









目录
一、 数据容器(list、tuple、str、map、dict)
2.5 list列表的使用(列表的方法:追加元素或列表、获取元素等等..)
3. 元组tuple( () )&& ( tuple()空元组 )
4. 字符串str(python中也是一个容器)( "" )
4.2 字符串的下标索引(字符串是一个无法修改的数据容器,如果要修改则是一个新的字符串)字符串容器操作
5. 序列(list、tuple、str都可以视为序列)使用:[ 起始下标: 结束下标: 步长1]
5.1 序列-切片(序列中的元素可以被取出成为一个新的数据容器,因为序列中有str,tuple不支持修改)
6. 集合( {} )(注意定义空集合的时候不能用{}定义,因为{}被空字典占用了该使用(set()定义一个空集合))
6.2 集合的操作(集合.add添加 && 集合.remove移除)(set()空集合的意思并非是一个方法)
6.2.3 取出两个集合的差集:集合1.difference(集合2)
6.2.4 消除2个集合的差集:集合1.difference_update(集合2)
6.2.6 统计集合元素的数量:len(集合) && 集合的便利 for循环(为什么不用while循环呢,因为集合是没有下标的,所有不能用while循环,集合不支持下标索引)
7.3.2 删除 && 清空(.pop(key) && .clear())
7.3.3 便利字典(.keys()获取全部的key)for循环遍历全部的key获取value(获取字典的长度)
9.3 通用-类型转换(list(容器)、str(容器)、tuple(容器)、set(容器))
导航:
Python第二语言(一、Python start)-CSDN博客
Python第二语言(二、Python语言基础)-CSDN博客
Python第二语言(三、Python函数def)-CSDN博客
Python第二语言(四、Python数据容器)-CSDN博客
Python第二语言(五、Python文件相关操作)-CSDN博客
Python第二语言(九、Python第一阶段实操)-CSDN博客
Python第二语言(十、Python面向对象(上))-CSDN博客
Python第二语言(十一、Python面向对象(下))-CSDN博客
Python第二语言(十二、SQL入门和实战)-CSDN博客
Python第二语言(十三、PySpark实战)-CSDN博客
一、 数据容器(list、tuple、str、map、dict)
1. 数据容器概念
Python中的数据容器:一种可以容纳多份数据的数据类型,容纳的每一份数据称之为1个元素每一个元素,可以是任意类型的数据,如字符串、数字、布尔等;
- 数据容器根据特点的不同,如:
- 是否支持重复元素;
- 是否可以修改;
- 是否有序,等;
分为5类,分别是:列表(list)、元组(tuple)、字符串(str)、集合(set)、字典(dict)
2. 列表list( [] )
2.1 定义方式
name_list = ['yiyi', 'zhangsan', 'lisi']
print(name_list)
print(type(name_list))
my_list = ['yiyi', 18, True]
print(my_list)
print(type(my_list))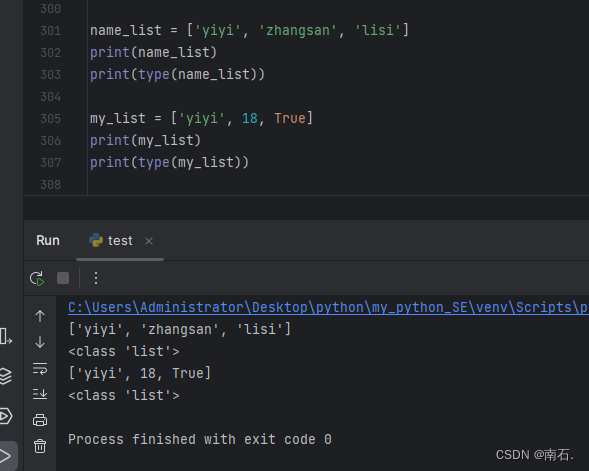
2.2 嵌套列表
my_list = [[1, 2, 3], [4, 5, 6]]
print(my_list)
print(type(my_list))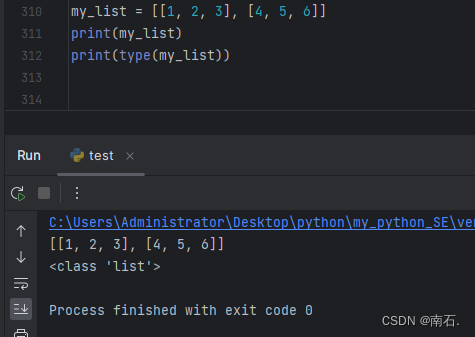
2.3 list通过获取下标索引获取值
- list获取值可用直接通过下标获取,比如xx[0],xx[1],xx[2]...
- list反向通过下标索引取值,依次递减,-1是最后一个值,-2是倒数第二个值,以此类推;
name_list = ['yiyi', 'zhangsan', 'lisi']
print(name_list[-1])
print(name_list[-2])
print(name_list[-3])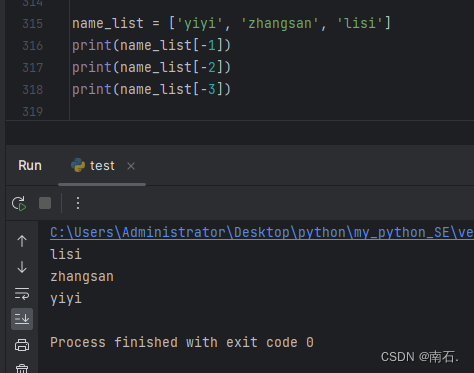
2.4 下标使用概念
- 列表的下标索引:
- 列表的每一个元素,都有编号称之为下标索引;
- 从前向后的方向,编号从0开始递增;
- 从后向前的方向,编号从-1开始递减;
- 通过下标索引取出对应位置的元素:
- 列表[下标],即可取出;
- 下标索引的注意事项;
- 要注意下标索引的取值范围,超出范围无法取出元素,并且会报错;
2.5 list列表的使用(列表的方法:追加元素或列表、获取元素等等..)
