







文章目录
为什么需要雪花算法
分布式系统中需要对数据进行唯一标识,也就是如何在分布式高并发场景下生成分布式全局唯一id?
1 分布式全局唯一id
分布式全局唯一id需满足
- 全局唯一
- 趋势递增:考虑到聚簇索引存储形式,要求主键有序来保证写入性能。某些业务场景也要求id递增,如事务版本号、IM增量消息、排序等特殊需求
- 信息安全:如果ID是连续的,恶意用户的扒取工作就非常容易做了,直接按照顺序下载指定URL即可;如果是订单号就更危险了,竞对可以直接知道我们一天的单量。所以需要ID不规则
- 含时间戳:这样就能够在开发中快速了解这个分布式Id的生成时间
- 低延迟,高QPS,高可用。能在高并发下稳定运行
2 UUID解决方案
UUID是一个32个十六进制字符串,分成5组显示,组与组之间用连字符“-”分开,格式为8-4-4-4-12的36个字符(包括连字符),例如:123e4567-e89b-12d3-a456-426614174000。
UUID能基于时间戳,随机数和MAC地址生成,算法设计高效但不能保证绝对唯一,存在
UUID不能很好的满足分布式全局唯一ID的特性
UUID本地生成性能好且唯一且高可用,但是UUID的无序性使得其作为主键写入回导致聚簇索引分裂,特别是数据量大时,写入性能不会乐观。
3 Redis解决方案
依靠Redis命令单线程特性,使用INCR或INCRBY命令就能实现分布式全局唯一ID
单Redis解决方案些缺点:服务端生成ID需要多一次和Redis交互,并且Redis中的id值需要保证不丢失,否则后续可能会出现重复ID
什么是雪花算法
上述解决方案都不如雪花算法解决方案
雪花算法是由 Twitter 开发的分布式 ID 生成算法,用于生成全球唯一的 64 位长整型 ID。它具有高性能、分布式支持以及趋势递增等特点,适用于大规模分布式系统。
1 雪花算法结构
雪花算法生成的 ID 是一个 64 位的二进制数,其中各个部分有特定的用途:
| 位数 | 含义 | 说明 |
|---|---|---|
| 1 | 符号位 | 固定为 0,ID 为正数 |
| 41 | 时间戳 | 精确到毫秒,表示当前时间与某个固定时间的差值 |
| 10 | 机器标识 | 包括数据中心 ID 和机器 ID,用于区分不同的节点 |
| 12 | 序列号 | 用于确保在同一毫秒内生成的 ID 是唯一的 |
总共是 64 位,其中:
-
1 位符号位:永远为 0,因为生成的 ID 是正数。
-
41 位时间戳:表示时间戳,通常是当前时间减去一个基准时间(通常是系统开始运行的时间),表的时间范围大约 69 年
-
10 位机器标识:5 位的数据中心 ID 和 5 位的机器 ID,保证在分布式系统中,不同的机器可以生成唯一的 ID
-
12 位序列号:用于标识同一毫秒内生成的不同ID。通过序列号 1 毫秒可以产生 4096 个不重复 ID,则 1 秒可以生成
4096 * 1000 = 409wID序列号生成逻辑:每次生成记录当前时间戳,若当前时间戳与上次生成 ID 的时间相同,序列号加 1,否则置0
默认的雪花算法是 64 bit,具体的长度可以自行配置。如果希望运行更久,增加时间戳的位数;如果需要支持更多节点部署,增加标识位长度;如果并发很高,增加序列号位数。
总结:雪花算法具体实现可以根据系统内具体场景进行定制,甚至雪花ID结构也能定制
2 雪花算法原理
了解即可
- 时间戳:生成 ID 时,首先获取当前的时间戳(以毫秒为单位)
- 机器标识:在分布式环境中,每个机器或者节点会有唯一的机器标识符,通常包括数据中心 ID 和机器 ID,用于区分不同节点生成的 ID
- 序列号:同一毫秒内多个请求生成 ID,每次生成ID记录当前时间戳,若当前时间戳与上次生成 ID 的时间相同,序列号加 1,否则置0。如果序列号超过 4096,系统会等待下一毫秒
- 组合 ID:将时间戳、机器标识和序列号组合成 64 位的长整型值,形成一个唯一的 ID。整个过程完全在本地进行,无需依赖外部存储系统
3 雪花算法优缺点
雪花算法生成的ID能很好的满足前面说的分布式全局唯一id需要满足的特点,唯一性,递增性,高性能等
雪花算法的缺点:依赖时间且有时间限制:由于时间戳占 41 位,只能表示约 69 年的时间范围,因此对于长生命周期的系统来说,需要重新设计或调整时间戳基准。(缺点不值一提)
如何生成雪花ID
MyBatis-Plus和hutool都有实现雪花算法,具体应用时可以定制,甚至引入开源框架完成
雪花ID默认结构
-
1 位符号位:永远为 0,因为生成的 ID 是正数
-
41 位时间戳:表示时间戳,通常是当前时间减去一个基准时间(通常是系统开始运行的时间),表的时间范围大约 69 年
