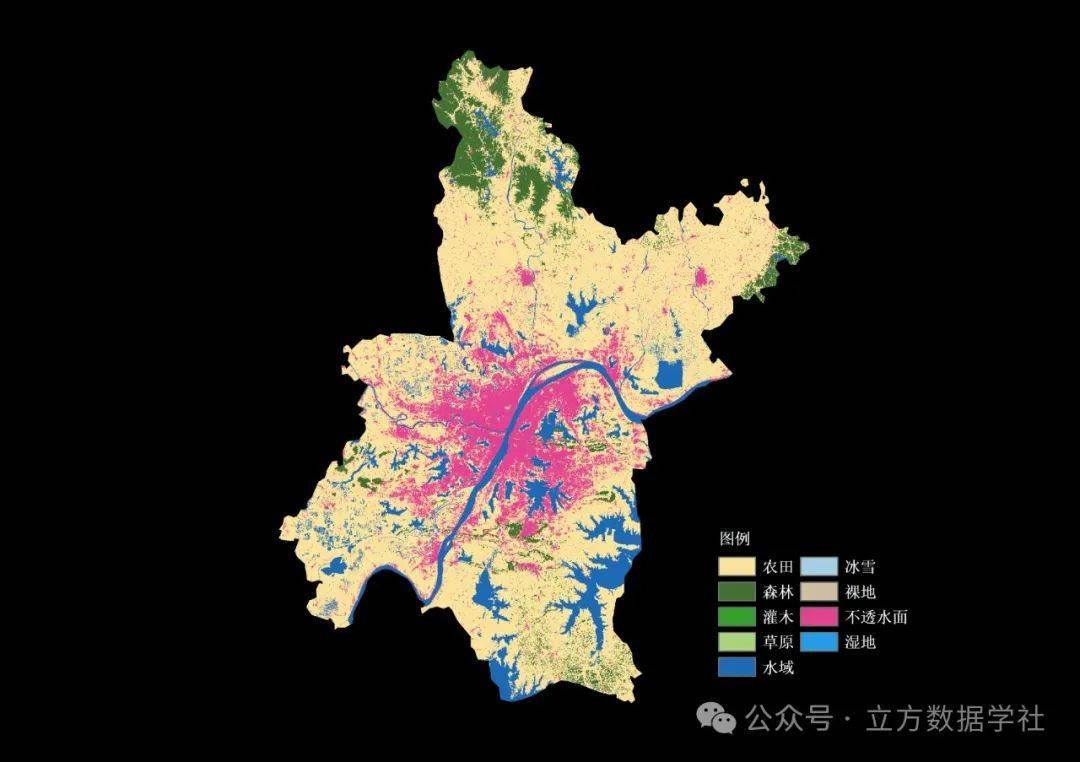
02 数据可视化教程
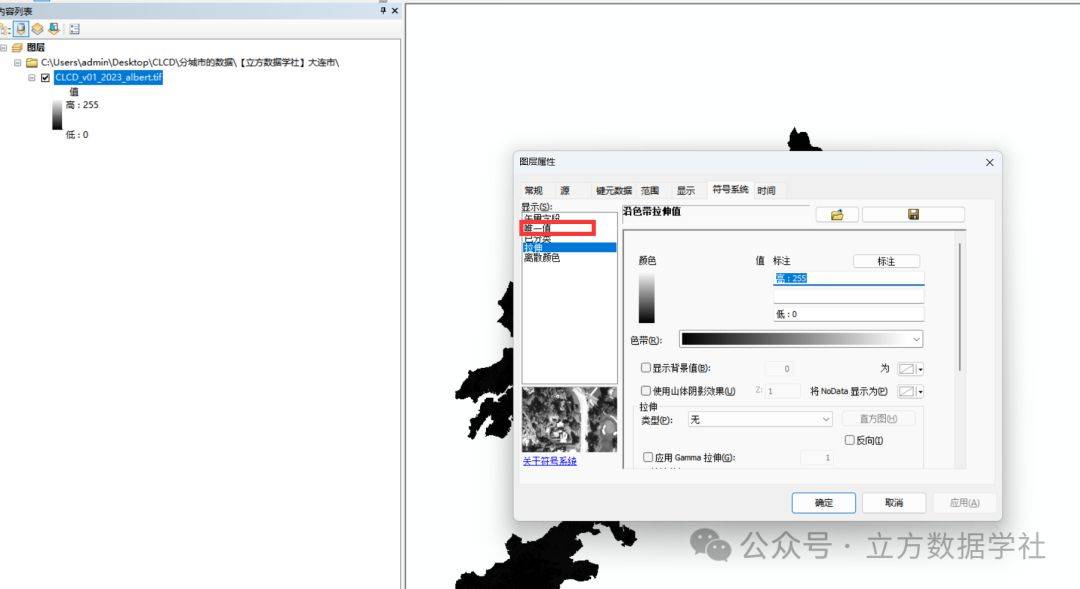
大家在arcgis软件里面打开该用地数据,数据如下图:

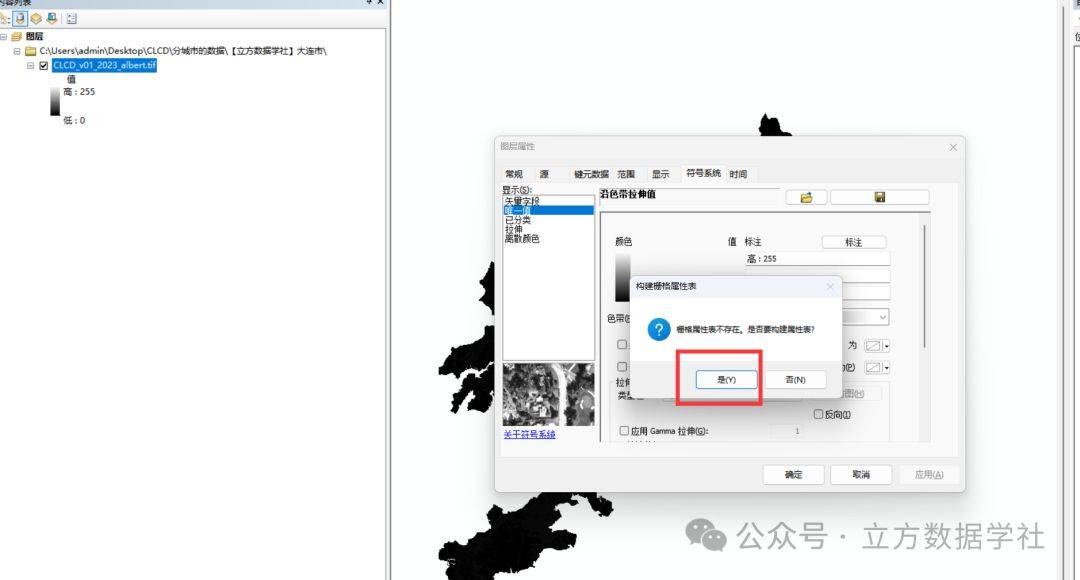
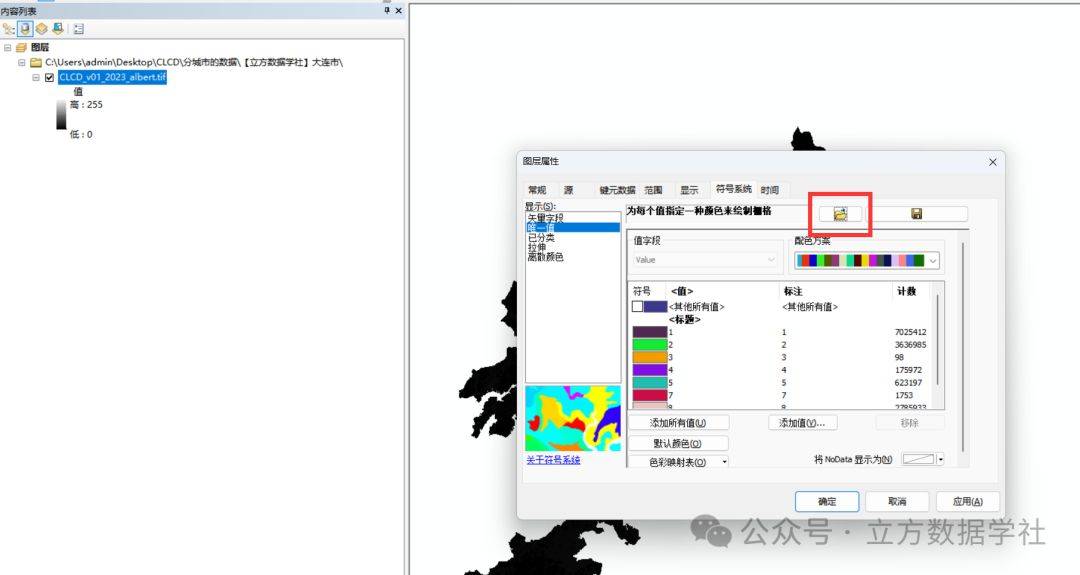
大家在图层名称上右键,选择属性,在属性里面可以对数据进行可视化,默认可视化样式是拉伸,我们选中唯一值,然后构建属性表,然后再加载我们提供给大家的可视化样式即可,效果下下图4!可视化样式的文件名为:可视化样式.lyr
03 数据详情
空间坐标:
