







题目链接
问题描述
那个曾经风靡全球的贪吃蛇游戏又回来啦!这次贪吃蛇在m行n列的网格上沿格线爬行,从左下角坐标为(0,0)的格点出发,在每个格点处只能向上或者向右爬行,爬到右上角坐标为(m-1,n-1)的格点时结束游戏。网格上指定的格点处有贪吃蛇喜欢吃的豆豆,给定网格信息,请你计算贪吃蛇最多可以吃多少个豆豆。
输入格式
输入数据的第一行为两个整数m、n(用空格隔开),分别代表网格的行数和列数;第二行为一个整数k,代表网格上豆豆的个数;第三行至第k+2行是k个豆豆的横纵坐标x、y(用空格隔开)。
输出格式
程序输出一行,为贪吃蛇可吃豆豆的最大数量。
样例输入
10 10
10
3 0
1 5
4 0
2 5
3 4
6 5
8 6
2 6
6 7
3 1
样例输出
5
数据规模和约定
1≤m, n≤10^6,0≤x≤m-1,0≤y≤n-1,1≤k≤1000
题目分析
一眼就是很简单是路径最值问题,如果开辟一个二维数组把有豆的坐标都标上,然后遍历即可,但是看一眼数据量,很明显这种方式是不可行的。实际上很多为没有豆的位置,就不需要开辟空间了。
也不用模拟从左下到右上,模拟成从左上到右下也是一样的,这样每次本层的最优解就是通过上一层和本层左边的最优解得到。
核心思路
通过离散化和滚动数组降低空间复杂度,离散化使用的数据结构是十字链表。
将有豆豆的位置存入vector<pair<int,int> >coor,并根据行进行排序,排序是为了把每行的豆豆位置聚集在一块,后续按行分割挨个遍历。
map<int,int>dp使用的滚动数组的方式,所以first对应的是列坐标,second表示到该行该列的最优解。
map<int,int>flag记录i曾有哪些豆豆,因为算法是先从行方向进行状态转移,再从列方向进行状态转移,从列方向转移的时候就要知道这个位置有没有豆豆。所以可以理解为他是服务列方向转移的。
逐解代码
初始化与预处理
int n,m,k; // 接收输入不同多说
cin >>m >> n>> k;
// 表示dp[i]的最优解,i是key,必然是不会重复的
map<int,int> dp; // 左为列,右为值
map<int,int> flag; // 用于标记i层哪些位置有豆豆
map<int, int>::iterator iter; // 用于遍历dp
int res=0; // 结果
vector< pair<int,int> > coor; // 接收x,y
int i,j;
for(i=0;i<k;i++){
int x,y;
cin >> x >> y;
coor.push_back(pair<int,int>(x,y));
}
// 根据行进行排序
sort(coor.begin(),coor.end());
使用样例数据打印一下
c
o
o
r
coor
coor排序后的结果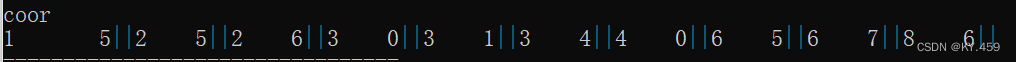
用||分隔每一个元素,左边是行,右边是列,第一行第一列是从0,0开始的,所以(1,5)表示第2行第6列有豆豆。
按层处理从上到下的最优解
保证每次只处理一行的所有豆豆,注意&&右边的条件,它控制着每层的遍历。
for(i=0;i<coor.size();i=j){
// 每次处理统一行的豆豆
for(j=i;j<coor.size() && coor[j].first==coor[i].first;j++)// 保证在某一行
{// 处理内容}
// 再遍历dp,求出[i]最优解从左来还是从上来
.........
}
根据上面 c o o r coor coor的数据:
第一次处理(1,5)
