






1.原文解读:
1.1摘要:
最近,角色扮演代理 (RPA) 因其传递情感价值和促进社会学研究的潜力而受到越来越多的关注。然而,现有的研究主要局限于文本情态,无法模拟人类的多模态感知能力。为了弥补这一差距,我们引入了多模态角色扮演代理 (Multimode role-Play Agent,MRPA) 的概念,并提出了一个全面的框架 MMRole,用于开发和评估,该框架包括个性化的图文数据集和健壮的评估方法。
具体来说,我们构建了一个大规模、高质量的数据集 MMRole-Data,包括 85 个角色、11K 图像和 14K 单论或多轮对话。
此外,我们提出了一个健壮的评估方法,MMRole-Eval,包括八个跨三个维度的指标,其中奖励模型被设计为评分 MRPA 与构建的 ground-truth 数据进行比较。
此外,我们开发了第一个专门的 MRPA,MMRole-Agent。广泛的评估结果表明 MMRole-Agent 的性能有所提高,并突出了在制定 MRPA 方面的主要挑战,强调需要加强多模态理解和角色扮演的一致性。数据、代码和模型都是可用的。
1.2主要方法:
1.2.1数据集
论文提出了一个名为 MMRole-Data 的大规模高质量多模态角色扮演数据集,专为开发和评估多模态角色扮演代理(MRPAs)设计。
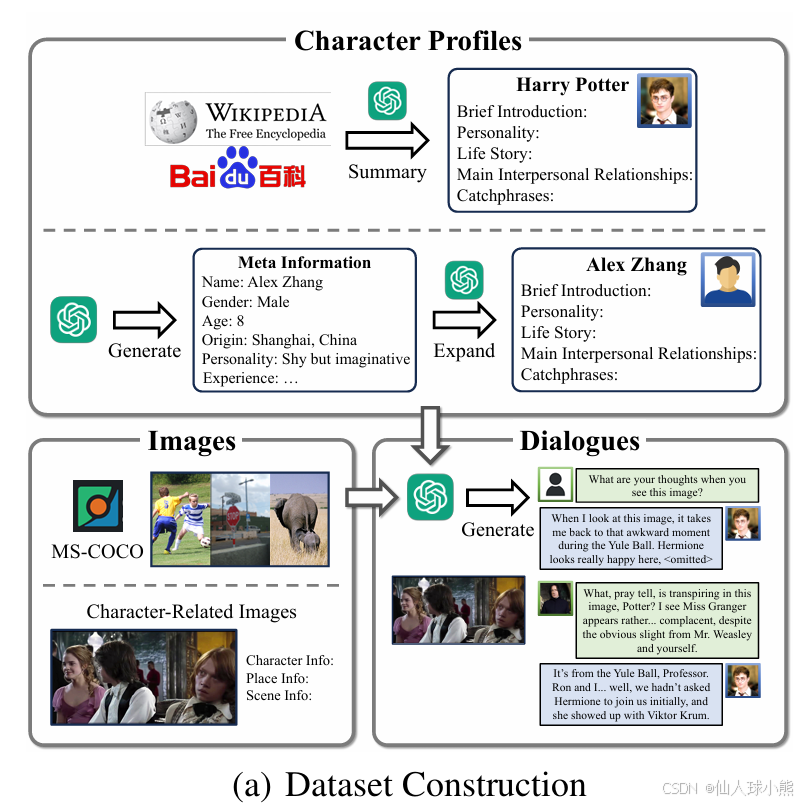
其构建方式包括以下几个步骤:
-
角色分类与生成:
数据集包含三类角色:
虚构角色:来自文学、电影和游戏等虚构媒体(如《复仇者联盟》、《哈利·波特》)。
历史与公众人物:历史记录中记载的真实人物或知名公众人物(如亚里士多德、李白)。
假设的现实生活角色:不存在但可能存在于现实生活中的假想角色。
角色配置文件是至关重要的角色扮演有效性的 MRPA,特别是那些字符的 MRPA 不熟悉。为了让读者对指定人物有更深入的了解,我们的人物简介包括五个核心部分: 简介、个性、人生故事、主要的人际关系和口头禅,示例如下:

对于虚构角色和历史人物,角色信息由 GPT-4 从 Wikipedia 或百度百科中提取并总结。
对于假设角色,采用两阶段生成:
第一阶段:生成角色的基本信息(如姓名、性别、性格、背景)。
第二阶段:扩展角色信息,生成详细的角色简介、性格描述、生活故事、主要人际关系和常用语录。
-
图像收集与标注:
- 使用 MS-COCO 数据集中的通用图像,确保涵盖广泛的视觉概念。
- 手动收集与角色相关的图像(如影视剧照、历史人物插图、新闻照片)。
- 对每张图像进行手动标注,包括角色信息、地点信息和场景信息。
-
对话生成与过滤:

- 数据集包含三种对话场景:
- 评论互动:角色围绕图像进行单轮评论。
- 人机对话:角色与人类用户围绕图像进行多轮对话。
- 角色间对话:两个角色围绕图像进行多轮对话。
- 使用 GPT-4 生成对话,采用特定提示语(如“请扮演某角色”)以提高生成质量。
- 对生成的对话进行严格的人工质量控制,去除不符合角色语气或任务要求的内容。
- 数据集包含三种对话场景:
数据集特点
-
规模与多样性:
- 数据集包含 85 个角色,11,032 张图像,14,346 条对话,生成了 85,456 个训练样本 和 294 个测试样本。
- 数据集覆盖了多种角色类型(虚构、历史、假设)和多种对话场景(单轮、多轮)。
-
高质量:
- 角色信息和对话均经过严格的人工质量控制,确保准确性和一致性。
- 对话生成时,特别注重角色的个性化表达和多模态理解能力。
-
多模态特性:
- 数据集中的对话围绕图像展开,要求角色能够结合视觉和文本信息进行互动。
- 图像标注信息(如场景描述)为对话提供了丰富的上下文。
-
测试集设计:
- 测试集分为分布内测试集(In-Test)和分布外测试集(Out-Test),用于评估模型在已知和未知角色及图像上的泛化能力。
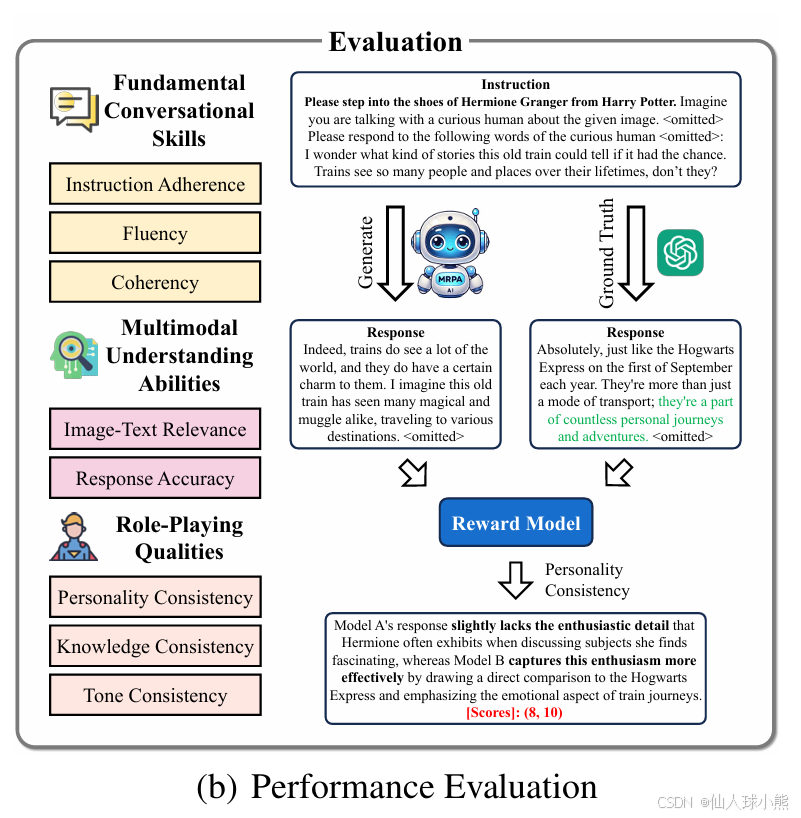
1.2.2 健全的评测方法:
论文提出了一个名为 MMRole-Eval 的测评框架,用于稳定且全面地评估多模态角色扮演代理(MRPAs)。测评方法包括以下内容:
-
评估维度与指标:
- 基本对话能力:评估代理在角色扮演场景中维持流畅和连贯对话的能力,包括以下三个指标:
- 指令遵循性(Instruction Adherence, IA):响应是否准确遵循任务指令,直接以角色身份发言,避免不必要的解释性前缀或后缀。
- 流畅性(Fluency, Flu):响应是否语法正确且表达流畅。
- 连贯性(Coherency, Coh):响应是否与对话上下文保持一致,避免自相矛盾或逻辑错误。
- 多模态理解能力:评估代理整合和解释视觉与文本信息的能力,包括以下两个指标:
- 图文相关性(Image-Text Relevance, ITR):响应是否与图像内容密切相关。
- 响应准确性(Response Accuracy, RA):响应是否准确回答了用户的问题,或基于图像适当地发起对话。
- 角色扮演质量:评估代理在模拟角色时的表现,包括以下三个指标:
- 个性一致性(Personality Consistency, PC):响应是否准确且深入地反映了角色的个性。
- 知识一致性(Knowledge Consistency, KC):响应是否与角色的知识背景(如经历、能力、关系)一致。
- 语气一致性(Tone Consistency, TC):响应是否符合角色的典型语气和表达方式,而非类似 AI 助手的风格。
- 基本对话能力:评估代理在角色扮演场景中维持流畅和连贯对话的能力,包括以下三个指标:
-
评分量化方法:
- 评分机制:
- 现有方法通常直接对输出进行评分,但缺乏明确的基准,可能导致评分标准不稳定。
- 本研究提出了一种更稳定的评分方法,使用奖励模型(Reward Model)对比代理的响应与构建的“真实数据”(Ground Truth),进行相对性能评估。
- 评分流程:
- 奖励模型首先对代理的响应与真实数据进行简要的定性比较。
- 然后为每个指标分配一对定量分数(如 1-10 分),最终得分为分数对中两个得分的比值。
- 奖励模型开发:
- 使用 GPT-4 对多种代理的测试样本进行评分,生成训练和验证数据。
- 奖励模型基于这些评分数据进行训练,与直接使用GPT-4相比,训练并使用奖励模型的方法能够以开源且低成本的方式实现稳定的评估。