# 1.定义这个列表,并用变量接受它
myList = [10, 20, 30, 40, 50]
# 2.追加一个数字60,到列表的尾部
myList.append(60)
# 3.追加一个新列表[70, 80, 90],到列表的尾部
myList.extend([70, 80, 90])
# 4.取出第一个元素(10)
num1 = myList[0]
print(f"列表的第一个元素是:{num1}")
# 5.取出最后一个元素(90)
num2 = myList[-1]
print(f"列表的最后一个元素是:{num2}")
# 6.查询元素30,在列表中的下标位置
index = myList.index(30)
print(f"元素30在列表中的下标位置是:{index}")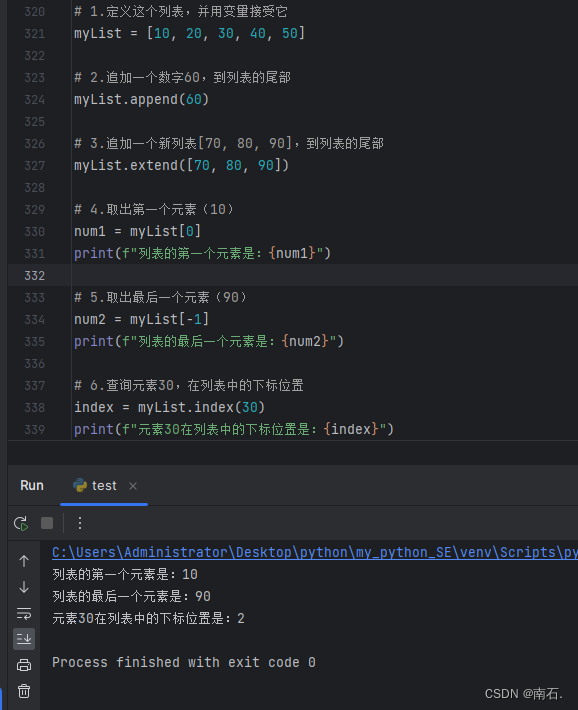
2.6 list列表删除
1. 根据索引值删除元素list[index];
# 根据索引值删除元素
# 1.定义这个列表,并用变量接受它
myList = [10, 20, 30, 40, 50]
# 2.del根据列表索引下标删除元素
del myList[2]
print("删除后的列表值:" + str(myList)) # [10, 20, 40, 50]
# 3.del删除区间的元素,del list[start : end]
myList = [10, 20, 30, 40, 50]
del myList[0 : 2]
print("根据区间删除后的列表值:" + str(myList)) # [30, 40, 50]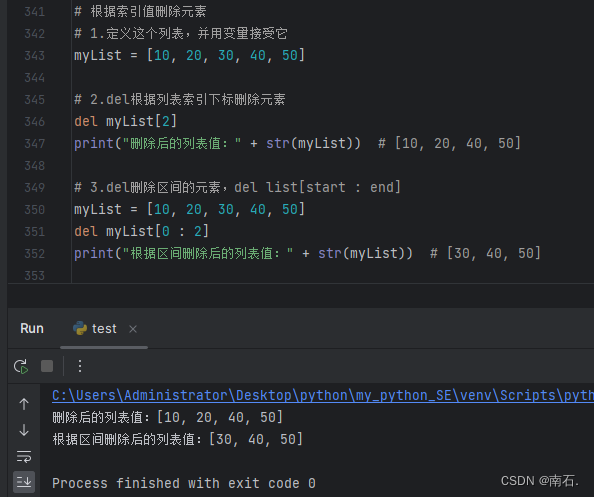
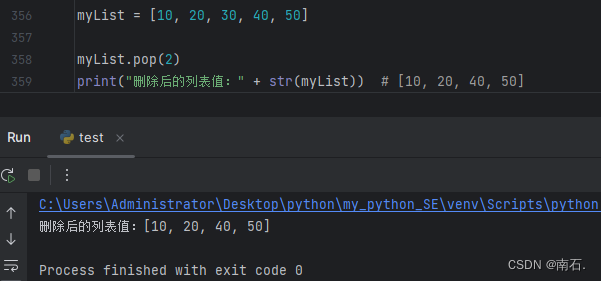
2. 根据索引值删除元素.pop(index);
3. 根据元素的值进行删除.remove(value);
# 根据元素值进行删除
myList = [10, 20, 30, 40, 50]
myList.remove(30)
print("删除后的列表值:" + str(myList))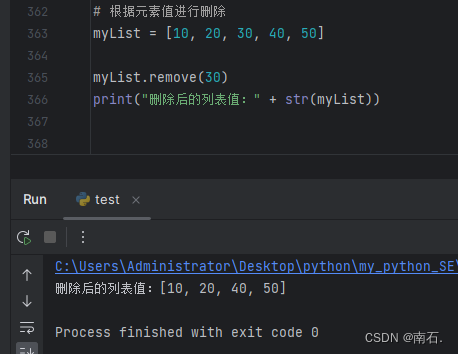
4. 删除列表的所有元素.clear();
myList = [10, 20, 30, 40, 50]
# 删除整个列表的值
myList.clear()
print(myList)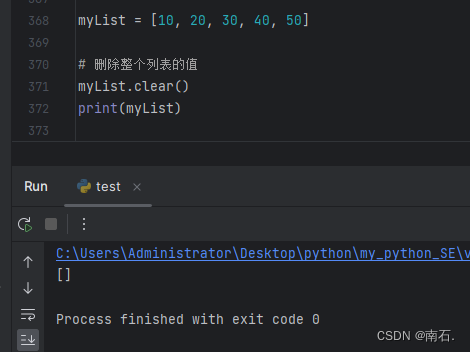
2.7 list列表的便利-循环
数据容器可以存储多个元素,匿名就会有需求从容器内依次取出元素进行操作;
将容器内的元素依次取出进行处理的行为,称之为:遍历,迭代;
def list_for_func():
"""
使用for循环遍历列表
:return: None
"""
my_list = [1, 2, 3, 4, 5]
for my in my_list:
print(f"列表的元素有:{my}")
list_for_func()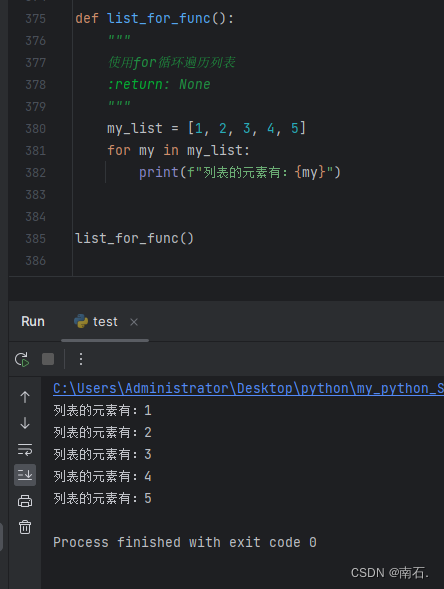
3. 元组tuple( () )&& ( tuple()空元组 )
3.1 定义元组
定义元组使用小括号,且使用逗号隔开各个数据,数据可以是不同的数据;
# 定义3个元素的元组
t1 = (1, 'hello', True)
# 定义1个元素的元组
t2 = ('hello',) # 注意:必须带有逗号,否则不是元组类型