第二次处理(2,5),(2,6)
第三次处理(3,0),(3,1),(3,4)
第四次处理(4,0)
第五次处理(6,5),(6,7) // 跳过了第五行,说明第五行没有豆
.....
处理内容
看注释
// 处理纵轴有豆的位置
for(j=i;j<coor.size() && coor[j].first==coor[i].first;j++){// 保证在某一行
// 处理内容 ,把coor的val作为dp的key
if(dp.find(coor[j].second)!=dp.end()){ // 如果这个位置的上一层有豆豆,从上面过来就要+1
dp[coor[j].second] += 1;
}
else dp[coor[j].second] =1; // 没有则表示从上方垂直到达这个位置的最优解
// 标记本行豆豆的位置 ,这样从左边到该点就可以+1了
if(flag.find(coor[j].second)!=flag.end()) // 一个点出现了多个豆 ,我也不确定数据里面会不会有多个豆在一个坐标
flag[coor[j].second] += 1;
else flag[coor[j].second] = 1; // 标记这个位置有豆
}
再处理左到右的最优解
注意下面代码 r e s + f l a g [ i t e r − > f i r s t ] res+flag[iter->first] res+flag[iter−>first]中,我是为了防止多个豆豆出现在一个点上才这样写,如果每个点只会出现一个豆豆,那么max左边参数传入写成 r e s + 1 res+1 res+1也是一样的。所以没有豆豆的话就不用+1了。
max左边传入的参数表示当前位置左边的位置。
max右边传入的参数表示当前位置,当前位置我们起初已经从上到下处理过了,所以此时的当前位置表示的是从上方下来的最优解,二者一比较就知道从左边过来和从上边下来那个值最大,大的就是当前位置的最优解。
另一个需要注意的点就是res = iter->second; // 更新到当前位置的最优解。
此时的res就代表了当前位置的最优解,而最优解可能是从上面下来也可能是从左边过来,我们并不用知道具体路径,只需要拿这个值和dp下一个元素继续比较即可。
//再处理横轴 ,求出[i][j]最优解从左来还是从上来
iter=dp.begin(); // 最左的位置
res = iter->second; // 最左边的值
// 因为是从左到右,所以最优解的计算从左边第二个元素开始
for(++iter;iter!=dp.end();iter++){// 遍历dp
if(flag.find(iter->first)!=flag.end()){ // 如果有豆豆,从左边过来就可以吃到,要+1
iter->second = max(res+flag[iter->first],iter->second); // 左边过来和从上面过来那个最优
}
else iter->second = max(res,iter->second);
res = iter->second; // 更新到当前位置的最优解
}
flag.clear(); // 清空标记
} // 这是最外层for的右括号
图解
根据样例数据看一下每次dp的状态
结合
c
o
o
r
coor
coor中的数据一起看
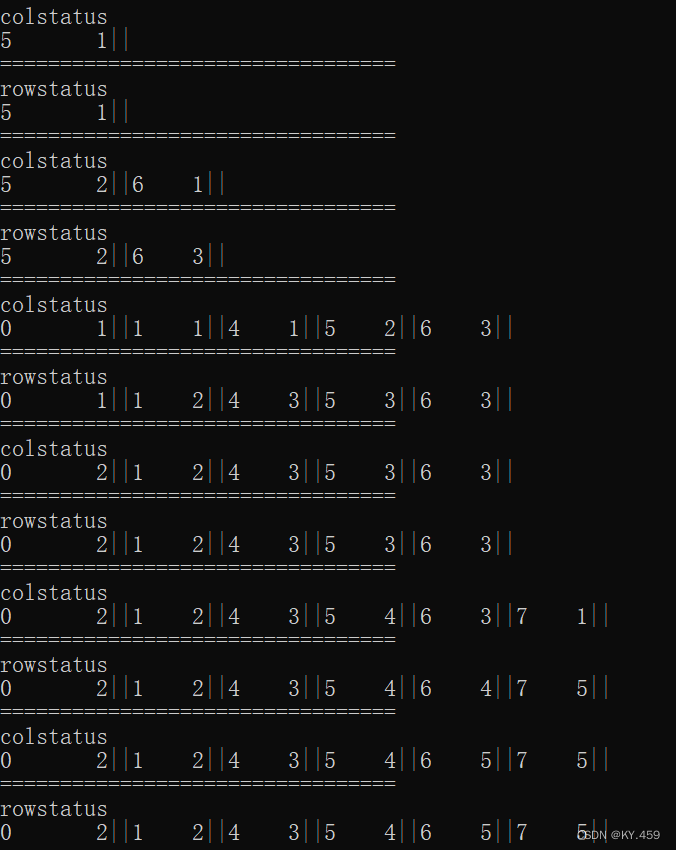
colstatus表示从上之下之后dp的元素状态
rowstatus表示从左至右之后dp的元素状态
模拟一下
c
o
o
r
coor
coor前三个元素的递推过程,可以对照上面打印结果看。

