







动机:
近年来,自监督学习(SSL)在语音和音频处理领域取得了巨大成功。例如,Wav2vec 2.0 、HuBERT、BigSSL、WavLM 和 data2vec 等语音SSL模型在各种语音处理任务中表现出色,尤其是在低资源场景下。与语音不同,音频通常包含广泛的环境事件变化,包括人声、自然声音、音乐节拍等,这给通用音频建模带来了巨大挑战(动机1)。为此,SS-AST和 AudioMAE 等音频SSL模型被提出用于通用音频分类任务,证明了SSL不仅能够为语音,也能为非语音信号学习鲁棒的听觉表示。
迄今为止,最先进的音频SSL模型 仍然采用声学特征重建损失作为预训练目标,而不是像语音 、视觉 和语言中SSL模型那样使用离散标签预测作为预训练任务。然而,通常认为重建损失只关注低层次时频特征的正确性,而忽略了高级音频语义的抽象 (动机2)。
离散标签预测可能是比重建更好的音频预训练目标,原因如下:
首先,从仿生学角度来看,人类通过提取和聚类高级语义来理解音频,而不是关注低层次的时频细节。人类能够通过捕捉和分类音频中的语义信息,轻松识别任何品类的狗的吠叫声。通过学习音频的语义提取和聚类,音频SSL模型有望学会与人类相同的理解和泛化能力。
其次,从建模效率的角度来看,重建损失可能会浪费音频模型参数容量和预训练资源,用于预测与语义无关的信息,这些信息对通用音频理解任务几乎没有益处。相比之下,离散标签预测目标可以通过提供语义丰富的标记作为预训练目标,并鼓励模型丢弃冗余细节,从而提高音频建模效率。
第三,使用离散标签预测目标进行音频SSL预训练推动了语言、视觉、语音和音频预训练的统一(统一的多模态大模型)。与其为每种模态设计预训练任务相比,这种统一使得构建跨模态的基础模型成为可能,即使用单一的预训练任务——离散标签预测。
尽管具有这些优势,并且在各个领域取得了巨大成功,但离散标签预测在通用音频处理中的应用仍然面临挑战,原因如下:
首先,由于音频信号是连续的,相同的声学事件在不同场合可能具有不同的持续时间,因此无法像语言处理中那样直接将音频划分为语义上有意义的标记 。