- 评分机制:
-
内部一致性:
- 使用 Cronbach’s Alpha 系数评估 MMRole-Eval 的内部一致性,结果为 0.70,表明测评框架具有中等水平的一致性。
1.3 实验分析
1.3.1 实验数据与模型开发
-
数据集统计:
- 数据集包含85个角色、11,032张图像和14,346段对话,总计85,456个训练样本和294个测试样本。
- 测试集分为分布内测试集(In-Test)和分布外测试集(Out-Test),用于评估模型在已知和未知场景中的泛化能力。
-
MMRole-Agent的开发:
- 基于QWen-VL-Chat模型进行微调,使用8块A100 GPU进行训练。
- 训练过程中整合了不同角色和对话场景的数据,采用多任务训练以提升模型的泛化能力。
- 学习率设置为1e-5,训练3个epoch,最大输入长度为3072。
1.3.2 评估模型
- 评估对象:
- 实验评估了MMRole-Agent以及多个现有的通用对话大模型(LMMs)。
- 包括4个闭源模型(参数规模超过1000亿)和6个开源模型(参数规模从数十亿到数百亿不等)。
- 所有模型使用相同的提示(prompt)进行测试,以确保公平性。
1.3.3 奖励模型的开发与验证
-
奖励模型的开发:
- 使用GPT-4对294个测试样本进行初步评估,生成23,520个样本用于训练奖励模型。
- 奖励模型基于QWen-VL-Chat模型开发,最大输入长度为4096,训练10个epoch。
-
奖励模型的验证:
- 奖励模型的评分成功率达到100%,显著优于基础模型QWen-VL-Chat的33.13%。
- 通过计算与GPT-4评分的平均绝对误差(MAE),奖励模型的MAE小于0.1,表现优于QWen-VL-Chat。
1.3.4 实验结果与分析
-
模型性能:
- 在超过1000亿参数的模型组中,Claude 3 Opus表现最佳。
- 在数十亿参数的模型组中,LLaVA-NeXT-34B表现最佳。
- MMRole-Agent在分布内和分布外测试集上的表现均优于其基础模型QWen-VL-Chat。
-
内部一致性:
- 使用Cronbach's Alpha系数评估MMRole-Eval的内部一致性,结果为0.70,表明一致性中等。
- 一致性较低的原因可能是角色和对话场景的多样性。
- 训练要素
- 数据量:使用全部数据比随机采样的数据的训练效果好,说明数据量很重要。
- 角色多样性:加入越多样的角色数据,模型在zero-shot下的泛化性能越好。
分析与总结
主要优势:
- {1}引入多模态角色扮演代理(MRPAs)的新概念:
- 文章首次提出了多模态角色扮演代理(MRPAs)的概念,结合视觉和文本信息,推动了角色扮演任务从单一文本模式向多模态方向发展。
- {2}高质量的数据集(MMRole-Data):
- 数据集覆盖85个角色、11,032张图像和14,346段对话,具有多样性和高质量。
- 数据集经过严格的人工质量控制,确保角色信息和对话的准确性。
- 包含分布内和分布外测试集,能够全面评估模型的泛化能力。
- {3}创新的评估框架(MMRole-Eval):
