






你好# 大数据基础编程、实验和教程案例(实验七)
14.5 实验五:MapReduce 初级编程实践
本实验对应第 9 章的内容。
14.7.1 实验目的
(1)掌握使用 Spark 访问本地文件和 HDFS 文件的方法
(2)掌握 Spark 应用程序的编写、编译和运行方法
14.7.2 实验平台
| 操作系统 | Linux |
|---|---|
| Hadoop版本 | 3.1.3 |
| Spark 版本 | 2.4.0 |
14.7.3 实验步骤
1.Spark读取文件系统的数据
(1)在 spark-shell 中读取 Linux 系统本地文件“/home/hadoop/test.txt”,然后统计出文件的行数;
cd /usr/local/spark
./bin/spark-shell
scala>val textFile=sc.textFile("file:///home/hadoop/test.txt")
scala>textFile.count()

(2)在 spark-shell 中读取 HDFS 系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后,统计出文件的行数;
scala>val textFile=sc.textFile("hdfs://localhost:9000/user/hadoop/test.txt")
scala>textFile.count()

(3)编写独立应用程序(推荐使用 Scala 语言),读取 HDFS 系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后,统计出文件的行数;通过 sbt 工具将整个应用程序编译打包成 JAR 包,并将生成的 JAR 包通过 spark-submit 提交到 Spark 中运行命令。
使用 hadoop 用户名登录 Linux 系统,打开一个终端,在 Linux 终端中,执行如下命令创建一个文件夹 sparkapp 作为应用程序根目录:
cd ~
mkdir ./sparkapp
mkdir -p ./sparkapp/src/main/scala
需要注意的是,为了能够使用 sbt 对 Scala 应用程序进行编译打包,需要把应用程序代码存放在应用程序根目录下的“src/main/scala” 目录下。下面使用 vim 编辑器在“~/sparkapp/src/main/scala”下建立一个名为 SimpleApp.scala 的 Scala 代码文件,命令如下:
cd ~
vim ./sparkapp/src/main/scala/SimpleApp.scala
然后,在 SimpleApp.scala 代码文件中输入以下代码:
/* SimpleApp.scala */
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object SimpleApp {
def main(args: Array[String]) {
val logFile = " hdfs://localhost:9000/user/hadoop/test.txt"
val conf = new SparkConf().setAppName("Simple Application")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2)
val num = logData.count()
printf("The num of this file is %d", num)
}
}
下面使用 sbt 对 Scala 程序进行编译打包。
SimpleApp.scala 程序依赖于 Spark API,因此,需要通过 sbt 进行编译打包以后才能运行。 首先,需要使用 vim 编辑器在“~/sparkapp”目录下新建文件 simple.sbt,命令如下:
cd ~
vim ./sparkapp/simple.sbt
simple.sbt 文件用于声明该独立应用程序的信息以及与 Spark 的依赖关系(实际上,只要扩展名使用.sbt,文件名可以不用 simple,可以自己随意命名,比如 mysimple.sbt)。需要在 simple.sbt 文件中输入以下内容:
name := "Simple Project"
version := "1.0"
scalaVersion := "2.11.12"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.4.0"
为了保证 sbt 能够正常运行,先执行如下命令检查整个应用程序的文件结构:
cd ~/sparkapp
find .
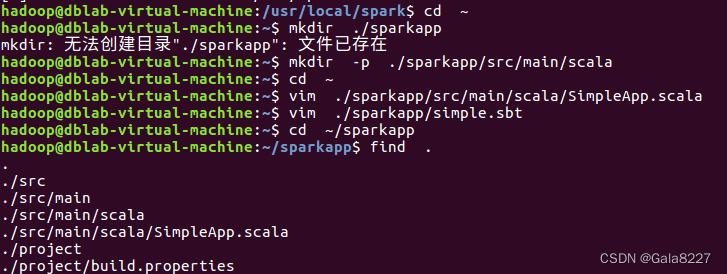
执行结果

生成的 JAR 包的位置为“~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar”。对于前面 sbt 打包得到的应用程序 JAR 包,可以通过 spark-submit 提交到 Spark 中运行

