







文章目录
单独编译
我们可以将原来的程序分为三部分。
- 头文件:包含结构声明和使用这些结构的函数的原型。
- 源代码文件:包含与结构有关的函数的代码
- 源代码文件:包含调用与结构相关的函数的代码。
不能将函数定义放在头文件中
下面列出了头文件中常包含的内容。
- 函数原型
- 使用#define或const定义的符号常量
- 结构声明
- 类声明
- 模板声明
- 内联函数
头文件管理
有一种标准的c/c++技术可以避免多次包含同一个头文件,例如:
#ifndef COORDIN_H_
#define COORDIN_H
//place include file contents here
#endif
存储持续性、作用域和链接性
作用域和链接
作用域描述了名称在文件(翻译单元)的多大范围内可见。在类声明的成员作用域为整个类。在名称空间中声明的变量的作用域为整个名称空间(由于名称空间已经引入到c++语言中,因此全局作用域是名称空间作用域的特例)
c++函数的作用域可以是整个类、整个名称空间,但不能是局部的。
自动储存持续性
在函数定义中声明的变量的储存持续性为自动的。他们在程序开始执行其所属的函数或代码块时被创建,在执行完函数或代码块时,他们使用的内存被释放。例如
#include<iostream>
using namespace std;
void print()
{
int a = 3;
cout << "in print" << " " << &a << " " << a << endl;
}
int main()
{
int a = 1;
cout << "in main" << " " << &a << " " << a << endl;
while (1)
{
int a = 2;
cout << "in while" << " " << &a << " " << a << endl;
break;
}
print();
}
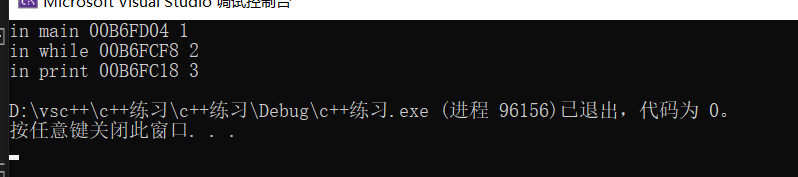
自动变量和栈
由于自动变量的数目随函数的开始和结束而增减,因此程序必须在运行时对自动变量进行管理。常用的方法是留出一段内存,并将其视为栈。
程序使用两个指针来跟踪栈,一个指针指向栈底,另一个指针指向变量后面的一下个可用内存单元,当函数调用时,其自动变量将被加入到栈中,栈顶指针指向变量后面的下一个可用的内存单元。函数结束时,栈顶指针被重置为函数被调用前的值,从而释放新变量使用的内存。
例如:
void fib(int real,long tell);
fib(16,50L)
函数fib()被调用时,传递一个2字节的int和一个4字节的long。这些值被加入到栈中,当fib()开始时,它将和名称real和tell同这两个值相关联起来。
静态持续变量
所有的静态持续变量都有下述初始化特征:未被初始化的静态变量的所有位都被设置为0.这种变量被称为零初始化的。
下面是五种变量存储方式
| 存储描述 | 持续性 | 作用域 | 链接性 | 如何声明 |
|---|---|---|---|---|
| 自动 | 自动 | 代码块 | 无 | 在代码块 |
| 寄存器 | 自动 | 代码块 | 无 | 在代码块,使用关键字register |
| 静态,无链接性 | 静态 | 代码块 | 无 | 在代码块中。使用static |
| 静态,外部链接性 | 静态 | 文件 | 外部 | 不在任何函数内 |
| 静态,内部链接性 | 静态 | 文件 | 内部 | 不在任何函数内,使用static |
| 例如: |
#include<iostream>
using namespace std;
int global = 1000;
static int one_file = 50;
void funct1()
{
static int count = 0;
int llama = 0;
}
int main()
{
count = 1;
}
global可以在其他文件中使用,one_file可以在当前文件中使用,count只能在funct1()函数中使用,但是和llama不同的是,即使在funct1()函数没有执行时,count也留在内存中。
静态持续变量、外部链接性
单定义规则
改规则指出,变量只能有一次定义。为满足这种需求,c++提供了两种变量声明。一种是定义声明,简称“定义”,他给变量分配空间;另一种是引用声明,或简称“声明”,他不给变量分配空间,因为它引用已有的变量。引用声明使用关键字extern,且不进行初始化‘否则,声明为定义;
例如:
#include<iostream>
using namespace std;
double warming = 0.1;
void update(double dt);
void local();
int main()
{
cout << "global warming is" << warming << endl;
update(0.1);
cout << "global warming is" << warming << endl;
local();
cout << "global warming is" << warming << endl;
}
#include<iostream>
using namespace std;
extern double warming;
void update(double dt);
void local();
void update(double dt)
{
warming += dt;
cout << "updating global warming to" << warming << endl;
}
void local()
{
double warming = 0.8;
cout << "local warming" << warming << endl;
cout << "but global warming=" << ::warming << endl;
}

通常情况下,应使用局部变量。
静态持续性,内部链接性
如果想要在两个文件中使用相同名称来表示其他变量,该怎么办?