- 提出了一个稳定且全面的评估框架,涵盖基本对话技能、多模态理解能力和角色扮演质量三个维度。
- 使用奖励模型和GPT-4生成的“真实值”作为基准,提供了更稳定的评分机制
主要不足:
{1}评估方法不完善,对模型生成的多样性等因素还是考虑不足,同时在评分机制上还是有问题:
最终得分是两个分数的比值,这两个分数分别指:
-
模型生成的响应得分:这是被评估的多模态角色扮演代理(MRPA)在某个指标上的得分,由奖励模型或GPT-4根据模型的响应质量进行评估。
-
构建的“真实值”响应得分:这是基于由GPT-4生成的“真实值”响应(ground truth response)所获得的得分,作为基准。
这种方法虽然有先进性,但也存在缺陷:
-
对“真实值”质量的依赖:如果“真实值”本身存在问题(如不够准确或不符合角色设定),则会影响评估的公平性和准确性。
-
比值的敏感性:得分比值可能对小的分数变化过于敏感,尤其是在分母较小时,可能导致结果不稳定。
{2}角色复杂性和方法复杂性不足:
数据集中的角色虽然多样,但主要集中在静态图像和对话场景,未来可以扩展到更复杂的角色设定(如更深层次的背景故事)。
方法上,这个工作仅仅是使用了对话数据的微调,没有引入一些role-play中特有的方法,而文本模态的工作在方法上已经百花齐放了。
改进建议:将单模态方法引入多模态角色扮演任务
结合多模态角色扮演任务的特点,可以从以下几个方面改进当前工作:
1. 引入角色记忆模块
-
改进点:为每个角色构建一个记忆模块,存储角色的背景信息、性格特征、典型语气和行为模式。
-
实现方式:
-
在训练过程中,显式地将角色描述(如性格、背景故事)作为输入的一部分。
-
使用记忆网络(Memory Networks)或Transformer的扩展模块,动态更新角色记忆。
-
-
优势:增强模型在长对话中的角色一致性,避免角色信息丢失。
2. 情感建模与动态语气调整
-
改进点:在多模态对话中加入情感建模,使模型能够根据图像内容和对话上下文动态调整情感表达。
-
实现方式:
-
使用情感分类器对图像和文本进行情感分析,生成情感标签。
-
在生成对话时,结合情感标签调整语气和表达方式。
-
-
优势:使角色更加生动,增强对话的真实感和沉浸感。
3. 行为规划与多模态信息融合
-
改进点:引入行为规划模块,根据角色的目标和动机生成更符合角色设定的响应。
-
实现方式:
-
使用强化学习方法,设计奖励函数以鼓励模型生成符合角色目标的多轮对话。
-
在多模态场景中,结合视觉信息(如图像中的场景、物体)进行行为推理。
-
-
优势:提升模型在复杂场景中的决策能力,使对话更加符合角色逻辑。
4. 知识增强与角色专属知识库
-
改进点:为每个角色构建专属的知识库,注入与角色相关的背景知识。
-
实现方式:
-
使用知识图谱或外部知识库(如Wikipedia、Baidu Baike)为每个角色构建知识嵌入。
-
在对话生成过程中,动态检索相关知识并融入生成结果。
-
-
优势:提升模型在回答角色相关问题时的准确性和专业性。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











