







文章目录
前言
内容仅供参考,本篇基于python描述文本数据处理相关内容。
提示:以下是本篇文章正文内容,下面案例可供参考
一、实验目的
-
掌握jieba库的使用,学会中文分词、词性标注、特征提取。
-
掌握词袋模型特征和TF-IDF模型。
-
了解案例:垃圾邮件识别。
二、实验环境
-
操作系统:Windows
-
应用软件:anaconda jupyter
三、实验内容与结果
特征提取:对于文本数据计算机无法直接处理,需要先将其数字化。特征提取的目的是将文本字符串转换为数字特征向量。常用的模型包括:
·词袋模型(Bag of word)
·TF-IDF(term frequency–inverse document frequency)
·词向量模型
(一)词袋模型
例7-3:提取文档集的词袋特征
文档集
句子1:“我是中国人,我爱中国”
句子2:“我是上海人”
句子3:“我住在上海松江大学城”
建立词袋模型:分词,构建词典
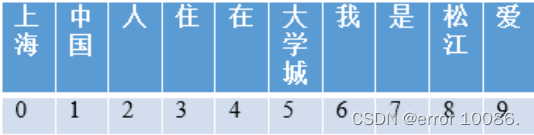
根据词典,构建词袋向量
句子1:[0 2 1 0 0 0 2 1 0 1] 上海0次,中国2次、人1次......
句子2:[1 0 1 0 0 0 1 1 0 0]
句子3:[1 0 0 1 1 1 1 0 1 0]
(二)TF-IDF模型
TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。
TF-IDF是一种统计方法,用以评估一字/词对于一个文件集或一个语料库中的某份文件的重要程度。字词的重要性与它在文件中出现的次数成正比升高,但同时会随着它在语料库中出现的频率成反比下降。
TF-IDF的主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
Scikit-learn中计算TF-IDF 值有两种方法:
一、CountVectorizer类 向量化之后 再调用TfidfTransformer类
二、用TfidfVectorizer完成向量化 与TF-IDF计算
例题一文档集包含以下5条文本:
"我是中国人,我爱中国"
"我是上海人"
"我住在上海松江大学城"
"松江大学城有很多大学"
"大学城共有15万余大学生"
提取以上文档集的词袋模型特征(包含字符数为1的词作为特征词)和TF-IDF模型特征。
from sklearn.feature_extraction.text import CountVectorizer
import jieba
import warnings
warnings.filterwarnings("ignore")
#给出文档集,放在字符串列表中
corpus = ["我是中国人,我爱中国",
"我是上海人",
"我住在上海松江大学城",
"松江大学城有很多大学",
"大学城共有15万余大学生" ]
split_corpus = [] #初始化存储分词结果的列表
for txt in corpus:
#将jieba分词后的字符串列表拼接为一个字符串,元素之间用" "分割,每个句子分词结果 精确分词
words = " ".join(jieba.lcut(txt)) #用” ”将多个词拼接为一个字符串
split_corpus.append(words) #将分词结果字符串添加到列表中
print(split_corpus)![]()
cv = CountVectorizer(token_pattern=r"(?u)\b\w+\b")#根据输入数据,获取词频矩阵
cv_fit=cv.fit_transform(split_corpus) #生成词袋向量
#即将从数据集中学到的特征应用到数据集中
print(cv.get_feature_names()) #显示特征列表
print(cv_fit.toarray()) #显示特征向量
from sklearn.feature_extraction.text import TfidfTransformer
tfidf_transformer = TfidfTransformer()#将文本词袋特征转化为TF-IDF值
tfidf_fit = tfidf_transformer.fit_transform(cv_fit)
#显示TF-IDF特征向量
print(tfidf_fit.toarray())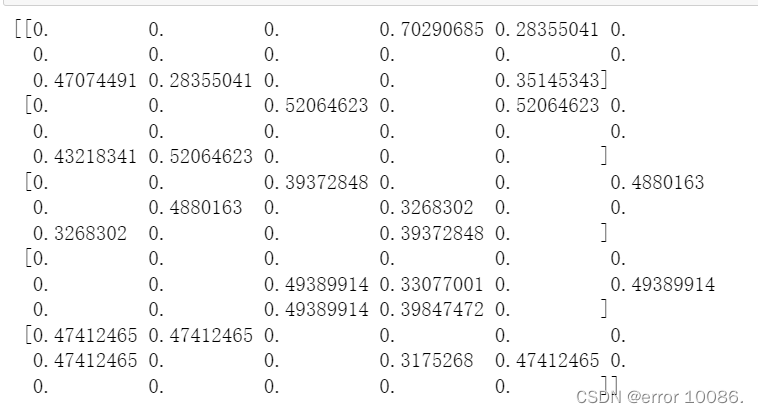
例题二:用TF-IDF模型提取邮件特征,朴素贝叶斯模型训练分类模型实现垃圾邮件识别并分析模型性能。
from sklearn.feature_extraction.text import CountVectorizer
import jieba
from sklearn.naive_bayes import GaussianNB
from sklearn import model_selection #划分测试集训练集
from sklearn import metrics #评估性能
#1、从文件中读出邮件内容,存放在列表中
train_file = open(".\mailcorpus.txt", 'r', encoding = "utf-8")
corpus = train_file.readlines() #列表中的每个元素为一行文本
#2、使用jieba进行中文分词,将每个中文字符串转换为用空格分隔的词。
split_corpus = [] #初始化存储分词结果的列表
for c in corpus:
split_corpus.append(" ".join(jieba.lcut(c)))
#3、使用TF-IDF模型提取邮件特征,得到文本特征向量
from sklearn.feature_extraction.text import TfidfVectorizer
cv = TfidfVectorizer(token_pattern=r"(?u)\b\w+\b") #初始化
X = cv.fit_transform(split_corpus).toarray()
#构造分类标签,垃圾邮件标签为0,正常邮件标签为1
y = [0] * 5000 + [1] * 5000 #列表,10000个元素,前5000为0,后5000为1
#将特征集 分为训练集和测试集
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.4, random_state = 0)
#4、采用朴素贝叶斯模型训练分类模型
clf = GaussianNB() #模型初始化
clf.fit(X, y) #模型训练![]()
#朴素贝叶斯模型分类性能
y_pred_clf = clf.predict(X_test)
print("clf accuracy:\n",clf.score(X_test, y_test))
print("clf report:\n",metrics.classification_report(y_test, y_pred_clf))
print("clf matrix:\n",metrics.confusion_matrix(y_test, y_pred_clf))

















 645
645

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









