







目录
第一章 大数据技术概论
1.1 大数据时代
很nb
1.2 大数据关键技术
大数据技术的不同层面以及其功能
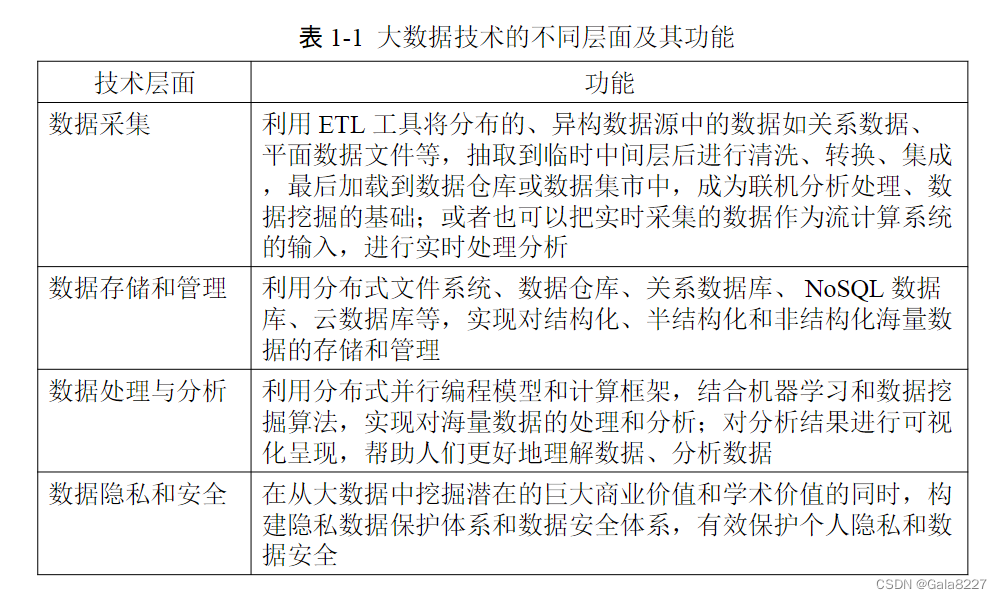
大数据两大核心技术
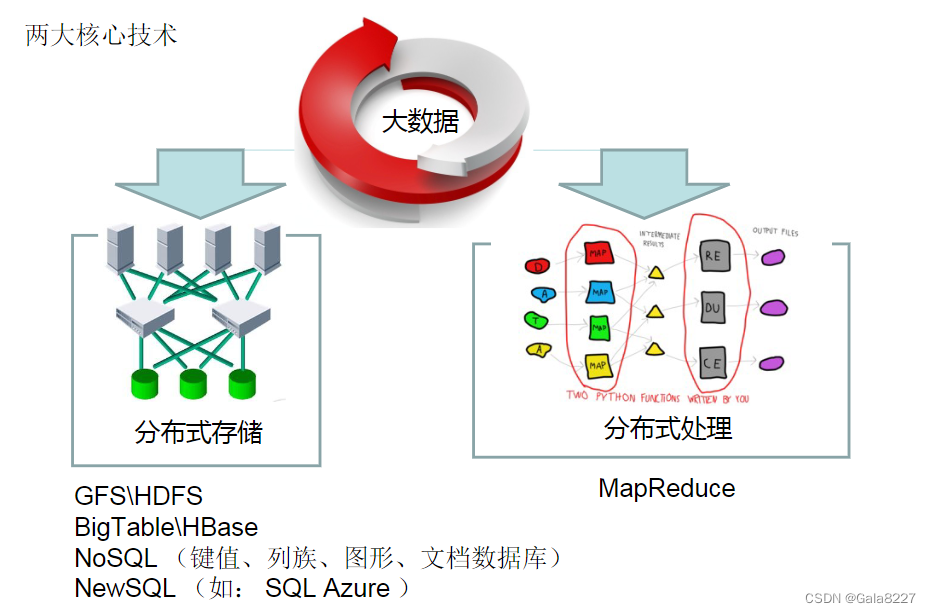
大数据计算模式及其代表产品
批处理计算主要解决针对大规模数据的批量处理,也是我们日常数据分析工作中常见的一类数据处理需求。例如爬虫......
