







哈夫曼树
-
结点的权:有某种显示含义的数值(如:表示结点的重要性等)
-
结点的带权路径长度:从树的根到该结点的路径长度(经过的边数)与该节点上权值的乘积。
-
数的带权路径长度:树种所有叶子结点的带权路径长度之 和(WPL,Weighted Path Length)
W P L = ∑ i = 1 n w i l i WPL=\sum_{i=1}^{n}{w_il_i} WPL=i=1∑nwili
在含有n个带权叶结点的二叉树中,其中带权路径长度(WPL)最小的二叉树称为哈夫曼树,也称最优二叉树
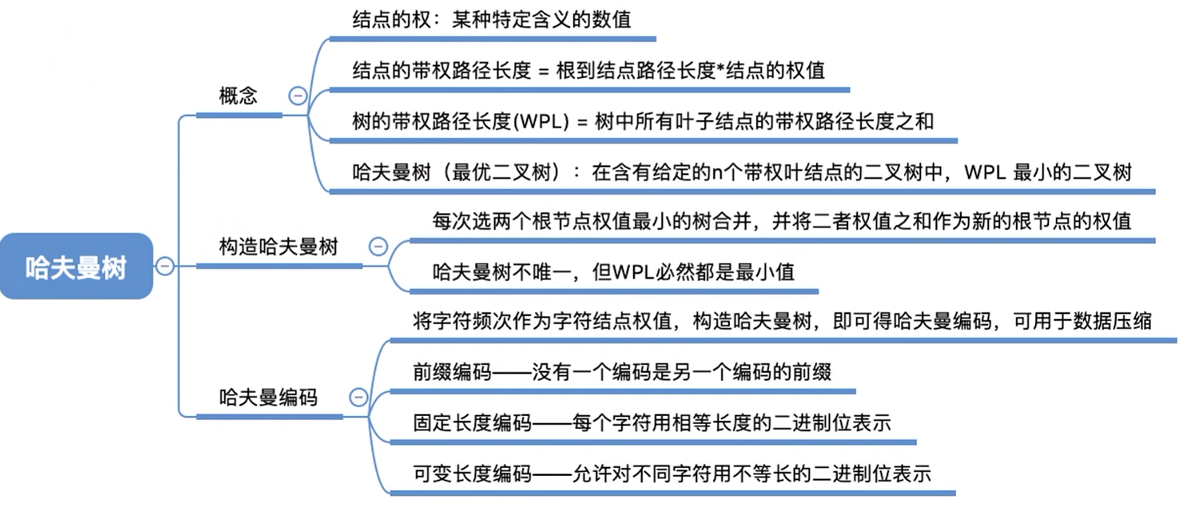
1. 构造哈夫曼树
给定n个权值分别为w1, w2…wn的结点,构造哈夫曼树的算法描述如下:
- 首先将这n个结点分别视作n棵仅含一个结点的二叉树,构成森林F。
- 在森林中选取两棵==根结点权值最小的树==作为新结点的左、右子树,并且将新结点的权值置为左、右子树上根结点的权值之和。
- 重复选树的过程,知道森林只剩下一棵树
下面是构建哈夫曼树的过程:
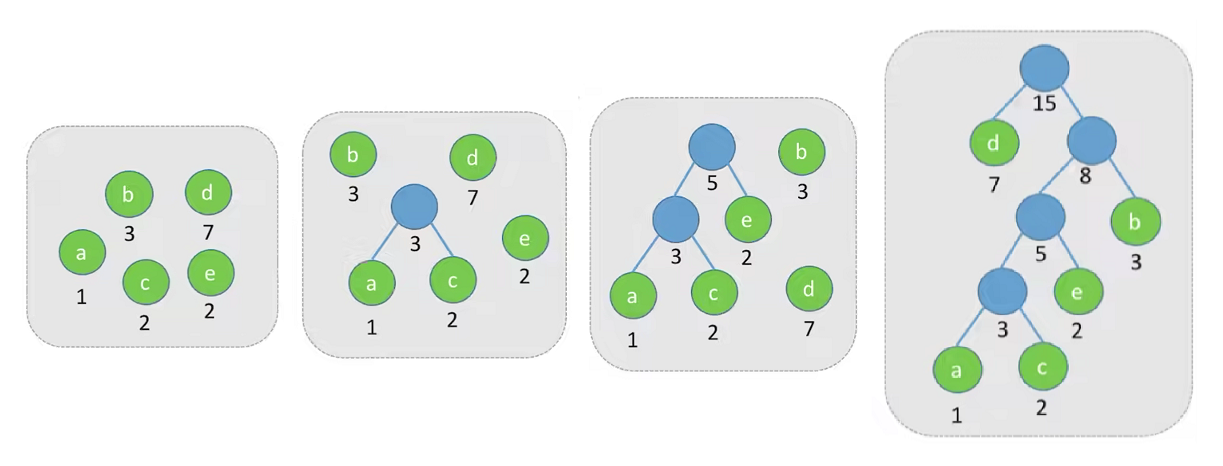
构建哈夫曼树的算法分析
-
初始化:首先动态申请2n个单元;然后循环2n-1次,从1号单元开始,依次将1至2n-1所有单元中的双亲、左孩子、右孩子的下标都初始化为0;最后循环n次,输入前n个单元中叶子节点的权值。
-
创建树:循环n-1次(就是选组n-1个根节点的过程),通过n-1次的选择、删除与合并来创建哈夫曼回树。
- 选择是从当前森林中选择双亲为0且权值最小的两个树根节点s1和s2;
- 删除是指将节点s1和s2的双亲改为非0;