print(t1)
print(t2)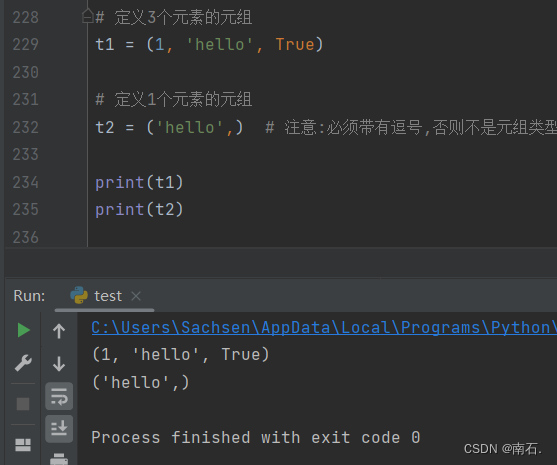
3.2 元组相关操作
| 方法 | 作用 |
| index() | 查找某个数据,如果数据存在返回对应的下标,否则报错 |
| count() | 统计某个数据在当前元组出现的次数 |
| len(元组) | 统计元组内的元素个数 |
# 1.根据下标(索引)取出数据
t1 = (1, 2, 'hello')
print(t1[2])
# 2.根据index(),查找特定元素的第一个匹配项
t2 = (1, 2, 'hello', 3, 4)
print(t2.index('hello'))
# 3.统计某个数据在元组内出现的次数
t3 = (1, 2, 'hello', 2, 4)
print(t3.count(2))
# 4.统计元组内的元素个数
t4 = (1, 2, 3)
print(len(t4))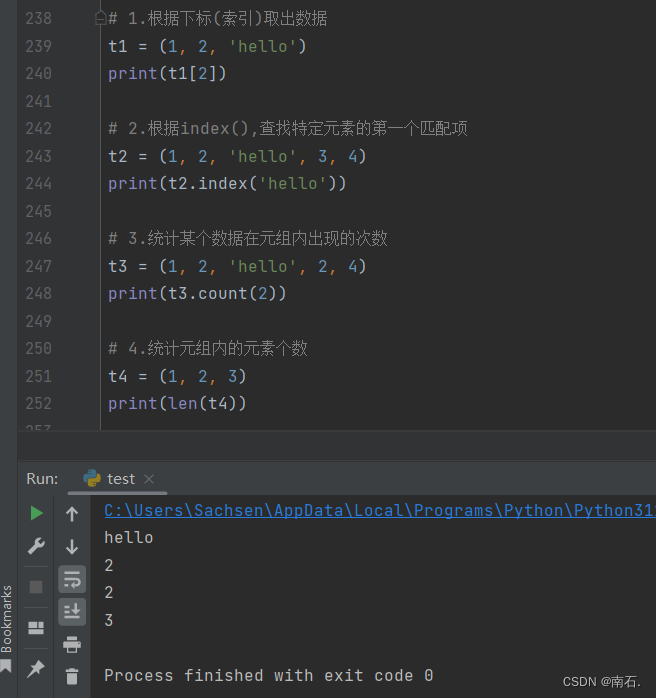
- 元组中定义list是可以被修改的:
- 但是注意:元组中的内容是不可以修改的;

# 可以修改元组内的list内容
t1 = (1, 2, ['hello', 'zhangSan'])
t1[2][0] = '你好'
print(t1)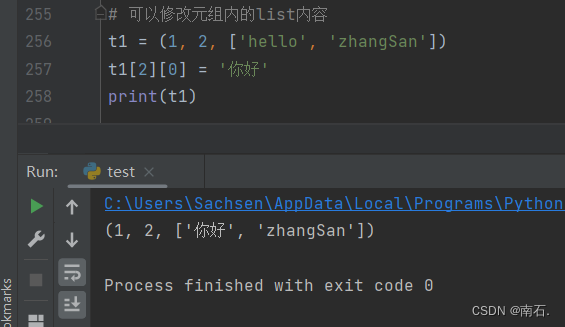
4. 字符串str(python中也是一个容器)( "" )
4.1 字符串概念
字符串是字符的容器,一个字符串可以存放任意数量的字符;
- 获取字符串:
- 和其他容器如:列表、元组一样,字符串也可以通过下标进行访问;
- 从前向后,下标从0开始;
- 从后向前,下标从-1开始;
name = "yiyi"
print(name[0])
print(name[-1])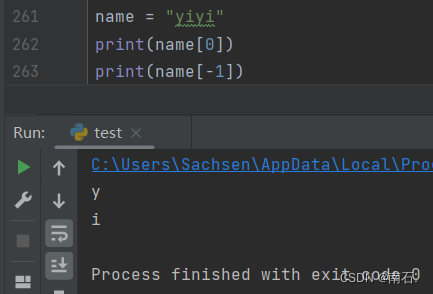
4.2 字符串的下标索引(字符串是一个无法修改的数据容器,如果要修改则是一个新的字符串)字符串容器操作
- 同元组一样,字符串是一个:无法修改的数据容器:
- 修改指定下标的字符(如:字符串[0] = "a")
- 移除特定下标的字符(如:del字符串[0]、字符串.remove()、字符串.pop()等)
- 追加字符等(如:字符串.append())
1. 根据字符串下标获取字符串[下标]:
name = "zhangSan"
print(name[5])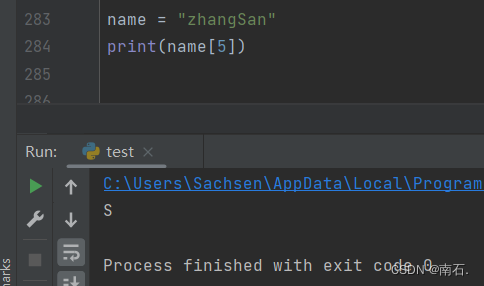
2. 字符串字符串.index("xxxx")方法获取字符串起始下标:
my_str = "hello yiyi"
print(my_str.index("yiyi"))
3. 字符串的替换字符串.replace(字符串1,字符串2):
- 语法:字符串.replace(字符串1,字符串2);
- 功能:将字符串内的全部:字符串1,替换为字符串2;
- 注意:不是修改字符串本身,而是得到了一个新字符串;
4. 字符串的分割 字符串.split(分隔字符串):
- 语法:字符串.split(分隔字符串);
- 功能:按照指定的分隔符字符串,将字符串划分为多个字符串,并存入列表对象中;
- 注意:字符串本身不变,而是得到了一个列表对象;
5. 字符串去除前后空格 字符串.strip() :字符串去除指定字符串 字符串.strip():
# 去除前后空格
my_str = " zhangSan is attorney "
