









一、问题背景
当我们给出主字符串s(长度为n)和副字符串t(长度为m),我们需要在s中找到与副字符串t相匹配的子字符串,我们常用的做法是遍历s中的每一个字符,对比是否和t中的相等,相等则返回匹配的第一个下标:
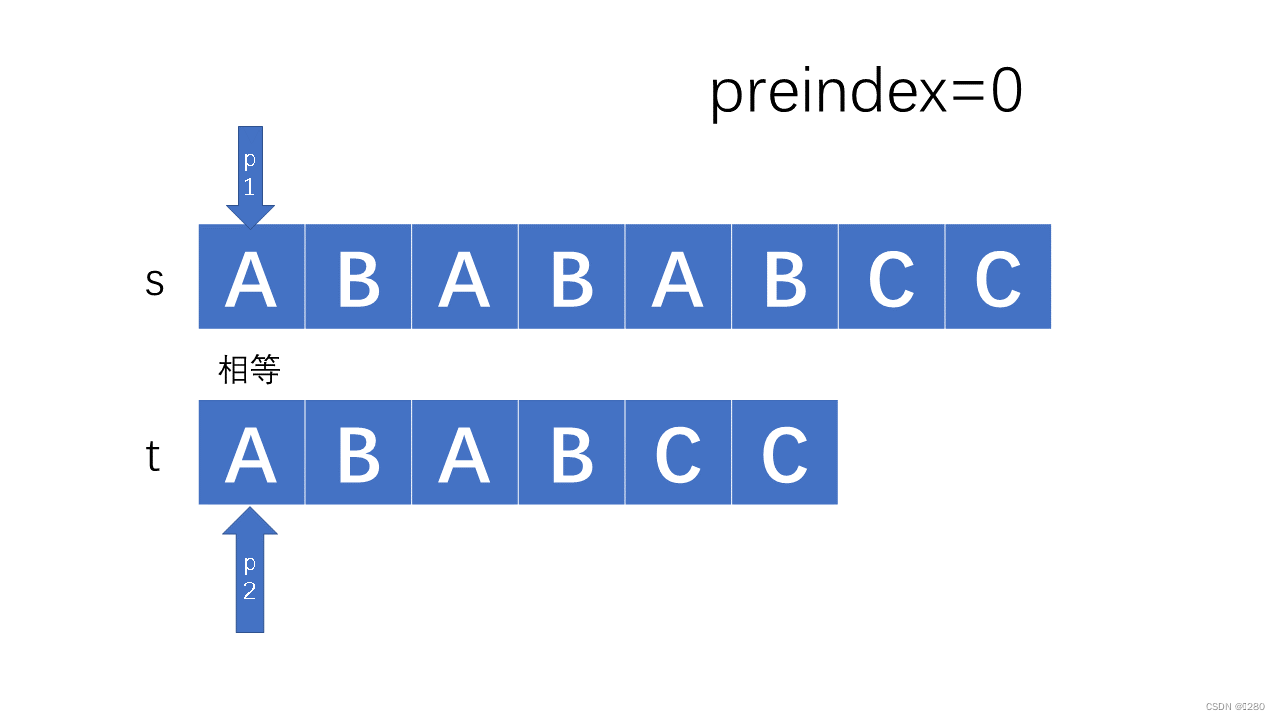

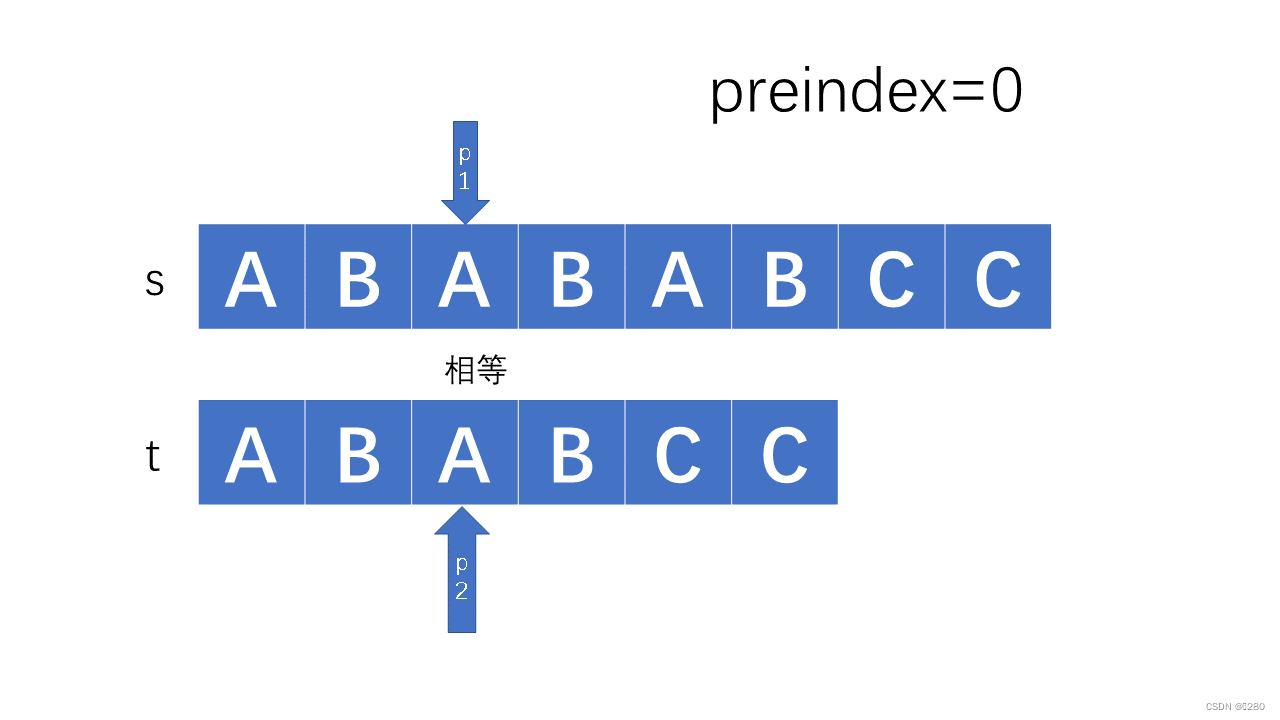
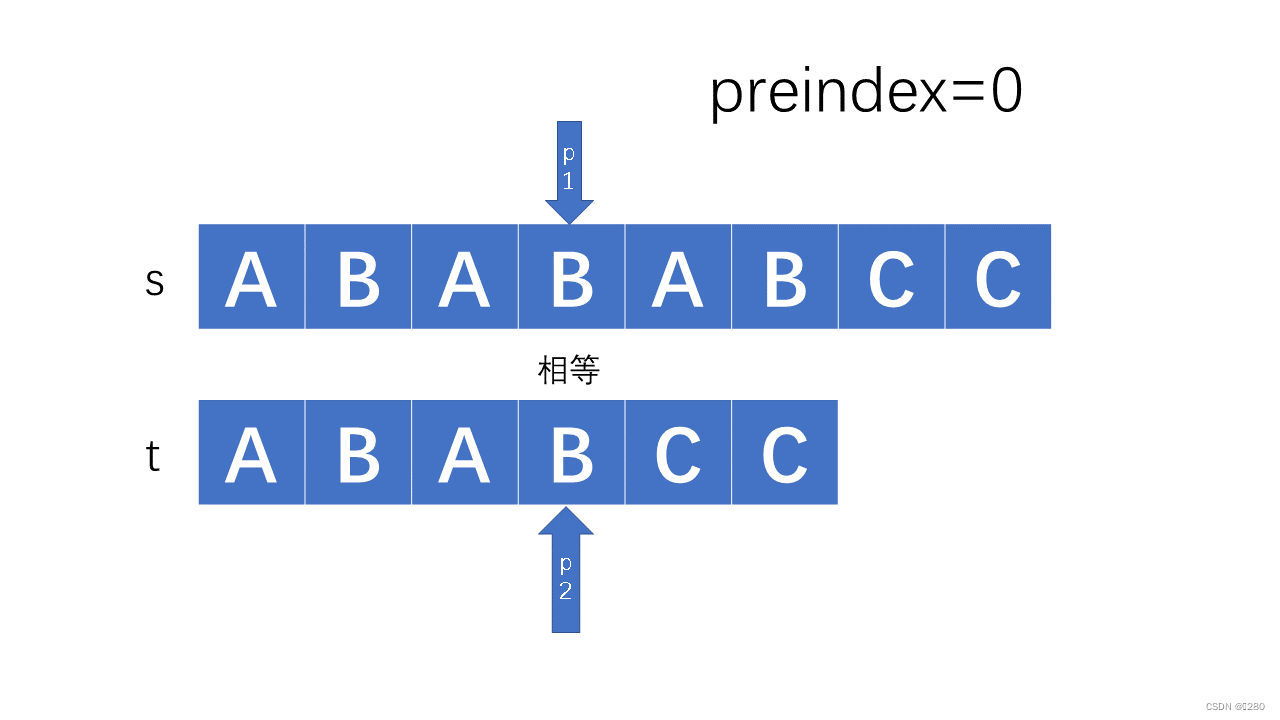
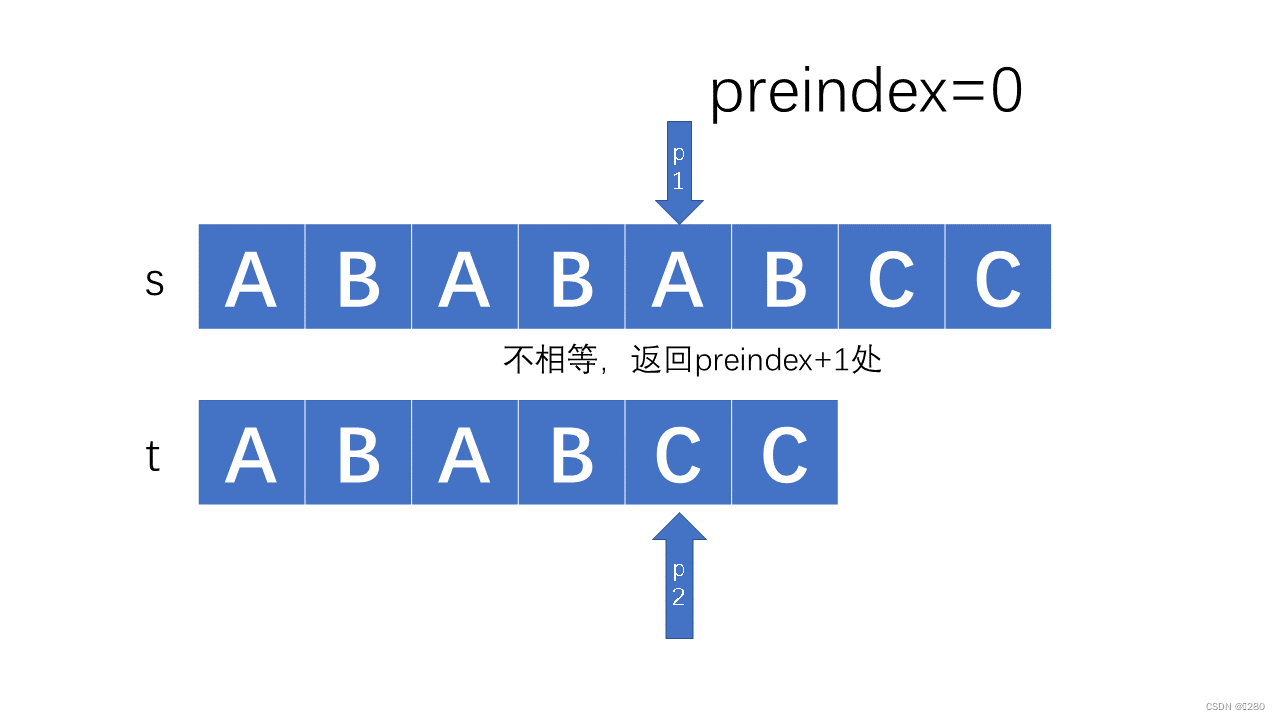
其代码实现如下:
int strmatch(string s, string t) {
if(t.size()>s.size())return -1;//副串长度大于主串,不可能匹配成功
int n=s.size(),m=t.size();