初始时,dp中没有元素。
第一个colstatus,表示到第五列可以吃到最多1个豆,而其左边没有豆,所以第一个rowstatus和colstatus一样。
第二个colstatus,第5列,和第6列有豆,在dp未进行状态转移前,表示dp的下一行的5列和6列有豆,转移过后,dp就表示本行从上至下到第5列和第6列的最优解dp[5]=2,dp[6]=1。

rowstatus从左到右,进行状态转移,(2,6)的位置是有豆的,所以过来需要(2,5)+1再和(2,6)比较,dp[6]表示到这行第6列的最大值为3。

最后模拟一下
c
o
o
r
coor
coor第四到第六个元素的递推过程,红框内是之前前三个元素递推的结果。
从上至下转移,得到从上方到当前层的最优解,excel中的结果:
对照代码打印的结果
rowstatus。再从左至右将dp更新成当前层的最优解:

从最左边开始向右移动,(3,1)有豆,那么(3,1)当前层的最优解就等于max( (3,0)+1 , (3,1) )
同样的,(3,4)有豆,它的当前层最优解max( (3,1)+1 , (3,4) )
而(3,5)和(3,6)没有豆,它们俩的当前层最优解就是
max( (3,4), (3,5) or (3,6) )
完整代码
#include <iostream>
#include <vector>
#include <utility>
#include <map>
#include <algorithm>
using namespace std;
// 提交代码时需要把print和宏定义都注释
template <typename T>
void print(T mapobj){
for(auto x:mapobj)
cout << x.first <<'\t' << x.second<<"||";
cout<< '\n' << "=================================" << endl;
}
int max(int a,int b){
return a>b?a:b;
}
int main()
{
int n,m,k;
cin >>m >> n>> k;
// 邻接表 ,左边保存列,右边保存值
map<int,int> dp; // 左为列,右为值
map<int,int> flag; // 用于标记i层哪些位置有豆豆
map<int, int>::iterator iter; // 用于遍历dp
int res=0; // 结果
vector< pair<int,int> > coor; // 接收x,y
int i,j;
for(i=0;i<k;i++){
int x,y;
cin >> x >> y;
coor.push_back(pair<int,int>(x,y));
}
// 得到升序排列的pair
sort(coor.begin(),coor.end());
#define printcoor 1// 设置为1打印coor
#if printcoor
cout << "coor" << endl;
print(coor);
#endif
for(i=0;i<coor.size();i=j){
// 先处理纵轴有豆的位置
for(j=i;j<coor.size() && coor[j].first==coor[i].first;j++){// 保证在某一行
if(dp.find(coor[j].second)!=dp.end()){ // dp[:,j]之前是否有豆豆
dp[coor[j].second] += 1;
}
else dp[coor[j].second] =1; // 没有就新建一个
// 标记i行豆豆位置
if(flag.find(coor[j].second)!=flag.end()) // 一个点出现了多个豆
flag[coor[j].second] += 1;
else flag[coor[j].second] = 1; // 标记这个位置有豆
}
#define printdpcol 0// 设置为1打印dp每次列方向的状态
#if printdpcol
cout << "colstatus" << endl;
print(dp);
#endif
//再处理横轴 ,求出[i][j]最优解从左来还是从上来
// 遍历dp
iter=dp.begin();
res = iter->second;
for(++iter;iter!=dp.end();iter++){
if(flag.find(iter->first)!=flag.end()){ // 如果有豆豆
iter->second = max(res+flag[iter->first],iter->second); // 左边过来和从上面过来那个最优
}
else iter->second = max(res,iter->second);
res = iter->second;
}
flag.clear(); // 清空标记
#define printdprow 0// 设置为1打印dp每次列方向的状态
#if printdprow
cout << "rowstatus" << endl;
print(dp);
#endif
}
cout << res << endl;
return 0;
}
总结
本文针对一道题做了大量的解释说明,会导致没有读下去的欲望,这点是我需要反思的。
但是我写的这道确实是网上目前题解中数一数二的优解,不论是时间还是空间。所以我希望尽可能写的详细,使更多小白能深刻理解核心思想。
在信息碎片化的时代,也希望对如此冗余的文章多一些耐心。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









