






双序遍历建立二叉树有三种:先序和中序,后序和中序以及层次和中序,如果仅是让我们手写出结果,在数据量不大的情况下还是简单的,但是写代码就需要一个清晰的思路了。
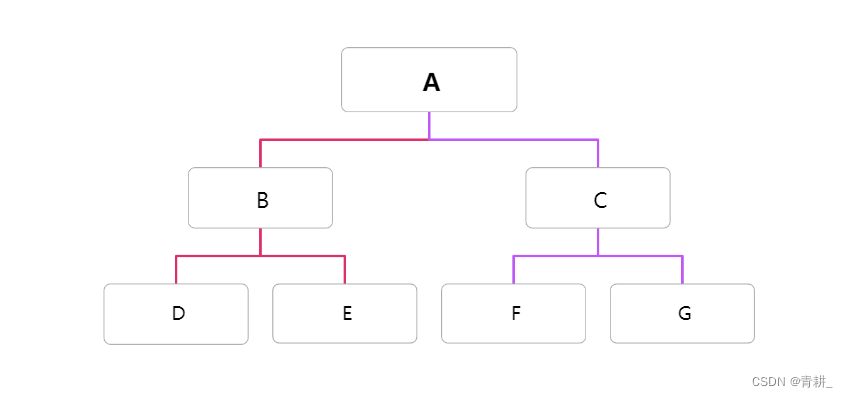
我们以这个二叉树为例进行演示。
先序:ABDECFG
后序:DEBFGCA
中序:DBEAFCG
层次:ABCDEFG
目录
先序和中序
先序:根左右
中序:左根右
先序:ABDECFG
中序:DBEAFCG
分析
中序遍历给出的信息是,节点的左子树元素都在该节点的左边,右子树元素都在该节点的右边,但是其左边元素并不一定都是其左子树元素,右边也是如此,此外,我们不难发现,在中序遍历中其左子树元素是连续的,所以,只要我们知道其左子树的元素个数,我们就可以知道其左子树所有的元素,然后层层递归,我们就可以将这个树建立出来。
在先序遍历中,父节点总是在子节点之前,对于一个节点,我们只要遍历中序遍历结果,找到该节点位置,再根据先序遍历得到的他的父节点并在中序遍历中找到父节点的位置,我们就可以确定以该节点为根节点的子树在中序遍历的范围(看不懂没事,下面的清晰)。
思路:
1.首先我们可以根据先序遍历找到根节点元素并建立根节点
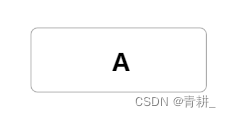
2.我们建立A的左子树
先看中序遍历,A的位置(从0开始计数)在第3位,且A为根节点,这意味着前三位都为其左子树元素,然后再看先序遍历的第1位为B,我们可以得到结论,B为A的左孩子元素。
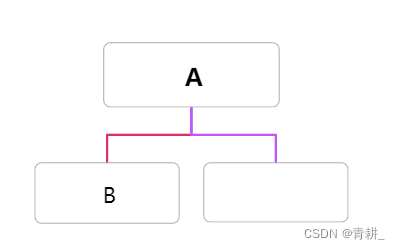
3.建立B的左子树
也是先看中序遍历,B的位置在第1位,其父节点位置在第3位,这就意味着,以B为根节点的子树的中序遍历是从第0位到第2位这三个元素,其左子树元素只有一个,再对比先序遍历的下一位也正是D(如果不一样就代表数据出错了),所以其左孩子就是D。
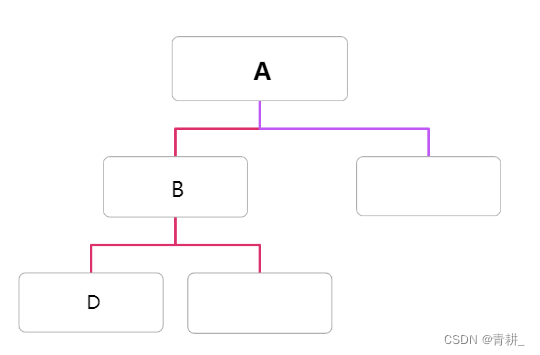
4.建立D的子树,我们根据中序遍历可以得到以D为根节点的子树的元素个数为1,这就意味着仅有D一个节点,返回上一层B。
5.建立B的右子树
同第3步,我们知道B右子树元素也只有一个为E,先序遍历的下一位也是E,所以我们直接就可以得到E为B的左孩子。
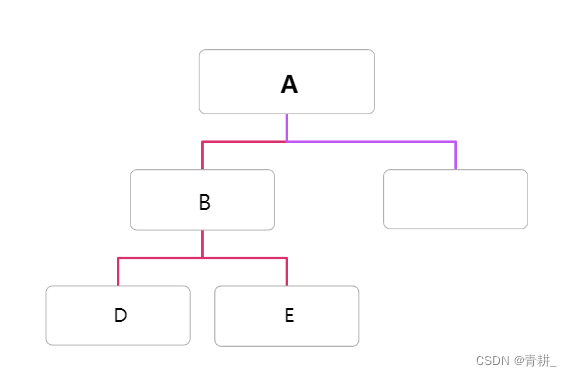
6.同样,我们根据中序遍历可以得到以E为根节点的子树的元素个数为1,这就意味着仅有E一个节点,返回上一层B,B的左右子树建立完成,直接返回到A。
7.A右子树的建立过程也是一样的,不再过多赘述。
代码思路:
根据上面的思路我们很容易会想到要用递归来做,但我们还需要确定递归的参数:
首先肯定是要有先序遍历和中序遍历的结果,分别记为s1,s2。
然后我们上面一直在提到范围,即以当前节点为根节点的子树的中序遍历在原中序遍历结果中的范围,这也是我们递归所要传递的参数,记为i1,i2。
再就是我们需要知道当前节点在先序遍历的位置,才能对新节点赋值,并确定下一节点的数据。所以我们需要接收一个参数用来确定这个位置,记为p1。
上面说到,我们递归到无左右子树的节点时,需要进行一个判断才能返回,即以该节点为根节点的子树仅有一个元素,这个命题有很多等价的命题,比如:
1.我们如果是创建左子树,我们就传递左子树的元素个数,若为1,我们建完新节点后就可以直接返回,右子树也是一样
2.也可以是看中序遍历,如果是建立左子树,我们看其左边是否还有元素,其右边是否是其父节点元素,也可以判断是否可以直接返回。
但是在我的代码中,我选择的判断条件是,在先序遍历中,以该节点为根节点的子树起始位置和终止位置是否一样,若是一个,也代表着以该节点为根节点的子树仅有其一个元素。而起始位置其实就是前面的p1,我们只需要在传递一个先序遍历中的终止位置就可以了,记为p2。
整理一下,我们可以得到每一层递归的代码思路:
1.新建节点p,根据存储s1[p1]的数据。
2.判断是否可以直接返回,若不可以进行下一步。
3.遍历中序遍历结果,找到s1[p1]的位置a。
4.根据当前的i1,i2来计算p左右子树的元素个数leftlen,rightlen。
5.建立p的左右子树,范围根据a,leftlen,rightlen,a,p1,p2,i1,i2进行计算(具体的计算式根据前面的思路可以很容易的得出)。
6.返回当前节点指针。
node* creat1(string s1, string s2, int p1, int p2, int i1, int i2)
{
//p1,p2是在s1里的子树范围,i1,i2是在s2里的子树范围
node*p = new node;
p->data = s1[p1];
p->left = NULL;
p->right = NULL;