print(my_str.strip())
# 去除前后指定字符串
my_str1 = "123zhangSan"
print(my_str1.strip("123"))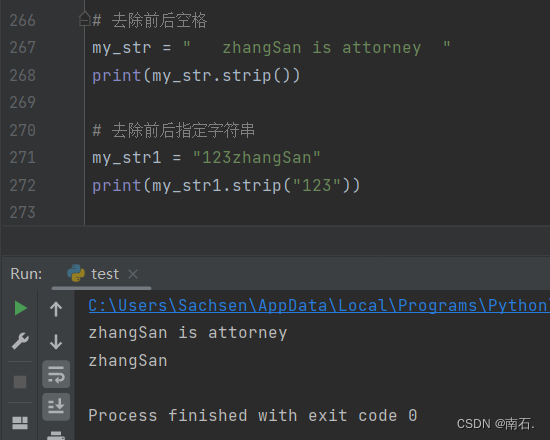
6. 统计字符串出现的次数 字符串.count(字符串) :
# 统计字符串中某字符串的出现次数,count
my_str = "hello yiyi, my yiyi"
count = my_str.count("yiyi")
print(f"字符串{my_str}中出现yiyi的次数是:{count}")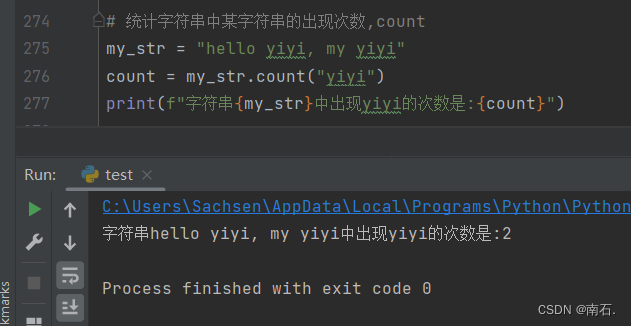
7. 字符串.len(字符串):统计字符串的字符个数;
my_str = "hello yiyi, my yiyi"
print(len(my_str))
5. 序列(list、tuple、str都可以视为序列)使用:[ 起始下标: 结束下标: 步长1]
- 序列概念:内容连续、有序,可使用下标索引的一类数据容器:列表、元组、字符串,均可以视为序列;
5.1 序列-切片(序列中的元素可以被取出成为一个新的数据容器,因为序列中有str,tuple不支持修改)
- 序列支持切片,即:列表、元组、字符串,均支持进行切片操作;
- 切片:从一个序列中,取出一个子序列;
- 语法:
序列[起始下标:结束下标:步长]- 表示从序列中,从指定位置开始,依次取出元素,到指定位置结束,得到一个新序列;
- 起始下标表示从何处开始,可以留空,留空视作从头开始;
- 结束下标(不含)表示何处结束,可以留空,留空视作截取到结尾;
- 步长表示,依次取元素的间隔;
- 步长1表示,一个个取元素;
- 步长2表示,每次跳过1个元素取;
- 步长N表示,每次跳过N-1个元素取;
- 步长为负数表示,反向取(注意,起始下标和结束下标也要反向标记);
1. 对数据类型使用:
# 对list进行切片,从1开始,4结束,步长1
my_list = [0, 1, 2, 3, 4, 5, 6]
print(f"结果1:{my_list[1:4]}") # 步长默认是1,可以省略:(从下标1开始,到下标4结束,不包含下标4)
# 对tuple进行切片,从头开始,到最后结束,步长1
my_list1 = (0, 1, 2, 3, 4, 5, 6)
print(f"结果2:{my_list1[:]}") # 起始和结束不写表示从头到尾,步长1可以省略
# 对str进行切片,从头开始,到最后结束,步长2
my_str = "0123456789"
print(f"结果3:{my_str[::2]}")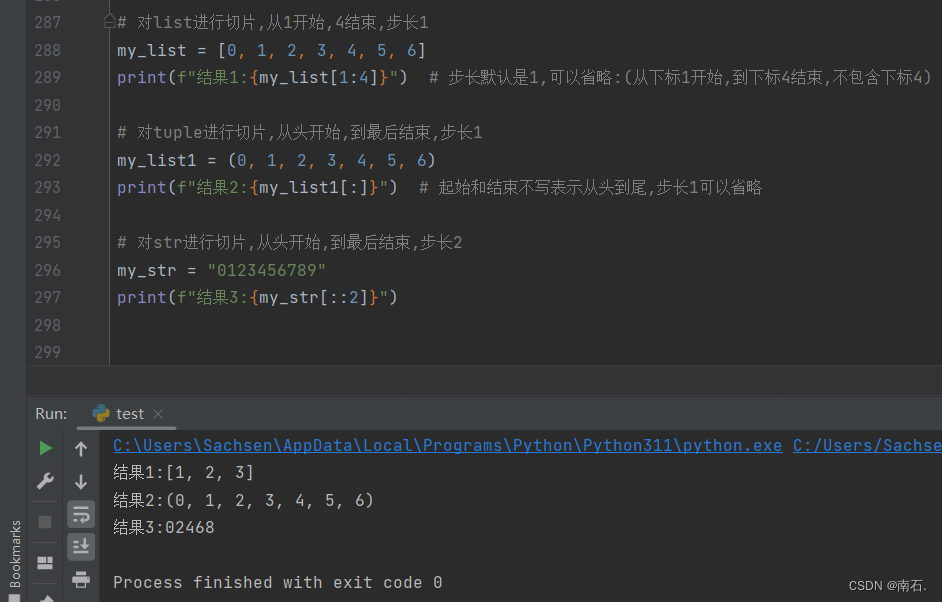
2. 对数据类型切片反转操作:
# 对str进行切片,从头开始,到最后结束,步长-1
my_str = "0123456789"
print(f"结果4:{my_str[::-1]}") # 等同于将序列反转了
# 对列表进行切片,从3开始,到1结束,步长-1
my_list = [0, 1, 2, 3, 4, 5, 6]
print(f"结果5:{my_list[3:1:-1]}")
# 对元组进行切片,从头开始,到尾结束,步长-2
my_tuple = (0, 1, 2, 3, 4, 5, 6)
print(f"结果6:{my_tuple[::-2]}")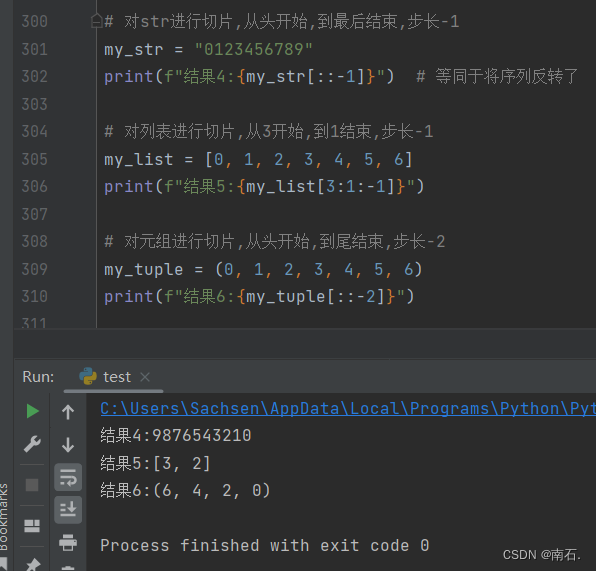
