






一.选题背景
当研究网络分析、机器学习和社交网络等领域时,随机游走算法作为一种基础且强大的工具,引起了广泛关注。随机游走模型通过模拟节点或者系统在网络结构中的随机移动,不仅能够揭示复杂网络中的潜在结构和信息流动规律,还在信息检索、推荐系统和社交网络分析等实际应用中展现了卓越的效果。随着数据量和网络复杂性的增加,如何高效地实现和优化随机游走算法成为了当前研究的重要课题之一。本文旨在探讨随机游走算法的实现方法及其在不同应用场景下的性能表现,以期为进一步优化算法和推动相关领域的发展提供新的思路和方法。
二.数据爬取与收集
2.1数据集Wikipedia图数据集
需要翻墙对维基百科进行访问
Wiki关键词:计算机视觉,深度学习,卷积神经网络,决策树,支持向量机
爬取5个页面中所有的链接,深度设定为4.
https://en.wikipedia.org/wiki/Computer_vision
https://en.wikipedia.org/wiki/Deep_learning
https://en.wikipedia.org/wiki/Convolutional_neural_network
https://en.wikipedia.org/wiki/Decision_tree
https://en.wikipedia.org/wiki/Support_vector_machine
2.2 数据爬取
抓取数据采用开源的Seealsology
网址:https://densitydesign.github.io/strumentalia-seealsology/
SeeAlsology是由意大利DensityDesign实验室开发的一款可视化工具,旨在帮助用户探索概念之间的关联和联系。它通过交互式的方式展示了不同概念之间的关系网络,使用户能够直观地理解和探索各种主题或关键词之间的连接。主要利用图形化界面展示概念或关键词之间的关系网络。用户可以通过节点(关键词)和边(关系)的布局来理解和分析不同概念之间的相关性。另外用户可以通过操作,如点击和拖动,探索和调整网络中节点的布局,以及查看特定概念的详细信息和与之相关联的其他概念。SeeAlsology提供了直观的可视化效果,使复杂的概念网络易于理解。通常使用节点的大小、颜色和位置等视觉属性来表达不同概念之间的重要性和关联度。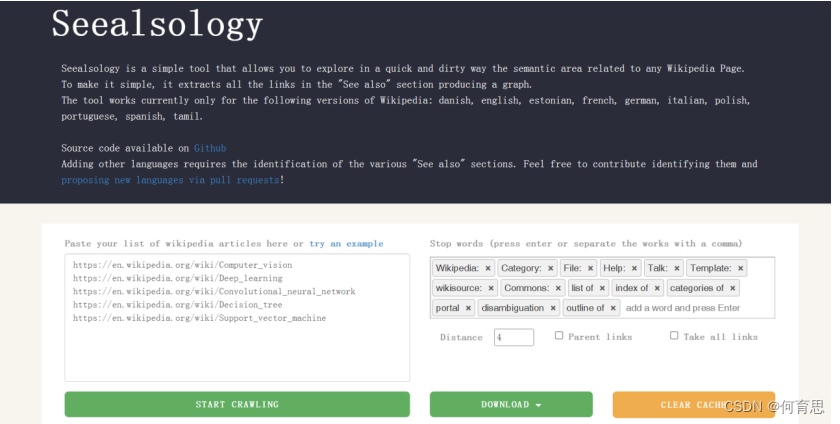