例如
int a=1;
在另一个文件中只需
statci int a=2;
这个静态的内部链接性的a和静态外部链接性的a的地址不同,但如果另一个文件是extern int a,那么这两个a是同一个变量。
静态存储持续性、无链接性
无链接性的static就是之前接触过的类似求阶乘的东西。这里就不多介绍。这里注意到了一点东西。
char input[10];
cin.get(input,10);
这个cin.get()函数只能读取10-1个字符,剩下一个’\0’放到input中并留下一个换行符在队列中,另外将cin.get(char *,int)读取空行将会导致cin为false;
说明符和限定符
- auto(在c++11中不再是说明符)
- register
- static
- extern
- thread_local
- mutable
register用于在声明中指示寄存器存储,但在c++11中,它只是显式地指出变量是自动的。thread_local指出变量的持续性与其所属线程的持续性相同。
cv-限定符
下面就是cv-限定符
- const
- volatile
volatile表明,即使程序代码没有对内存单元进行修改,其值也可能发生变化。
mustable
mutable 指出,即使结构或类被声明为const,其某个成员也可被修改。例如:
struct data
{
char name[30];
mutable int accesses;
int a = 1;
};
int main()
{
const struct data veep = { "324234" };
strcpy(veep.name, "fdsfs");
veep.accesses++;
veep.a++;
}
strcpy()函数的第一个参数必须是char 而不是const char,另外a是不能++的而accesses由于mutable可以进行++;
再谈const
默认情况下全局变量的链接性是外部的,但const全局变量的链接性为内部的。也就是说,在c++看来,全局const定义就像使用了static一样
const int fingers=10//same as static const int fingers=10
这样,程序员就能将一组常量放在头文件中,并在同一个程序的多个文件中使用该头文件,如果const声明是外部的,根据单定义规则这样做将会出错。但如果程序员希望某个常亮的链接性是外部的,则可以使用extern关键字来覆盖默认的内部链接性:
extern const int states=50;
但在其他使用该变量的地方必须使用extern。
函数和链接性
在默认情况下,所有函数的存储持续性都自动为静态的,即在程序执行期间都存在。在默认情况下,函数的链接性是外部的,即可在文件中共享。可以使用static关键字将函数的链接性设置为内部的,使之只能在一个文件中使用。必须同时在原型和函数定义中使用该关键字:
static int private(double x);
static int private(double x)
{
}
对于链接性为外部的函数来说,这意味着在多文件程序中,只能有一个文件包含函数的定义,但使用该函数的每个文件都应包含其函数原型。
内联函数不受这项规则的约束,这允许程序员将内联函数的定义放在头文件中。然而c++要求同一个函数的所有内联定义必须相同。
c++在哪里查找函数
如果改文件中的函数原型指出函数是静态的,则编译器只在该文件中查找函数定义;否则,编译器将在所有的程序文件中查找,如果在程序文件中没找到,编译器会去库中查找。
语言的链接性
在c语言中,一个名称只能对应一个函数,为满足内部需要,c编译器可能将spiff这样的函数名翻译为_spiff。这种方法被称为c语言链接性。但在c++中,同一个名称可能对应多个函数,c++编译器执行名称矫正或名称修饰,为重载函数生成不同的符号名称,例如可能将spiff(int)转化成)_spiff_i,而将spiff(double,double)转换成)_spiff_d_d。这种方法被称为c++语言链接性。链接程序寻找与c++函数调用匹配的函数时,使用了c库中预编译的函数,将会出现什么情况?
spiff(22);他在c库中的名称为_spiff,但对于我们假设的链接程序来说,c++查询的是_spiff_i,为解决这样的问题,可以使用函数原型来指出我们的约定:
extern "C" void spiff(int);
extern void spoff(int);
extern "C++" void spaff(int);
举个例子
#include<iostream>
using namespace std;
#include<stdio.h>
extern "C" void spoff(int a);
int main()
{
spoff(2);
}
这是我在c++中的代码,如果不加上extern "C"编译器将会报错
#include<stdio.h>
void spoff(int a)
{
printf("yes");
}
这是用c语言写的代码,这样就能正确运行并输出yes.
