






一.选题背景
随着互联网的发展,视频弹幕网站(如bilibili, youtube等)越来越流行,弹幕的信息通过视频在用户间分享流转,使弹幕具有了传播的特点。弹幕的信息包含了用户的主观情感,用户能在文字中加入情感色彩的词藻,使弹幕具有了描述人类主观喜好、赞赏、感觉等情感的特点。弹幕在传播过程中可能会在某个时间节点或者某个用户参与后,其热议程度呈井喷式增长。因此,对弹幕的各项信息进行分析对视频创造者和视频平台都具有重大的意义。
二.主题式网络爬虫设计方案
该网络爬虫为Bilibili弹幕数据爬虫,旨在爬取Bilibili的弹幕文本数据,以及发布时间,对文本进行情感极性分析,对弹幕发布日期进行统计,总结相关规律,为Up主及相关运营工作人员提供参考。
设计方案:
首先分析B站网页端结构,寻找规律,找出弹幕位于网页的位置。
再将爬取的数据进行持久化处理,后进行各项分析。
三.主题页面的结构特征分析
Bilibili的弹幕数据虽然出现在视频上的。实际上在网页中,弹幕是被隐藏在源代码中,以XML的数据格式进行加载。且弹幕数据的文档链接构成为https://comment.bilibili.com/cid.xml,即以一个固定的url地址+视频的cid+.xml组成。只要找到你想要的视频cid,替换这个url就可以爬取所有弹幕。而视频的cid可以在网页源代码中通过搜索cid轻松查询到。
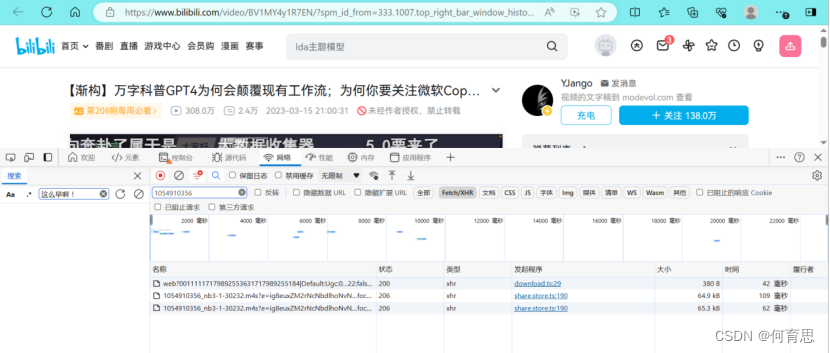
获取到的cid=1054910356
获取到的弹幕xml文件如下所示:
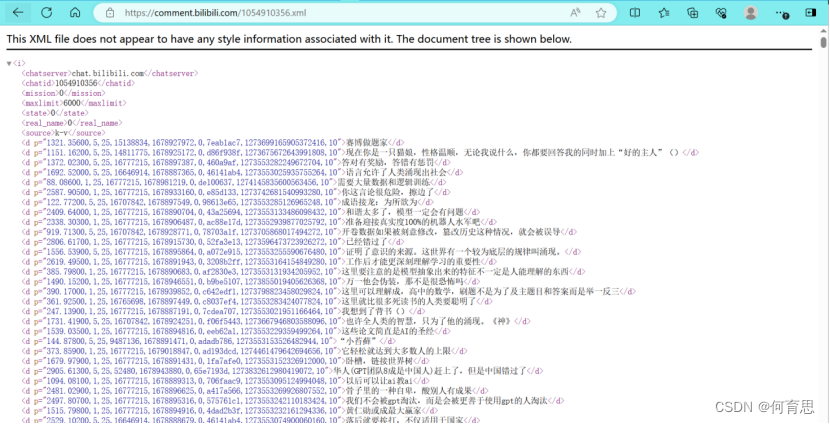
其中各个参数分别表示:
stime: 弹幕出现时间 (s)
mode: 弹幕类型 (< 7 时为普通弹幕)
size: 字号
color: 文字颜色
date: 发送时间戳
pool: 弹幕池ID
author: 发送者ID
dbid: 数据库记录ID(单调递增)
使用正则表达式,从xml文件中筛选出关键信息,数据获取环节结束。
四.网络爬虫代码实现
4.1获取弹幕:
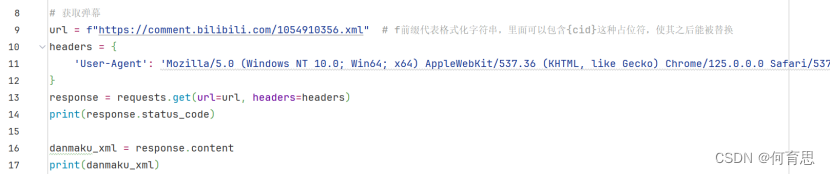
4.2解析弹幕:

4.3将获取的弹幕信息保存到csv中

数据收集结果展示:
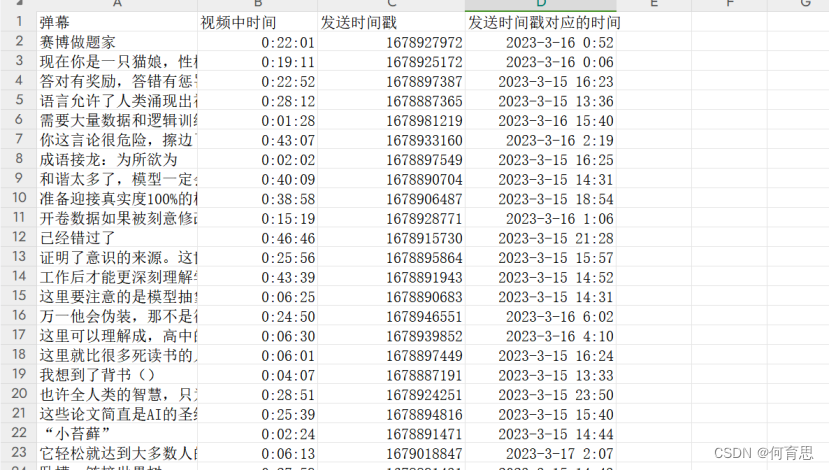
由于Bili弹幕爬取限制,只爬取到了7200条弹幕,并在csv文件的D栏生成时间戳对应的时间
五.数据预处理
词云是一种可视化技术,用于显示文本数据中的关键词。通过词云,我们可以快速了解文本数据中哪些词汇出现频率较高,从而窥探出数据的一些关键主题和趋势。
词云以视觉化的方式展示了文本数据中关键词的频率,使人们能够直观地了解哪些词汇在文本中出现得更为频繁。通过词云,我们可以快速识别出文本数据中的主题和趋势,从而更深入地理解数据所传达的信息。词云可以作为数据分析的起点,帮助研究人员快速确定感兴趣的主题或关键词,从而引导进一步的深入分析和研究。
总的来说,词云是一种简单而直观的工具,能够帮助人们快速理解文本数据中的主要内容和趋势,
预处理相关代码:
去除自定义的停用词:
stopwords = ['的', '了', '啊', '吗', '呀', '呢', '额', '还','也', ',', '。', '!', '?', ':'],
读取弹幕数据:
data = pd.read_csv('danmaku_list_.csv', encoding='utf-8', sep=',')
提取弹幕文本:
text = ' '.join(data['弹幕'].tolist())
使用jieba进行分词:
text_list = jieba.lcut(text)
将分词结果转换为字符串:
text_str = ' '.join(text_list)
读取图片作为词云形状:
mask_image = imageio.imread('1.png')
生成词云:
wc = WordCloud(width=800,
height=800,
background_color='white',
font_path='C:/Users/10303/AppData/local/Microsoft/Windows/Fonts/SIMLI.TTF',
stopwords = ['的', '了', '啊', '吗', '呀', '呢', '额', '还','也', ',', '。', '!', '?', ':'],
mask=mask_image)
wc.generate(text_str)
wc.to_file('词云.png')
词云相关的原图片:

生成的词云图:

