






- 实验目的
- 掌握机器学习建模分析
- 掌握回归分析、分类分析、聚类分析、降维等
- 了解各分类器之间的差异
- 实验环境
操作系统:作系统:Windows 11
应用软件:Jupyter Notebook
- 实验内容与结果
(题目、源程序、运行结果)
一个分类器只能使用一列lable
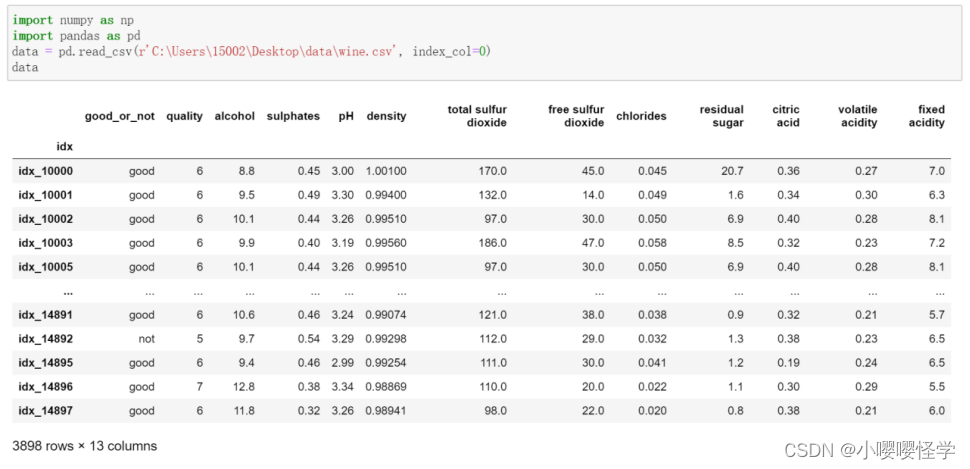
- 使用scikit-learn建立决策树为葡萄酒数据集构造分类器(分类结果为’good’或‘not’ )
[“不可使用quantity”列]