- 合并就是将s1和s2的权值和作为一个新节点的权值依次存入数组的n+1号及之后的单元中,同时记录这个新节点左孩子的下标为s1,右孩子的下标为s2。
代码实现
typedef char BTDataType;
struct BTNode {
BTDataType data;
BTNode* left;
BTNode* right;
};
struct HTNode {
int weight;//权值
string word;
int parent, lchild, rchild;//双亲,左孩子,右孩子
};
struct Node {
string word;
int weight;
};
//找到当前森林里权值最小的两个节点对应在数组中的位置
void search(HTNode* root,int Number, int& x, int& y) {
int reference = INT_MAX;
for (int i = 1; i <= Number; i++) {
if (root[i].parent == 0 && root[i].weight < reference) {
x = i;
reference = root[i].weight;
}
}
reference = INT_MAX;
for (int i = 1; i <= Number; i++) {
if (root[i].parent == 0 && root[i].weight < reference && i != x) {
y = i;
reference = root[i].weight;
}
}
}
//哈夫曼树的根节点,num为哈夫曼树叶子节点--也就是数据的个数
void createHTree(HTNode*& root, int num) {
//n个叶子节点(数据),需要创建n-1个根节点,并且数组0号位置空出来
root = new HTNode[2 * num];
//将整个哈夫曼树双亲和孩子初值设置为0
for (int i = 0; i < 2*num; i++) {
root[i].lchild = 0;
root[i].rchild = 0;
root[i].parent = 0;
}
//将叶子节点(数据)放入哈夫曼树
for (int i = 1; i <num+1; i++) {
//输入哈夫曼树节点数据和权值
cin >> root[i].word;
cin >> root[i].weight;
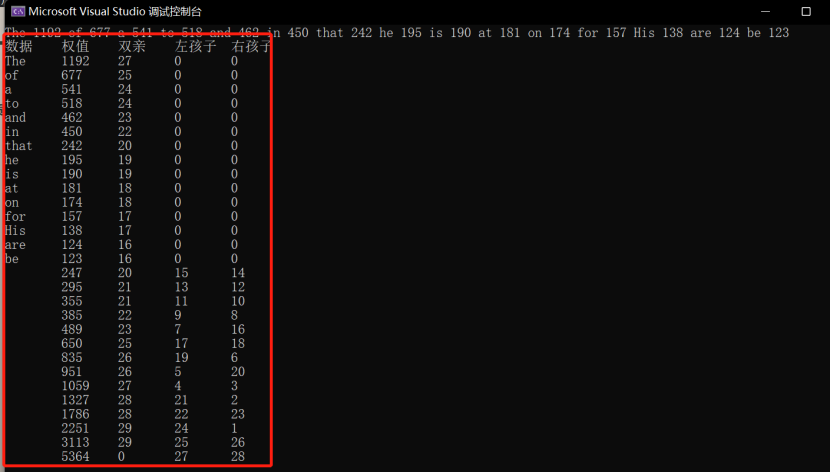
//这里有个例子,友友可以测试用:
//The 1192 of 677 a 541 to 518 and 462 in 450 that 242 he 195 is 190 at 181 on 174 for 157 His 138 are 124 be 123
}
//num+1到2*num为哈夫曼树根节点
for (int i = num + 1; i < 2 * num; i++)
{
int x , y ;
search(root, i-1, x, y);//找到当前森林里面权值最小的两棵树,返回小标x和y
//链接节点
root[i].weight = root[x].weight + root[y].weight;
root[x].parent = root[y].parent = i;
root[i].lchild = x;
root[i].rchild = y;
}
}
测试小案例
2. 哈夫曼树的性质
-
每个初始结点最终都成为叶结点,且权值越小的结点到根结点的路径长度越大