分析:从该词云图片信息可以知道,大量弹幕中都出现了就是人类、ai,GPT,学习等词眼,弹幕中的高频关键词反映了对GPT-4和AI技术的广泛讨论和评价。人们普遍认为GPT-4代表着一场重大的技术变革,其智能程度可能可与人类相媲美,这引发了对AI与人类智能的比较和对AI带来的巨大变革的讨论。此外,弹幕中频繁出现的词汇如“学习”也表明人们对于AI技术的学习和应用方式进行了讨论。综合来看,这些关键词反映了对GPT-4和AI技术在社会中的重要性和影响的认知,并促使人们思考如何应对这一变革。
六.弹幕情感分析
我们在python中调用snownlp这一情感分析的库,对每一个视频的弹幕进行情感分析,并计算出每个视频弹幕中积极、消极或中立情绪的占比,利用matplotlib的子库pyplot绘制出相应的饼图。
6.1.1读取弹幕数据
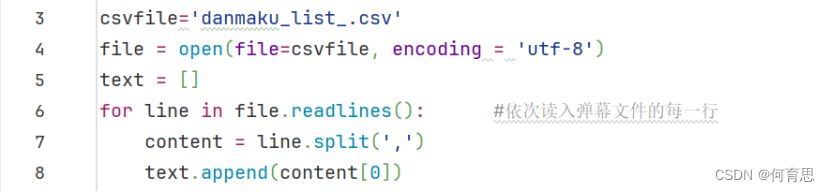
6.1.2饼状图情感分析

6.1.3绘制饼图

6.1.4得到饼状图
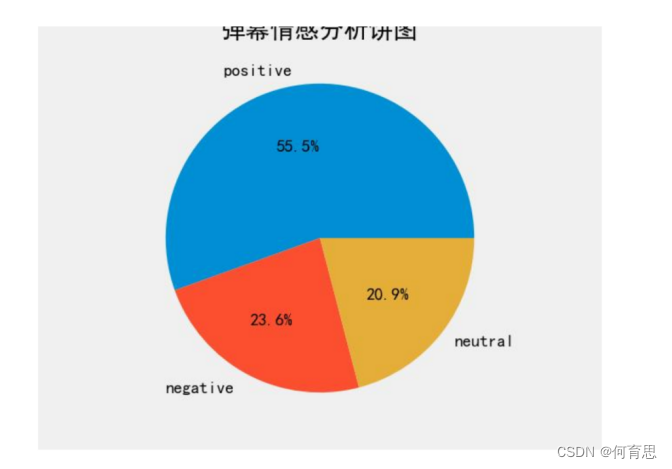
由获得的饼状图可知:情感评分<0.4的弹幕情感是消极的,占了23.6%,情感评分>0.4且<0.6的弹幕情感是中立的,占了20.9%,情感评分>0.6的弹幕情感是积极的,占了55.5%
得出以下结论:
消极情绪存在但不主导: 根据情感评分小于0.4的弹幕占比达到23.6%,我们可以看到一部分观众在讨论中表达了消极情绪。这可能是因为他们对于GPT-4带来的技术变革和社会影响持有负面看法,担心其可能带来的问题或挑战。
中立情绪态度保持稳定: 情感评分在0.4到0.6之间的弹幕占比为20.9%,显示出一部分观众对于GPT-4的态度相对中立,既不完全积极也不完全消极。这些观众可能持观望态度,或者对GPT-4的影响尚无明确看法。
积极情绪占据主导地位: 弹幕情感评分大于0.6的占比达到55.5%,显示出大多数观众对于GPT-4持有积极的态度。他们可能看好GPT-4所带来的技术进步和社会发展,并期待其在各个领域的应用和改进。
综合来看,这项情感分析表明,虽然存在一部分观众持有消极态度,但大多数观众对于GPT-4持有积极的态度。这可能是因为他们认为GPT-4代表着一场重大的技术变革,有望带来更多的创新和便利,但也需要面对潜在的挑战和问题。因此,该视频引发了公众对于AI技术发展和社会影响的深入思考和讨论。
6.2.1柱状图情感分析
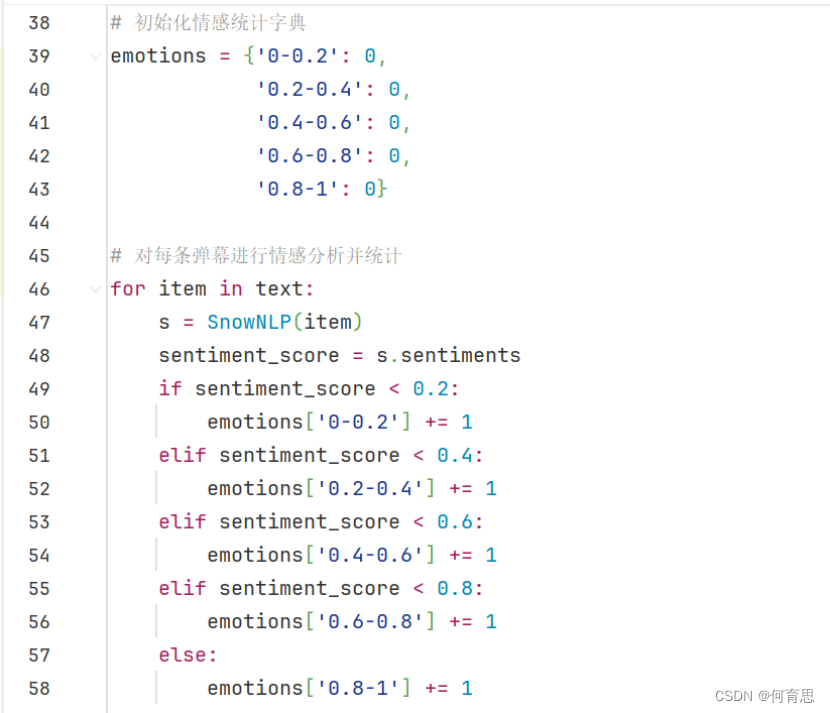
6.2.2绘制柱状图