另一方面,与语音不同,通用音频信号包含过大的数据变化,包括各种非语音声学事件和环境声音,常用的语音分词器(用于提取音素信息)无法直接应用。
方法:
为了应对这些挑战,我们提出了BEATS(Bidirectional Encoder representation from Audio Transformers 的缩写),这是一个迭代音频预训练框架,其中声学分词器和音频SSL模型通过迭代进行优化。
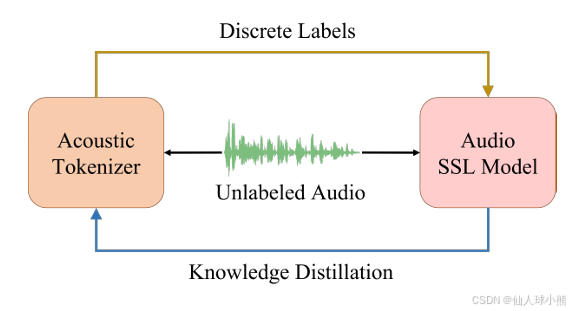
图1展示了训练流程。在每次迭代中,我们首先使用声学分词器生成给定未标记音频的离散标签,并使用它们,通过掩蔽和离散标签预测损失来优化音频SSL模型。模型收敛后,音频SSL模型作为“教师”,通过知识蒸馏 ,指导声学分词器学习音频语义。
在这个交替更新的学习过程中,声学分词器和音频SSL模型可以相互受益。重复该过程直到收敛。具体来说:
3.1 迭代音频预训练

需要注意的是,我们可以使用预训练的音频SSL模型或微调后的音频SSL模型作为声学分词器训练的“教师”。微调后的模型不仅从自监督预训练中学习语义知识,还从监督微调中学习,使其成为音频语义蒸馏的更好“教师”。通过这种交替更新的学习过程,声学分词器受益于音频SSL模型编码的语义丰富知识,而音频SSL模型则受益于声学分词器生成的语义丰富离散标签。重复该过程直到收敛。
3.2 声学分词器
声学分词器用于为BEATS预训练的每次迭代生成离散标签。在第一次迭代中,由于没有教师模型可用,我们采用随机投影分词器对连续的声学特征进行聚类,生成离散标签作为“冷启动”。从第二次迭代开始,我们训练一个自蒸馏分词器,利用上一次迭代中获得的预训练/微调音频SSL模型的语义知识来生成更精细的离散标签。
3.2.1 冷启动:随机投影分词器
在BEATS预训练的第一阶段,我们采用随机投影分词器 为每个输入音频生成块级离散标签。
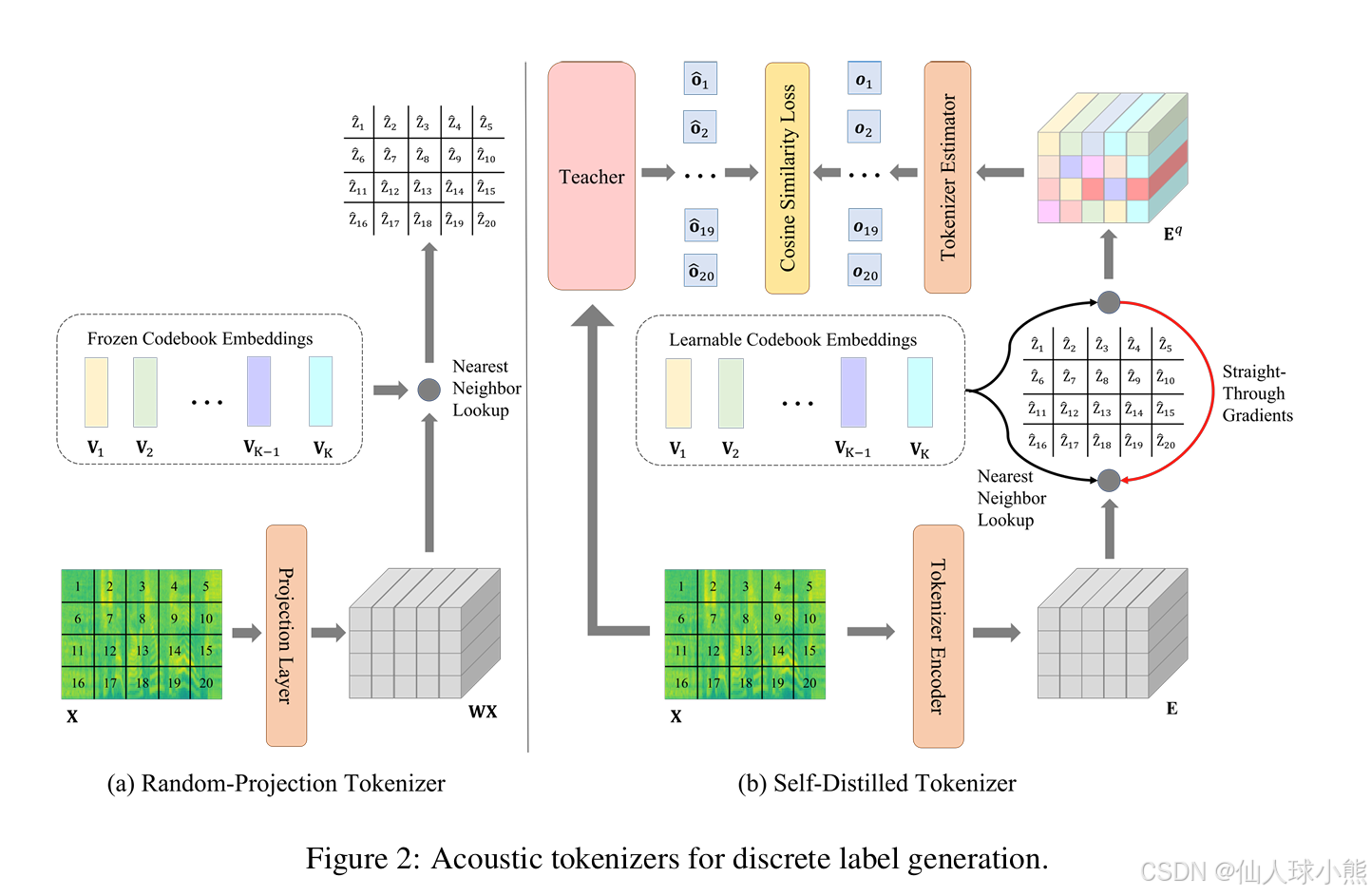