2.对于两个输入文件 A 和 B,编写 Spark 独立应用程序(推荐使用 Scala 语言),对两个文件进行合并,并剔除其中重复的内容,得到一个新文件 C。
下面是输入文件和输出文件的一个样例,供参考。
输入文件 A 的样例如下:
20170101 x
20170102 y
20170103 x
20170104 y
20170105 z
20170106 z
输入文件 B 的样例如下:
20170101 y
20170102 y
20170103 x
20170104 z
20170105 y
根据输入的文件 A 和 B 合并得到的输出文件 C 的样例如下:
20170101 x
20170101 y
20170102 y
20170103 x
20170104 y
20170104 z
20170105 y
20170105 z
20170106 z
(1)假设当前目录为/usr/local/spark/mycode/remdup,在当前目录下新建一个目录 mkdir -p src/main/scala,然后在目录/usr/local/spark/mycode/remdup/src/main/scala 下新建一个remdup.scala,复制下面代码
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
import org.apache.spark.HashPartitioner
object RemDup {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("RemDup")
val sc = new SparkContext(conf)
val dataFile = "file:///home/charles/data"
val data = sc.textFile(dataFile,2)
val res = data.filter(_.trim().length>0).map(line=>(line.trim,"")).partitionBy(new HashPartitioner(1)).groupByKey().sortByKey().keys
res.saveAsTextFile("result")
}
}
(2)在目录/usr/local/spark/mycode/remdup 目录下新建 simple.sbt,复制下面代码:
name := "Simple Project"
version := "1.0"
scalaVersion := "2.11.12"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.4.0"
(3)在目录/usr/local/spark/mycode/remdup 下执行下面命令打包程序
sudo /usr/local/sbt/sbt package
(4)最后在目录/usr/local/spark/mycode/remdup 下执行下面命令提交程序
/usr/local/spark/bin/spark-submit --class "RemDup" /usr/local/spark/mycode/remdup/target/scala-2.11/simple-project_2.11-1.0.jar
查看结果
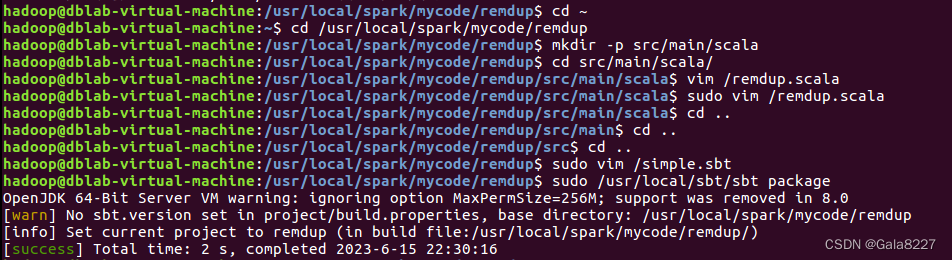

3.编写独立应用程序实现求平均值问题
每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生名字,第二个是学生的成绩;编写 Spark 独立应用程序求出所有学生的平均成绩,并输出到一个新文件中。
Algorithm成绩的样例如下:
小明 92
小红 87
小新 82
小丽 90
Database成绩的样例如下:
小明 95
小红 81
小新 89
小丽 85
Python成绩的样例如下:
小明 83
小红 82
小新 94
小丽 91
平均成绩的样例如下:
小明 89.67
小红 83.67
小新 88.33
小丽 88.67
准备工作
1.进入到mycode目录,新建RemDup目录(没有mycode目录可以新建一个)
再进入到RemDup目录中去

2.新建datas目录,写入文件algorithm、database、python:

写入文件:

Algorithm
小明 92
小红 87
小新 82
小丽 90
Database
小明 95
小红 81
小新 89
小丽 85
Python
小明 82
小红 83
小新 94
小丽 91
题目
书上是 avgscore ->AvgScore
(1)假设当前目录为/usr/local/spark/mycode/AvgScore,在当前目录下新建一个目录src/main/scala,然后在目 录/usr/local/spark/mycode/AvgScore/src/main/scala 下新建一个AvgScore.scala。复制如下代码:

//实际运行代码
//导入必要的 Spark 库:
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
import org.apache.spark.HashPartitioner
//定义应用程序对象和入口点:
object AvgScore {
def main(args: Array[String]) {
//设置 Spark 应用程序的配置:
val conf = new SparkConf().setAppName("AvgScore")
val sc = new SparkContext(conf)
//定义数据文件的路径并加载数据:
val dataFile = "file:///usr/local/spark/mycode/AvgScore/datas"
/*
这里使用 sc.textFile() 方法加载一个文本文件,
3 参数指定每个分区包含的行数。
*/
val data = sc.textFile(dataFile,3)
//定义一个计算平均分的函数,并应用到数据集上:
val res = data
//filter() 方法通过 trim() 函数过滤空行
.filter(_.trim().length > 0)
/*
map() 方法转换数据集,每行数据被转换成一个元组,包含学生姓名和成绩。
split() 方法用于将行拆分为数组
trim() 方法用于去除多余的空格,并将成绩转换为整数。
*/
.map(line => (line.split(" ")(0).trim(), line.split(" ")(1).trim().toInt))
//partitionBy() 方法将结果分区。
.partitionBy(new HashPartitioner(1))
//groupByKey() 方法将数据集按键(学生姓名)分组。
.groupByKey()
/*map() 方法遍历分组,计算平均成绩,并格式化为两位小数。
函数返回一个新的元组,包含学生姓名和平均成绩。*/
/*
下面这段代码是针对一个键值对RDD进行操作,其中每个键对应一个浮点数数组。
代码中的.map()函数将每个键值对映射为一个新的键值对,
其中新的值是原始数组的平均值(保留两位小数)。
首先定义了一个变量n和一个变量sum,分别用于计算数组元素的数量和总和。
然后,使用for循环遍历数组中的每个元素,将其加入sum中,并将n加1。
接下来,计算平均值avg,并使用f"$avg%1.2f"格式化为保留两位小数的字符串,
最后将键值对的值更新为这个字符串转换为Double类型的结果。
最终,代码返回一个新的键值对,其中键与原始RDD中的键相同,
而值则为该键对应的数组的平均值(保留两位小数)。
*/
.map(x => {
var n = 0
var sum = 0.0
for (i <- x._2) {
sum = sum + i
n = n + 1
}
val avg = sum / n
val format = f"$avg%1.2f".toDouble
(x._1, format)
})
/*
将结果保存到输出文件:
这里使用 saveAsTextFile() 方法将结果保存到一个文本文件。
Spark 会自动将数据保存在多个分区中。
*/
res.saveAsTextFile("file:///usr/local/spark/mycode/AvgScore/result")
}
}
(2)在/usr/local/spark/mycode/AvgScore目录下新建simple.sbt,复制如下代码:
name := "Simple Project"
version := "1.0"
scalaVersion := "2.11.12"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.4.0"
这里我先查看scala 和spark版本并修改
scala 2.11.12 => 2.11.6
spark 2.4.0 => 2.4.0

修改好内容如下:

(3)在/usr/local/spark/mycode/AvgScore目录下执行如下命令打包程序:
sudo /usr/local/sbt/sbt package

结果如下:

(4)在/usr/local/spark/mycode/AvgScore 目录下执行如下命令提交程序:
/usr/local/spark/bin/spark-submit --class "AvgScore" /usr/local/spark/mycode/avgscore/target/scala-2.11/simple-project_2.11-1.0.jar
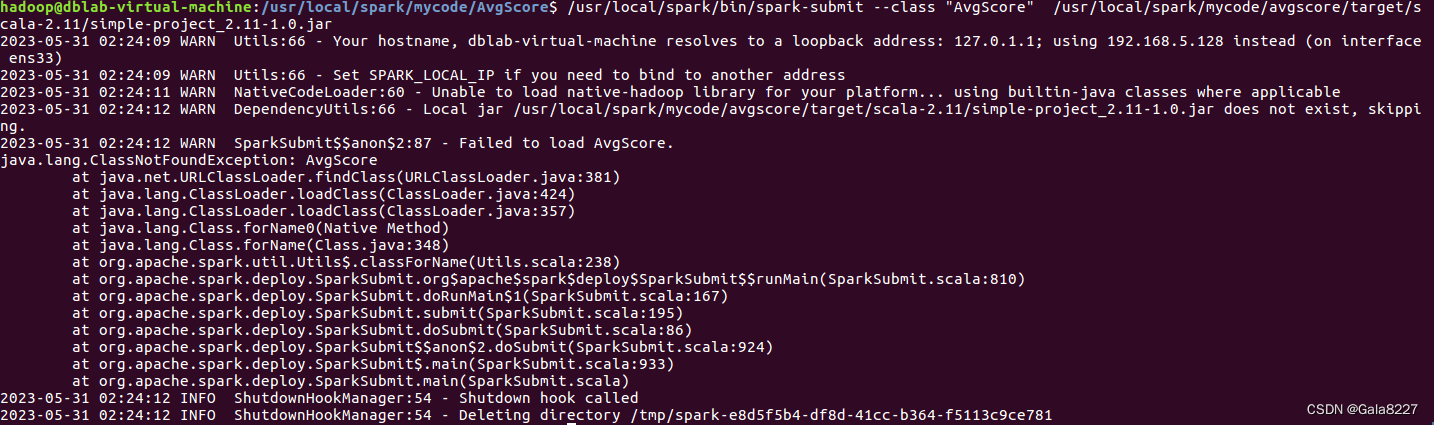
(5)在/usr/local/spark/mycode/AvgScore/result 目录下即可得到结果文件。

