







前言
前段时间阅读自监督去噪的Noise2Noise方法,收获了很多,将其应用到医学图像中也有较好的效果,经过自己的验证后,写一些心得。
论文:https://arxiv.org/pdf/1803.04189
在论文专栏会更新有关Noise2Noise的内容
论文主要解决的问题是在缺乏干净数据的情况下,如何学习图像恢复。传统上,图像恢复或去噪任务通常依赖于大量的干净图像及其对应的噪声版本进行模型训练。然而,这篇论文提出了一种新颖的方法,允许模型仅通过分析含噪图像对来学习去除噪声,利用含有不同噪声水平或类型的两幅或多幅图像,它们虽各自含噪,但反映的是相同场景或对象。
dwi医学图像去噪
思路:
受到论文的启发,Noise2Noise 可以处理同一b值下不同梯度方向的扩散加权成像(Diffusion Weighted Imaging, DWI)数据采集。DWI是一种磁共振成像(MRI)技术,用于评估组织中水分子的扩散性质,常用于神经科学、肿瘤学等领域,尤其是脑部结构和病理状态的研究。
当对同一区域进行多次扫描,每次采用相同b值但改变梯度方向时,尽管每次扫描都会引入一定的噪声(如热噪声、运动伪影等),这些扫描图像本质上反映的是相同解剖结构的扩散特性。因此,即使没有“干净”的参考图像,这些含噪的DWI图像对仍然可以作为Noise2Noise算法的输入。在同一b值下采集的多方向DWI图像序列,即使各自含有不同的随机噪声,但反映的是相同场景,可以使用N2N方法进行尝试去噪。
数据处理:
使用HCP Young Adult - Connectome - Publications,筛选同一b值下q空间向量余弦相似度最接近的数据(三维数据)作为输入(即noise图像对),最近研究的是单b值图像,故提前进行数据处理b=1000和b=5(可看作b0图像,可以最后做验证使用)附近的数据提取出来作为新的数据。
找出b1000和b0图像:
def get_groups_by_b_threshold(b_values, gradient_directions):
# 初始化字典,分别存储b值大于5和小于等于5的梯度向量及索引
gradient_groups = {"b1000": [], "b0": []}
b_indices = {"b1000": [], "b0": []}
b_index = 0
for b_val, gradient_dir in zip(b_values, gradient_directions):
# 判断b值大小并添加到相应的字典中
temp = b_val > 5
condition="b1000" if temp else "b0"
gradient_groups[condition].append(gradient_dir) # 存梯度
b_indices[condition].append(b_index) # 存索引
b_index += 1
#print("梯度向量",gradient_groups)
#print("索引",b_indices)
return gradient_groups,b_indices匹配数据对:
def find_target(gradients, indices):
# 计算余弦相似度矩阵
similarity_matrix = np.zeros((len(gradients), len(gradients)))
for i, vec_i in enumerate(gradients):
for j, vec_j in enumerate(gradients):
similarity_matrix[i, j] = np.dot(vec_i, vec_j) / (np.linalg.norm(vec_i) * np.linalg.norm(vec_j))
nearest_match = []
for i in range(len(gradients)):
max_sim_index = np.argmax(similarity_matrix[i]) # 先找到最大相似度的索引
if max_sim_index == i: # 如果是自己,则找第二大的
similarity_matrix[i, i] = -1
max_sim_index = np.argmax(similarity_matrix[i])
nearest_match.append((indices[i], indices[max_sim_index]))