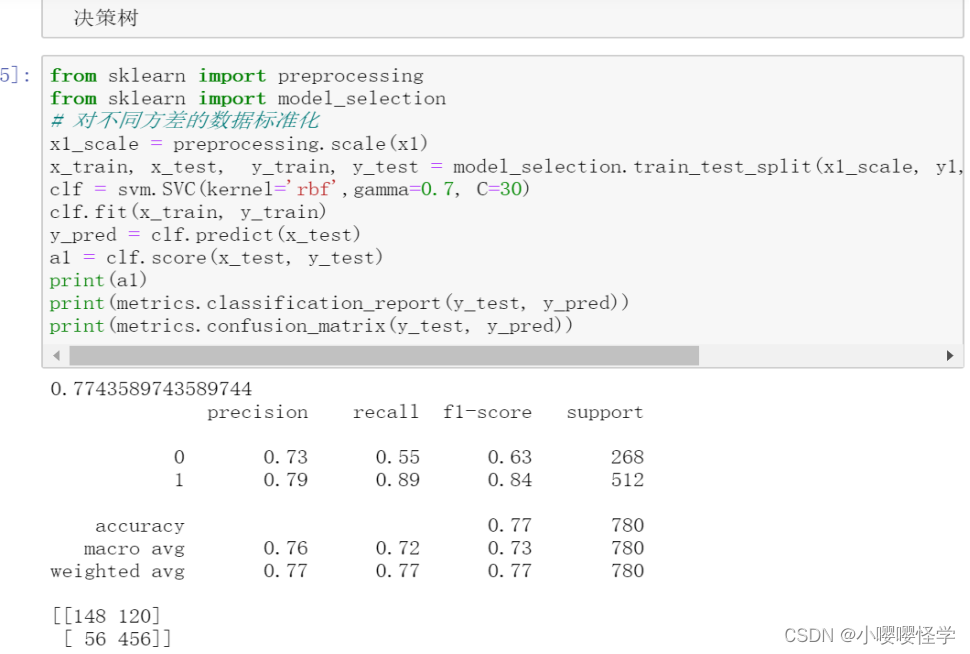
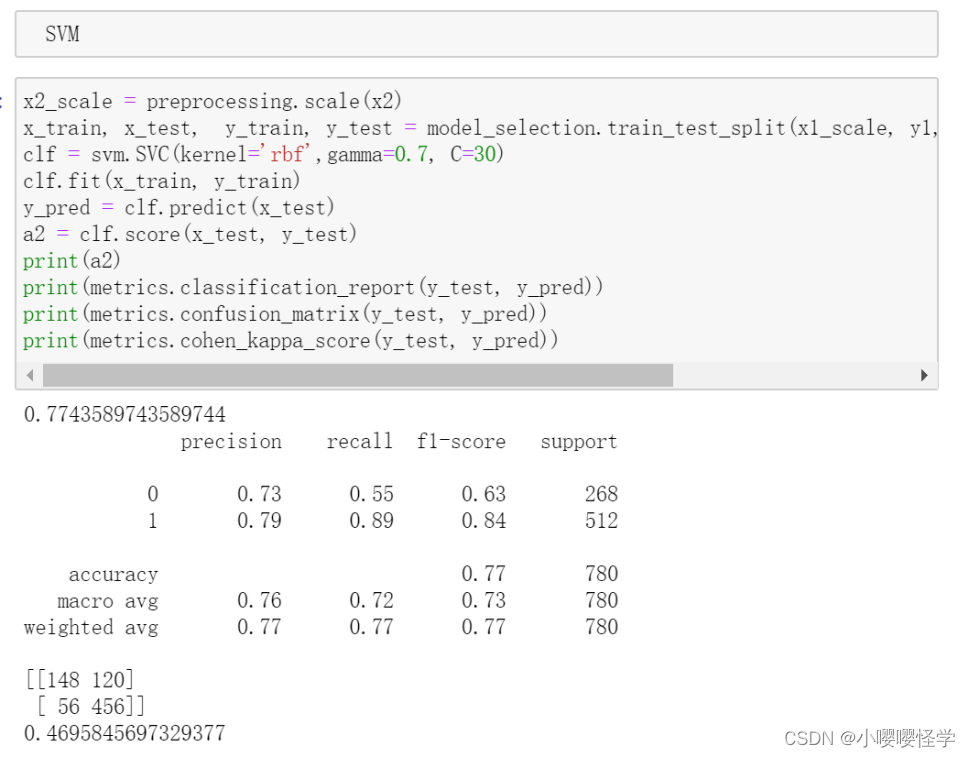
2.使用scikit-learn建立SVM模型预测葡萄酒质量(1-10之间)[“不可使用good_or_not”列]

3.(选作)评估以上两种分类器在此数据集上的分类性能
使用SVM多分类的时候需要用到Kappa系数
* 需要划分训练集和测试集
- 实验总结
分类问题是对事物所属类型的判别,类型的数量是已知的。
分类算法通过数据集自动学习分类模型(也称分类器),在分类学习(也称训练)过程中,采用不同的学习算法可以得到不同的分类器,常用的分类算法有很多,如决策树(Decision Tree)、贝叶斯分类、KNN (K近邻)、支持向量机(Support Vector Machine,SVM)、神经网络(Neural Network)和集成学习(EnsembleLearning)等。本次实验为决策树和SVM两种学习算法。
scikit-learn的Decision Tree Classifier 类实现决策树分类器学习,支持二分类和多分类问题。分类性能评估同样采用metrics类实现。
支持向量机 (SVM)的基本思想是将数据看作多维空间的点,求解一个最优的超平面,将两种不同类别的点分割开来。SVM采用核函数(Kernel Function)将低维数据映射到高维空间,选用适当的核函数,就能得到高维空间的分割平面,较好地将数据集划分为两部分。常用的核函数有线性核、多项式核、高斯核和 sigmoid核等。核函数的选择是影响SVM分类性能的关键因素,若核函数选择不合适,则意味着将样本映射到不合适的高维空间,无法找到分割平面。当然,即使采用核函数,也不是所有数据集都可以被完全分割的,因此SVM 的算法中添加了限制条件,来保证尽可能减少不可分点的影响,使划分达到相对最优。
















 8081
8081











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