-
10 位机器标识:5 位的数据中心 ID 和 5 位的机器 ID,保证在分布式系统中,不同的机器可以生成唯一的 ID
-
12 位序列号:通过序列号 1 毫秒可以产生 4096 个不重复 ID,则 1 秒可以生成 4096 * 1000 = 409w ID
序列号生成逻辑:每次生成记录当前时间戳,若当前时间戳与上次生成 ID 的时间相同,序列号加 1,否则置0
单服务实例,雪花算法的时间戳和序列号已经能保证雪花算法的雪花ID不重复,因为就单机而言,如果并发过高,单台机器单秒生成雪花ID超过序列号标识范围就会等待下一秒。但是对于高并发下的分布式系统,可能存在多服务同时生成雪花ID,也就是多服务可能在同一毫秒生成雪花ID,也即时间戳和序列号可能一致,所以必须严格保证机器标识不一致,这样才能保证雪花ID唯一
所以关键在于如何获取机器标识??
1 MyBatis-Plus如何获取机器标识
MyBatis-Plus中的雪花算法集中在实现类Sequence中
机器标识由数据中心ID和工作ID两部分组成
第一部分:数据中心ID
protected static long getDatacenterId(long maxDatacenterId) {
long id = 0L;
try {
InetAddress ip = InetAddress.getLocalHost();
NetworkInterface network = NetworkInterface.getByInetAddress(ip);
if (network == null) {
id = 1L;
} else {
byte[] mac = network.getHardwareAddress();
if (null != mac) {
id = ((0x000000FF & (long) mac[mac.length - 2]) | (0x0000FF00 & (((long) mac[mac.length - 1]) << 8))) >> 6;
id = id % (maxDatacenterId + 1);
}
}
} catch (Exception e) {
logger.warn(" getDatacenterId: " + e.getMessage());
}
return id;
}
解析:
- 通过
InetAddress.getLocalHost()方法获取当前机器的本地IP地址 - 通过
NetworkInterface.getByInetAddress(ip)获取与该IP地址关联的网络接口(网卡)。如果机器有多个网卡,它将返回与该IP地址相关联的那一个。 - 如果
network为null,则说明没有找到与本地IP地址关联的网络接口,默认将id设置为 1。 - 如果找到网络接口,且
mac地址不为空,则进行以下操作:- 获取MAC地址:
network.getHardwareAddress()返回该网络接口的MAC地址,存储在mac数组中。 - 计算ID
(0x000000FF & (long) mac[mac.length - 2]):取MAC地址倒数第二个字节,并通过与0xFF按位与操作获取该字节的无符号值。(0x0000FF00 & (((long) mac[mac.length - 1]) << 8)):取MAC地址最后一个字节,并左移8位以填充为高8位。- 将上述两部分进行按位或运算得到一个16位的数,然后右移6位(
>> 6),以获取数据中心ID的基础值。
- 取模操作:通过
id % (maxDatacenterId + 1)确保最终的datacenterId在合法范围内,即不会超过maxDatacenterId。
- 获取MAC地址:
关于
getDatacenterId方法的入参maxDatacenterId是固定的,如下private final long datacenterIdBits = 5L; private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
-1L:这是一个 long 类型的值,其二进制形式是所有位都是 1(即111111...1111)。
-1L << datacenterIdBits:这是对-1L左移 5 位(即datacenterIdBits),左移后的结果在二进制中会是111111...11100000
^:按位异或操作。对-1L与(-1L << 5)进行按位异或,结果是在-1L左移 5 位后产生的前 5 位变为 0,后 5 位保持为 1,即000000...11111很巧妙地获得了指定bit位的最大值!
