






目录
1 数据集
User Behavior Data from Taobao for Recommendation
阿里云天池数据集: User Behavior Data from Taobao for Recommendation
1.1 概述
UserBehavior是阿里巴巴提供的一个淘宝用户行为数据集,用于隐式反馈推荐问题的研究。
1.2 介绍
| 文件名称 | 说明 | 包含特征 |
|---|---|---|
| UserBehavior.csv | 包含所有的用户行为数据 | 用户ID,商品ID,商品类目ID,行为类型,时间戳 |
UserBehavior.csv
本数据集包含了 2017年11月25日至2017年12月3日 之间,有行为的约 一百万随机用户 的所有行为(行为包括点击、购买、加购、喜欢)。数据集的组织形式和MovieLens-20M类似,即数据集的每一行表示一条用户行为,由用户ID、商品ID、商品类目ID、行为类型和时间戳组成,并以逗号分隔。关于数据集中每一列的详细描述如下:
| 列名称 | 说明 |
|---|---|
| 用户ID | 整数类型,序列化后的用户ID |
| 商品ID | 整数类型,序列化后的商品ID |
| 商品类目ID | 整数类型,序列化后的商品所属类目ID |
| 行为类型 | 字符串,枚举类型,包括('pv', 'buy', 'cart', 'fav') |
| 时间戳 | 行为发生的时间戳 |
注意到,用户行为类型共有四种,它们分别是
| 行为类型 | 说明 |
|---|---|
| pv | 商品详情页pv,等价于点击 |
| buy | 商品购买 |
| cart | 将商品加入购物车 |
| fav | 收藏商品 |
关于数据集大小的一些说明如下
| 维度 | 数量 |
|---|---|
| 用户数量 | 987,994 |
| 商品数量 | 4,162,024 |
| 用户数量 | 987,994 |
| 商品类目数量 | 9,439 |
| 所有行为数量 | 100,150,807 |
2环境准备
2.1 安装 jdk 工具包
因为 kettle 是Java写的,它需要 Java 的运行环境。其实只需要下载 jre 即可。然后配置好环境变量。
2.2 安装 Kettle
下载 kettle,Kettle 的作用类似于ORM框架,比如像EF、SqlSugar,Mybatis。。。
2.3 MySQL 驱动
下载 connector,下载后将其移动到 kettle 的 lib 目录即可。
因为Kettle 是Java写的,要与数据库连接,需要下载 JDBC 驱动。
2.4 运行 Kettle
在 window 中只需要点击 spoon.bat 即可。
3 将亿级数据导入 MySQL
3.1 建立库表
首先创建数据库和数据表:
create database taobao;
use taobao;
create table user_behavior (user_id int(9), item_id int(9), category_id int(9), behavior_type varchar(5), timestamp int(14) );3.2 CSV 输入
在 Kettle 中建立转换,CSV 作为输入,表作为输出,并建立连接:

导入 CSV 文件,修改字段。

3.3 表输出
连接数据库:
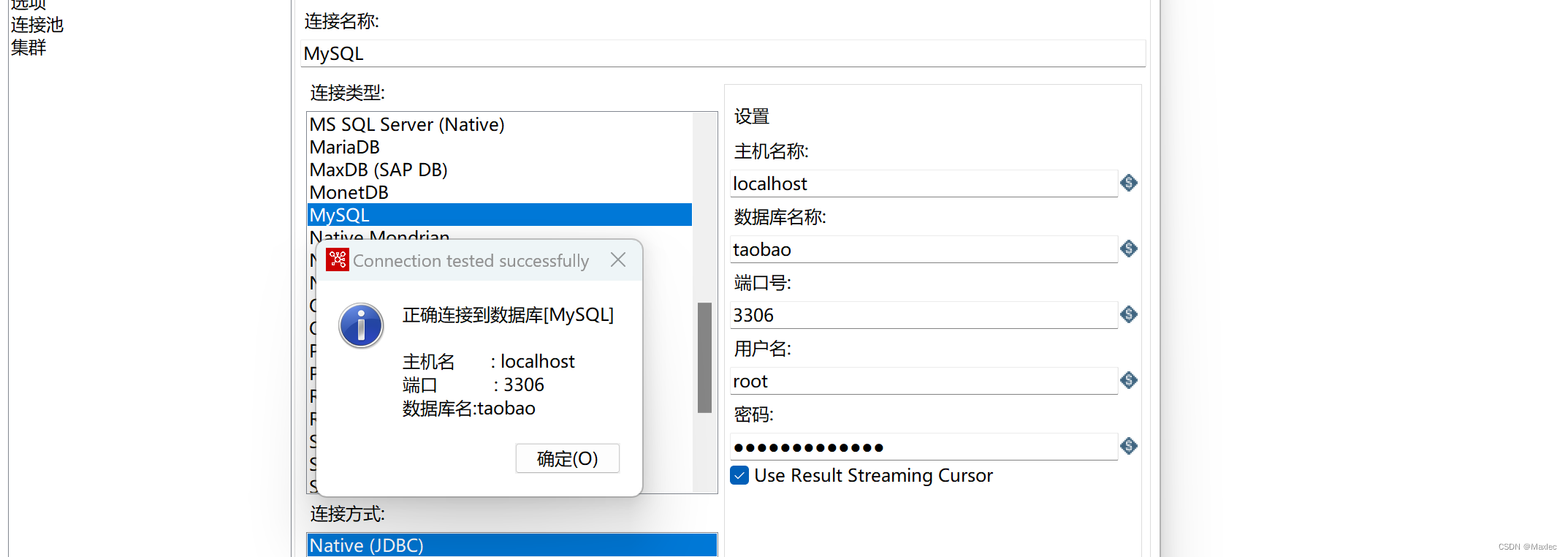
数据量较大,配置使用连接池,后续开启多线程处理:

设置参数,开启批处理:

输出目标:

开启15个线程复制:
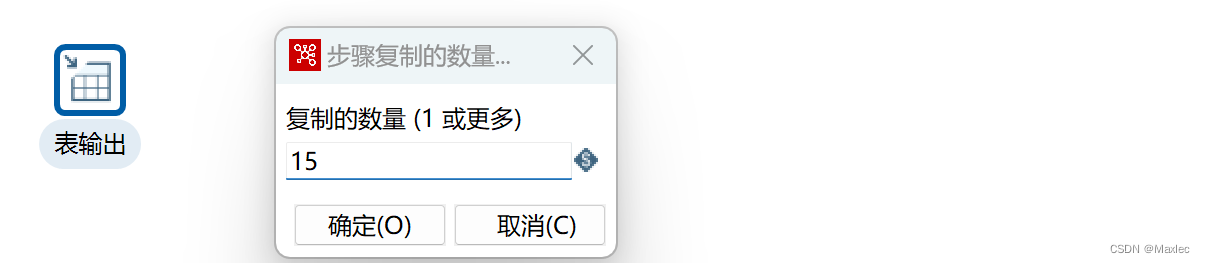
启动转换:

导入成功:

数据表总共包含一亿零十五万条记录。
4 数据预处理
其实一般是要新建临时表进行测试,再对原表下手。
create table temp_behavior like user_behavior; insert into temp_behavior select * from user_behavior limit 100000; -- 截取0-10万数据进行测试
字段处理
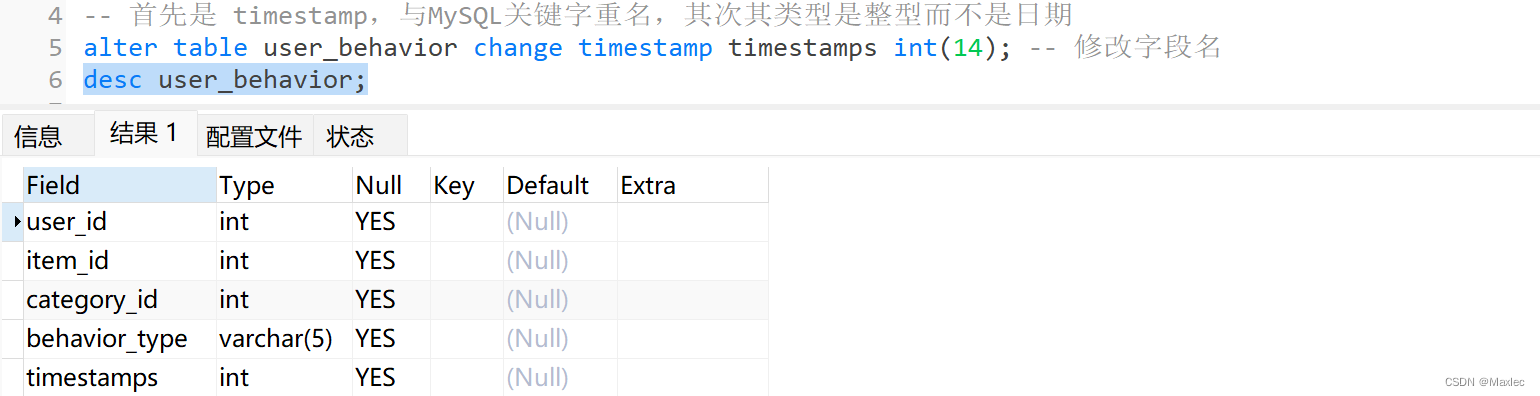
开始预处理三部曲:
检测空值(去空)
全部字段无空值。
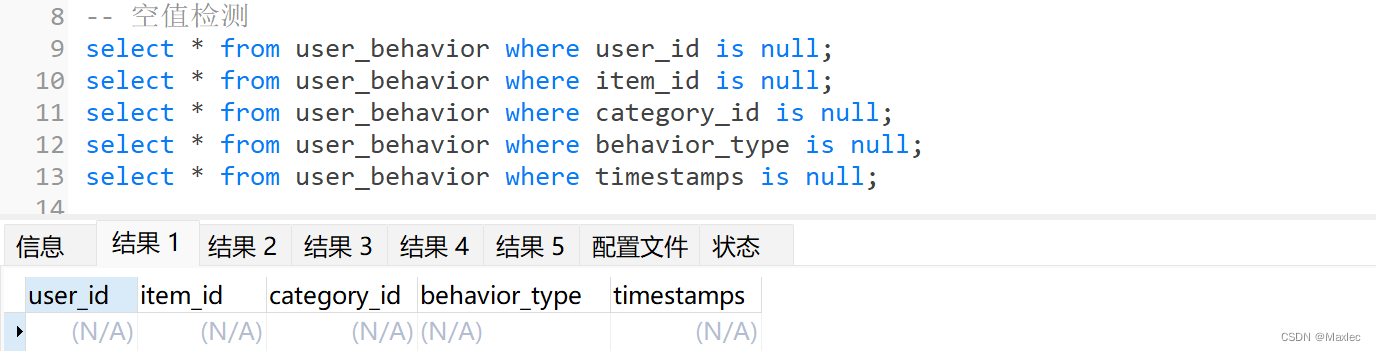
检测重复值(去重)
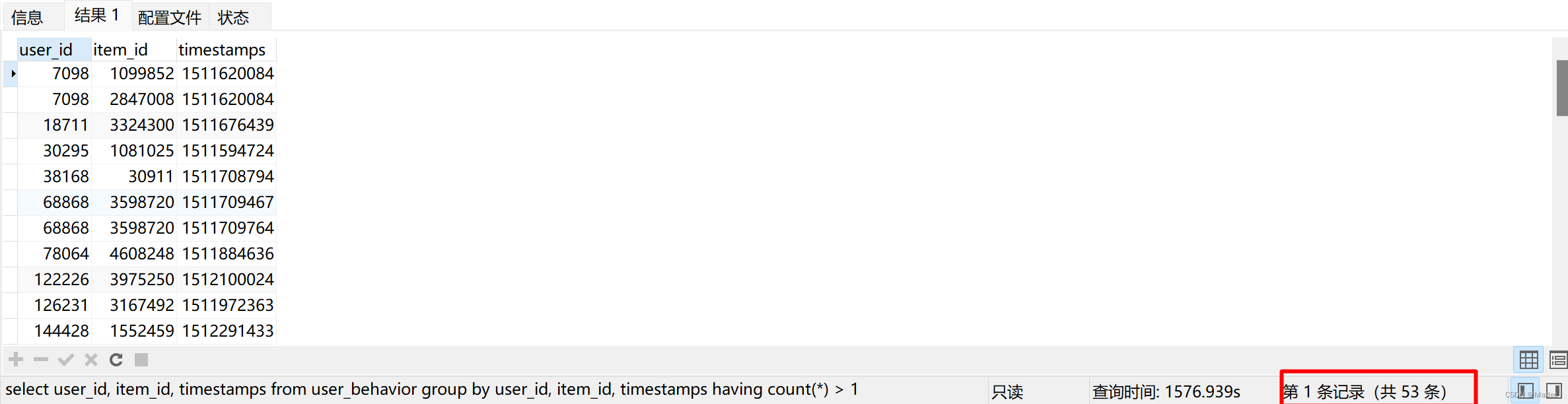
-- 查看重复的行
select user_id, item_id, timestamps
from user_behavior
group by user_id, item_id, timestamps
having count(*) > 1;可以看到有53条分组存在重复。
首先创建 id 自增字段辅助去重:
alter table user_behavior add column id int unsigned not null AUTO_INCREMENT PRIMARY KEY FIRST去重语句:利用重复行新建临时表,记录重复行中 id 最小的值。删除表 user_behavior 中符合连接条件的记录,保留每组相同 user_id、item_id 和 timestamps 下的最小 id。
DELETE user_behavior from user_behavior,
(
select user_id, item_id, timestamps, min(id) id
from user_behavior
group by user_id, item_id, timestamps
having count(*) > 1
) t2
where user_behavior.user_id = t2.user_id
and user_behavior.item_id = t2.item_id
and user_behavior.timestamps = t2.timestamps
and user_behavior.id > t2.id完成去重:

添加字段
首先修改缓存,默认是1Mb。我们直接改为10G,10871635968。

新增 datetimes 字段。并将 timestamps 的 int 型改为日期型,赋值给 datetimes。
-- 新增datetimes字段
alter table user_behavior add datetimes TIMESTAMP(0); -- 新建日期字段,去掉毫秒
UPDATE user_behavior set datetimes = FROM_UNIXTIME(timestamps); -- 将timestamps的int型改为日期型,赋值给datetimes
-- 注意:删除datetimes中可能存在的 null 值,因为虽然检测了空值,转换的时候有些timestamps不满足转换条件
delete from user_behavior where datetimes is null;
新增 dates、times、hours 字段。并截取 datetimes 填充。
alter table user_behavior add dates char(10);
alter table user_behavior add times char(8);
alter table user_behavior add hours char(2);
UPDATE user_behavior set dates = substring(datetimes, 1, 10), times = substring(datetimes, 12, 8), hours = substring(datetimes, 12, 2);
查看效果:
SELECT * from user_behavior limit 5;检测异常数据(去异常)
查看是否存在异常值:(此数据集认为不再时间范围内的都为异常数据)
select max(datetimes),min(datetimes) from user_behavior;-- 去异常,不在统计时间内的记录
DELETE from user_behavior
where datetimes < '2017-11-25 00:00:00'
or datetimes > '2017-12-03 23:59:59';
查看预处理效果
-- 查看预处理效果
desc user_behavior; -- 字段是否完整
select * from user_behavior LIMIT 100; -- 概览
select count(*) from user_behavior; -- 查看最终的记录,原一亿零十五万条
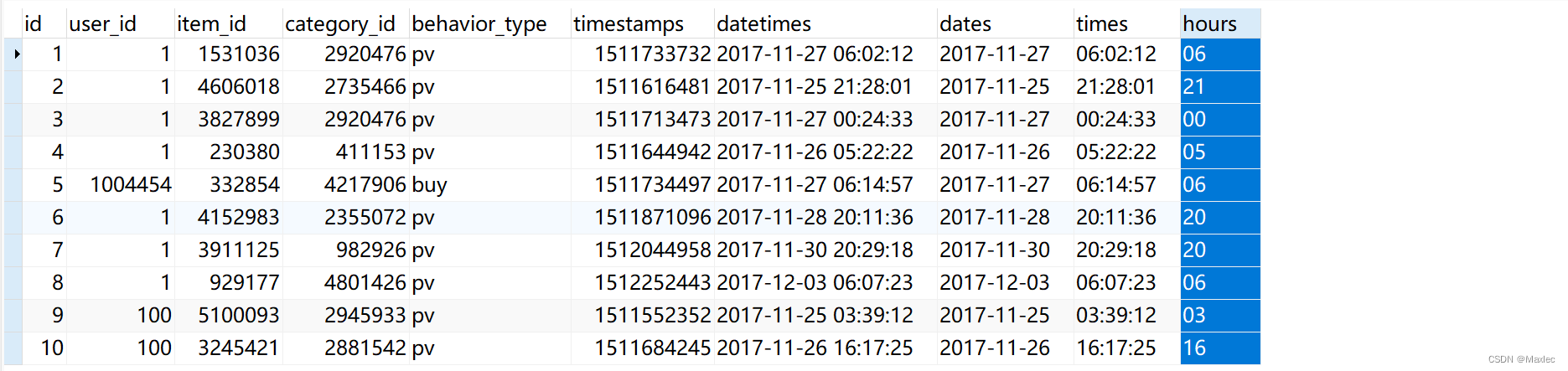

可以看到去重了 53 条记录,去异常 55258 条。原记录1000150807 - 55258 - 53 = 100095496。数据在保证去重去异常的情况下保证了数据的完整性。















 510
510











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