对上述五个网址输入进去,再将distance设置为4,然后点击starting crawling,爬取每个词条中的sea also 以及sea also词条中的 sea also词条,获取这些词条之间的关联关系。将关联关系文档以tsv格式进行下载。
2.3 数据集展示
在爬取完成后,将数据下载为TSV格式,保存于项目根目录seealsology_data.tsv。如下表,共有三列(父节点-子节点-深度)。有了这个数据,我们便可在Python中实施DeepWalk以查找相似的Wikipedia页面。
2.3.1SeeAlsology生成图
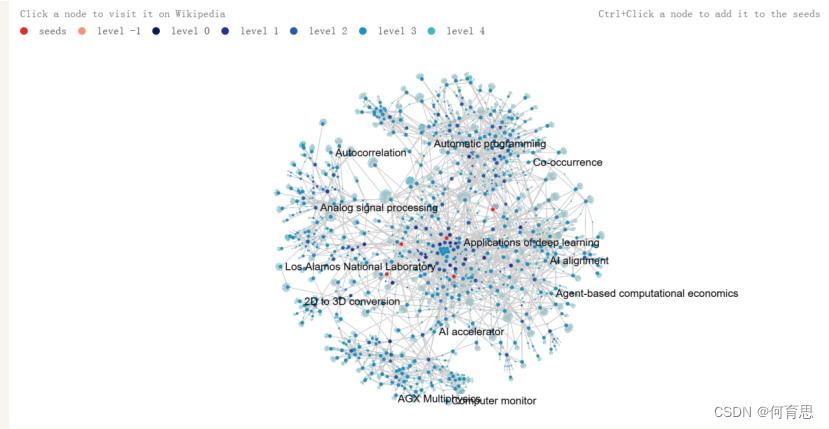
SeeAlsology生成的图是一个节点(节点)和边(边)构成的网络图,用于展示不同概念之间的关联和联系。以下是对该图的解释说明:
节点:每个节点代表一个特定的关键词、主题或概念。这些节点的大小、颜色或其他视觉属性通常反映了它们在整个网络中的重要性或与其他节点的关联程度。例如,在上图中,看到的节点代表"自相关"、"模拟信号处理"、"自动编程"等概念。
边:边表示节点之间的连接或关系。它们通常用于显示不同节点之间的相关性、相似性或其他类型的关联。边的粗细、颜色或样式可以用来表示连接的强度或类型。
2.3.2SeeAlsology生成TSV文件
生成的TSV文件说明:SeeAlsology可以导出一个包含节点和边信息的TSV文件,通常包括三列:
第一列:源节点(Source Node)。
第二列:目标节点(Target Node)。
第三列:边的权重或类型(Edge Weight or Type)。
这些信息可以用来在其他工具或平台上进一步分析或可视化,或者用作进一步研究和数据处理的基础。
通过这些节点和边的可视化及其导出的TSV文件,用户能够更好地理解和探索复杂网络中的概念结构、关系和演化过程,促进了相关研究领域的深入分析和交流。
三.模型介绍
3.1 两个涉及的算法及其伪代码
在本作业中共用到DeepWalk和RandomWalk。
以下为两个算法的伪代码:
算法1:DeepWalk