6. 集合( {} )(注意定义空集合的时候不能用{}定义,因为{}被空字典占用了该使用(set()定义一个空集合))
6.1 集合的定义{}
# 定义集合字面量
{'元素', '元素', ..., '元素'}
# 定义集合变量
变量名称 = {'元素', '元素', ..., '元素'}
# 定义空集合
变量名称 = set()6.2 集合的操作(集合.add添加 && 集合.remove移除)(set()空集合的意思并非是一个方法)
- 集合中的值都是无序不可重复的,且删除元素的时候也没有指定下标删除,而是随机删除的。
6.2.1 add && remove(添加、移除)
# 集合.add(元素),将元素添加到集合内
my_set = {"hello", "world"}
my_set.add("yiyi")
print(my_set)
# 集合.remove(元素),将指定元素,从集合内移除
my_set.remove("hello")
print(my_set)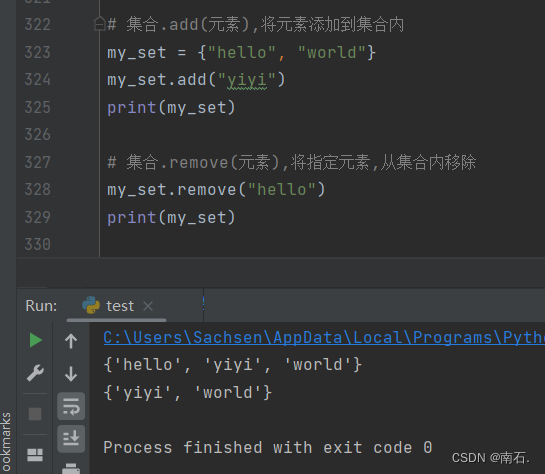
6.2.2 pop && clear(移除、清空)
# 集合.pop(),从集合中随机取出一个元素
my_set = {"hello", "world", "yiyi"}
print(my_set.pop())
# 集合.clear(),清空集合
print(my_set.clear())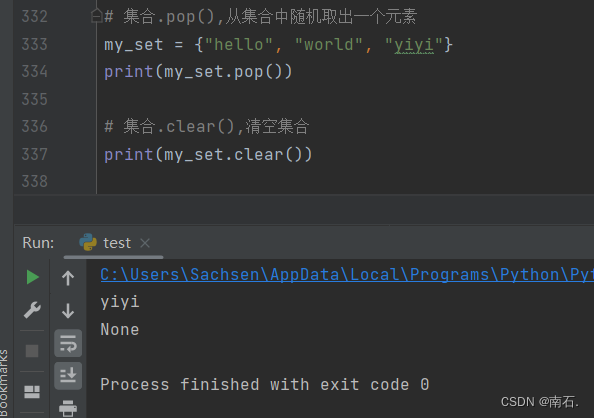
6.2.3 取出两个集合的差集:集合1.difference(集合2)
# 取出2个集合的差集
# 集合1.difference(集合2),功能:取出集合1和集合2的差集(集合1有而集合2没有的)
# 会返回一个新的集合,集合1和集合2不变
set1 = {1, 2, 3}
set2 = {1, 5, 6}
set3 = set1.difference(set2)
print(set1)
print(set2)
print(set3)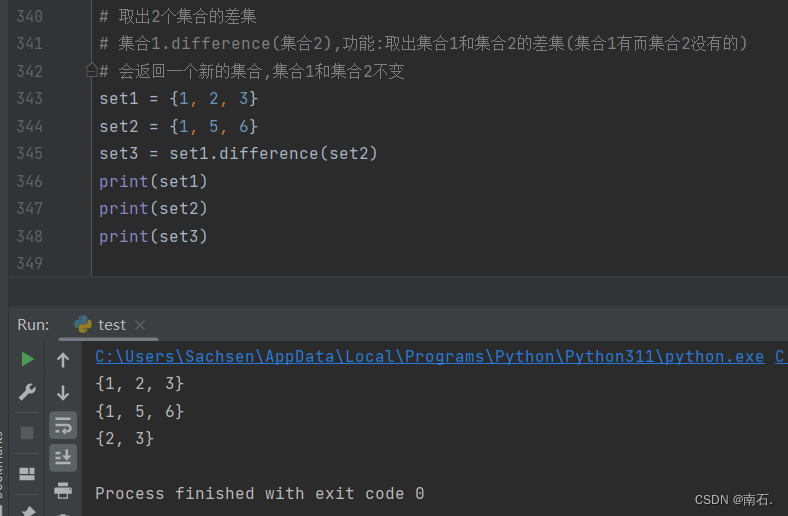
6.2.4 消除2个集合的差集:集合1.difference_update(集合2)
# 消除2个集合的差集
set1 = {1, 2, 3}
set2 = {1, 5, 6}
set1.difference_update(set2) # 对比集合1和集合2,在集合1内,删除和集合2相同的元素
print(set1)
print(set2)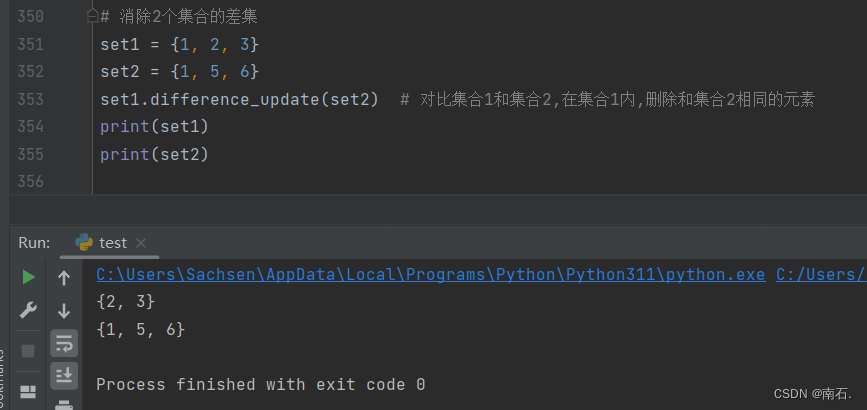
6.2.5 two个集合合并:集合1.union(集合2)
# 集合1.union(集合2): 2个集合合并,将集合1和集合组合成新集合
set1 = {1, 2, 3}
set2 = {1, 5, 6}
set3 = set1.union(set2) # set无序不重复
print(set3)
print(set2)
print(set1)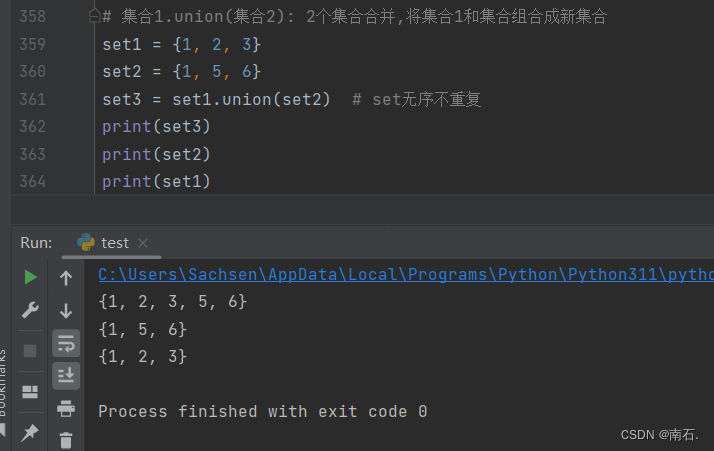
6.2.6 统计集合元素的数量:len(集合) && 集合的便利 for循环(为什么不用while循环呢,因为集合是没有下标的,所有不能用while循环,集合不支持下标索引)
# 统计集合元素数量len()
set1 = {1, 2, 3}
print(f"集合数量有:{len(set1)}")
print("-------------------")