第二部分:工作ID
protected static long getMaxWorkerId(long datacenterId, long maxWorkerId) {
StringBuilder mpid = new StringBuilder();
mpid.append(datacenterId);
String name = ManagementFactory.getRuntimeMXBean().getName();
if (StringUtils.isNotBlank(name)) {
/*
* GET jvmPid
*/
mpid.append(name.split(StringPool.AT)[0]);
}
/*
* MAC + PID 的 hashcode 获取16个低位
*/
return (mpid.toString().hashCode() & 0xffff) % (maxWorkerId + 1);
}
datacenterId就是上一个方法获取地数据中心ID,而maxWorkderId其实也是固定值:
private final long workerIdBits = 5L;
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
获取工作ID地方法解析:
- 创建
StringBuilder实例,将传入的datacenterId附加到mpid字符串中 - 获取 JVM 进程名称:通过
ManagementFactory获取 JVM 的运行时信息,并提取进程名称。这通常包括进程 ID - 附加进程ID:使用
@字符分隔进程名称,通常第一个部分是进程 ID,将其附加到mpid。这里使用StringPool.AT表示@符号,通常是一个常量值
生成 Worker ID
- 计算
hashCode:将mpid转换为字符串并计算其哈希码 - 掩码操作:使用
& 0xffff获取哈希码的低 16 位。这是为了确保生成的 ID 在 0 到 65535 之间 - 取模操作:最后,通过
% (maxWorkerId + 1)确保 Worker ID 在允许的范围内(0 到maxWorkerId)
2 如何保证机器标识唯一
回顾:单服务实例,雪花算法的时间戳和序列号已经能保证雪花算法的雪花ID不重复,因为就单机而言,如果并发过高,单台机器单秒生成雪花ID超过序列号标识范围就会等待下一秒。但是对于高并发下的分布式系统,可能存在多服务同时生成雪花ID,也就是多服务可能在同一毫秒生成雪花ID,也即时间戳和序列号可能一致。所以保证分布式环境机器标识唯一才能保证分布式雪花ID唯一
Mybatis-Plus 标识位的获取依赖 Mac 地址和进程 PID,分布式多机器部署保证MAC地址唯一,即使运行在相同机器进程PID也唯一。所以MyBatis-Plus能保证分部署雪花ID唯一?不不不
MAC地址48位二进制,由制造商分配保证全球唯一,但是某些设备或操作系统(如Linux)允许用户修改MAC地址,称为“MAC地址伪装”或“MAC地址更改”,比如使用VM克隆虚拟机的时候就需要手动填写MAC地址。所以虽然设备原始MAC地址全球唯一,但是手动修改后依旧MAC存在冲突风险。所以Mybatis-Plus的生成的分布式雪花ID依旧存在冲突风险!
解决方案如下:
2.1 预分配
应用上线前,统计当前服务的节点数,人工去申请标识位。
此方案没有代码开发量,在服务节点固定或者项目少可以使用,但是解决不了服务节点动态扩容性问题
2.2 动态分配
将机器标识存放在 Redis、Zookeeper、MySQL 等中间件,在服务启动的时候去请求机器标识,请求后标识位更新为下一个可用的
服务的节点数超过
1024,则需要做额外的扩展;可以扩展 10 bit 标识位,或者选择开源分布式 ID 框架。
2.2.1 Redis 动态分配机器标识
Redis 存储一个 Hash 结构 Key,包含两个键值对:dataCenterId 和 workerId
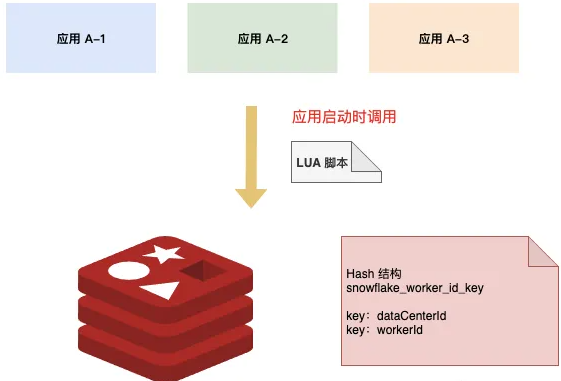
在应用启动时,通过 Lua 脚本去 Redis 获取标识位。dataCenterId 和 workerId 的获取与自增在 Lua 脚本中完成,调用返回后就是可用的标示位
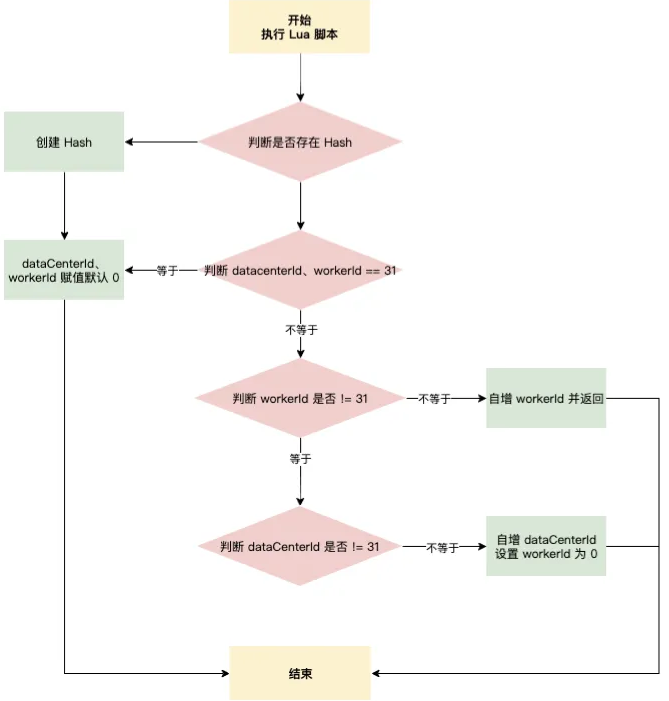
逻辑总结:
dataCenterId和workId都为31则全部置为0返回workId不为31,自增返回dataCenterId不为31,自增返回、
2.2.2 Redis+MyBatis-Plus+Lua优化方案
lua脚本文件luaScript.lua(类路径resources下)
local id = redis.call('INCR', KEYS[1])
if tonumber(id) < 32 then
return tonumber(id)
else
redis.call('SET', KEYS[1], 0)
return 0
end
代码参考