for(int preindex=0;preindex<=n-m;preindex++;{//只用遍历到主串长度-副串长度的位置
int p1=preindex,p2=0;
while(k<m&&s[j]==s[k]){//比较是否相等,相等则移动p1,p2;
p1++;
p2++;
}
if(p2==m)return preindex;//此时p2已经走完,则说明成功
}
return -1;
}
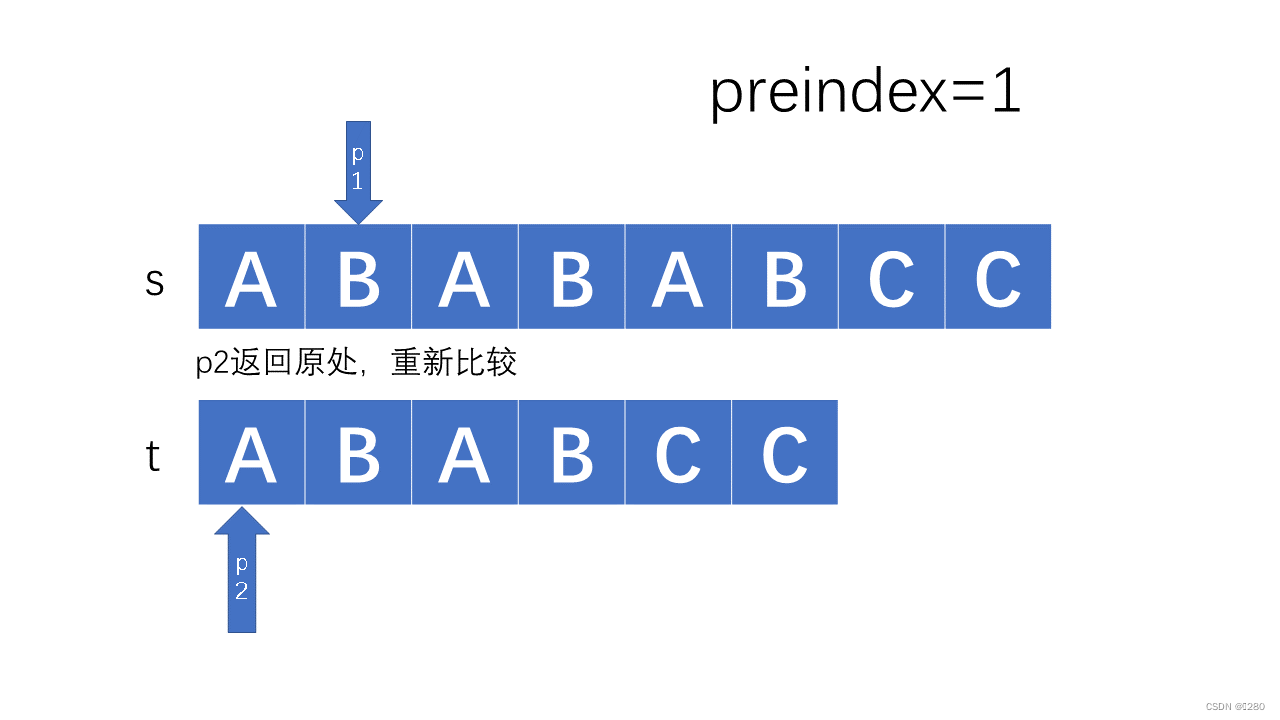
上述方法是暴力枚举法BF算法,其时间复杂度为O(n*m),空间复杂度为O(1),该复杂度太高,而且里面有许多没必要的冗余操作,例如在上上图例子中,当我们匹配完ABAB后,如果下一个不为C则不一定需要移动,我只要比较主字符串的下一个是否是为A就行,因此就提出了一个线性时间的字符匹配算法:KMP算法。
二、KMP算法概述
KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt提出的,因此人们称它为克努特—莫里斯—普拉特操作(简称KMP算法)。KMP算法的核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。具体实现就是通过一个next()函数实现,函数本身包含了模式串的局部匹配信息。(建议跳过)
三、KMP算法实现
在KMP算法中,我们借助一个叫next数组的数据结构来帮助我们解答,先不关注next数组怎么来的(实在想知道跳往目录四),在枚举方法中,我们没有充分利用已经遍历过的信息,充分利用信息可以帮助我们减少时间,KMP算法原理如下:
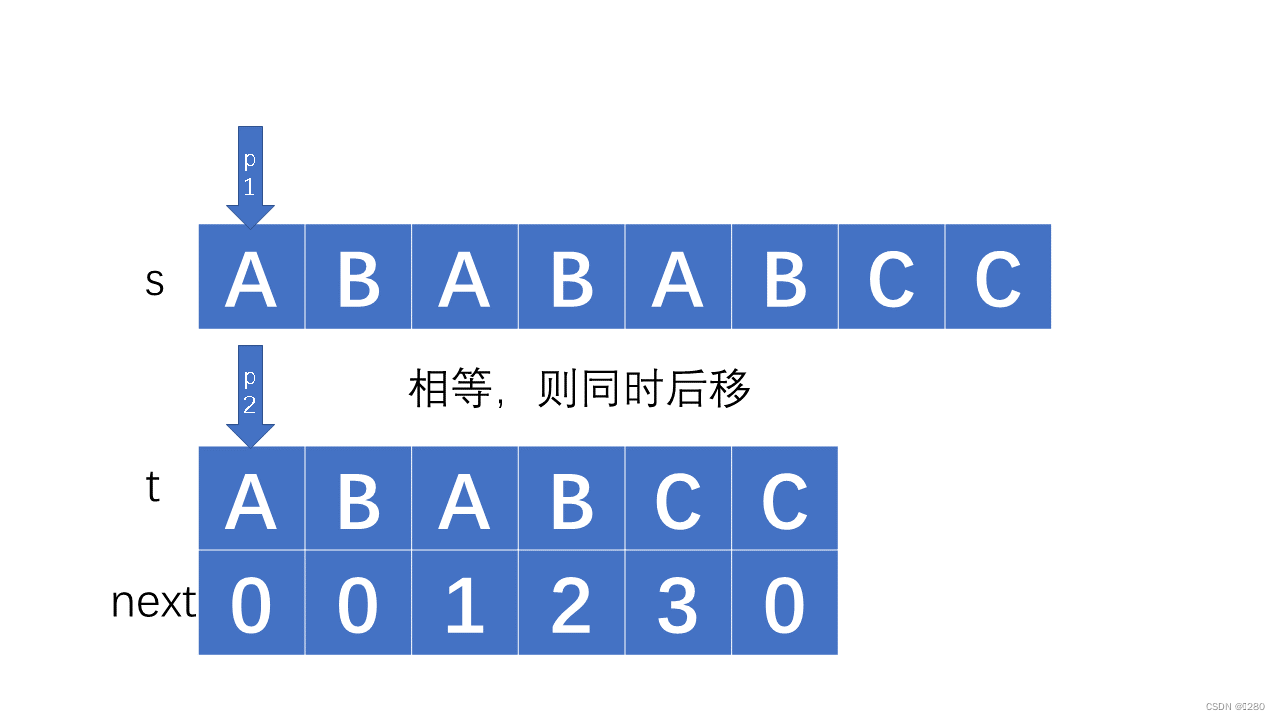
如果主副串相同,则直接后移:
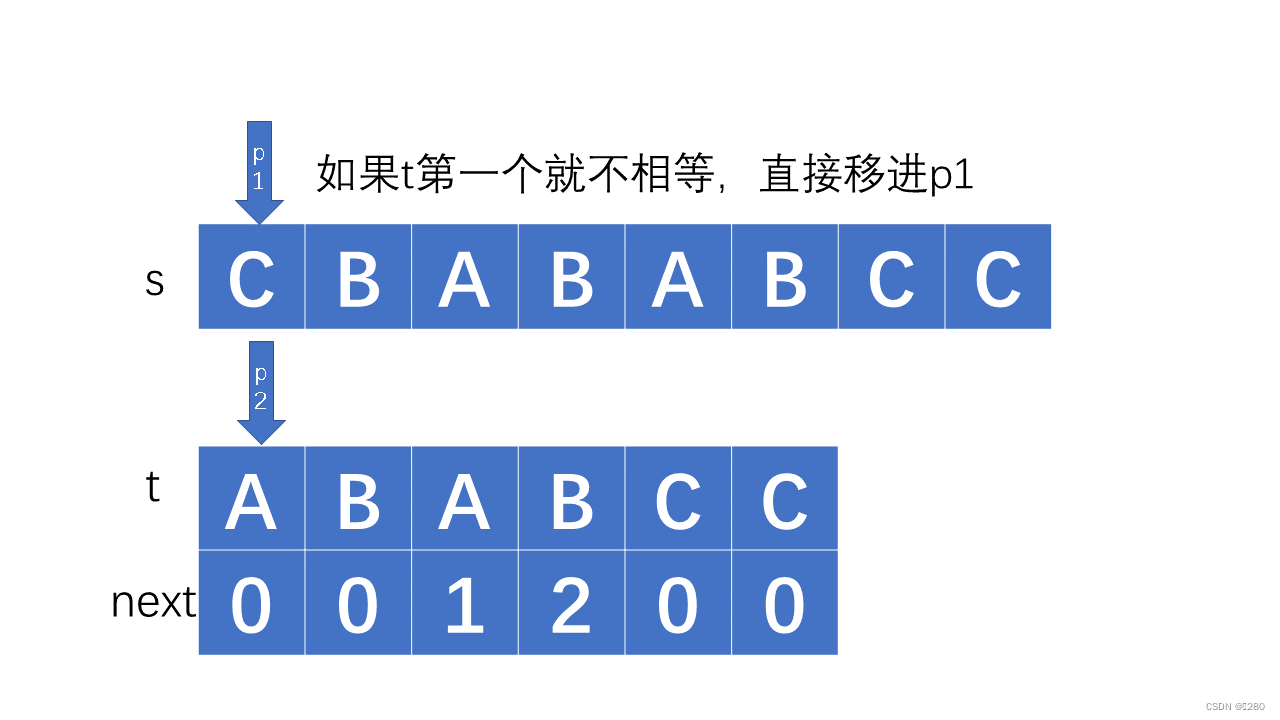
若不相同,如果是副首项不同,移进主串即可:
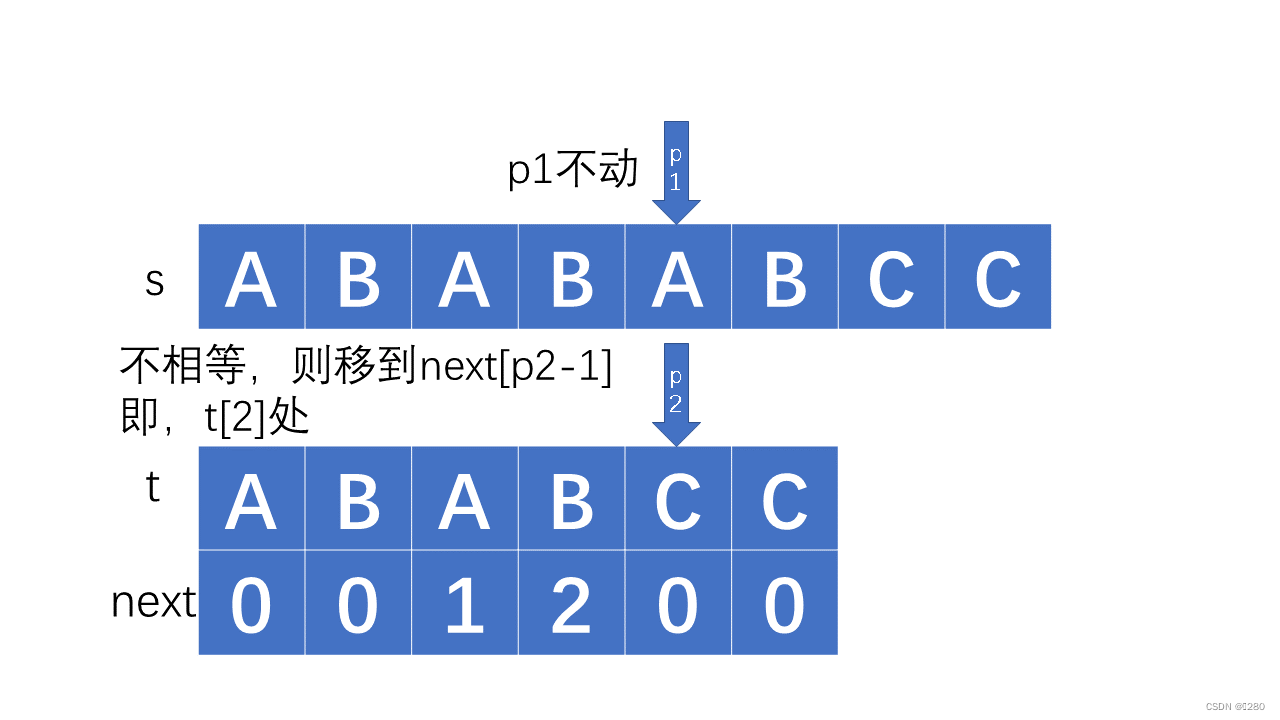
如果不是首项不同,例如ABABC,当我们检测到c与主串中不同的时候,我们已经知道主串指针当前位置与其前四个一定是ABABX(其中X非C),那么我们就没必要再次回到第二个B去再次比较,主串中的第二个AB已经可以和副串的第一个AB匹配了,我们返回到t的第二个A处,这都标记在我们的next数组中,即p2=p2[next-1]:
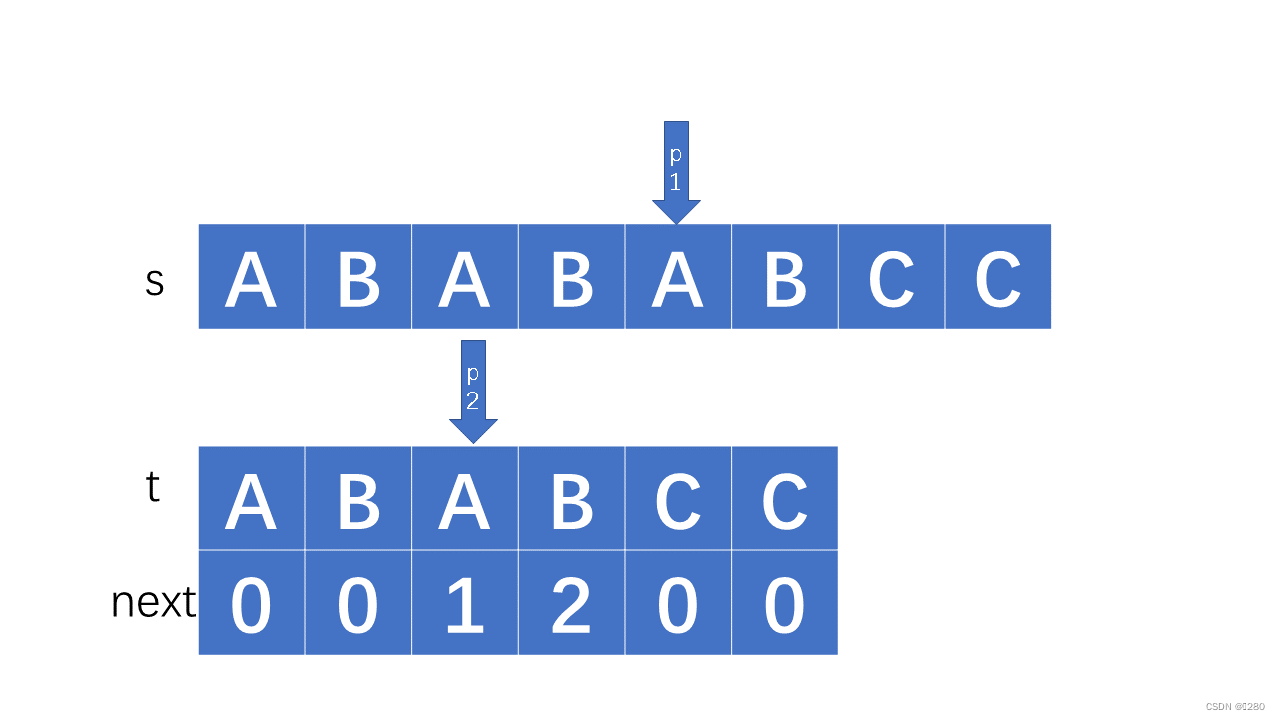
这样的推进方式p1只会向前走,不会回溯,这就是精髓所在,因此该算法得到的时间复杂度为O(n)(不包括子串求解部分),打破nm大关
其代码实现:
int KMP(string s,string t){
vector<int> next=getNext(t);//获取next数组
int p1=0;
int p2=0;