# 集合遍历
set2 = {1, 5, 6}
for x in set2:
print(f"集合元素有:{x}")
6.2.7 集合小结
- 可以容纳多个数据;
- 可以容纳不同类型的数据(混装);
- 数据是无序存储的(不支持下标索引);
- 不允许重复数据存在;
- 可以修改(增加活删除元素等);
- 支持for循环;
7. 字典( {} )&& ( dict()空字典 )
7.1 字典的定义
- 字典的key和value可以是任意数据类型(但是key不可为字典)
- 不允许key的重复
# 定义字典字面量
{ket: value, key: value,...}
# 定义字段变量
my_dict = {key: value, key: value,...}
# 定义空字典
my_dict = {}
my_dict = dict()- 字典通过key值来获取对应的value;
# 语法:字典[key]可以取到对应的value
stu_score = {"yiyi": 80, "zhangSan": 85, "lisi": 90}
print(stu_score["yiyi"])
print(stu_score["zhangSan"])7.2 定义嵌套字典 及 获取嵌套字典中的数据
# 嵌套字典
stu_score_dict = {
"zhangSan": {
"语文": 80,
"数学": 95,
"英语": 80
},
"lisi": {
"语文": 85,
"数学": 100,
"英语": 90
}
}
print(stu_score_dict)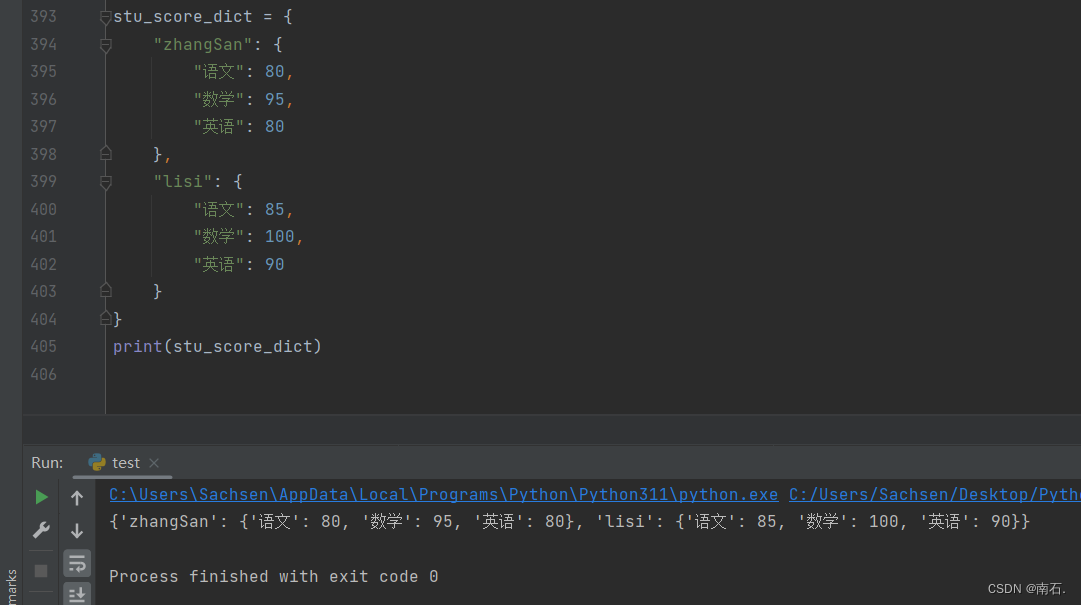
根据字典中的key获取:
# 嵌套字典
stu_score_dict = {
"zhangSan": {
"语文": 80,
"数学": 95,
"英语": 80
},
"lisi": {
"语文": 85,
"数学": 100,
"英语": 90
}
}
score = stu_score_dict["zhangSan"]["语文"] # 根据key查询嵌套字典中的value
print(f"zhangSan的语文分数是:{score}")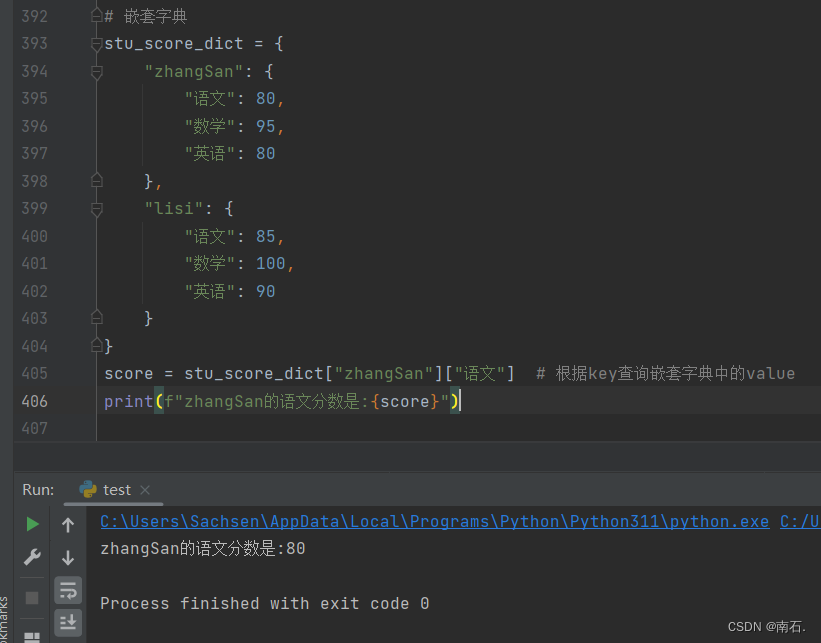
7.3 字典的操作
7.3.1 新增 && 更新([key]=value)
- 不存在就新增,存在就更新
stu_score = {
"yiyi": 88,
"lisi": 99
}
stu_score["zhangSan"] = 77 # 新增原损
print(stu_score)
stu_score["yiyi"] = 100 # # 更新元素:根据key更新value
print(stu_score)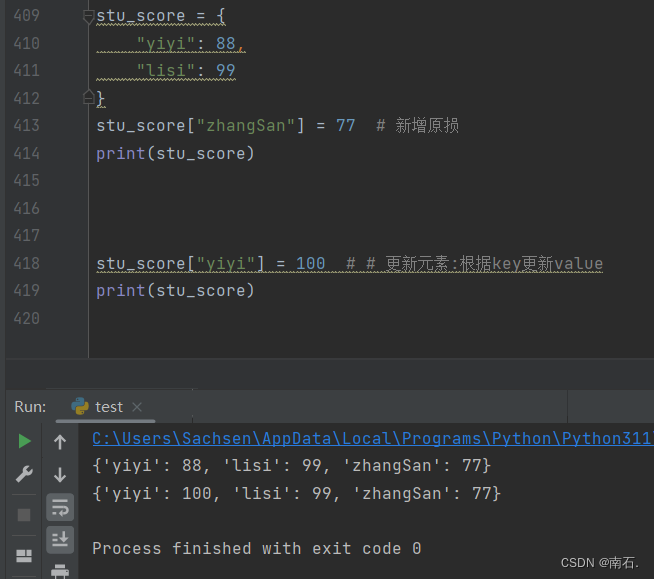
7.3.2 删除 && 清空(.pop(key) && .clear())
stu_score = {
"yiyi": 88,
"lisi": 99
}
value = stu_score.pop("yiyi") # 删除元素
print(value) # 返回删除的value
print(stu_score)
# 清空字典
stu_score.clear()
print(stu_score)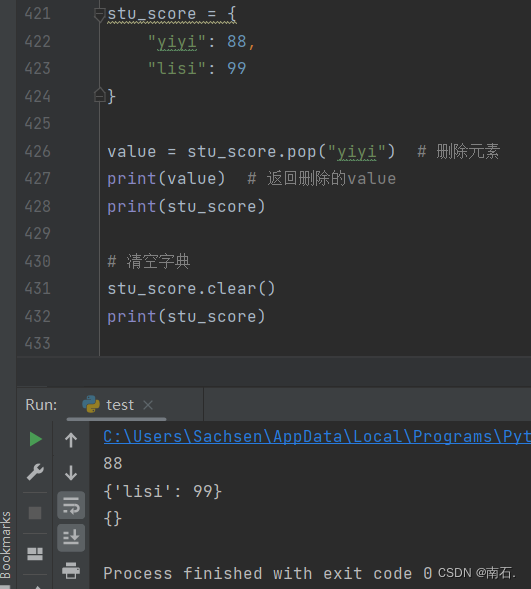
7.3.3 便利字典(.keys()获取全部的key)for循环遍历全部的key获取value(获取字典的长度)