return nearest_match找出干净数据,噪声对
def find_pair_data(data_array,index_match,b_indices):
noise1_index = [aim[0] for aim in index_match]
noise2_index=[aim[1] for aim in index_match]
b0_index = b_indices['b0']
noise1 = data_array[:, :, :, noise1_index]
noise2 = data_array[:, :, :, noise2_index]
clean = data_array[:, :, :, b0_index]
return clean,noise1,noise2由于Noise2Noise论文中处理的rgb图像,3通道,故需要修改最初的通道数(我们的数据处理输入为1通道),且我们的数据为四维数据,需要进行维度变化
def resize_dwi(data):
data_size = np.prod(data.shape)
new_shape = (72, 72, -1) # 新的形状
# 计算第三个维度的大小
third_dim = data_size // (new_shape[0] * new_shape[1])
# 确保能够整除,调整第三个维度的大小
new_shape = (new_shape[0], new_shape[1], third_dim)
dataed = np.resize(data, new_shape)
#print('data_train shape: ', dataed.shape) # (72, 72, n*518)
return dataed网络结构:
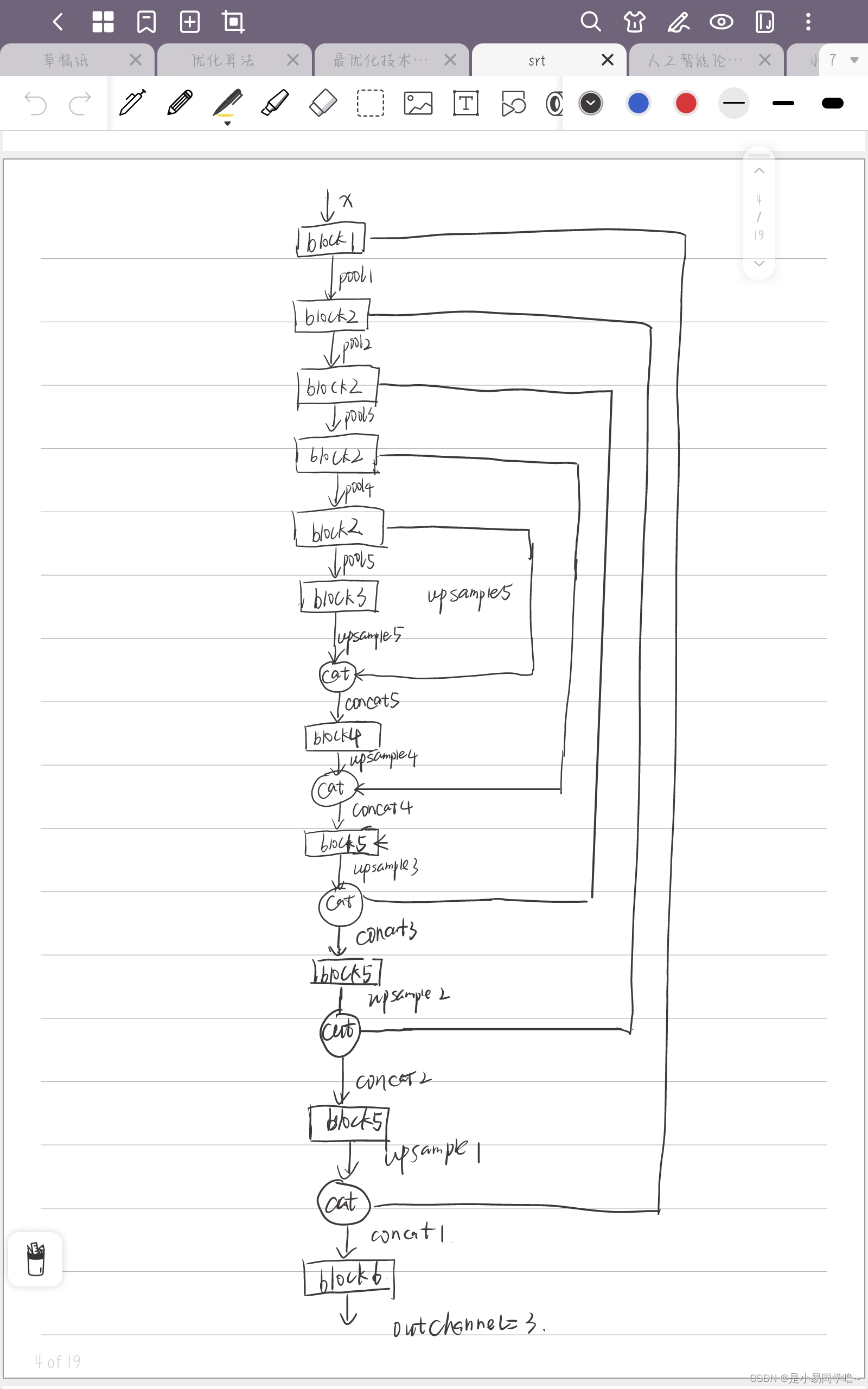
N2N的网络没有改动,如下为网络示意图(只在最初的输入通道处有改动)
训练和测试:
将含噪图像对输入模型,模型尝试预测另一张含噪图像,尽管两者都含有噪声,但模型学习的是去除或减少噪声的共同结构。通过反向传播和梯度下降(optim),不断调整网络权重以减小预测误差。最后保存模型
for batch_idx, (noise1_input, noise2_target) in enumerate(train_loader):
# noise1_input : (batch_size,72,72) class 'torch.Tensor'>
# noise2_target : (batch_size,72,72) class 'torch.Tensor'>
batch_start = datetime.datetime.now()
noise1_input = noise1_input.unsqueeze(1) # (batch_size,channel,72,72)
if self.use_cuda:
noise1_input = noise1_input.cuda()
noise2_target = noise2_target.cuda()
denoise_sclie = self.model(noise1_input)
denoise_sclie = denoise_sclie.squeeze(1) # 剔除第2个维度 (batch_size,72,72)
loss = self.loss(denoise_sclie, noise2_target)
# compute psnr
denoise_sclie = denoise_sclie.cpu()
noise2_target = noise2_target.cpu()
ps = psnr(noise2_target, denoise_sclie) # psnr 去噪与noise2
self.optim.zero_grad() # 清空梯度
loss.backward() # 反向传播
self.optim.step() # 更新参数
loss_meter.update(loss.item()) #
psnr_meter.update(ps)
time_meter.update(self.time_elapsed_since(batch_start)[1])
# self.avg_loss_list.append(loss_meter.avg)
self.show_on_report(batch_idx, num_batches, train_loss_meter.avg, time_meter.avg,