//cout << p->data << ' ' << p1 << ' ' << p2 << ' ' << i1 << ' ' << i2 << endl;
if (s1[p1] == s1[p2])
return p;
int a = i1;
while (s2[a] != p->data && a <= i2)
a++;
if (s2[a] != p->data)
exit(0);
int leftlen = a - i1;//当前节点左子树元素个数
if (leftlen > 0)
p->left = creat1(s1, s2, p1 + 1, p1 + leftlen, i1, a - 1);
int rightlen = i2 - a;//当前节点右子树元素个数
if (rightlen > 0)
p->right = creat1(s1, s2, p2 - rightlen + 1, p2, a + 1, i2);
return p;
}后序和中序
这个思路其实和前面的一样,我们对比先序和后序遍历的结果:
先序:ABDECFG
后序:DEBFGCA
有点像,但是不多,那我们把后序遍历结果逆置一下呢
先序:ABDECFG rLR
后序逆置:ACGFBED rRL
这就很像了,只不过是先进右子树再进左子树而已,所以建立思路跟前面的很像,我们可以选择先逆置再建立,也可以从后往前遍历后序遍历的结果,都是一样的,不过多介绍了,我选择的是从后往前。
node* creat2(string s1, string s2, int p2, int p1, int i1, int i2)
{
//p1,p2是在s1里的子树范围,i1,i2是在s2里的子树范围
node* p = new node;
p->data = s1[p1];
p->left = NULL;
p->right = NULL;
//cout << p->data << ' ' << p1 << ' ' << p2 << ' ' << i1 << ' ' << i2 << endl;
if (s1[p1] == s1[p2])
return p;
int a = i1;
while (s2[a] != p->data && a <= i2)
a++;
int rightlen = i2 - a;//当前节点右子树元素个数
if (rightlen > 0)
p->right = creat2(s1, s2, p1 - rightlen, p1 - 1, a + 1, i2);
int leftlen = a - i1;//当前节点左子树元素个数
if (leftlen > 0)
p->left = creat2(s1, s2, p2, p2 + leftlen - 1, i1, a - 1);
return p;
}层次和中序
这个就跟前面两个不一样了,因为层次遍历并不是所有子节点紧跟其父节点的,所以根本思路是有变化的。
分析
我的想法是根据层次遍历对所有节点进行编号,这样的话,编号小的在上层或左边,同样的,我们看中序遍历,我们根据中序遍历从当前节点向左右进行计数,知道到头,或者是遇到编号比当前节点小的节点。这样的话我们就可以获得左右子树的元素个数,而左右子树中编号最小的就是当前节点的左孩子后右孩子,思路很朴素,实现也不用递归,直接循环嵌套就好了。
思路
1.现将所有数据存到节点中,从根节点A开始
2.遍历中序遍历结果,得到A的位置在第3位,向左,向右遍历,所有节点编号都比A的编号大,得到A的左子树元素个数为3,右子树元素个数也为3。
3.建立A的左子树,在A左子树元素范围内寻找编号最小的节点为B,B为左孩子。同理,得到A的右孩子为C。
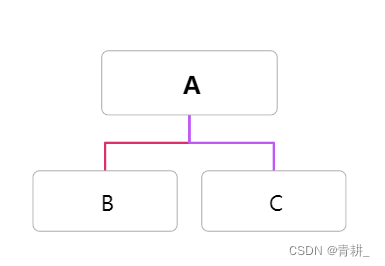
4.其他节点的孩子寻找也是一样的,重复即可。
代码思路也是一样的 。
node* creat3(string s1, string s2, int l)
{
map<char, int>m;//编号
node** t = new node * [l + 1];
for (int i = 0; i <= l; i++)
{
t[i] = new node;
t[i]->data = s1[i];
t[i]->left = t[i]->right = NULL;
m[s1[i]] = i;
}
for (int i = 0; i < l; i++)
{
int a = 0;
while (s2[a] != t[i]->data)
a++;
int leftlen = 0, rightlen = 0;
int leftb = 0, rightb = l - 1;
for (int k = a - 1; k >= 0; k--)
{
if (m[s2[k]] < i)
{
leftb = k + 1;//记录左边的 子树截止位置
break;
}
leftlen++;
}//向左计数