Albers_Conic_Equal_Area
数据格式:
.tif格式
数据分类:
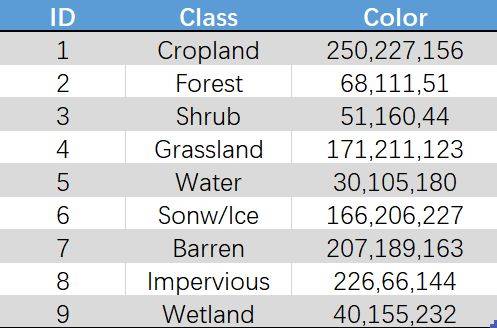
分为九类用地,以数字的形式表示,数字对应的用地类型为:
1:农田
2:森林
3:灌木
4:草原
5:水域
6:冰雪
7:裸地
8:不透水面
9:湿地
引用方式:
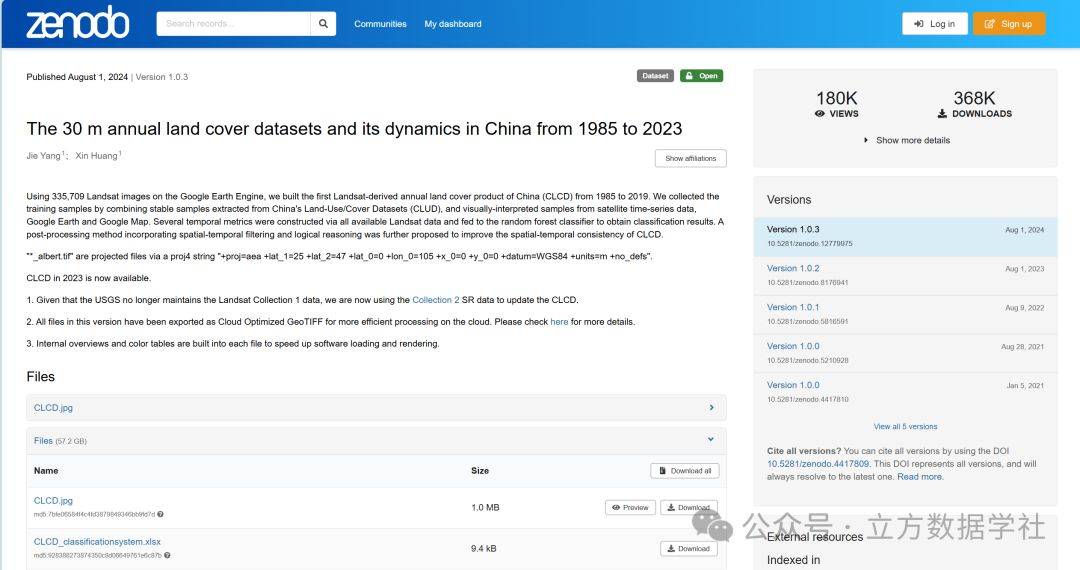
Jie Yang, & Xin Huang. (2024). The 30m annual land cover datasets and its dynamics in China from 1985 to 2023 [Data set]. In Earth System Science Data (1.0.3, Vol. 13, Number 1, pp. 3907–3925). Zenodo. https://doi.org/10.5281/zenodo.12779975
04 数据下载方式
大家可以在下面网址下载原始数据,有关数据的更多详情也可以查看网站介绍进行了解:https://zenodo.org/records/12779975
05 数据获取
如需获取数据,请关注下方公众号~

















 1404
1404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