补充:
scala运行版本和查看版本不一致,让人思考simple.sbt底下用哪个版本合适
实验结果过后表明,两个版本都可以
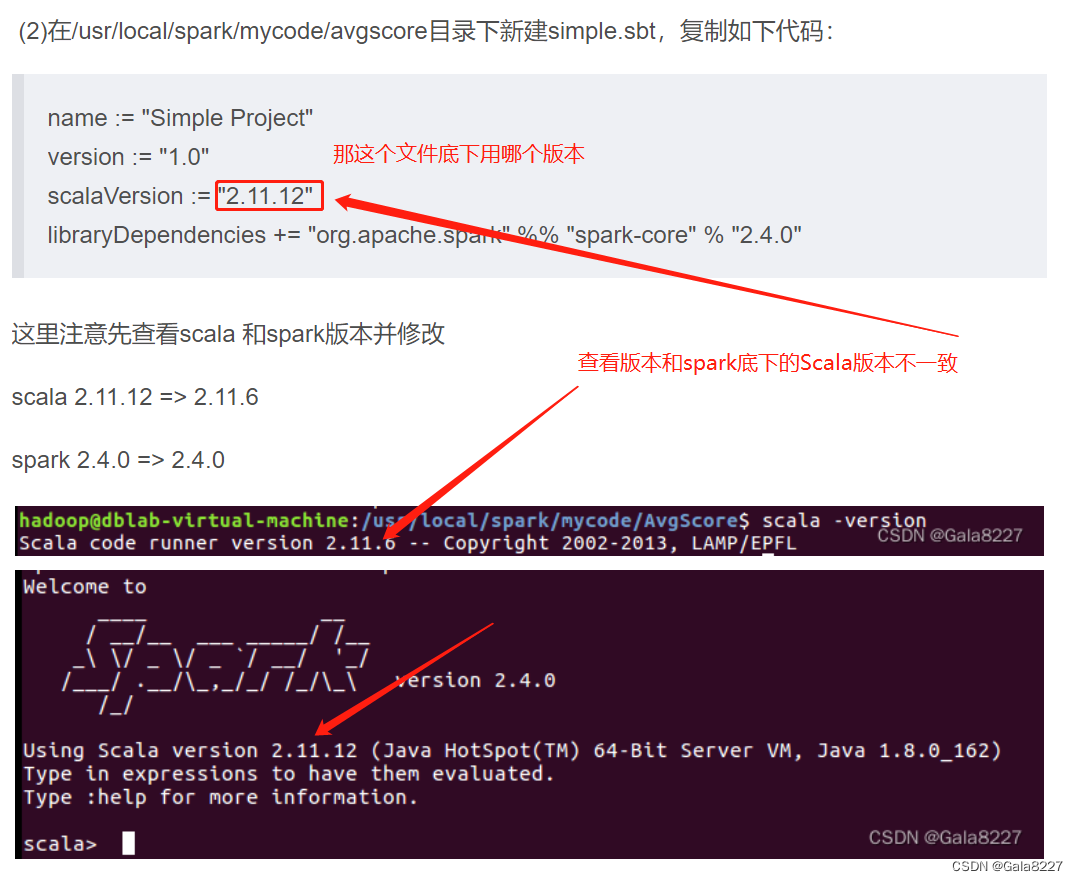
scala2.11.12 底下的运行结果

查看结果















 6710
6710











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