for (int k = a + 1; k < l; k++)
{
if (m[s2[k]] < i)
{
rightb = k - 1;//记录右边的 子树截止位置
break;
}
rightlen++;
}//向右计数
int le = 100;
for (int k = 0; k < leftlen; k++)//找到编号最小的节点
{
if (m[s2[k + leftb]] < le)
le = m[s2[k + leftb]];
}
if (le != 100)
t[i]->left = t[le];
int r = 100;
for (int k = 0; k < rightlen; k++)//找到编号最小的节点
{
if (m[s2[rightb - k]] < r)
r = m[s2[rightb - k]];
}
if (r != 100)
t[i]->right = t[r];
}
return t[0];
}另一种思路
后来看网上的代码发现一种其他的思路
根据中序遍历对节点进行编号,这就意味着,左子树编号都小于根节点,右子树编号都大于根节点,对于任意子树都是如此,然后我们根据层次遍历的顺序进行节点的加入(就是一层一层的建立),这就是二叉排序树的建立,虽然需要用到递归,但我觉得比我的思路要简单,具体的可以看这个(虽然他的题目好像写错了):
层次遍历和后序遍构建二叉树_跨考上浙大的博客-CSDN博客_层序遍历和后序遍历能确定二叉树吗
源代码
#include<iostream>
#include<fstream>
#include<map>
#include<iomanip>
using namespace std;
typedef struct node {
char data;
node* left;
node* right;
}node;
class BT {
public:
node* root;
BT(int x);
void print(node* r, int layer);
void PreOrder(node* p);
};
int main()
{
BT a(2);
a.PreOrder(a.root);
cout << endl;
a.print(a.root, 0);
}
node* creat1(string s1, string s2, int p1, int p2, int i1, int i2)
{
//p1,p2是在s1里的子树范围,i1,i2是在s2里的子树范围
node*p = new node;
p->data = s1[p1];
p->left = NULL;
p->right = NULL;
//cout << p->data << ' ' << p1 << ' ' << p2 << ' ' << i1 << ' ' << i2 << endl;
if (s1[p1] == s1[p2])
return p;
int a = i1;
while (s2[a] != p->data && a <= i2)
a++;
if (s2[a] != p->data)
exit(0);
int leftlen = a - i1;//当前节点左子树元素个数
if (leftlen > 0)
p->left = creat1(s1, s2, p1 + 1, p1 + leftlen, i1, a - 1);
int rightlen = i2 - a;//当前节点右子树元素个数
if (rightlen > 0)
p->right = creat1(s1, s2, p2 - rightlen + 1, p2, a + 1, i2);
return p;
}
node* creat2(string s1, string s2, int p2, int p1, int i1, int i2)
{
//p1,p2是在s1里的子树范围,i1,i2是在s2里的子树范围
node* p = new node;
p->data = s1[p1];
p->left = NULL;
p->right = NULL;
//cout << p->data << ' ' << p1 << ' ' << p2 << ' ' << i1 << ' ' << i2 << endl;
if (s1[p1] == s1[p2])
return p;
int a = i1;
while (s2[a] != p->data && a <= i2)
a++;
int rightlen = i2 - a;//当前节点右子树元素个数
if (rightlen > 0)
p->right = creat2(s1, s2, p1 - rightlen, p1 - 1, a + 1, i2);
int leftlen = a - i1;//当前节点左子树元素个数
if (leftlen > 0)
