







目录
②Q:爬虫只能用python吗?真的是万能的吗?怎样确保合法性?
1.爬虫Q&A
①Q:什么是爬虫?目的是什么?
A1:网络爬虫,又称为网页蜘蛛,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。高大上的说法就是,通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬到本地,进而提取自己需要的数据,存放起来使用。简单理解来说就是抓取网络上的数据(文档、资料、图片等)。
A2:目的是:如何快速高效地找到我们需要的信息,常见的百度等搜索引擎就是利用爬虫对数据进行了整合和筛选操作。
②Q:爬虫只能用python吗?真的是万能的吗?怎样确保合法性?
A:很多语言都可以写爬虫,python有对应的库,所以会容易入手一点,但是应遵守法律,爬了不该爬的内容可快速实现“从入门到入狱”。
确保合法性:几乎每一个网站都有一个名为 robots.txt 的文档,当然也有部分网站没有设定 robots.txt。对于没有设定 robots.txt 的网站可以通过网络爬虫获取没有口令加密的数据。
以淘宝网为例,在浏览器中访问 https://www.taobao.com/robots.txt,淘宝网的robots.txt文件内容如图 所示:
淘宝网允许部分爬虫访问它的部分路径,而对于没有得到允许的用户,则全部禁止爬取,代码如下:
User-Agent:*
Disallow:/
这一句代码的意思是除前面指定的爬虫外,不允许其他爬虫爬取任何数据
爬虫原理:要给爬虫一个网址(程序中通常叫URL),爬虫发送一个HTTP请求给目标网页的服务器,服务器返回数据给客户端(也就是我们的爬虫),爬虫再进行数据解析、保存等一系列操作。
也可以换一个思路进行理解:
网页请求的过程分为两个环节:
Request (请求):每一个展示在用户面前的网页都必须经过这一步,也就是向服务器发送访问请求。
Response(响应):服务器在接收到用户的请求后,会验证请求的有效性,然后向用户(客户端)发送响应的内容,客户端接收服务器响应的内容,将内容展示出来,就是我们所熟悉的网页请求,如图 8 所示。
网页请求的方式也分为两种:
GET:最常见的方式,一般用于获取或者查询资源信息,也是大多数网站使用的方式,响应速度快。
POST:相比 GET 方式,多了以表单形式上传参数的功能,因此除查询信息外,还可以修改信息。
③写一个爬虫代码需要了解那些?对小白友好吗?
A:完成爬虫代码是现实的,但网站都会设置一定的反爬机制,所以也需要了解一下基础内容:
Q1:第一是所爬取的主题:网页,网页是什么呢?
A1:网页一般由三部分组成,分别是 HTML(超文本标记语言)、CSS(层叠样式表)和 JS(活动脚本语言)。
HTML(HTML 是整个网页的结构,相当于整个网站的框架。带“<”、“>”符号的都是属于 HTML 的标签,并且标签都是成对出现的。)
常见的标签如下:
<html>..</html> 表示标记中间的元素是网页
<body>..</body> 表示用户可见的内容
<div>..</div> 表示框架
<p>..</p> 表示段落
<li>..</li>表示列表
<img>..</img>表示图片
<h1>..</h1>表示标题
<a href="">..</a>表示超链接
CSS(CSS 表示样式,图 1 中第 13 行<style type="text/css">表示下面引用一个 CSS,在 CSS 中定义了外观。)
JScript(JScript 表示功能。交互的内容和各种特效都在 JScript 中,JScript 描述了网站中的各种功能。)
如果用人体来比喻,HTML 是人的骨架,并且定义了人的嘴巴、眼睛、耳朵等要长在哪里。CSS 是人的外观细节,如嘴巴长什么样子,眼睛是双眼皮还是单眼皮,是大眼睛还是小眼睛,皮肤是黑色的还是白色的等。JScript 表示人的技能,例如跳舞、唱歌或者演奏乐器等。
举个例子:
通过编写和修改 HTML,可以更好地理解 HTML。首先打开一个记事本,然后输入下面的内容:
<html>
<head>
<title> Python 3 爬虫与数据清洗入门与实战</title>
</head>
<body>
<div>
<p>Python 3爬虫与数据清洗入门与实战</p>