3.2 DeepWalk模型简介
参考此篇文章链接:
[https://www.analyticsvidhya.com/blog/2019/11/graph-feature-extraction-deepwalk/]
随机游走是一种从图中提取序列的技术。我们可以使用这些序列来训练一个skip-gram模型来学习节点嵌入。
随机游走的工作原理:
让我们考虑下面的无向图:
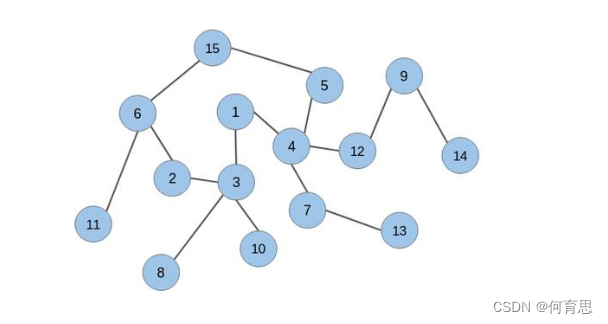
我们将在该图上应用随机游走并从中提取节点序列。我们将从节点1开始,并覆盖任意方向的两条边: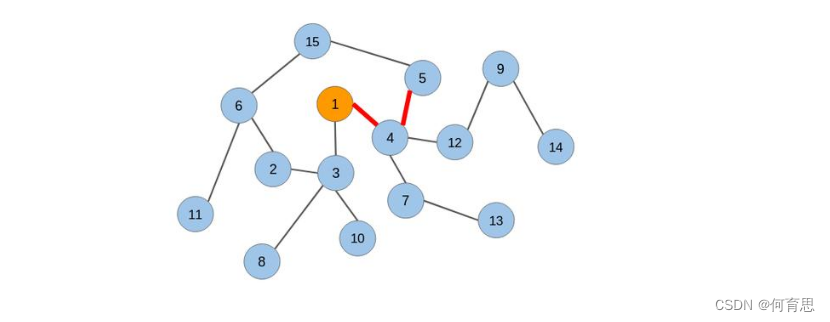
从节点1,我们可以转到任何连接的节点(节点3或节点4)。我们随机选择了节点4。现在再次从节点4开始,我们不得不随机选择前进的方向。我们将转到节点5。现在我们有3个节点的序列:[节点1 –节点4 –节点5]。
让我们生成另一个序列,但是这次是从另一个节点生成的:
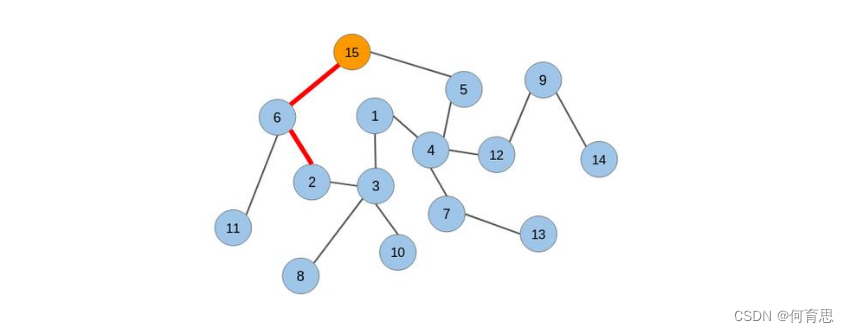
让我们选择节点15作为原始节点。从节点5和6,我们将随机选择节点6。然后从节点11和2,我们选择节点2。新序列为[节点15 –节点6 –节点2]。
我们将对图中的每个节点重复此过程。这就是随机游走技术的工作原理。
在生成节点序列之后,我们必须将它们提供给一个skip-gram模型以获得节点嵌入。整个过程被称为Deepwalk。
四.执行过程与展示
4.1导入相关的包