p->left = creat2(s1, s2, p2, p2 + leftlen - 1, i1, a - 1);
return p;
}
node* creat3(string s1, string s2, int l)
{
map<char, int>m;
node** t = new node * [l + 1];
for (int i = 0; i <= l; i++)
{
t[i] = new node;
t[i]->data = s1[i];
t[i]->left = t[i]->right = NULL;
m[s1[i]] = i;
}
for (int i = 0; i < l; i++)
{
int a = 0;
while (s2[a] != t[i]->data)
a++;
int leftlen = 0, rightlen = 0;
int leftb = 0, rightb = l - 1;
for (int k = a - 1; k >= 0; k--)
{
if (m[s2[k]] < i)
{
leftb = k + 1;//记录左边的 子树截止位置
break;
}
leftlen++;
}
for (int k = a + 1; k < l; k++)
{
if (m[s2[k]] < i)
{
rightb = k - 1;//记录右边的 子树截止位置
break;
}
rightlen++;
}
int le = 100;
for (int k = 0; k < leftlen; k++)
{
if (m[s2[k + leftb]] < le)
le = m[s2[k + leftb]];
}
if (le != 100)
t[i]->left = t[le];
int r = 100;
for (int k = 0; k < rightlen; k++)
{
if (m[s2[rightb - k]] < r)
r = m[s2[rightb - k]];
}
if (r != 100)
t[i]->right = t[r];
}
return t[0];
}
BT::BT(int x)
{
switch (x)
{
case 1: {
fstream file("text1.txt", ios::in);
string s1, s2;
file >> s1 >> s2;
//cout << s1 << endl << s2 << endl;
int l1 = s1.length();
int l2 = s2.length();
//cout << l1 << " " << l2 << endl;
root = creat1(s1, s2, 0, l1 - 1, 0, l2 - 1);
break;
}
case 2: {
fstream file("text2.txt", ios::in);
string s1, s2;
file >> s1 >> s2;
//cout << s1 << endl << s2 << endl;
int l1 = s1.length();
int l2 = s2.length();
//cout << l1 << " " << l2 << endl;
root = creat2(s1, s2, 0, l1 - 1, 0, l2 - 1);
//cout << root->data;
break;
}
case 3: {
fstream file("text3.txt", ios::in);
string s1, s2;
file >> s1 >> s2;
//cout << s1 << endl << s2 << endl;
int l1 = s1.length();
int l2 = s2.length();
root = creat3(s1, s2, l2);
break;
}
}
}
void BT::print(node* r, int layer)
{
if (r->right != NULL)
{
print(r->right, layer + 1);
}
for (int i = 0; i < layer; i++)
cout << " |";
cout << setw(4) << r->data << '|' << endl;
if (r->left != NULL)
{
print(r->left, layer + 1);
}
}
void BT::PreOrder(node* p)
{
if (p == NULL)
return;
else
{
cout << p->data << ' ';
PreOrder(p->left);
PreOrder(p->right);
}
}















 6968
6968











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