while(p1<p2){
if(s[p1]==[p2])p1++,p2++;//相等则指针同时后移
else if(p2==0)p1++;//此时副字符串第一个就不相等,直接移动p1
else p2=next[p2-1];//p2根据已有信息跳过一些字符
if(p2==t.size())return p1-p2;//匹配成功
}
return -1;
}四、NEXT数组的求取
next数组对我们的算法提升如此重要我们要如何求取呢?如果用暴力方法去求取该回到何处,那么我们的复杂度回到O(),肯定是不能这么做的。
在KMP算法中,我们在主副串不匹配的时候,可以根据next数组去跳过我们可以不匹配的字符的个数,那么为什么可以这么做呢?

因为我们之前所匹配的AB(t中第二条横线)和我们要跳过的AB(t中第一条横线)是一样的,因此我们可以省略该工作。我们抽象其中的原理出来,也就是第一个AB是t的前缀,第二个AB是t的后缀,他们相等且长度为2,所以我们能跳过的数目就是副串中最长相等前后缀的长度。
next数组的意义就是:副串中最长相等前后缀的长度(该长度要小于串长度,否则跳过了全部又回到该不匹配的字母就无意义了)
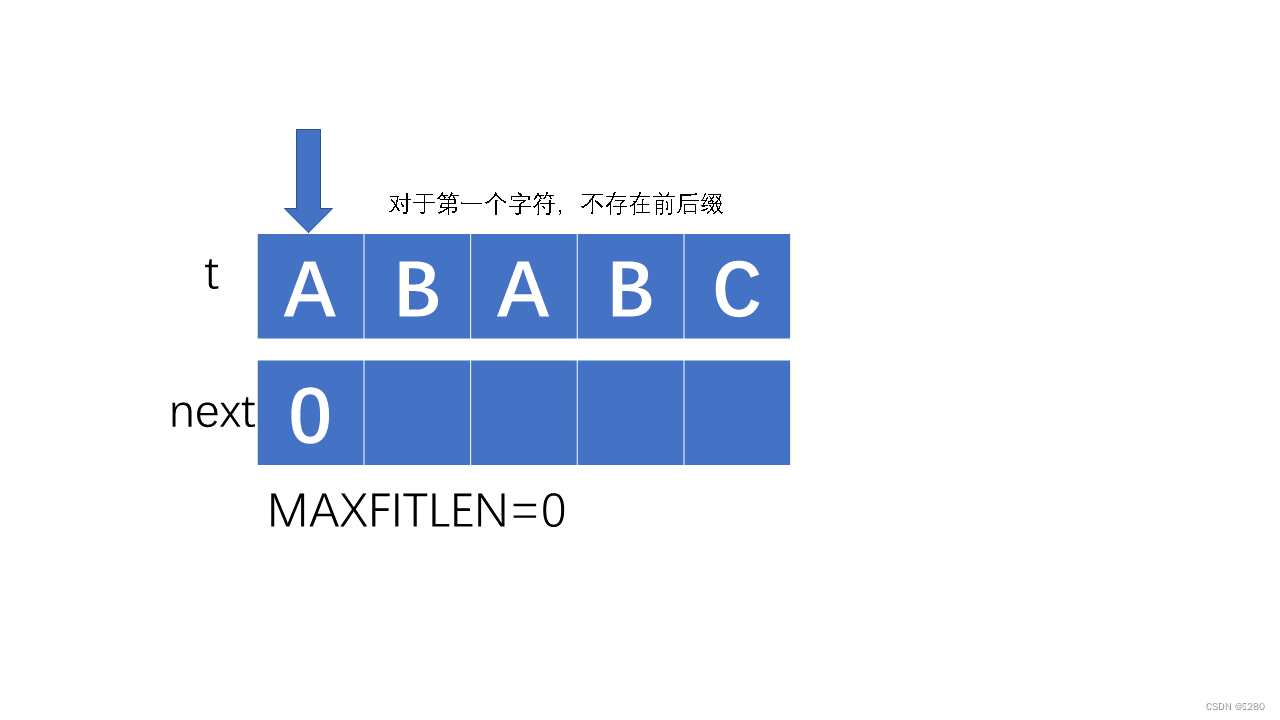
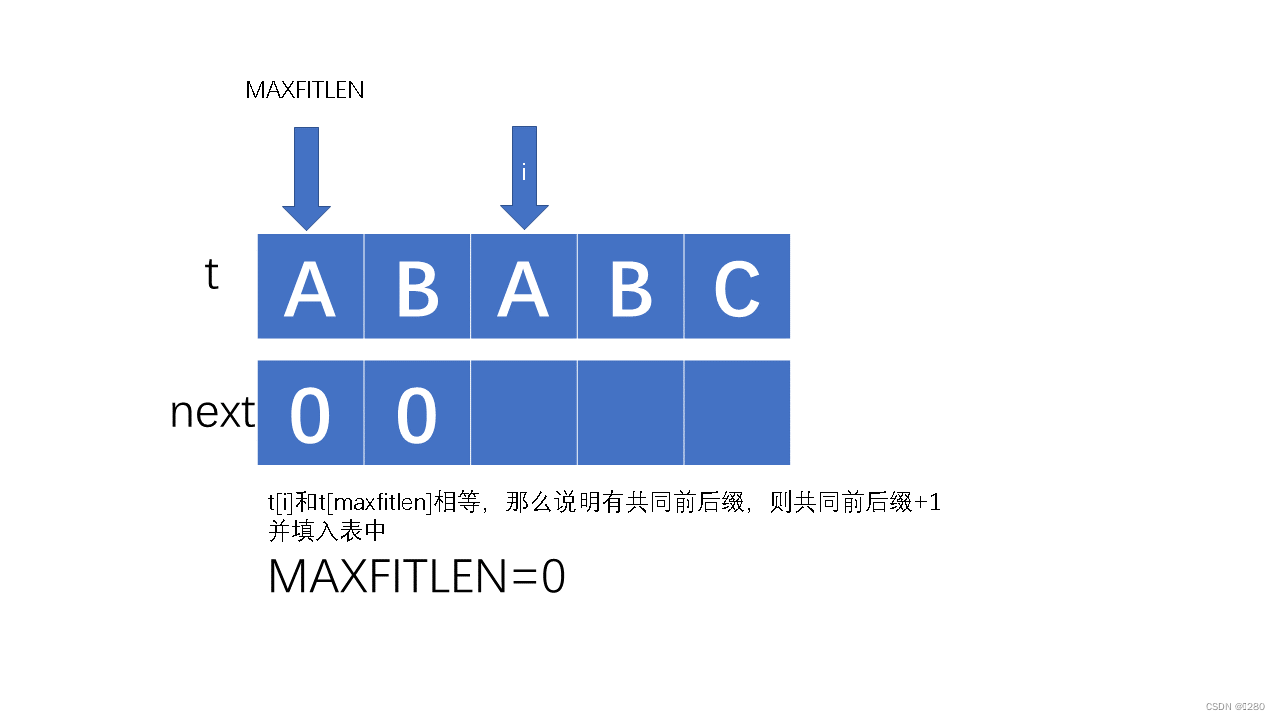
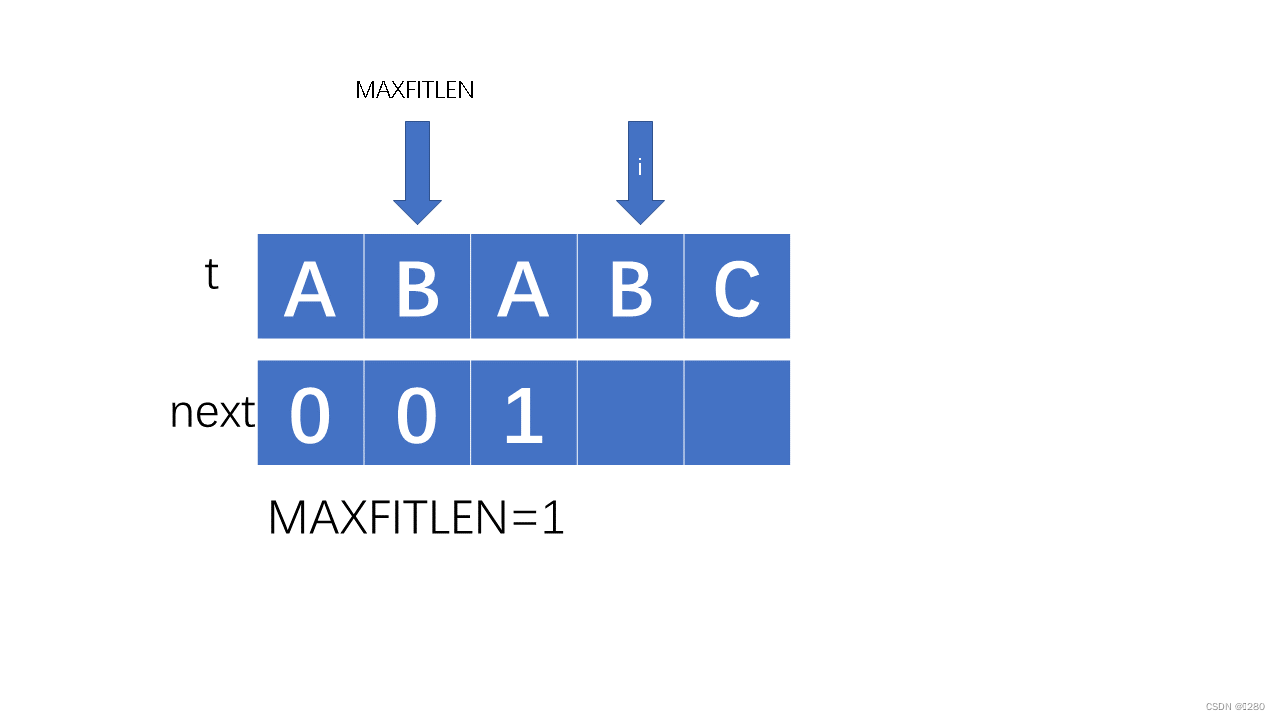
next的求解过程:
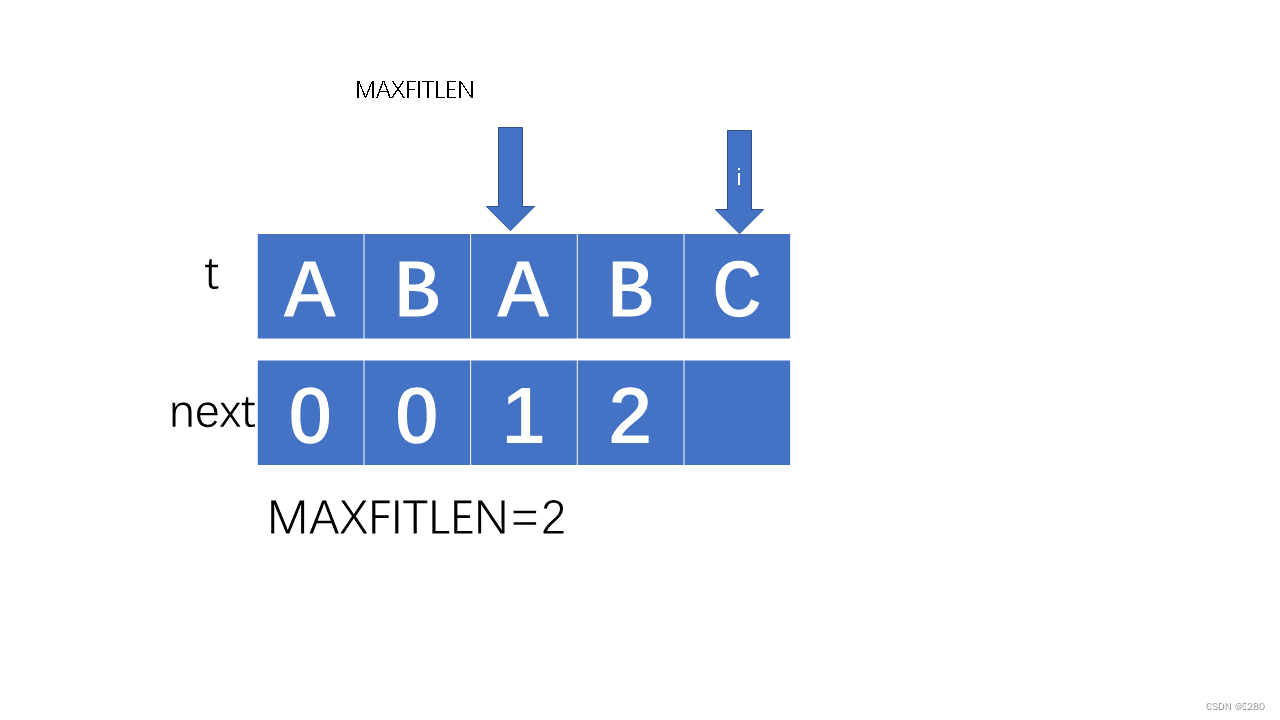
下面考虑一种情况,当我们遇到不相等,但是前面也有匹配项时
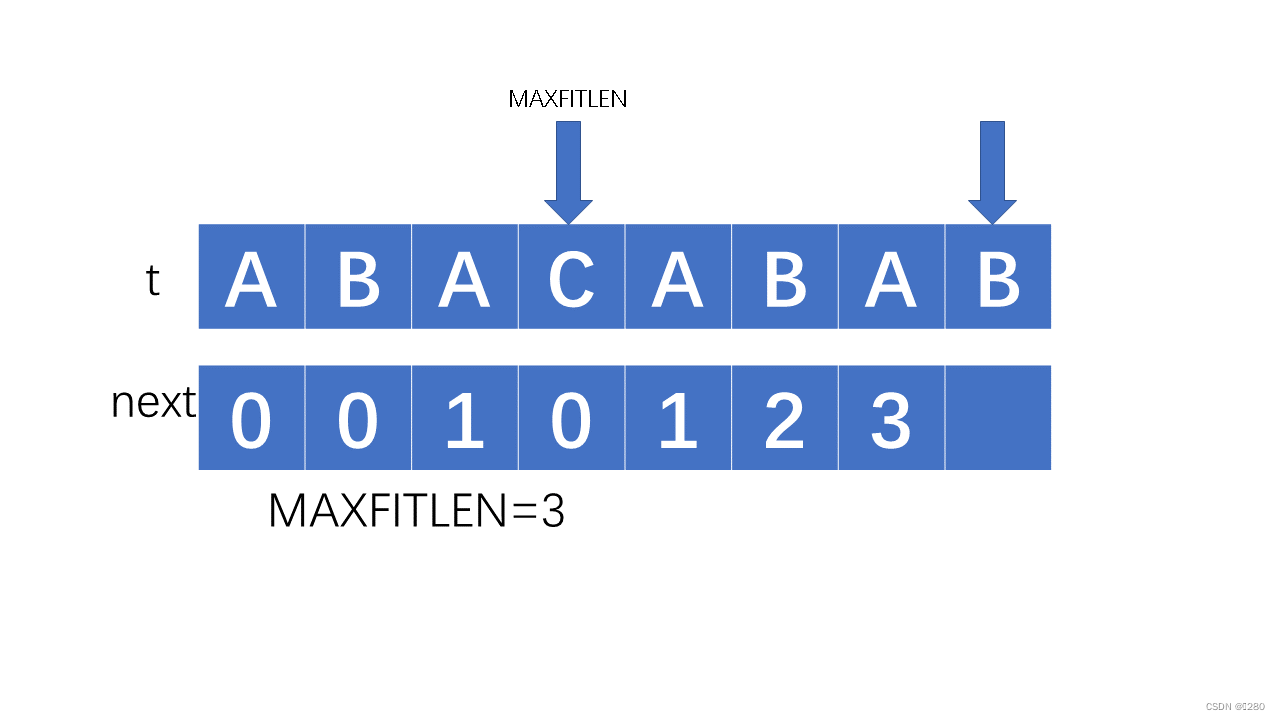
当我们匹配到有三个前缀时,发现下一个字符不匹配,我们该怎么做呢,如果我们直接按不匹配处理,那么会得到最长前后缀是0,这显然是