import com.baomidou.mybatisplus.core.incrementer.IdentifierGenerator;
import com.baomidou.mybatisplus.core.toolkit.Sequence;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.core.io.ClassPathResource;
import org.springframework.core.io.Resource;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.script.DefaultRedisScript;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.Collections;
@Component
public class CustomIdGenerator implements IdentifierGenerator {
@Autowired
private RedisTemplate redisTemplate;
private Sequence mySequence;
public CustomIdGenerator(RedisTemplate redisTemplate) throws IOException {
// 初始化时,设置 workerId 和 datacenterId 的初始值
redisTemplate.opsForValue().setIfAbsent("workerId", 0); // 如果没有 workerId,则设置初值为 10
redisTemplate.opsForValue().setIfAbsent("datacenterId", 0); // 如果没有 datacenterId,则设置初值为 1
//读取lua脚本文件
Resource resource = new ClassPathResource("luaScript.lua");
String luaScript = new String(Files.readAllBytes(Paths.get(resource.getURI())));
// 获取并自增 workerId
Long workerId = (Long)redisTemplate.execute(
new DefaultRedisScript<>(luaScript, Long.class), // 将 Lua 脚本与返回类型绑定
Collections.singletonList("workerId") // KEYS 参数
);
// 获取并自增 datacenterId
long datacenterId = (Long)redisTemplate.execute(
new DefaultRedisScript<>(luaScript, Long.class), // 将 Lua 脚本与返回类型绑定
Collections.singletonList("datacenterId") // KEYS 参数
);
System.out.println("====================================");
//输出lua脚本内容
System.out.println("luaScript = " + luaScript);
// 打印 workerId 和 datacenterId
System.out.println("workerId = " + workerId);
System.out.println("datacenterId = " + datacenterId);
System.out.println("====================================");
// 创建 Sequence 对象,用于生成 ID
mySequence = new Sequence(workerId, datacenterId);
}
@Override
public Long nextId(Object entity) {
return mySequence.nextId();
}
}
dataCenterId、workerId是一直向下推进的,总体形成一个环状。通过 Lua 脚本的原子性,保证 1024 节点下的雪花算法生成不重复。如果标识位等于 1024,则从头开始继续循环推进。
3 开源分布式ID框架
Leaf 和 Uid 都有实现雪花算法,Leaf 额外提供了号段模式生成 ID。
美团 Leaf:https://github.com/Meituan-Dianping/Leaf
百度 Uid:https://github.com/baidu/uid-generator
雪花算法可以满足大部分场景,如无必要,不建议引入开源方案增加系统复杂度。

















 3801
3801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