存储方案和动态分配
使用new运算符初始化
在c++98中例如:
int *pi=new int(6);
double *pd=new double (99.99)
要初始化常规结构和数组,需要用大括号的列表初始化,这要求编译器支持c++11例如:
struct where { double x; double y; double z; };
int main()
{
where* one = new where{ 2.3,3.0 };
int* ar = new int[4]{ 2,3,45,2 };
int *pi=new int{};
double *pd=new double {99.99};
}
new:运算符、函数和替换函数
运算符new和new[]分别调用以下函数:
void* operator new(std::size_t);
void* operator new[](std::size_t);
同样也有delete和delete[]的释放函数例如:
void operator delete(void*);
void operator delete[](void*);
例如:
int *pi=new int;
///被转化为
int *pi=new(sizeof(int));
int *pa=new int [40]
///
int *pa=new(40*sizeof(int));
定位new运算符
他让您能够指定要使用的位置。程序员可能使用这种特性来设置其内存管理规程、处理需要通过特定地址进行访问的硬件或在特定位置创建对象
举个例子:
#include<iostream>
using namespace std;
char buffer[500];
int main()
{
double* pd1, * pd2;
pd1 = new double[5];
pd2 = new (buffer)double[5];
for (int i = 0; i < 5; i++)
{
pd1[i] = pd2[i] = 1000 + 20.0 * i;
}
cout << "pd1的地址=" << pd1 << "buffer的地址=" << (void*)buffer << endl;
for (int i = 0; i < 5; i++)
{
cout << pd1[i] << "at" << &pd1[i] << " " << pd2[i] << "at " << &pd2[i] << endl;
}
cout << "第二次" << endl;
double* pd3, * pd4;
pd3 = new double[5];
pd4 = new(buffer)double[5];
for (int i = 0; i < 5; i++)
{
pd3[i] = pd4[i] = 1000 + 40.0 * i;
}
cout << "pd3的地址=" << pd3 << "buffer的地址=" << (void*)buffer << endl;
for (int i = 0; i < 5; i++)
{
cout << pd3[i] << "at" << &pd3[i] << " " << pd4[i] << "at " << &pd4[i] << endl;
}
cout << "第三次\n";
delete[] pd1;
pd1 = new double[5];
pd2 = new (buffer + 5 * sizeof(double))double[5];
for (int i = 0; i < 5; i++)
{
pd1[i] = pd2[i] = 1000 + 60.0 * i;
}
cout << "pd1的地址=" << pd1 << "buffer的地址=" << (void*)buffer << endl;
for (int i = 0; i < 5; i++)
{
cout << pd1[i] << "at" << &pd1[i] << " " << pd2[i] << "at " << &pd2[i] << endl;
}
}

需要指出的是定位运算符使用传递给它的地址,他不跟踪那些内存单元被使用,也不查找未使用的内存块。而且delete不能用于释放定位new运算符分配的内存,buffer指定的内存是静态内存,而delete只能用于这样的指针:指向常规new运算符分配的堆内存。c++允许程序员重载定位new函数。
名称空间
新的名称空间特性
c++新增了这样一种功能,即通过定义一种新的声明区域来创建命名的名称空间,这样做的目的之一是提供一个声明名称的区域。例如,使用新的关键字namespace 创建两个名称空间:fack和jill
namespace jack {
double pail;
void fetch();
int pal;
struct well
{
};
}
namespace jill
{
double bucket(double n)
{
return 1;
}
double fetch;
int pal;
struct hill
{
};
}
名称空间可以是全局的,也可以位于另一个名称空间中,但不能位于代码块中。
void test1()
{
namespace jill
{
double bucket(double n)
{
return 1;
}
double fetch;
int pal;
struct hill
{
};
}
}
这将会报错。
namespace jack {
double pail;
void fetch();
int pal;
struct well
{
};
namespace jill
{
double bucket(double n)
{
return 1;
}
double fetch;
int pal;
struct hill
{
};
}
}
这样就不会。在默人情况下,在名称空间中声明的名称的链接性是外部的。
除了用户定义的名称空间外,还存在另一个名称空间–全局名称空间。它对应于文件级声明区域,因此前面所说的全局变量现在被描述为位于全局名称空间中.