4.2生成random walk

在控制台上输出了tsv文件的前几行数据如下图所示:

查看数据框的行数和列数:
![]()
生成的图G的节点数:

图G中所有节点的列表在控制台上如图所示:

 由于节点过多,这里只列出部分节点。
由于节点过多,这里只列出部分节点。
![]()
对'computational photography')进行随机游走,最大长度为3,结果如下所示:
![]()
这表示从 'computational photography' 出发,依次经过了 'computational photography' 和 'monte carlo localization'。
生成的随机游走序列的总数:
第二个随机游走序列:

4.2训练word2vec

4.3分析word2vec的结果

查看'computational photography'节点的Embedding:(256,)表示有256个Embedding维数
具体向量展示:
[ 0.25173846 -0.43026745 0.1083096 0.11256905 0.11828031 0.29962033
-0.42579708 0.25689688 -0.03291091 0.07353493 0.15883268 -0.18145548
-0.12475763 -0.12066862 0.12148566 0.00931693 0.12517837 0.17936216
-0.03346702 0.16110651 -0.05644802 0.05648758 0.338115 0.02904321
-0.5645608 0.14061707 0.04872936 -0.38914317 -0.05995866 -0.3380035
-0.12444948 -0.06258503 -0.05284603 -0.3881412 -0.14848566 0.31073293
0.39358965 0.15962812 0.38698158 0.05452434 -0.09656779 0.20286179
-0.23701012 -0.39877868 0.37104487 -0.04276029 0.12455332 0.37414938
0.3099994 0.3374489 -0.51342213 -0.0587239 -0.13950856 -0.31692713
0.29138348 0.1719742 -0.23510817 -0.5136901 -0.4909264 0.11127438
0.22866781 -0.08501502 0.05308182 0.17127736 0.45048058 -0.11897277
-0.21052352 0.2794529 0.20667951 0.5975413 -0.09228335 0.51928043
0.0663617 -0.27741933 0.02775949 -0.0268053 -0.22108757 0.37719697
-0.0010096 -0.09209611 -0.19247083 -0.04638695 0.5228365 0.14439982
0.01855442 -0.26390642 -0.31561 -0.13032995 -0.21910474 0.14013194
-0.17440148 0.11526059 -0.01089565 -0.3035997 -0.22247471 0.304129
0.48724774 0.06505688 -0.28503752 0.08481828 0.10001393 -0.35146892
-0.02501885 0.09653639 -0.15285179 -0.49240282 0.12030103 -0.15577687
0.15240525 0.26682895 -0.26979682 -0.02222666 -0.00121882 0.03775968
0.4392618 -0.22116518 0.11802054 0.3041677 -0.02074244 0.7201194
0.3444568 0.07032063 0.06394979 -0.11999241 0.01922427 0.33787793
-0.34003723 0.10506711 -0.38812777 0.41442233 -0.30622765 0.05964248
-0.3777023 -0.17333055 0.07522721 0.3927935 0.12501973 0.49581885
-0.08911778 -0.40282127 0.10673469 -0.01768475 0.10506852 0.13359503
-0.31472757 -0.07250302 0.55599463 0.17134449 -0.17305689 0.12010978
0.02032169 0.09577939 0.14786139 -0.0970631 0.08650237 0.11603669
-0.08074988 -0.19356732 -0.31768396 0.08438274 -0.16805552 -0.24347474
0.13327049 0.17036967 0.35348824 -0.16174883 0.06195257 0.42670807
-0.12536879 0.15206757 0.11294698 -0.14423507 0.11347059 -0.00768777
0.3523711 -0.10934942 0.11037035 -0.14554091 -0.01464043 -0.21132383
-0.03118199 -0.05864146 -0.05611007 0.09142175 -0.14840482 0.01101821
0.06297901 0.20511918 0.11080959 0.5371753 0.16954304 0.01709065
0.24612871 -0.15431286 -0.1337524 -0.2698121 0.07162987 0.12955801
0.15793087 0.29325873 -0.01397655 -0.00538251 -0.17972805 -0.1793443
0.2400003 -0.09468662 -0.09178053 -0.25028569 -0.04395651 -0.18456821
0.3321678 -0.19474636 0.02772515 -0.31789103 0.21081723 -0.2317036
-0.03860504 0.10225802 0.27260035 0.26692984 0.18041497 0.03555385
0.00136777 0.01194809 0.26737523 -0.2685229 -0.53714097 0.1911193
-0.04686916 -0.11127774 0.11299986 0.13067332 0.3022113 -0.20327371
0.14185204 0.0516258 -0.13915484 -0.36977142 0.048122 0.1585258
-0.27723867 0.01678753 -0.00400845 0.13876228 -0.07158938 0.23394436
0.31740668 0.2840673 -0.09129781 -0.00978999 -0.07531729 -0.31270033
-0.12148237 0.19109178 -0.06902272 -0.00849641]
一共有256个维度的向量,每一个维度都是一个连续的实数,其也是连续稠密的一个向量。
而这个向量反映了这个节点的在图里的连接信息,集群信息和一些语义信息。
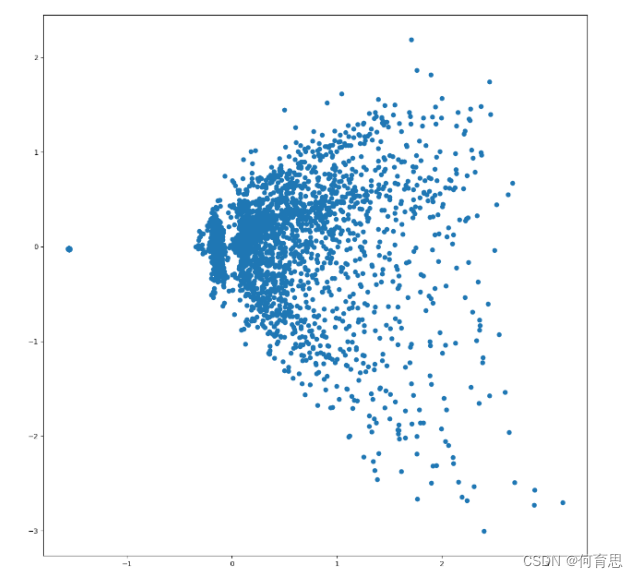
4.4 PCA降维,可视化全部词条的二维Embedding
由于高维能捕获出更多更丰富的信息,所以可以先转成高纬,在用降维算法转换成我们人类能理解的二维或三维算法。