不合理的,因为它存在最长前后缀AB,因此我们要通过什么办法才能找到它的最长公共前后缀呢,在next数组中我们存储的是最长公共前后缀的长度,也就是ABA在最前面也存在,我们要重新找最长公共前后缀,我们之前掌握了一个信息,就是在指针之前的ABA是一样的,他们也拥有一样的字符和前后缀,所以我们可以利用最长公共前后缀长度去访问之前的最长公共前后缀长度,即maxfitlen=next[maxfitlen-1]:

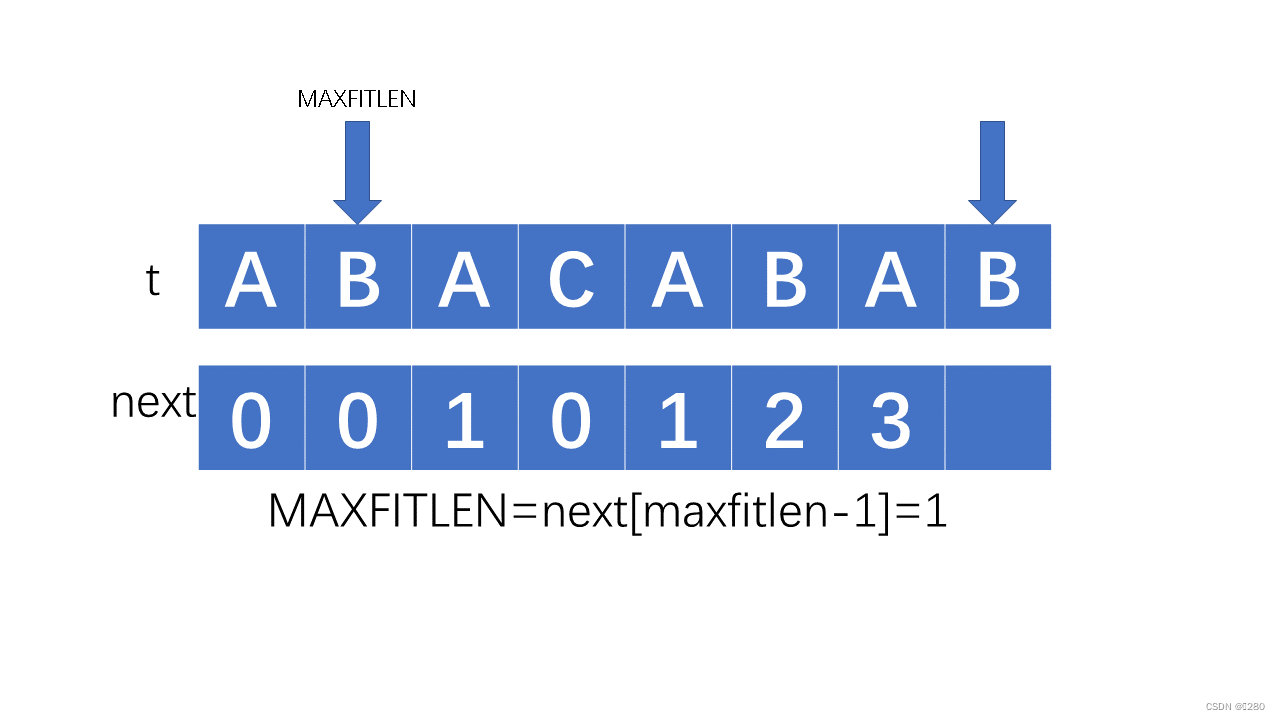
理解起来也就是可以看成,忽略我们之前不相等的部分,只看我们知道的相等的部分,按这种方式去求最长公共子前缀
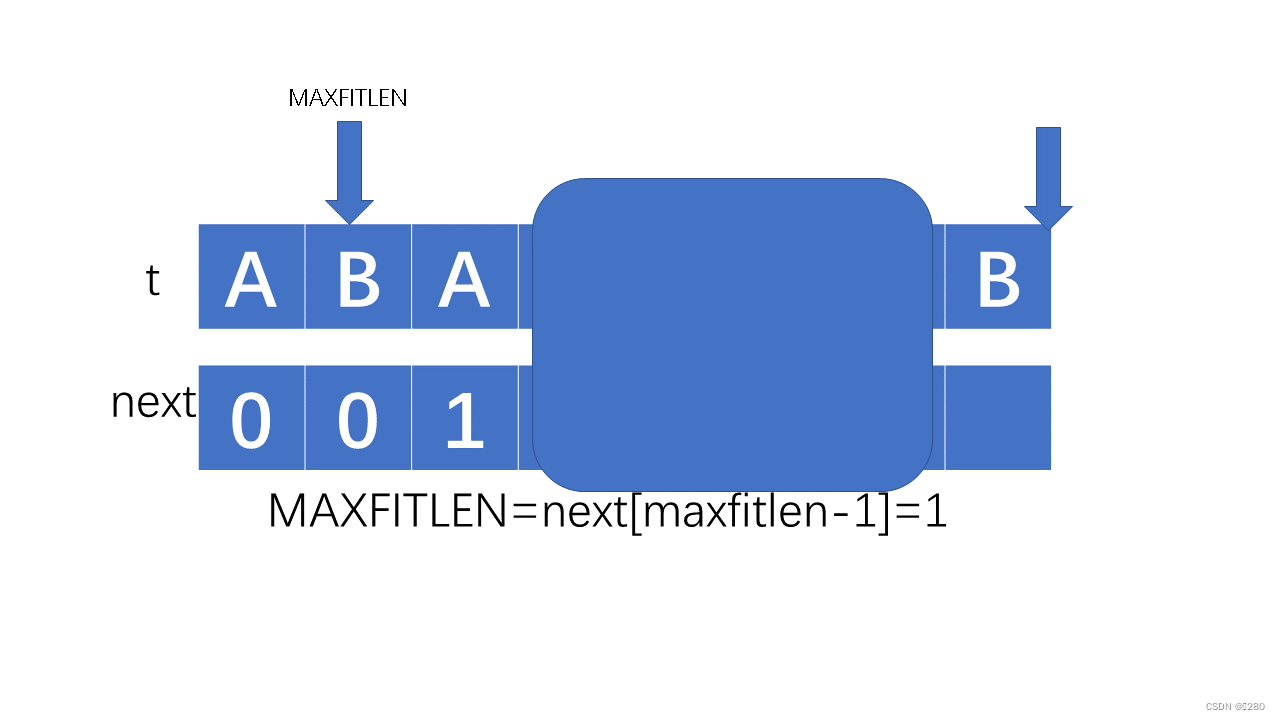
此时可以发现next[B]处匹配,填写的是maxfitlen+1=2
代码实现:
vector<int> getNext(string s){
vector<int> res;
res.push_back(0);//初始化第一个
int i=1,maxlen=0;
while(i<s.size()){
if(s[maxlen]==s[i]){//匹配移动
res.push_back(++maxlen);
i++;
}
else{
if(maxlen==0){//无相同情况
res.push_back(0);
i++;
}
else{//递归回去找到前缀第一个相同的,从前缀开始找
maxlen=res[maxlen-1];
}
}
}
return res;
}该算法的时间复杂度为O(m)
所以整体KMP算法的时间复杂度就为O(m+n),空间复杂度为O(m)















 646
646











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