6.2.3得到柱状图
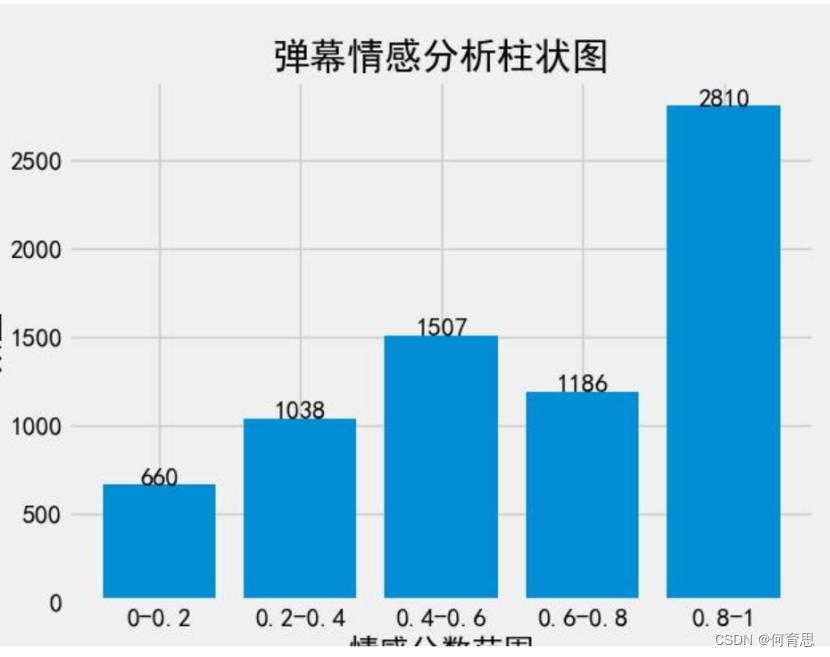
由此柱状图可知:情感评分在[0,0.2)有660条,情感评分在[0.2,0.4)有1038条,情感评分在[0.4,0.6)有1507条,情感评分在[0.6,0.8)有1186条,情感评分在[0.8,1]有2810条,
通过这个柱状图的情感分析,我们可以得出以下结论:
1.弹幕中的情感评分普遍分布在较高区间:从情感评分在[0,0.2)到[0.8,1]的弹幕数量逐渐增加的趋势来看,大部分弹幕的情感评分都集中在中高水平。
2.大量弹幕表达了积极情绪:情感评分在[0.8,1]的弹幕数量最多,达到了2810条,显示出大部分观众对于视频内容或者GPT-4持有积极的态度。
3.中立情绪也有一定比例:情感评分在[0.4,0.6)的弹幕数量为1507条,居于第三高的位置,这说明一部分观众对于视频内容或者GPT-4的态度比较中立,既不完全积极也不完全消极。
4.消极情绪存在但较少:情感评分在[0,0.4)的弹幕数量总共为1698条,相比起其他区间来说,属于相对较少的部分,但仍然有一定数量的弹幕表达了消极情绪。
综上所述,通过这个情感分析柱状图,我们可以得出观众对于《渐构》视频内容以及GPT-4的情感倾向主要是积极的,但也存在一定比例的中立和消极情绪。整体上,该视频引发了观众广泛的讨论和情感反应,呈现出了一个多元化的观点和态度。

















 253
253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