方式一:
my_dict = {"zhangSan": 88, "lisi": 99, "wangWu": 90}
keys = my_dict.keys() # 获取全部的key
print(f"字段的全部keys是:{keys}")
# 遍历字典
for key in keys:
print(f"字典的key是:{key}")
print(f"字典的value是:{my_dict[key]}")
方式二:
my_dict = {"zhangSan": 88, "lisi": 99, "wangWu": 90}
for key in my_dict:
print(f"字典的key是:{key}")
print(f"字典的value是:{my_dict[key]}")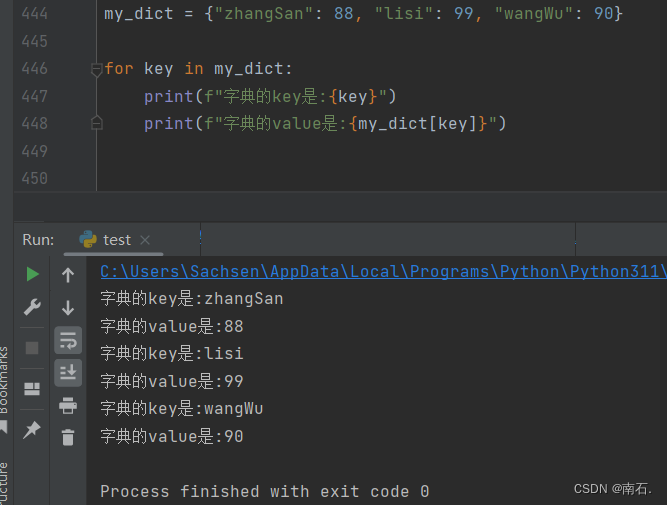
统计字典的长度:len()
my_dict = {"zhangSan": 88, "lisi": 99, "wangWu": 90}
print(f"字典的长度:{len(my_dict)}")
7.4 字典的特性
- 可以容纳多个数据;
- 可以容纳不同类型的数据;
- 每一份数据是key:value键值对;
- 可以通过ket获取到value,key不重复(重复会覆盖原始值);
- 不支持下标索引;
- 可以修改(增加活删除更新元素等);
- 支持for循环,不支持while循环;
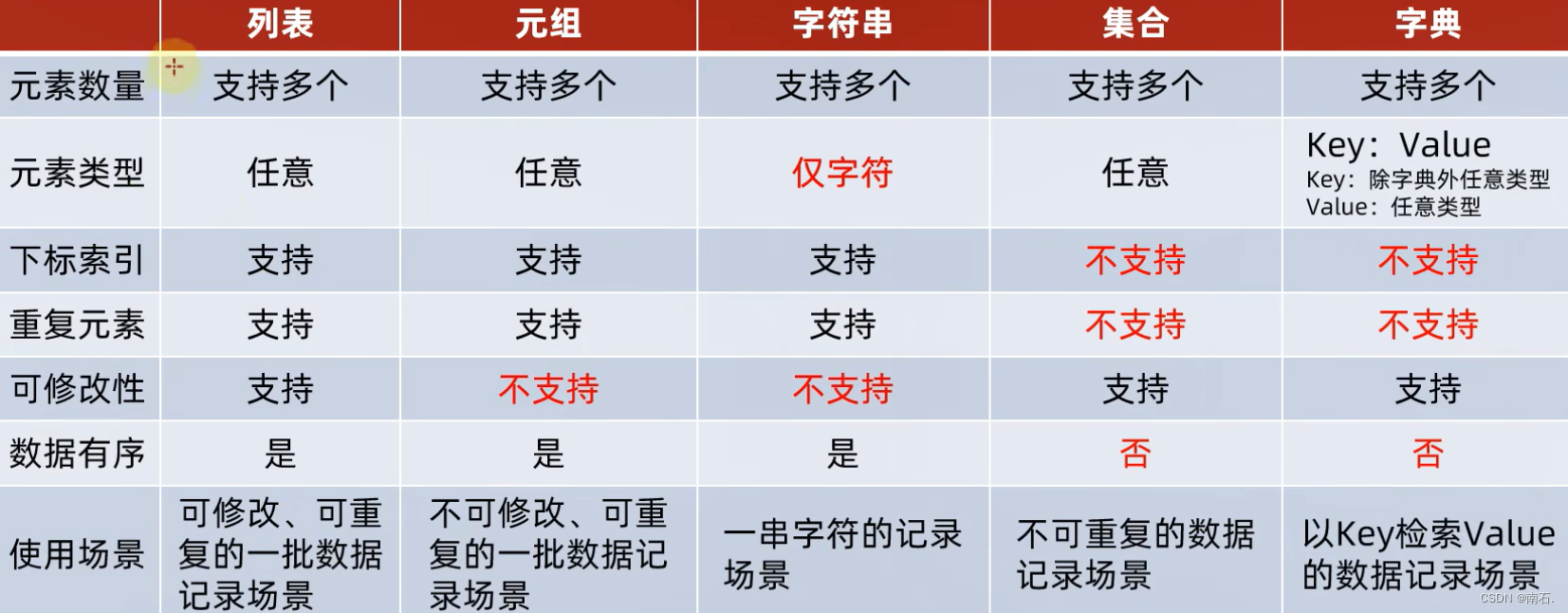
8. 数据容器小结
9. 数据容器的通用操作
9.1 通用-遍历(for || while)
- 5类数据容器都支持for循环遍历;
- 列表、元组、字符串支持while循环,集合、字典不支持(因为无下标索引,但可以使用for循环);
9.2 通用-统计功能(len、max、min)
9.2.1 len(容器):
# len(容器): 统计容器的元素个数
my_list = [1, 2, 3]
my_tuple = (1, 2, 3)
my_str = "name"
print(len(my_list))
print(len(my_tuple))
print(len(my_str))
9.2.2 max(容器):
# max(容器): 统计容器的最大元素
my_list = [1, 2, 3]
my_tuple = (1, 2, 3)
my_str = "name"
print(max(my_list))
print(max(my_tuple))
print(max(my_str))
9.2.3 min(容器):
# min(容器): 统计容器的最小元素
my_list = [1, 2, 3]
my_tuple = (1, 2, 3)
my_str = "name"
print(min(my_list))
print(min(my_tuple))
print(min(my_str))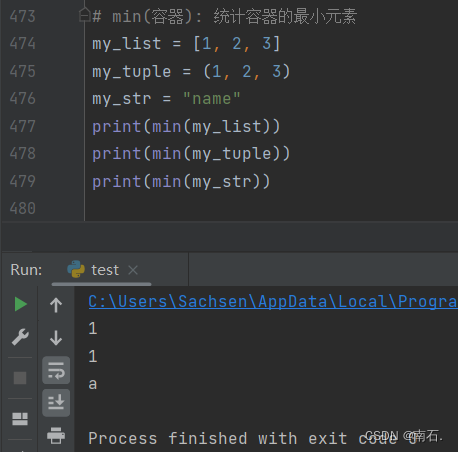
9.3 通用-类型转换(list(容器)、str(容器)、tuple(容器)、set(容器))
- list(容器):将给定容器转换为列表;
- str(容器):将给定容器转换为字符串;
- tuple(容器):将给定容器转换为元组;
- set(容器):将给定容器转换为集合;
转换过程及结果:
- 字典是不可以转换成别的类型的,因为字典是键值对的形式,而字典可以被别的类型转换。
9.3.1 物种类型转list的情况:
my_list = [1, 2, 3]
my_tuple = (1, 2, 3)
my_str = "name"
my_set = {1, 2, 3}
my_dict = {"key1": 1, "key2": 2, "key3": 3}
print(f"列表转列表:{list(my_list)}")
print(f"元组转列表:{list(my_tuple)}")
print(f"字符转列表:{list(my_str)}")
print(f"集合转列表:{list(my_set)}")
print(f"字典转列表:{list(my_dict)}")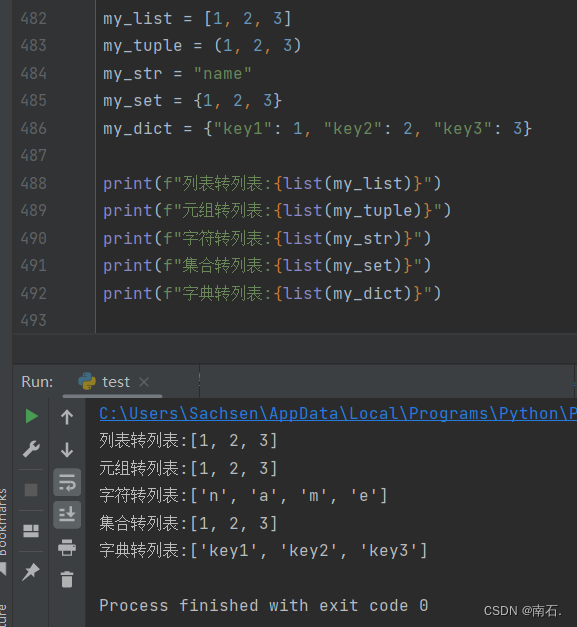
9.3.2 字符串转化
相当于把所有类型的值加了一个""双引号包裹起来成字符串;
my_list = [1, 2, 3]
my_tuple = (1, 2, 3)
my_str = "name"
my_set = {1, 2, 3}
my_dict = {"key1": 1, "key2": 2, "key3": 3}
print(f"列表转字符串:{str(my_list)}")
print(f"元组转字符串:{str(my_tuple)}")
print(f"字符转字符串:{str(my_str)}")
print(f"集合转字符串:{str(my_set)}")
print(f"字典转字符串:{str(my_dict)}")
9.3.3 集合转换过程
集合是无序的,会自动去重;
my_list = [1, 2, 3]
my_tuple = (1, 2, 3)
my_str = "name"
my_set = {1, 2, 3}
my_dict = {"key1": 1, "key2": 2, "key3": 3}
print(f"列表转集合:{set(my_list)}")
print(f"元组转集合:{set(my_tuple)}")
print(f"字符转集合:{set(my_str)}")
print(f"集合转集合:{set(my_set)}")
print(f"字典转集合:{set(my_dict)}")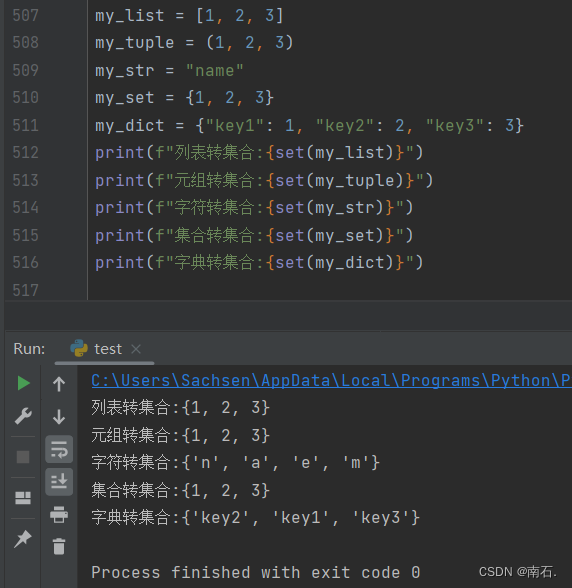
9.4 通用-排序(sorted(容器))
- 默认是从大到小,加上
sorted(容器, [reverse=True])会将排序的结果反转,给定容器进行排序; - 及排序的结果都会变成列表对象;
my_list = [4, 1, 2, 3]
my_tuple = (4, 1, 2, 3)
my_str = "name"
my_set = {4, 1, 2, 3}
my_dict = {"key4": 1, "key1": 1, "key2": 2, "key3": 3} # 根据key排序
print(f"列表对象的排序结果:{sorted(my_list)}")
print(f"元组对象的排序结果:{sorted(my_tuple)}")
print(f"字符对象的排序结果:{sorted(my_str)}")
print(f"集合对象的排序结果:{sorted(my_set)}")
print(f"字典对象的排序结果:{sorted(my_dict)}")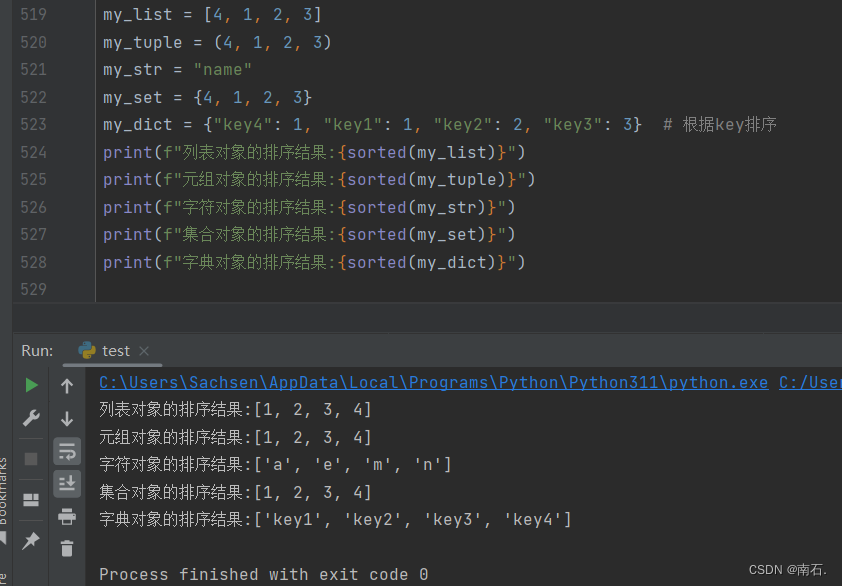















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