生成的散点图如下:
4.5可视化某个词条的二维Embedding
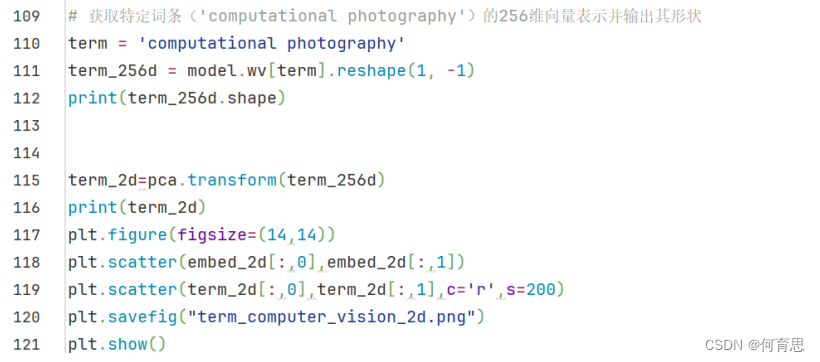
结果展示:
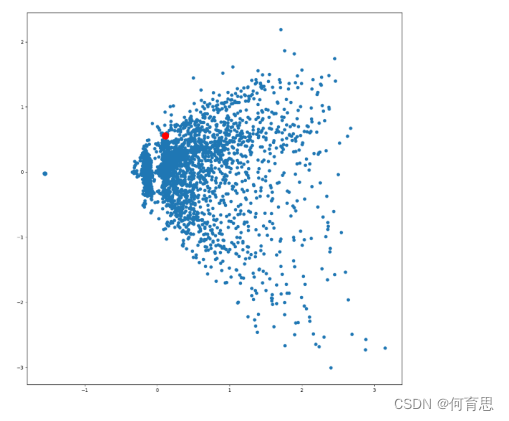
表示计算摄影在这5000多个词条里面在红色点的位置。
4.6可视化某些词条的二维Embedding
把重要度前30的30个节点给重点关注,我们关心的节点可视化在图里面如下图所示:

五.结果分析
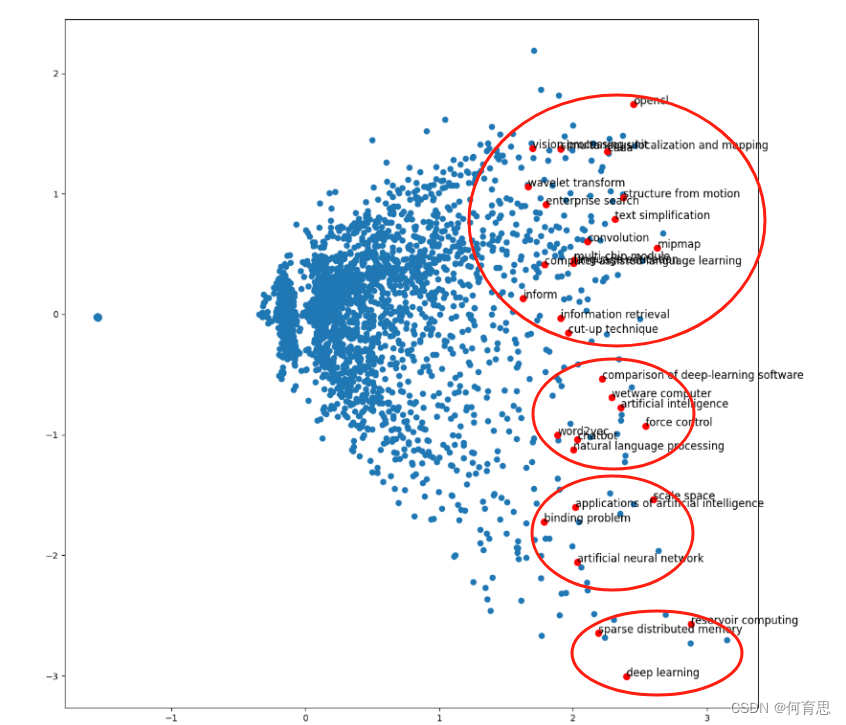
以上30个节点,共可分为4个分类区域。
| opencl convolution structure from motion mipmap simultaneous localization and mapping vision processing unit wavelet transform cuda multi-chip module language education text simplification cut-up technique information retrieval inform enterprise search comparison of deep-learning software 16个 |
| word2vec natural language processing chatbot artificial neural network wetware computer computer-assisted language learning force control 7个 |
| artificial intelligence scale space applications of artificial intelligence binding problem 4个 |
| sparse distributed memory deep learning reservoir computing 3个 |
分类1:计算机视觉和图像处理,这个分类涵盖了在计算机视觉和图像处理领域中关键的技术和概念。OpenCL 是一种用于并行计算的开放式标准,广泛应用于GPU和多核CPU计算。Convolution 是图像处理和深度学习中的基础操作,用于特征提取和模式识别。Structure from Motion (SfM) 则是从多个图像中重建三维场景的技术,常用于机器人导航和虚拟现实。Mipmap 是一种优化纹理映射的技术,通过多级别贴图提升图像渲染效率。SLAM 则是机器人领域的关键技术,用于实时定位和地图构建。Vision Processing Unit (VPU) 是专门设计用于计算机视觉任务的硬件加速器,优化视觉任务的处理速度和效率。Wavelet Transform 则用于信号处理和数据压缩,能够在不同尺度上分析数据特征。
分类2:自然语言处理和相关技术,这一分类涵盖了自然语言处理(NLP)和相关的语言学习和理解技术。Word2Vec 是用于将词汇映射到高维向量空间的算法,常用于NLP任务中的词义表示和语义相似度计算。NLP 领域研究如何使计算机能够理解、解释和生成人类语言。Chatbot 是自动化对话系统,通过人工智能技术实现智能回复和交互。Artificial Neural Network (ANN) 是一种模仿人脑神经系统的计算模型,用于语言处理和其他复杂任务。Wetware Computer 涉及到生物大脑与计算机技术的对比和结合。Computer-Assisted Language Learning (CALL) 利用计算机技术来辅助语言学习,通过交互和个性化学习提升语言能力。Force Control 则是机器人技术中控制外部力量和运动的重要技术,有助于精确的物理交互和操作。
分类3:人工智能和相关应用,这个分类关注人工智能(AI)及其应用领域。AI 是一门研究如何使计算机能够展现出智能的学科,涵盖了从机器学习到知识表示的广泛领域。Scale Space 是用于多尺度分析的数学理论,广泛应用于计算机视觉和图像处理中。Applications of Artificial Intelligence 研究AI在各个领域的应用,如医疗保健、金融和智能交通系统等。Binding Problem 则是神经科学中一个关键问题,探讨感觉信息如何整合成统一的知觉体验,对理解认知过程至关重要。
分类4:其他这一分类包含了一些不易归类到其他大类中的技术和概念。Sparse Distributed Memory 是一种非常规的存储和检索模型,通常用于模拟人类记忆和认知过程。Deep Learning 是机器学习的分支,利用深度神经网络进行高级模式识别和特征提取。Reservoir Computing 则是一种新兴的机器学习方法,利用动态系统的随机矩阵进行计算,适用于时间序列数据分析和预测。
附录
| deep learning |


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