1.3 大数据软件
本文章所涉及的大数据软件
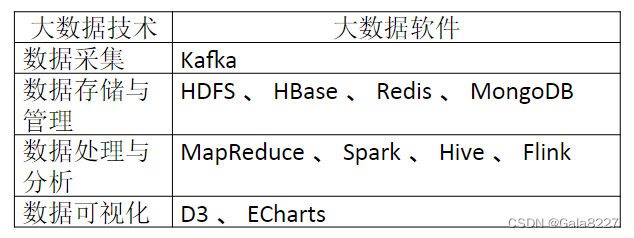
日志中会详细介绍软件安装和下载
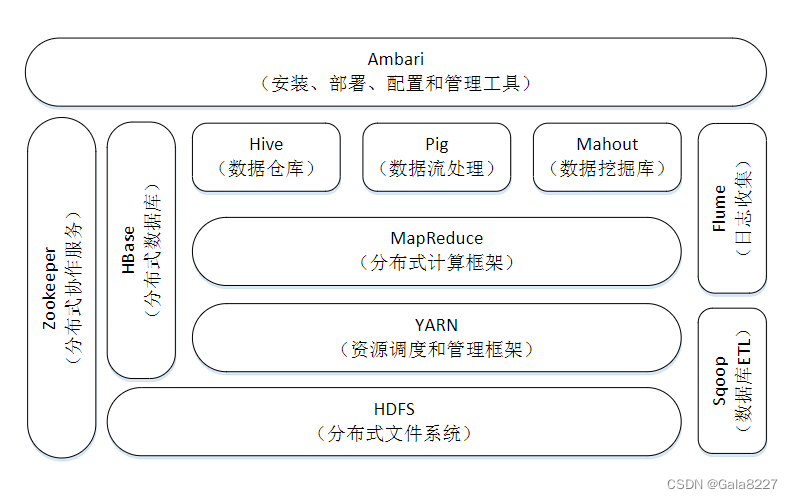
1.3.1 Hadoop
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算 。
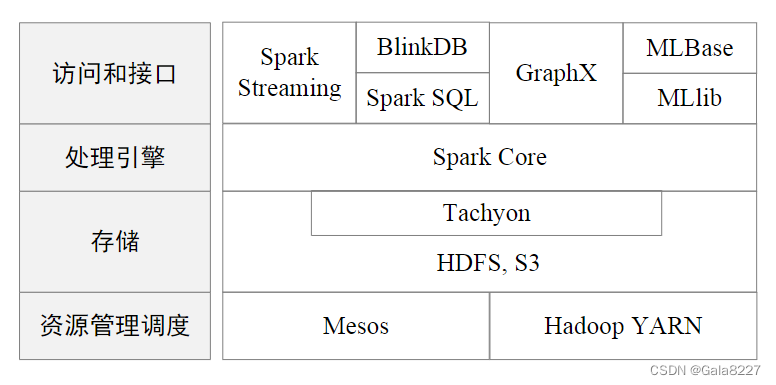
1.3.2 Spark
spark是一个用来实现快速,通用的集群计算平台。spark适用于各种各样原先需要多种不同的分布式平台的场景,包括批处理,迭代算法,交互式查询,流处理。通过在一个统一的框架下支持这些不同的计算,spark使我们可以简单而低耗地把各种处理流程整合在一起。
1.3.3 NoSQL数据库
NoSQL,泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在处理web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,出现了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,特别是大数据应用难题。NoSQL 数据库是一种不同于关系数据库的数据库管理系统,是对一大类非关系型数据库的统称,它所采用的数据模型并非传统关系数据库的关系模型,而是类似键 / 值、列族、文档等非关系模型。
NoSQL 数据库没有固定的表结构,通常也不存在连接操作,也没有严格遵守 ACID 约束,因此,与关系数据库相比, NoSQL 具有灵活的水平可扩展性,可以支持海量数据存储。
此外, NoSQL 数据库支持 MapReduce 风格的编程,可以较好地应用于大数据时代的各种数据管理。 NoSQL 数据库的出现,一方面弥补了关系数据库在当前商业应用中存在的各种缺陷,另一方面也撼动了关系数据库的传统垄断地位。
NoSQL 数据库虽然数量众多,但是,归结起来,典型的 NoSQL 数据库通常包括键值数据库、列族数据库、文档数据库和图数据库。本教程将介绍两种流行的 NoSQL 数据库产品的安装和使用方法,即键值数据库 Redis 和文档数据库 MongoDB 。
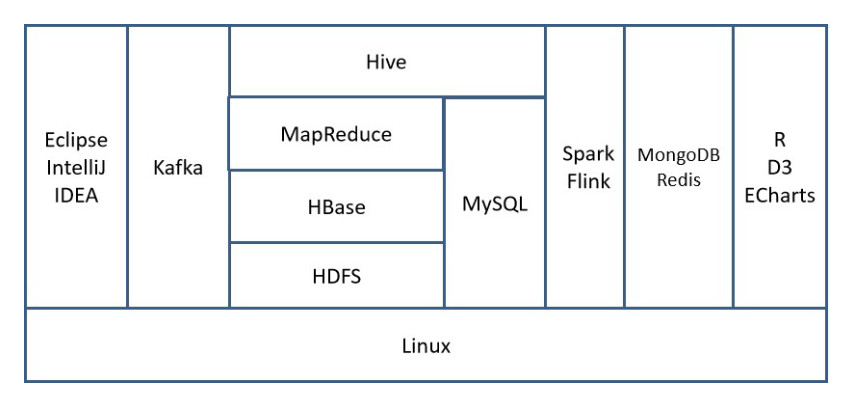
1.4 内容
本文大数据软件之间的相互关系
1.5 小结
大数据技术是一个庞杂的知识体系,包含了大量相关技术和软件。在具体学习相关技术及其软件之前,非常有必要建立对大数据技术体系的整体性认识。因此,本章首先从总体上介绍了大数据关键技术和各类大数据软件。鉴于不同的大数据学习者有着不同的学习需求,为了方便读者迅速找到对应的学习章节,本章给出了本教程的整体内容安排。此外,与教程配套的相关资源
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1310
1310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









