String
* UTF-16 类似于 UTF-8,在表示非 Latin1 字符时更加高效
* ISO 8859-1,又叫 Latin1,在 ASCII 字符集上添加了西欧字符
* value 字符数组,表示实际的字符串
* coder 整型变量,表示编码器,有 Latin1 和 UTF-16 两种
COMPACT_STRINGS 表示当前字符串是否使用 LATIN1 编码器,由 JVM 进行判断
@Native static final byte LATIN1 = 0; // LATIN1 编码器的 coder 为 0
@Native static final byte UTF16 = 1; // UTF16 编码器的 coder 为 1
// 从虚拟机对数组的大小有限制上看,String 最长不能超过虚拟机可分配的空间最大值
// 从方法签名上看,String 最长不能超过 int 的最大值,即 Integer.MAX_VALUE
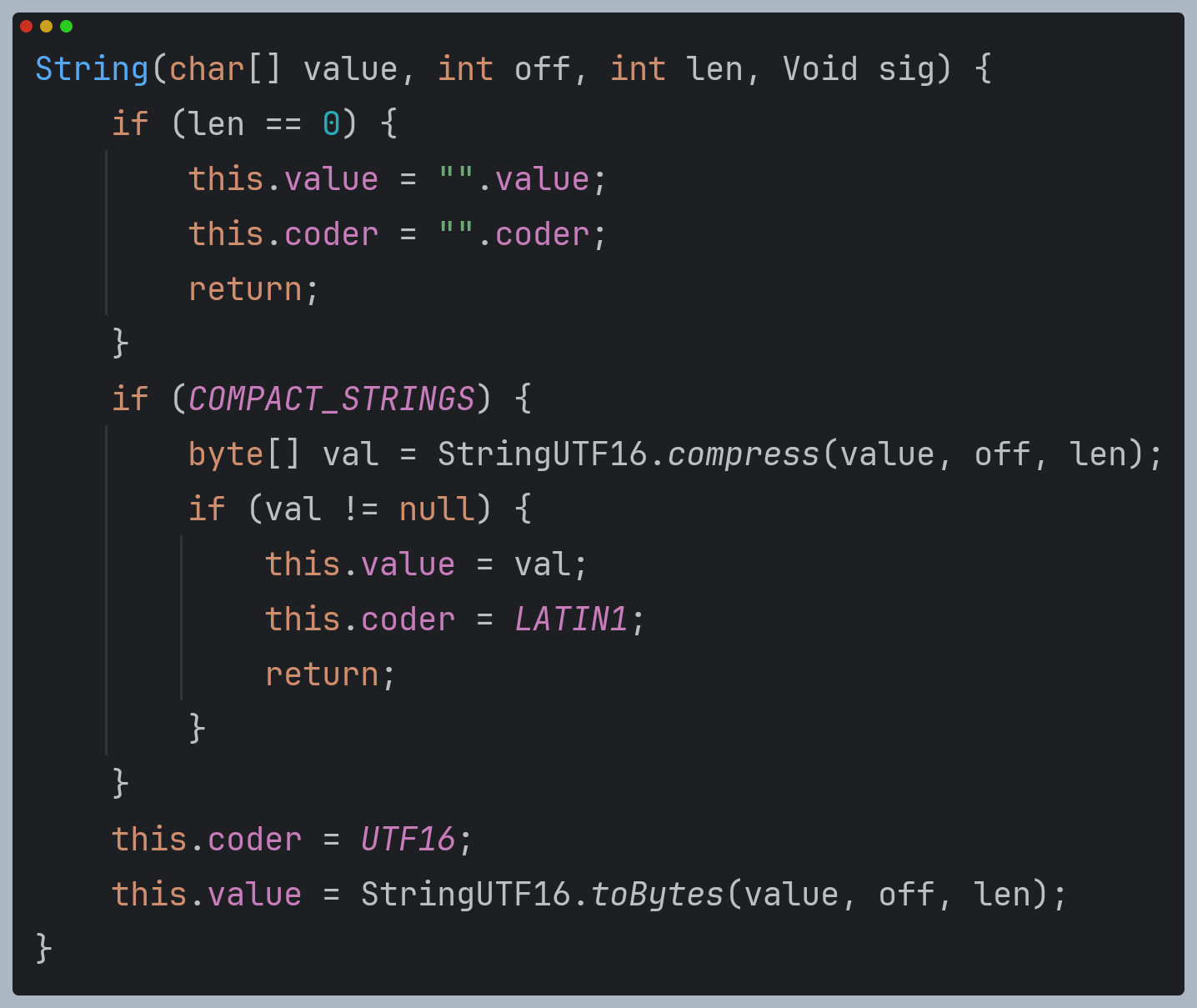
String(char[] value, int off, int len, Void sig) {
if (len == 0) {
this.value = "".value;
this.coder = "".coder;
return;
}
if (COMPACT_STRINGS) {
byte[] val = StringUTF16.compress(value, off, len);
if (val != null) {
this.value = val;
this.coder = LATIN1;
return;
}
}
this.coder = UTF16;
this.value = StringUTF16.toBytes(value, off, len);
}
* char 相当于无符号整数
* 与运算 0 与 1 为 0,1 与 1 为 1
* 0xff 等于 255 二进制表示是 8 个 1
* byte 类型的变量和 0xff 做 & 运算,相当于转为无符号整数
private static native boolean isBigEndian(); // 调用 c 或 c++ 库
// 高 8 位 SHIFT
static final int HI_BYTE_SHIFT;
// 低 8 位 SSHIFT
static final int LO_BYTE_SHIFT;
// 运行时加载
static {
if (isBigEndian()) {
HI_BYTE_SHIFT = 8;
LO_BYTE_SHIFT = 0;
} else {
HI_BYTE_SHIFT = 0;
LO_BYTE_SHIFT = 8;
}
}
@IntrinsicCandidate
// intrinsic performs no bounds checks
static char getChar(byte[] val, int index) {
assert index >= 0 && index < length(val) : "Trusted caller missed bounds check";
index <<= 1;
// 取出高字节
return (char)(((val[index++] & 0xff) << HI_BYTE_SHIFT) |
// 取出低字节,使用或运算进行合并
((val[index] & 0xff) << LO_BYTE_SHIFT));
}
public static String trim(byte[] value) {
UTF-16 每个字符占两个字节,右移一位后可得实际字符数量
int length = value.length >> 1;
int len = length;
int st = 0;
while (st < len && getChar(value, st) <= ' ') {
st++;
}
while (st < len && getChar(value, len - 1) <= ' ') {
len--;
}
return ((st > 0) || (len < length )) ?
new String(Arrays.copyOfRange(value, st << 1, len << 1), UTF16) :
null;
}
public String trim() {
String ret = isLatin1() ? StringLatin1.trim(value)
: StringUTF16.trim(value);
// 如果字符串为 null 返回该对象,否则返回一个新字符串
return ret == null ? this : ret;
}