如图2的左半部分所示,随机投影分词器包括一个线性投影层和一组代码本嵌入向量,这些向量在随机初始化后保持不变。每个输入特征的块首先通过线性层进行投影,然后在代码本嵌入向量中找到最近邻向量,最近邻向量的索引被定义为离散标签。
3.2.2 迭代:自蒸馏分词器
从BEATS预训练的第二次迭代开始,我们利用上一次迭代的音频SSL模型作为“教师”,它可以是预训练模型或微调模型,来指导当前迭代的分词器学习。我们将这种分词器称为自蒸馏分词器,用于为每个输入音频生成块级离散标签。
如图2的右半部分所示,自蒸馏分词器首先使用基于Transformer的分词器编码器将输入块转换为离散标签,并使用一组可学习的代码本生成嵌入向量。然后,一个基于Transformer的分词器估计器被训练用来预测教师模型的输出。以知识蒸馏作为训练目标,分词器生成的离散标签被优化为包含更多来自教师的语义丰富知识,同时减少输入音频的冗余信息。
3.3 音频SSL模型
3.3.1 骨干网络
遵循以往的研究 ,我们采用ViT结构 (vison transformer)作为音频SSL模型的骨干网络,它由一个线性投影层和多层Transformer编码器组成。

3.3.2 预训练
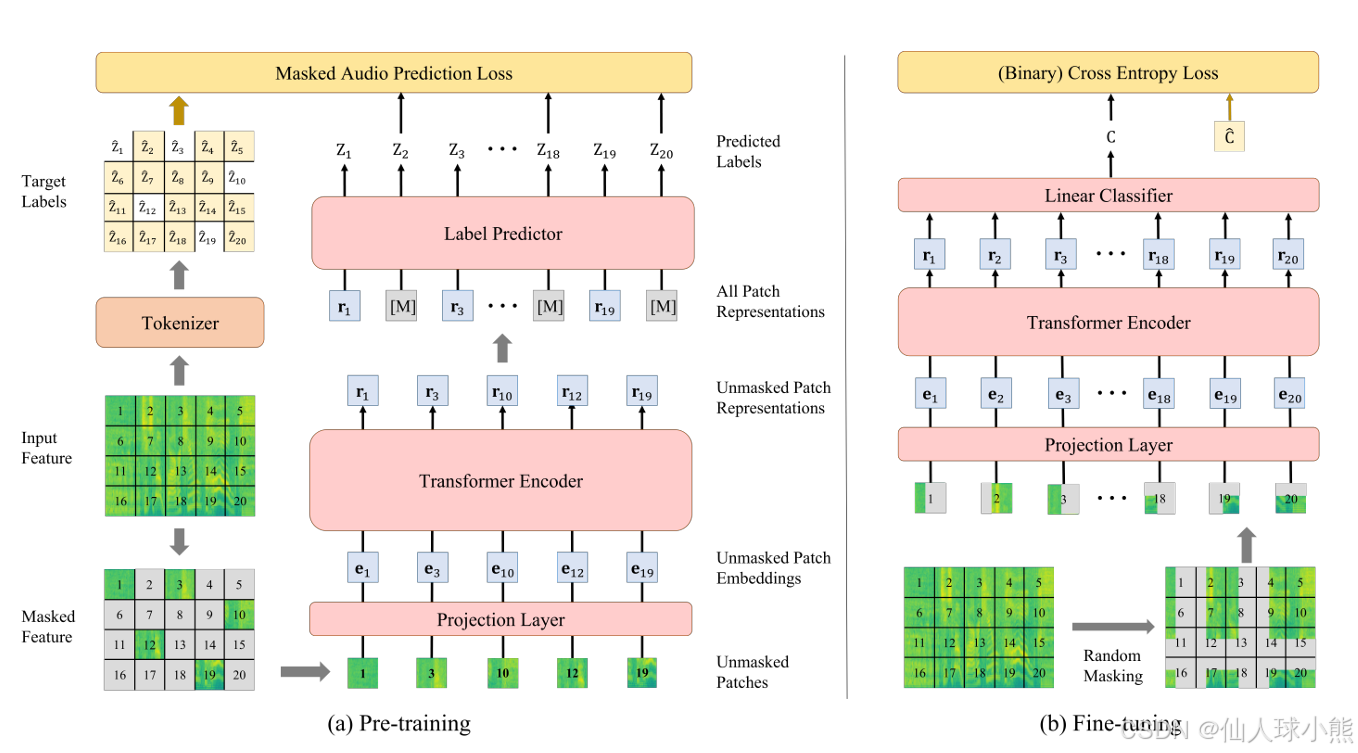
我们提出了一个名为**掩蔽音频建模(Masked Audio Modeling, MAM)**的自监督任务,用于音频SSL模型的预训练,如上图的左半部分所示。与以往的音频预训练方法不同,我们的模型不是优化重建输入的声学特征,而是优化预测由声学分词器生成的块级离散标签,使用基于Transformer的标签预测器来实现。
MAM的预训练目标是交叉熵损失,旨在最大化给定未掩蔽块序列的掩蔽位置中正确声学标签的对数似然:
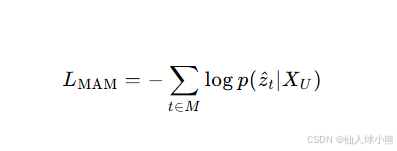
3.3.3 微调
在音频SSL模型的微调阶段,我们丢弃标签预测器,并在ViT编码器的顶部添加一个特定于任务的线性分类器,以生成下游分类任务的标签,如图3的右半部分所示。

结果可视化:
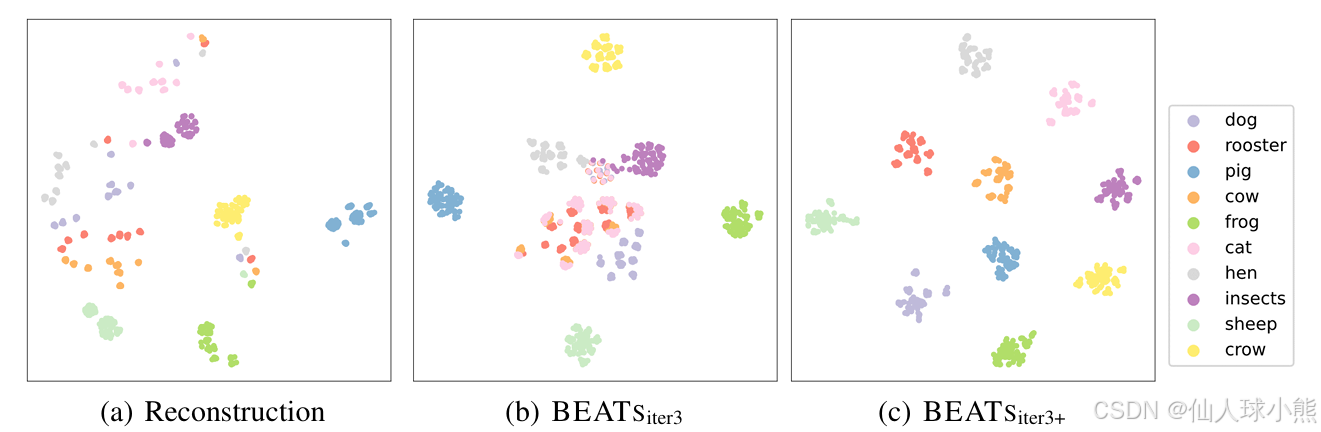