名称空间是开放的,即你可以把名称加入到已有的名称空间中。例如:
namespace jill
{
char* goose(const char*);
}
jack为fetch()函数提供了原型。我可以在文件后面或者另一个文件中再次使用jack名称来提供该函数的代码。
namespace jack {
void fetch()
{
}
}
通过作用域解析运算符可以来访问给定名称空间中的名称。例如:
int main()
{
jack::pail = 12.34;
jill::hill mole;
jack::fetch();
}
using 声明和using编译指令
using声明使特定的标识符可用,using编译指令使整个名称空间可用。
using 声明将特定的名称添加到它所属的声明区域中。例如main()中的using声明jill::fetch将fetch添加到main()定义的声明区域中。
namespace jill {
double bucket()
{
}
double fetch;
struct hill {
};
}
char fetch;
int main()
{
using jill::fetch;
double fetch; error 局部fetch重定义
cin >> fetch; ///jill::fetch
cin >> ::fetch; ///char fetch
}
和using namespace std 一样using编译指令使所有的名称都可用。
需要注意的是using编译指令和using声明,增加了名称冲突的可能性,要使用作用域解析运算符就不会存在二义性。
using编译指令和using声明之比较
如果使用using编译指令导入一个已经在函数中声明的名称,则局部名称将隐藏名称空间名,就像隐藏同名的全局变量一样,但是如果是using声明将名称空间的名称导入该声明区域,则这两个名称会发生冲突,从而出错。另外在函数中也应使用限定的标识符例如;
namespace jill
{struct hill{};
}
int foom()
{
hill top;///error
jill::hill creast;///valid
}
名称空间的其他特性
可以将名称空间声明进行嵌套:
namespace elements
{
namespace fire
{
int flame;
}
float water;
}
这里的flame可以是elements:🔥:flame。也可以是using namespace elements::fire;
另外也可以在名称空间中使用using编译指令和using声明。如:
namespace myth
{
using jill::fetch;
using namespace elements;
using std::cout;
using std::cin;
}
则可以
using namespace myth;
cin>>fetch;
using编译指令使可传递的。
例如;
using namespace myth;
等价于:
using namespace myth;
using namespace elements;
可以给名称空间起别名。例如:
namespace my_very_favorite_things
{
};
可以这样:
namespace mvft=my_very_favorite_things;
未命名的名称空间
例如:
namespace
{
int ice;
int bandycoot;
}
由于没有名称,则不能在未命名名称所属文件之外的其他文件中,使用该名称空间中的名称。这提供了链接性为内部的静态变量的替代品。例如;
static int count;
等价于
namespace
{
int counts
}
#include<iostream>
#include"namesp.h"
void other(void);
void another(void);
int main()
{
using debts::debt;
using debts::showdebt;
debt golf = { {"benny","goatsniff"},120.0 };
showdebt(golf);
other();
another();
return 0;
}
void other(void)
{
using std::cout;
using std::endl;
using namespace debts;
person dg = { "doodles","glister" };
showperson(dg);
cout << endl;
debt zippy[3];
int i;
for (i = 0; i < 3; i++)
{
getdebt(zippy[i]);
}
for (i = 0; i < 3; i++)
{
showdebt(zippy[i]);
}
cout << "total debt: $" << sumdebts(zippy, 3) << endl;
return;
}
void another(void)
{
using pers::person;
person collector = { "milo","rightshift" };
pers::showperson(collector);
std::cout << std::endl;
}
namespace debts
{
void getdebt(debt & rd)
{
getperson(rd.name);
std::cout << "enter debt: ";
std::cin >> rd.amount;
}
void showdebt(const debt& rd)
{
showperson(rd.name);
std::cout << ": &" << rd.amount << std::endl;
}
double sumdebts(const debt ar[], int n)
{
double total = 0;
for (int i = 0; i < n; i++)
{
total += ar[i].amount;
}
return total;
}
}
#pragma once
#include<string>
namespace pers
{
struct person
{
std::string fname;
std::string lname;
};
void getperson(person&);
void showperson(const person&);
}
namespace debts
{
using namespace pers;
struct debt
{
person name;
double amount;
};
void getdebt(debt&);
void showdebt(const debt&);
double sumdebts(const debt ar[], int n);
}
一个简单的账单管理系统。
名称空间及前途
- 使用在已命名的名称空间中声明的变量,而不是使用外部全局变量
- 使用在已命名的名称空间中声明的变量,而不是使用静态全局变量
- 如果开发了一个函数库或类库,将其放在一个名称空间中。
- 不要在头文件中使用using编译指令,这样做掩盖了要让哪些名称可用。非要使用编译指令using,应将其放在所有预处理编译器指令#include之后。
- 导入名称时,首选使用作用域解析运算符或using声明的方法。
- 对于using声明,首先将其作用域设置为局部而不是全局。
















 155
155











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