-
哈夫曼树的结点总数为
2n -1(n个结点构建哈夫曼树,会创建n-1个新结点,所以一共有2n-1个结点) -
哈夫曼树中不存在度为1的结点。
-
哈夫曼树并不唯一,但WPL必然相同且为最优(带权路径长度最小的树就是哈夫曼树,’最‘当然相等)
上面那道题另外一种构建哈夫曼树的方法为:
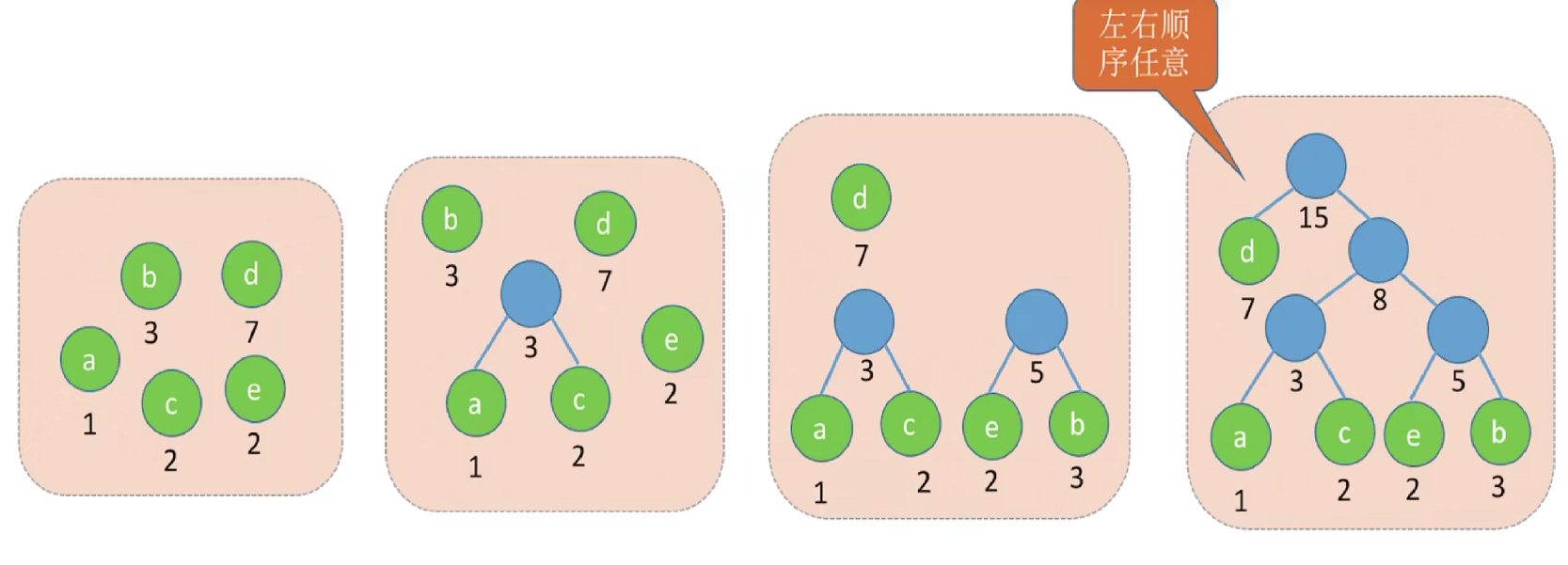
计算两棵哈夫曼树,会发现WPL的值一致
3. 哈夫曼编码
- 可变长度编码,对不同字符采用不等长的二进制位表示。
- 前缀编码:没有一个编码时另一个编码的前缀
用哈夫曼树得到的编码方案叫哈夫曼编码,并且哈夫曼编码时前缀编码
具体:对不同的字符赋予权值,就得到了带权的结点,相应构建哈夫曼树。每一个字符对应哈夫曼树的叶子结点,规定查找路径向左为编码1,向右为编码0。该叶子的查找路径就对应了字符的唯一编码。
下面时哈夫曼编码的案例:可以看到同一权值的结点能构造的哈夫曼树不唯一,对应的哈夫曼编码也是不唯一的!
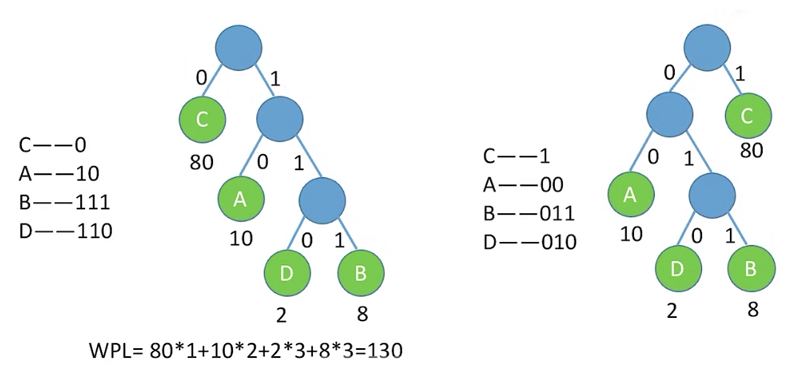
对使用频率高的字符赋予较高权值,对应哈夫曼树种权值高的结点查找路径更短,相应的编码也更短,从而实现文件压缩!
提到这里有人想说为什么非得用哈夫曼树?结点作为中间结点出现,也能对应唯一编码呀?但这样的编码并非前缀编码,当对一大段字符进行解码时,由于不是前缀编码,会出现解码歧义!如下,同一编码有两种解释
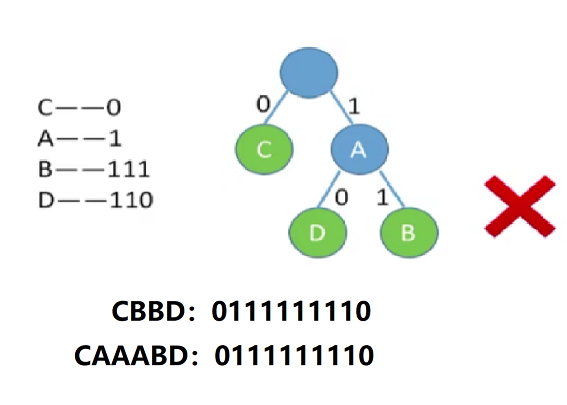















 1345
1345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