图4通过可视化展示了不同自监督学习(SSL)模型的预训练目标,以直观地比较这些目标在语义丰富性和对随机干扰的鲁棒性方面的差异。
-
(a) 重建目标(Reconstruction)
这部分展示了基于重建损失的SSL模型的预训练目标。这些目标通常是原始的声学特征(例如梅尔频谱图)。图中显示了这些特征对输入音频的随机扰动(如回声和噪声)非常敏感。-
观察结果:
-
同一音频的不同扰动版本在特征空间中可能相距较远。
-
不同类别音频的特征可能非常接近,导致模型难以区分。
-
-
结论:
重建目标主要关注低层次的时频特征,缺乏对音频语义的抽象,因此对噪声和扰动非常敏感。
-
-
(b) BEATSiter3的预训练目标
这部分展示了使用BEATS框架进行预训练时的离散标签目标。这些目标是由自蒸馏分词器生成的,其“教师”模型是BEATSiter2(一个自监督预训练模型)。-
观察结果:
-
同一音频的不同扰动版本在特征空间中聚集在一起,表明这些目标对扰动具有较强的鲁棒性。
-
不同类别的音频在特征空间中被较好地分离,说明这些目标能够捕捉到音频的语义信息。
-
-
结论:
BEATSiter3的目标通过自监督学习提取了音频的高级语义特征,从而在特征空间中更好地表示音频的语义类别。
-
-
(c) BEATSiter3+的预训练目标
这部分展示了BEATS框架中使用微调后的模型(BEATSiter2)作为“教师”时的预训练目标。这些目标同样由自蒸馏分词器生成,但“教师”模型经过了监督学习的微调。-
观察结果:
-
相比BEATSiter3,BEATSiter3+的目标对扰动的鲁棒性更强,且不同类别的音频在特征空间中被更清晰地分离。
-
这些目标不仅捕捉了音频的语义信息,还通过监督学习进一步优化了语义表示。
-
-
结论:
BEATSiter3+的目标能够更准确地表示音频的语义类别,同时对输入音频的低层次细节(如噪声和回声)具有更强的鲁棒性。
-


















 707
707

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