</div>
<div>
<ul>
<li><a href="http://c.biancheng.net">爬虫</a></li>
<li>数据清洗</li>
</ul>
</div>
</body>
输入代码后,保存记事本,然后修改文件名和后缀名为"HTML.html";
运行该文件后的效果,如下所示。
通过浏览器请求数据,服务器都会把以上三部分组成的内容发送过来,再经浏览器编译,就展现出看到的界面。实际上爬虫获取信息也是相似的流程,向服务器请求数据,请求到的数据存储到内存中,然后解析出想要的信息。
Q2:第二是爬虫的技术步骤是什么样子的?
A2:一般步骤:模拟浏览器发送请求(获取网页代码)->提取有用的数据->存放于数据库或文件中
a.发起请求
使用http库向目标站点发起请求,即发送一个Request
Request包含:请求头、请求体等(Request模块缺陷:不能执行JS 和CSS 代码)
b.获取响应内容
如果服务器能正常响应,则会得到一个Response(Response包含:html,json,图片,视频等)
c.解析内容
解析html数据:正则表达式(RE模块)、xpath(主要使用)、beautiful soup、css
(解析json数据:json模块、解析二进制数据:以wb的方式写入文件)
d.保存数据
数据库(MySQL,Mongdb、Redis)或 文件的形式。
2.爬虫的基本知识介绍
2.1爬虫的原理
如果要获取网络上数据,我们要给爬虫一个网址(程序中通常叫URL),爬虫发送一个HTTP请求给目标网页的服务器,服务器返回数据给客户端(也就是我们的爬虫),爬虫再进行数据解析、保存等一系列操作。
2.2流程
爬虫可以节省我们的时间,比如我要获取豆瓣电影 Top250 榜单,如果不用爬虫,我们要先在浏览器上输入豆瓣电影的 URL ,客户端(浏览器)通过解析查到豆瓣电影网页的服务器的 IP 地址,然后与它建立连接,浏览器再创造一个 HTTP 请求发送给豆瓣电影的服务器,服务器收到请求之后,把 Top250 榜单从数据库中提出,封装成一个 HTTP 响应,然后将响应结果返回给浏览器,浏览器显示响应内容,我们看到数据。我们的爬虫也是根据这个流程,只不过改成了代码形式。
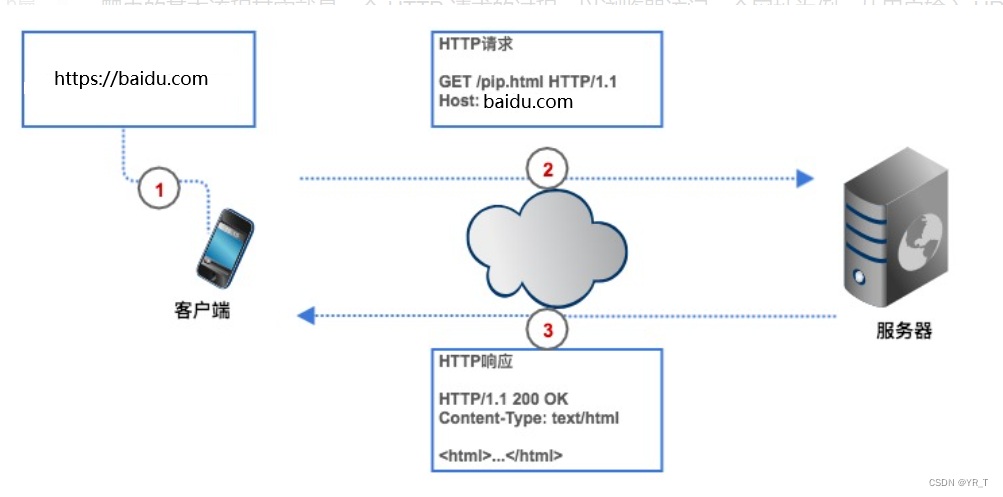
2.3HTTP请求
HTTP 请求由请求行、请求头、空行、请求体组成。
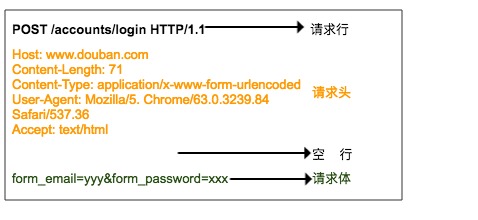
请求行由三部分组成:
1.请求方法,常见的请求方法有 GET、POST、PUT、DELETE、HEAD
2.客户端要获取的资源路径
3.是客户端使用的 HTTP 协议版本号
请求头是客户端向服务器发送请求的补充说明,比如说明访问者身份,这个下面会讲到。
请求体是客户端向服务器提交的数据,比如用户登录时需要提高的账号密码信息。请求头与请求体之间用空行隔开。请求体并不是所有的请求都有的,比如一般的GET都不会带有请求体。
上图就是浏览器登录豆瓣时向服务器发送的HTTP POST 请求,请求体中指定了用户名和密码。
2.4HTTP 响应
HTTP 响应格式与请求的格式很相似,也是由响应行、响应头、空行、响应体组成。
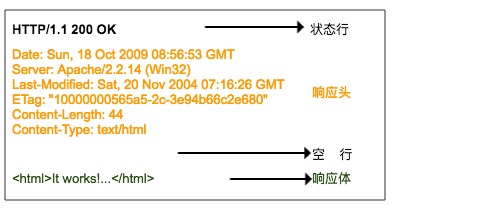
响应行也包含三部分,分别是服务端的 HTTP 版本号、响应状态码和状态说明。
这里状态码有一张表,对应了各个状态码的意思



第二部分就是响应头,响应头与请求头对应,是服务器对该响应的一些附加说明,比如响应内容的格式是什么,响应内容的长度有多少、什么时间返回给客户端的、甚至还有一些 Cookie 信息也会放在响应头里面。
第三部分是响应体,它才是真正的响应数据,这些数据其实就是网页的 HTML 源代码。
引用来源:
[1]Python爬虫详解(一看就懂)_练习时长两年半的Programmer的博客-CSDN博客
[2]Python 爬虫入门的教程(2小时快速入门、简单易懂、快速上手)_python爬虫快速入门_出走半生归来仍是少年的博客-CSDN博客















 80万+
80万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