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
return (anObject instanceof String aString)
&& (!COMPACT_STRINGS || this.coder == aString.coder)
&& StringLatin1.equals(value, aString.value);
}
StringBuilder
* 类似于 String 的可变对象,是线程不安全的
* StringBuilder 是如何将字符串对象转为 StringBuilder 呢?
简单来讲:调用抽象类 AbstractStringBuilder 的构造方法,确定编码器,声明数组空间,
进行复制
AbstractStringBuilder(String str) {
int length = str.length();
int capacity = (length < Integer.MAX_VALUE - 16)
? length + 16 : Integer.MAX_VALUE;
final byte initCoder = str.coder();
coder = initCoder;
value = (initCoder == LATIN1)
? new byte[capacity] : StringUTF16.newBytesFor(capacity);
append(str);
}
public StringBuilder append(String str) {
super.append(str);
return this;
}
public AbstractStringBuilder append(String str) {
if (str == null) {
return appendNull();
}
int len = str.length();
/*
count 表示当前字符串的字符数量
*/
ensureCapacityInternal(count + len); // 确保有足够的空间
putStringAt(count, str);
count += len;
return this;
}
private void ensureCapacityInternal(int minimumCapacity) {
// overflow-conscious code
/*
value 子节数字,表示当前存储的字符
*/
int oldCapacity = value.length >> coder;
// 不够就扩容
if (minimumCapacity - oldCapacity > 0) {
value = Arrays.copyOf(value,
newCapacity(minimumCapacity) << coder);
}
}
private void putStringAt(int index, String str) {
putStringAt(index, str, 0, str.length());
}
private void putStringAt(int index, String str, int off, int end) {
if (getCoder() != str.coder()) { // 可能会添加不同字符集的字符
inflate();
}
// 进行复制
str.getBytes(value, off, index, coder, end - off);
}
void getBytes(byte[] dst, int srcPos, int dstBegin, byte coder, int length) {
if (coder() == coder) {
System.arraycopy(value, srcPos << coder, dst, dstBegin << coder, length << coder);
} else { // this.coder == LATIN && coder == UTF16
StringLatin1.inflate(value, srcPos, dst, dstBegin, length);
}
}
StringBuffer
* 类似于 StringBuilder 是线程安全的可变对象,通过添加 synchronized 锁
* StringBuffer 是如何将 String 对象转为 StringBuffer 对象呢?
和 StringBuilder 相同






















 354
354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