psnr_meter.avg) # 打印训练状态
train_loss_meter.update(loss_meter.avg)
loss_meter.reset()
time_meter.reset()
# 训练一个nii文件,保存一次模型.pt
self._on_epoch_end(stats, train_loss_meter.avg, epoch, psnr_meter.avg)
train_loss_meter.reset()
psnr_meter.reset()测试时使用独立于训练集的含噪测试图像对模型进行评估,这些图像应反映训练数据的噪声特性,但不包含在训练集中,打印评价指标峰值信噪比(PSNR)、结构相似度指数(SSIM)
for batch_idx, (origin_data_sclie) in enumerate(test_loader):
print(f" -----> {batch_idx} / {nums}", end="\r")
origin_data_sclie = origin_data_sclie.unsqueeze(1) # (batch_size,channel,72,72),有顺序的抽出
if self.use_cuda:
origin_data_sclie = origin_data_sclie.cuda()
denoise_sclie = self.model(origin_data_sclie) # (batch_size,channel,72,72)
denoise = denoise_sclie.squeeze(1) # (batch_size,72,72)
denoise = denoise.permute(1, 2, 0) # (72,72,batch_size)
denoise = denoise.detach().cpu().numpy()
if flag:
flag = False
output_nii = denoise
else:
output_nii = np.append(output_nii, denoise, axis=-1)
# 3维数据转换为原来的4维 (72,72,*)
print("---------------------------------")
# print(output_nii.shape, origin_array.shape)
save_array = resize_back(output_nii, origin_array.shape) # (144,168,111,N)
print("save_array:", save_array.shape) # (144,168,111,n)
# psnr,ssim
psnr, ssim = PSNR_SSIM(origin_array, save_array)
print(f"psnr {psnr:.2f} ssim: {ssim:.5f}")
# 定义保存文件的路径
nii_name_str = ''.join(re_nii_name)
nii_gz_save_path = os.path.join(save_path, "denoised_" + nii_name_str) # 保存为压缩的 .nii.gz 格式,也可以选择其他格式
save_nifti_gz(nii_gz_save_path, save_array, affine)
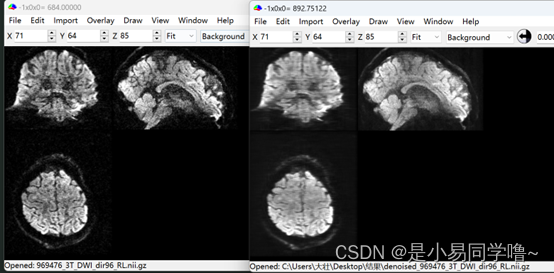
print("save nifti has finished,+", nii_gz_save_path)结果:
可以看到原图中很多黑点被去除

总结:
本实验成功展示了Noise2Noise方法在处理同一b值下不同梯度方向的DWI图像时的高效性和有效性。通过自监督学习,我们不仅绕过了对无噪声图像的需求,而且提升了DWI图像的信噪比,为后续的临床分析和科研探索提供了更为准确和可靠的图像资源。
心得:
先前尝试的方法将其中一个维度作为通道数发现效果非常不好,于是我们转换思路将思维数据转换维度,发现没有变形,psnr和ssim效果也还不错,很开心。

















 608
608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









